
Abstract
Current medical practice is driven by clinical guidelines which are designed for the “average” patient. Deep learning is enabling medicine to become personalized to the patient at hand. In this paper we present a new recurrent neural network model for personalized survival analysis called rnn-surv. Our model is able to exploit censored data to compute both the risk score and the survival function of each patient. At each time step, the network takes as input the features characterizing the patient and the identifier of the time step, creates an embedding, and outputs the value of the survival function in that time step. Finally, the values of the survival function are linearly combined to compute the unique risk score. Thanks to the model structure and the training designed to exploit two loss functions, our model gets better concordance index (C-index) than the state of the art approaches.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


1 Introduction
Healthcare is moving from a population-based model, in which the decision making process is targeted to the “average” patient, to an individual-based model, in which each diagnosis is based on the features characterizing the given patient. This process has been boosted by the recent developments in the Deep Learning field, which has been proven to not only get impressive results in its traditional areas, but also to perform very well in medical tasks.
In particular, in the medical field, the study of the time-to-event, i.e., the expected duration of time until one or more events happen, such as death or recurrence of a disease, is of vital importance. Nevertheless, it is often made more complicated by the presence of censored data, i.e., data in which the information about the time-to-event is incomplete, as it happens, e.g., when a patient drops a clinical trial. Traditionally, these issues are tackled in a field called Survival Analysis, a branch of statistics in which special models have been proposed to predict the time-to-event exploiting censored data, while only a few deep learning approaches have such an ability (e.g., [13, 28]). About the latter, it is interesting to note that most of the encountered deep learning approaches are based on feedforward neural networks and, at least so far, there does not seem to exist published results deploying recurrent neural networks despite the sequential nature of the problem.
In this paper we present a new recurrent neural network model handling censored data and computing, for each patient, both a survival function and a unique risk score. The survival function is computed by considering a series of binary classifications problems each leading to the estimation of the survival probability in a given interval of time, while the risk score is obtained through the linear combination of the estimates. rnn-surv three main features are:
-
1.
its ability to model the possible time-variant effects of the covariates,
-
2.
its ability to model the fact that the survival probability estimate at time t is function of each survival probability estimate at \(t': t' < t\), and
-
3.
its ability to compute a highly interpretable risk score.
The first two are given by the recurrent structure, while the last is given by the linear combination of the estimates.
rnn-surv is tested on three small publicly available datasets and on two large heart transplantation datasets. On these datasets rnn-surv performs significantly better than the state of the art models, always resulting in a higher C-index than the state of the art models (up to 28.4%). We further show that if we simplify the model we always get worse performances, hence showing the significance of rnn-surv different features.
This paper is structured as follows. We start with the analysis of the related work (Sect. 2), followed by the background about Survival Analysis (Sect. 3). Then, we present of our model (Sect. 4), followed by the experimental analysis (Sect. 5), and finally the conclusions (Sect. 6).
2 Related Work
The problem of survival analysis has attracted the attention of many machine learning scientists, giving birth to models such as random survival forest [11], dependent logistic regressors [26], multi-task learning model for survival analysis [17], semi-proportional hazard model [27] and support vector regressor for censored data [21], all of which not based on neural networks.
Considering the works that have been done in the field of Survival Analysis using Deep Learning techniques, these can be divided in three main subcategories, that stemmed from just as many seminal papers:
-
(1)
Faraggi and Simon [7] generalized Cox Proportional Hazards model (CPH) [5] allowing non-linear functions instead of the traditional linear combinations of covariates by modeling the relationship between the input covariates and the corresponding risk with a single hidden layer feedforward neural network. This work has been later resumed in [13] and [28]. Contrarily to rnn-surv, CPH and the models [13] and [28] assume time-invariant effects of the covariates.
-
(2)
Liestbl, Andersen and Andersen [18] subdivided time into K intervals, assumed the hazard to be constant in each interval and proposed a feedforward neural network with a single hidden layer that for each patient outputs the conditional event probabilities \(p_k = P(T \ge t_k | T \ge t_{k-1})\) for \(k = 1,...,K\), T being the time-to-event of the given patient. This work was then expanded in [2], but even in this later work the value of the estimate \(p_{k-1}\) for a given patient is not exploited for the computation of the estimate \(p_k\) for the same patient. On the contrary, rnn-surv, thanks to the presence of recurrent layers, is able to capture the intrinsic sequential nature of the problem.
-
(3)
Buckley and James [4] developed a linear regression model that deals with each censored data by computing its most likely value on the basis of the available data. This approach was then generalized using neural networks in various ways (e.g., [6]). Unlike rnn-surv, in [4] and in the following ones, estimated and known data are treated in the same way during the regression phase.
3 Background on Survival Analysis
Consider a patient i, we are interested in estimating the duration \(T_i\) of the interval in between the event of interest for i and the time \(t_0\) at which we start to measure time for i. We allow for right censored data, namely, data for which we do not know when the event occurred, but only that it did not occur before a censoring time \(C_i\). The observed time \(Y_i\) is defined as \(Y_i = \text {min}(T_i,C_i)\), and each datapoint corresponds to the pair \((Y_i,\delta _i)\) where \(\delta _i = 0\) if the event is censored (in which case \(Y_i = C_i\)) and \(\delta _i = 1\) otherwise.
In Survival Analysis, the standard functions used to describe \(T_i\) are the survival function and the hazard function [15].
-
1.
The survival function \(S_i(t)\) is defined as:
$$\begin{aligned} S_i(t) = Pr (T_i > t) \end{aligned}$$(1)with \(S_i(t_0) = 1\).
-
2.
The hazard function \(h_i(t)\) is defined as:
$$\begin{aligned} h_i(t) = \lim _{dt \rightarrow 0}\frac{Pr(t \le T_i < t + dt \mid T_i \ge t)}{dt}. \end{aligned}$$(2)
Further, in order to offer a fast understanding of the conditions of the patient, a common practice of the field is to create a risk score \(r_i\) for each patient i: the higher the score the higher the risk of the occurrence of the event of interest.

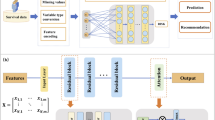
rnn-surv with \(N_1=2\) feedforward layers, followed by \(N_2=2\) recurrent layers.
4 RNN-SURV
In order to transform the survival analysis problem in a series of binary decision problems, we assume that the maximal observed time is divided into K intervals \((t_0 , t_1], \ldots , (t_{K -1} , t_K]\) and that the characteristic function modeling \(T_i\) is constant within each interval \((t_{k-1},t_k]\) with \(k = 1,\ldots ,K\). Given a patient i, the purpose of our model is to output both an estimate \(\hat{y}_i^{(k)}\) of the survival probability \(S_i\) for the kth time interval and a risk score \(r_i\).
4.1 The Structure of the Model
The overall structure of rnn-surv is represented in Fig. 1 and is described and motivated below:
-
1.
the input of each layer is given by the features \(\mathbf {x}_i\) of each patient i together with the time interval identifier k. Thanks to this input, rnn-surv is able to capture the time-variant effect of each feature over time,
-
2.
taking the idea from the natural language processing field, the input is then elaborated by \(N_1\) embedding layers. Thanks to the embeddings we are able to create a more meaningful representation of our data, and
-
3.
the output of the embedding layers is then passed through \(N_2\) recurrent layers and a sigmoid non-linearity. This generates the estimates \(\hat{y}_i^{(1)}, \ldots , \hat{y}_i^{(K)}\) from which we can compute the risk score with the following equation:
$$\begin{aligned} \hat{r}_i = \sum _{k=1}^K w_k \hat{y}_i^{(k)} \end{aligned}$$(3)where \(w_k\) for \(k = 1, \ldots , K\) are the parameters of the last layer of rnn-surv. Thanks to the linear combination, the risk score, whose quality is evaluated with the C-index [9], is highly interpretable.
Further, in order to handle the vanishing gradient problem, the feedforward layers use the ReLU non-linearity [19], while the recurrent layers are constituted of LSTM cells [10], which are defined as:

4.2 Training
Since the neural network predicts both the discrete survival function and the risk score for each datapoint, it is trained to jointly minimize two different loss functions:
-
1.
The first one is a modified cross-entropy function able to take into account the censored data, defined as:
 (5)
(5)where \(U_k = \{i \mid \delta _i=1 \,\,\text{ or } \,\, C_i > t_k\}\) represents the set of individuals that are uncensored throughout the entire observation time or for which censoring has not yet happened at the end of the kth time interval.
-
2.
The second one is an upper bound of the negative C-index [23] defined as:
$$\begin{aligned} \mathcal {L}_2 = - \frac{1}{\mathcal {|C|}} \sum _{(i,j) \in \mathcal {C}} \bigg [ 1 + \bigg (\frac{\log \sigma (\hat{r}_j - \hat{r}_i) }{\log 2} \bigg )\bigg ] \end{aligned}$$(6)where \(\mathcal {C}\) is the set of pairs \(\{(i,j) \mid \delta _i = 1 \text {~and~} (Y_i \le Y_j) \}\). The advantage of minimizing (6) instead of the negative C-index is that the former still leads to good results [23], and the latter is far more expensive to compute and would have made the experimental evaluation impractical.

The two losses \(\mathcal {L}_1\) and \(\mathcal {L}_2\) are then linearly combined, with the hyperparameters of the sum optimized during the validation phase.
In order to avoid overfitting, we apply dropout to both the feedforward layers [22] and to the recurrent layers [8], together with a holdout-based early stopping as described in [20]. Further, we add L2-regularization to the linear combination of the losses. The entire neural network is trained using mini-batching and Adam optimizer [14].
5 Experimental Analysis
All our experiments are conducted on two large datasets, UNOS Transplant and UNOS Waitlist, from the United Network for Organ Sharing (UNOS)Footnote 1 and on three publicly available, small datasets, AIDS2, FLCHAIN, NWTCO.Footnote 2 In each experiment we deploy 60/20/20 division into training, validation and test sets and the early stopping is configured as a no validation gain for 25 consecutive epochs. The main characteristics of these datasets are shown in Table 1, while the structure of rnn-surv for each dataset is shown in Table 2. The performances of our model are measured using the C-index [9].Footnote 3
5.1 Preprocessing
Our datasets present missing data and thus they require a preprocessing phase. UNOS Transplant and UNOS Waitlist contain data about patients that registered in order to undergo heart transplantation during the years from 1985 to 2015. In particular UNOS Transplant contains data about patients who have already undergone the surgery, while UNOS Waitlist contains data about patients who are still waitlisted. From the complete datasets, we discard 12 features that can be obtained only after transplantation and all the features for which more than 10% of the patients have missing information. In order to deal with the missing data on the remaining 53 and 27 features, we conduct 10 multiple imputations using Multiple Imputation by Chained Equations (MICE) [24].
The three small datasets contain data about:
-
1.
NWTCO: contains data from the National Wilm’s Tumor Study [3],
-
2.
FLCHAIN: contains half of the data collected during a study [16] about the possible relationship between serum FLC and mortality, and
-
3.
AIDS2: contains data on patients diagnosed with AIDS in Australia [25].
For these datasets, we complete the missing data using the mean value for the continuous features and using the most recurrent value for the categorical ones. Once complete the missing data, we then use one-hot encoding for the categorical features and we standardize each feature so that each has mean \(\mu = 0\) and variance \(\sigma = 1\).
5.2 Comparison with Other Models
We have compared rnn-surv with the two traditional Survival Analysis models, CPH and Aalen Additive Hazards model (AAH) [1], and with three recent models that try to conjugate Machine Learning with Survival Analysis: rfs [11], deep-surv [13] and mtlsa [17]. Both CPH and AAH have been implemented using the lifelines packageFootnote 4, while we deployed the randomForestSRC packageFootnote 5 for rfs, the deepsurv packageFootnote 6 for deep-surv and the mtlsa packageFootnote 7 for mtlsa. The results shown in Table 3 are obtained using k-fold cross validation (with \(k = 5\)). As it can be seen from the table, rnn-surv outperforms the other models in all the datasets. In particular, the biggest improvements are obtained with respect to mtlsa, with a peak of 28.4% on the FLCHAIN dataset.
5.3 Estimating the Survival Curves
To further demonstrate the good results obtained by rnn-surv, in Fig. 2 we show some of the survival curves obtained in largest dataset available, the UNOS Transplant dataset.
Figure 2 shows that our model is able to capture the average trend of the survival curves, both for the whole population and for subsets of it. Further, rnn-surv demonstrates to have a great discriminative power: it is able to plot a unique survival function for each patient and, as it is shown in Fig. 2(c), the survival curves can be very different one from another and from the average survival curve.

Performances of rnn-surv on UNOS Transplant dataset on a 36 months horizon on the test set. (a) average Survival Function obtained with rnn-surv and Kaplan-Meier curve [12]. (b) average Survival Functions obtained with rnn-surv and Kaplan-Meier curves for two subgroups of patients: patients who experienced an infection and patients who did not. (c) Kaplan-Meier curve together with the survival curves of two different patients (P1: Patient 1, P2: Patient 2).
5.4 Analysis of the Model
We now analyze how the different main components of rnn-surv contribute to its good performances. In particular, we consider the model without the three main features of the model:
-
1.
We first consider the case in which we do not have the feedforward layers, i.e., with \(N_1 = 0\);
-
2.
Then the case in which the interval identifier k as input to the feedforward layer is always set to 1;
-
3.
Finally the case in which the model has only one likelihood, i.e., \(\mathcal {L}_2\).
The C-index of the various versions and of the complete model on the different datasets are shown in Table 4. In the Table the best results are in bold, while the worst results are underlined. As it can be seen, the best performances are always obtained by the complete model, meaning that all the different components have a positive contribution. Interestingly, the worst performances are obtained when we disable the \(\mathcal {L}_1\) score on the large datasets and the feedforward layers in the small ones. The explanation for the very positive contribution of using both the \(\mathcal {L}_1\) and \(\mathcal {L}_2\) scores on the two large datasets is that \(\mathcal {L}_1\) allows to take into account the intermediate performances of the network when computing \(\hat{y}^{(1)}_i,\ldots ,\hat{y}^{(K)}_i\). On the other hand, for the small datasets, the positive contribution of using the two scores is superseded by the feedforward layers and this can be explained by the characteristics of the datasets presenting a majority of discrete features.
6 Conclusions
In this paper we have presented rnn-surv: a new recurrent neural network model for predicting a personalized risk score and survival probability function for each patient in presence of censored data. The proposed model has three main distinguishing features, each having a positive impact on the performances on two large and three small, publicly available datasets. Our experiments show that rnn-surv always performs much better than competing approaches when considering the C-index, improving the state of the art up to 28.4%.
Notes
- 1.
- 2.
- 3.
Implementation by lifelines package.
- 4.
- 5.
- 6.
- 7.
References
Aalen, O.: A Model for nonparametric regression analysis of counting processes. In: Klonecki, W., Kozek, A., Rosiński, J. (eds.) Mathematical Statistics and Probability Theory. LNS, vol. 2, pp. 1–25. Springer, New York (1980). https://doi.org/10.1007/978-1-4615-7397-5_1
Biganzoli, E., Boracchi, P., Mariani, L., Marubini, E.: Feed forward neural networks for the analysis of censored survival data: a partial logistic regression approach. Stat. Med. 17, 1169–1186 (1998)
Breslow, N.E., Chatterjee, N.: Design and analysis of two-phase studies with binary outcome applied to Wilm’s tumour prognosis. Appl. Stat. 48, 457–468 (1999)
Buckley, J., James, I.: Linear regression with censored data. Biometrika 66(3), 429–436 (1979)
Cox, D.R.: Partial likelihood. Biometrika 62(2), 269 (1975)
Dezfouli, H.N.: Improving gastric cancer outcome prediction using time-point artificial neural networks models. Cancer Inform. 16, 117693511668606 (2017)
Faraggi, D., Simon, R.: A neural network model for survival data. Stat. Med. 14(1), 73–82 (1995)
Gal, Y., Ghahramani, Z.: A theoretically grounded application of dropout in recurrent neural networks. In: 29th NIPS, pp. 1019–1027 (2016)
Harrell, F.J., Califf, R., Pryor, D., Lee, K., Rosati, R.: Evaluating the yield of medical tests. JAMA 247(18), 2543–2546 (1982)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997). https://doi.org/10.1162/neco.1997.9.8.1735
Ishwaran, H., Kogalur, U.B., Blackstone, E.H., Lauer, M.S.: Random survival forests. Ann. Appl. Stat. 2, 841–860 (2008)
Kaplan, E.L., Meier, P.: Non parametric estimation from incomplete observations. J. Am. Stat. Assoc. 53, 457–481 (1958)
Katzman, J., Shaham, U., Cloninger, A., Bates, J., Jiang, T., Kluger, Y.: Deep survival: a deep cox proportional hazards network. CoRR (2016)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. CoRR abs/1412.6980 (2014). http://arxiv.org/abs/1412.6980
Klein, J.P., Moeschberger, M.L.: Survival Analysis Techniques for Censored and Truncated Data, 2nd edn. Springer, New York (2003)
Kyle, R., et al.: Use of monclonal serum immunoglobulin free light chains to predict overall survival in the general population. N. Engl. J. Med. 354, 1362–1369 (2006)
Li, Y., Wang, J., Ye, J., Reddy, C.K.: A multi-task learning formulation for survival analysis. In: 22nd ACM SIGKDD, KDD 2016, pp. 1715–1724. ACM, New York (2016)
Liestbl, K., Andersen, P.K., Andersen, U.: Survival analysis and neural nets. Stat. Med. 13(12), 1189–1200 (1994)
Nair, V., Hinton, G.E.: Rectified linear units improve restricted Boltzmann machines. In: 27th ICML, pp. 807–814 (2010)
Prechelt, L.: Early stopping—but when? In: Montavon, G., Orr, G.B., Müller, K.-R. (eds.) Neural Networks: Tricks of the Trade. LNCS, vol. 7700, pp. 53–67. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-35289-8_5
Shivaswamy, P.K., Chu, W., Jansche, M.: A support vector approach to censored targets. In: Proceedings of 7th IEEE ICDM, ICDM 2007, pp. 655–660. IEEE Computer Society (2007). https://doi.org/10.1109/ICDM.2007.93
Srivastava, N., Hinton, G.E., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15(1), 1929–1958 (2014)
Steck, H., Krishnapuram, B., Dehing-oberije, C., Lambin, P., Raykar, V.C.: On ranking in survival analysis: bounds on the concordance index. In: Platt, J.C., Koller, D., Singer, Y., Roweis, S.T. (eds.) 20th NIPS, pp. 1209–1216. Curran Associates Inc., New York (2008)
Van Buuren, S., Oudshoorn, K.: Flexible mutlivariate imputation by MICE. TNO, Leiden (1999)
Venables, W.N., Ripley, B.D.: Modern Applied Statistics with S. Springer, Heidelberg (2002). https://doi.org/10.1007/978-0-387-21706-2
Yu, C.N., Greiner, R., Lin, H.C., Baracos, V.: Learning patient-specific cancer survival distributions as a sequence of dependent regressors. In: Shawe-Taylor, J., Zemel, R.S., Bartlett, P.L., Pereira, F., Weinberger, K.Q. (eds.) 24th NIPS, pp. 1845–1853. Curran Associates Inc., New York (2011)
Zhang, J., Chen, L., Vanasse, A., Courteau, J., Wang, S.: Survival prediction by an integrated learning criterion on intermittently varying healthcare data. In: 30th AAAI, AAAI 2016, pp. 72–78. AAAI Press (2016)
Zhu, X., Yao, J., Huang, J.: Deep convolutional neural network for survival analysis with pathological images. In: IEEE International Conference on Bioinformatics and Biomedicine, BIBM 2016, Shenzhen, China, pp. 544–547 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Giunchiglia, E., Nemchenko, A., van der Schaar, M. (2018). RNN-SURV: A Deep Recurrent Model for Survival Analysis. In: Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I. (eds) Artificial Neural Networks and Machine Learning – ICANN 2018. ICANN 2018. Lecture Notes in Computer Science(), vol 11141. Springer, Cham. https://doi.org/10.1007/978-3-030-01424-7_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-01424-7_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-01423-0
Online ISBN: 978-3-030-01424-7
eBook Packages: Computer ScienceComputer Science (R0)