
Abstract
We set the stage for this chapter by recapitulating Winne and Hadwin’s (1998) model of self-regulated learning and identifying three obstacles learners face when they strive to effectively self-regulate learning autonomously. In this context, we provide an overview of the nStudy software system, a web application that offers learners a wide array of tools for identifying and operating on information they study. We designed nStudy to be a laboratory for learners and researchers alike to explore learning skills, metacognition and self-regulated learning. As learners use nStudy’s tools to study information in the Internet or researchers’ specially prepared HTML material, nStudy logs fine-grained, time-stamped trace data that reflect the cognitive and metacognitive events in self-regulated learning. Next steps in work on the nStudy system are to add tools learners that provide feedback they can use to advance personal programs of research on improving learning skills and gainfully self-regulating learning.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
Context
Today’s learners are making extensive use of information resources in the Internet to do homework assignments, mine information for term papers, and pursue curiosity-driven investigations. Easy and inexpensive means for online self-publication—e.g., blogs and free server space—coupled with the exploding popularity of ebooks and ebook readers leads us to conjecture that the Internet is quickly becoming learners’ chief information resource.
The Internet’s extensive scope, accessibility, and openness has drawbacks. In our experience, very few online authors, Web site designers, and other information providers configure online information in ways that promote or, at least, don’t interfere with learning processes. (see Mayer, 2005, for a compendium of these principles.) Our informal survey of Internet information sources shows that the accuracy and reliability of information varies wildly, and that empirically validated guidelines for promoting learning are rarely evident with respect to the organization and layout of information, adjuncts (summaries, tables, figures, etc.), cues (e.g., font styles), and other widely researched features of instructional design. Compounding these flaws, some information sources overuse features that spike superficial appeal at likely cost to promoting deep understanding. As well, the sheer scope of information and its unsystematic cataloguing substantially increases the challenge learners face to select, coordinate, and synthesize information from hundreds of thousands of potential sources. In this context, learners face an intimidating task. They must simultaneously be skilled librarians, content appraisers, curriculum organizers, self-teachers, and learning skills specialists. Skills they need to succeed are underdeveloped (Nist & Holschuh, 2000; Pressley, Yokoi, van Meter, Van Etten, & Freebern, 1997). Thus, in an already cognitively demanding situation, learners also should work on improving learning skills. In short, learners seeking to learn from information resources in the Internet must excel at productively self-regulating learning.
Unfortunately, learners have a high probability of failing at this task. Tens of thousands of experiments over more than a century of research in educational psychology validate at least one clear, generalizable, and powerful finding: Learners who participate in unstructured control groups or “business as usual” comparison groups studying information sources that are not carefully instructionally designed and who have only accumulated experience to guide learning fare poorly compared to learners who participate in treatments designed by researchers. This disadvantage for “learning as usual” is particularly disconcerting because most of these less successful participants in research have been undergraduates with the “benefit” of 12–16 years of formal education!
We foresee two fundamentally different ways to address this challenge for learners foraging for knowledge in the Internet. One is to develop software technologies that can intelligently intervene to help learners compensate for deficits in the instructional design of information they locate and in underdeveloped skills for learning. Other chapters in this Handbook report advances on this front. A second approach is to provide learners with tools they can use to carry out a progressive program of personal research that helps them productively self-regulate learning so they become more effective at learning. To set the stage for this second approach, we first sketch a model of self-regulated learning (SRL) and its empirical support for self-improving learning.
Theory
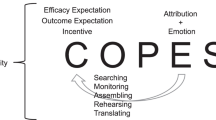
SRL is a cognitively and motivationally active approach to learning. We posit learners engage in four weakly sequenced and recursive phases of cognitive and behavioral activity (Winne, 2011; Winne & Hadwin, 1998; see Fig. 20.1).

Winne and Hadwin’s 4-phase model of self-regulated learning. Reprinted with permission from Winne, P. H., & Hadwin, A. F. (1998). Studying as self-regulated learning. In D. J. Hacker, J. Dunlosky, & A. C. Graesser (Ed.), Metacognition in educational theory and practice (pp. 277–304). Mahwah, NJ: Lawrence Erlbaum Associates
In phase 1, a learner surveys features of an assigned (or self-chosen) task as well as the environment surrounding it. The environment includes external conditions—e.g., standards a teacher will use to grade a project, resources such as lexicons and search engines—and internal conditions—e.g., interest in the topic, self-efficacy, and tactics the learner for studying information. The result of this survey is raw materials from which the learner constructs an understanding of the task as it is first presented and a string of updated states of that task as work progresses. Without accurate perceptions of tasks, academic performance suffers (Miller & Hadwin, 2010).
In phase 2, the learner sets goals and, conditional on them, selects and organizes learning tactics to forge a provisional plan for reaching goals. Setting goals with enough specificity to guide frequent metacognitive monitoring and control is a challenging task. It requires learners to have accurate perceptions about a task’s features plus skill to break distal goals into specific, measurable, achieivable, proximial and action-oriented standards that can be monitored and potentially revised on an ongoing basis (Webster, Helm, Hadwin, Gendron, & Miller, 2010). Choosing how to approach goals is cognitively demanding. Theoretically, it involves (a) forecasting products that tactics can create (outcome expectations), (b) estimating the value of each outcome (its incentive), (c) assessing efficacy for carrying out each tactic and the overall plan (self-efficacy), (d) considering attributions for results and the affect(s) linked to attributions (e.g., attributing success to ability is rewarding but attributing failure to ability is punishing), and (e) judging the marginal utility of choosing one versus another plan (see Winne, 1997; Winne & Marx, 1989).
In phase 3, the learner initiates work on the task. As work unfolds, the learner metacognitively monitors progress relative to (a) subgoals and (b) the plan generated in phase 2. Metacognitive control may be exercised to make minor adjustments on the fly. Learners are not particularly adept at choosing and adapting tactics to adress specific challenges they encounter (Hadwin, Webster, Helm, McCardle, & Gendron, 2010; McCardle et al., 2010).
In phase 4, the learner takes a wide view of phases 1 through 3 to consider large-scale changes in the definition of the task, the goals and plans for reaching them, and the nature of interactions with resources to get the task done. This is perhaps the most challenging phase in the self-regulatory cycle. It requires synthesizing information within as well as across studying events, then systematically investigating the root source of learning problems. Students are challenged to systematically analyze their learning even within one academic task that spans multiple studying events (Hadwin, 2000). Furthermore, when learners neglect to recognize patterns in the match of tactics to challenges in studying, maladaptive regulation patterns can emerge and motivation may be undermined (Hadwin, Webster et al., 2010).
Throughout each phase and not just in phase 3, the active learner metacognitively monitors processes and results, and may exercise metacognitive control to make changes. Because the learner can “jump” to any phase from any other phase, or choose to revise the same phase, we theorize that work on a task need not unfold serially—phases of SRL are weakly sequenced and can generate information for any other phase. SRL is recursive.
Research on the Model of SRL
Work on SRL in academic contexts emerged in the 1980s growing mainly from studies investigating learning strategies. Two important findings were established in that seminal research. First, learners could be taught learning tacticsFootnote 1—methods that built comprehension of text, self-questioning techniques, and so forth—and, as a result, they learned more than peers not taught these cognitive tools (cf. Hadwin & Winne, 1996; Hattie, Biggs, & Purdie, 1996). Second, after learners had acquired tactics and experienced success using those tactics, they infrequently transferred or generalized use beyond the training context or when encouragements to use the tactics were withdrawn (see Zimmerman, 2008). This invited theorizing to explain why learners did not persist in using tactics they could use and had personally experienced to benefit learning.
The second of these findings makes clear an obvious but previously slippery fact: learners are agents. They choose how they will learn. Beyond recognizing agency, however, the question of how and why learners choose tactics for learning—how they self-regulate learning—became a critical issue.
Greene and Azevedo (2007) examined a broad sample of empirical work in an incisive theoretical review of research related to our 4-phase model of SRL. Their analysis provides warrants for our model overall as well as many of its specifics. Greene and Azevedo also identified a few key points where more research is needed to clarify and test our model.
Three Obstacles to Improving Learningon One’s Own
For reasons not yet clear, learners are unreliable observers of (a) features of tasks that should guide planning about how to accomplish tasks (Hadwin, Oshige, Miller, & Wild, 2009; Miller, 2009; Oshige, 2009) and (b) tactics they use in learning (see Winne & Jamieson-Noel, 2002; Winne, Jamieson-Noel, & Muis, 2002; Winne & Perry, 2000). Except in social settings where a peer or teacher can supplement data that learners themselves collect, having unreliable data inhibits productive SRL because decisions about how to adapt learning are based on inaccurate output from metacognitive monitoring.
Second, when learners try to use learning tactics that were only recently introduced or tactics they have not practiced extensively—that is, when tactics are not automated—learners are likely to experience a utilization deficiency (Bjorklund, Miller, Coyle, & Slawinski, 1997). A utilization deficiency is a situation where a learning tactic would be effective if the learner chose to use it under appropriate conditions and applied it skillfully. But, when conditions are not appropriate or the learner’s skill with the tactic is not well developed, achievement suffers and learners understandably are less motivated to continue using the tactic. As a result, they may abandon a tactic that, under less demanding circumstances or with practice, could become an effective tool for learning.
Third, earlier studies in which learners (a) were taught learning tactics and (b) had opportunity to observe that the tactics improved their achievement also document that learners faltered in transferring tactics (see Zimmerman, 2008). Perhaps learners perceived insufficient incentive to apply the extra effort to use these tactics outside the focused context of research. Perhaps they judged the tactics were too complicated or they were unsure whether tactics were appropriate in new situations that differed from the context in which they were learned and practiced. Or, perhaps learners were able to use the tactics in the research context mainly because, unlike the unrestrained Internet, researchers carefully structured materials and managed other factors in the external environment so extraneous cognitive load was limited because this enhances the experiment’s sensitivity to detect what the researchers were investigating.
Implications of the Model and Related Research
In each phase of SRL, learners seek out and process data that are input to metacognitive monitoring. Topics monitored are factors they believe affect learning—e.g., effort applied, complexity of the task, familiarity with content, perceptions of ability, etc. (e.g., see Koriat, Ma’ayan, & Nussinson, 2006)—along with attributes they perceive about the state of their work—degree of completion, quality of products, consequences likely to be experienced, etc. In phase 1, data that describe conditions in the external environment and data each learner perceives about her or his internal cognitive, motivational and affective factors are raw materials for developing an understanding of tasks at hand. In the other phases of SRL, learners gather data about qualities of processes and products that metacognitive monitoring compares to goals for processes and products. In cases where a learner’s current toolkit of learning tactics is not sufficient, the learner may seek out information about new tactics that might help to make minor adjustments on-the-fly in phase 3 of SRL or, if necessary, to reformulate how they approach learning in a major way in phase 4.
In short, without reliable, revealing and relevant data that support making valid inferences about all four phases of SRL, learners will be handicapped. But data can be hard to come by. Fine-grained records that describe how learning unfolds are not a natural byproduct of “getting the work done.” Moreover, learners often overlook data. They are not clear that data are available. For example, we have never encountered a student who explicitly kept track of whether information they highlighted as they studied was more memorable than material they did not highlight. While some recognized the possibility to record and analyze these data, effort estimated to carry out this “personal research project” (Winne, 2010b) was too great.
In this context, we suggest learners could profit if software tools helped them identify, access and process data about the environment and how a learning task is situated within it, their goals, how they study, and what happens when they make minor or occasionally major adjustments to learning tactics. Next we describe a software environment, nStudy, that we and colleagues designed and implemented to help learners at the same time it gathers extensive data that researchers want for their work on learning and SRL.
nStudy
nStudy (Winne, Hadwin, & Beaudoin, 2010) is a Web application that runs in the Firefox Web browser. It was designed primarily as a tool for gathering fine-grained, time-stamped data about operations learners apply to information as they study online materials. Several features of nStudy’s toolkit also were designed to leverage well-established principles that research shows can improve learning.
The Browser and Linking Tools
nStudy displays HTML content that an instructor or researcher designs, or that is available in the Internet. Once learners access a Web page using its universal resource locator (URL), they can operate on information they find there. Each operation builds a link between specific information a learner selects on the Web page and other nStudy tools. As the learner constructs links, nStudy accumulates titles for each linked tool in a table that is organized by the kind of tool to which each information selection is linked.
Tags
To tag information in a Web page, the learner selects target text, mod-clicksFootnote 2 to expose a contextual popup menu and chooses a tagging option. In Fig. 20.2, in addition to a universally available generic tag titled Highlight, the contextual menu shows the five tags the learner has most recently used. In Fig. 20.2, these are as follows: Can do, Can’t do, Fallacy, funny, and is this a learning objective. A Tags… option allows the learner to review all tags that have been constructed before assigning a particular tag, and to create new tags. Tagging the selected text formats it to have a colored background, per the learner’s preferences, and posts the selection, called a quote, to a panel at left. The panel shows quotes for all the kinds of links the learner has forged to (a) quotes in this Web page or to (b) the bookmark that addresses the Web page as a whole, as well as terms appearing in the window (discussed later). Double clicking on an item in the panel opens the window containing its information.

nStudy browser, table of quotes, and linking tools
Notes and Terms
Learners can annotate quotes and bookmarks to Web pages by creating notes and terms. Figure 20.3 shows a note. nStudy assigns new notes a default title of untitled, which invites learners to change it to a meaningful description. Characterizing information by classifying it is a form of generative processing that promotes learning (Wittrock, 2010).

A basic note in nStudy
For every note, nStudy automatically records the quote the learner selected in the browser, if there is one, and provides a link to the source using the bookmark’s title. On making a new note, the learner chooses a schema for organizing information in the annotation by selecting an option from the dropdown Select Form. A basic note form is provided with a single text field: Description. As Fig. 20.4 shows, researchers and learners can customize any note’s form to adapt a schema for an annotation that satisfies particular standards. Forms can be a one off for use in only one particular note or saved for future use. A variety of fields are available to create forms using a drag-and-drop operation. In the properties tab (not shown), properties of the field can be defined such as end points for a slider and text describing options in a combobox.

An nStudy note showing a form and the editor for modifying and creating new forms that operationalize new schemas for notes
The researcher or learner can create terms to build a lexicon of foundational concepts in the domain of study. Terms use a single form including three fields: title, quotes, and description (see Fig. 20.5).

An nStudy term
Terms and Termnet
Whenever the learner opens a browser, note, or term window, nStudy surveys its contents to identify terms appearing in any field and lists each term in the left panel under Terms Used. This list displays the subset of all key concepts in the larger domain of study that appear in the window in which the learner is currently working.
Learners often work nearly simultaneously with several windows. To help conceptualize how key concepts form bundles of information, any term that appears in any window the learner has open is shown in the Termnet window (see Fig. 20.6). The Termnet structures its node-link display using a simple semantic relation: if the description of one term used another term, a link is built between two terms. Literally, the link represents an “in terms of …” relation. For example, suppose “working memory” is a term. If another term titled “cognitive load” is described as “the degree to which working memory is challenged by factors that are intrinsic, germane and extraneous to mastering a learning task” nStudy will link the term “cognitive load” to the term “working memory.”

An nStudy Termnet showing terms used in all windows currently open
Other nStudy Tools
Each learner has a private workspace. Several learners can collaborate in a shared workspace where each has full privileges to introduce, link, edit and delete information. Information items can be easily exchanged across workspaces if learners have a peer’s user name. This creates opportunities for three forms of computer-supported collaborative learning: (a) sequential collaboration where work is circulated to and augmented by team members; (b) convergent collaboration where each members’ work is exported from individual workspaces into a shared workspace where it is compiled and organized by the team; and (c) emergent collaboration in a shared workspace where all collaborative planning and work occurs.
A Chat tool allows learners to discuss content synchronously online. It affords opportunities for collaborators (and researchers) to experiment with varying architectures for synchronous collaboration by providing two dropdown lists configured by a researcher or instructor where learners can choose (a) a role and (b) view and enter into the chat any of several prompts that align to each role. For example, a learner may choose among a set of cogntive roles (e.g., forecaster, summarizer), a set of metacognitive roles (e.g., monitor, planner, evaluator), or a set of functional roles (e.g., recorder, leader). Corresponding prompts help collaborators take on a role in the chat. For example, a planner might have prompts, such as: What steps should we follow? What is our goal for this part? Roles and prompts can alert students to co-regulate one another (“Do you have a plan?” “I think you might be a little off track.”) or jointly share regulation (“What is our main goal?” “Are we meeting our goal?”) Chats are saved and can be annotated like a Web page. Thus, they become recoverable information resources for future tasks, including serving as models for collaboration upon which to improve.
Shared workspaces, the ability to exchange objects across workspaces and chats that can be structured by roles and prompts create opportunities for students to self-regulate, to co-regulate each other’s work, and to share regulation (Hadwin, Oshige, Gress, & Winne, 2010). nStudy does not dictate features of regulation but supports and implicitly guides those events. Trace data about learners’ activities advance research on collaboration and regulation by revealing: (a) products created by solo and collaborative work that are metacognitively monitored, (b) standards used in metacognitive monitoring, (c) operations controlled or regulated and (d) conditions under which regulation occurs (see Winne, Hadwin, & Perry, 2013).
In nStudy’s Concept Map window, learners can build maps from scratch by creating notes, terms, bookmarks and other nStudy items, then linking, grouping and spatially arranging them. From within any of nStudy’s information items, e.g., a note, a concept map of that item and other items linked to it can be constructed by clicking a button in the toolbar, Map.
In nStudy’s Document window, learners can compose essays, poetry, lab reports and other text documents using rich text (HTML) formatting tools. Selections within a document can be annotated like a browser. Also, a basic difference tool is available to track changes across versions of a document.
The Library is a table that lists every information item within a workspace (see Fig. 20.7). The table can be filtered by (a) type of information item, (b) folders into which items are organized, (c) tags applied to items, as well as various metadata, such as: creator, last editor, date modified, and so on. A search tool is available to identify items that have particular information in titles, content, or both. The learner can operate on one or a set of several items by selecting, mod-clicking to expose a contextual menu and choosing a desired operator.

nStudy’s Library and Operators
Data Logs
As the learner operates on information using nStudy’s tools, the software unobtrusively logs fine-grained data: which window has focus (is active), what its title is, what information was selected, when the contextual menu was exposed, which operator is selected from the menu, and so forth. Each low-level entry in the log is time stamped to the millisecond (as accurately as the computer chip’s cycle permits) to represent every observable operation the learner applied to information in a study session plus the information on which each operation was applied. In nStudy’s data analysis module, patterns of these very low level events are organized into “human-level” events like: make new note, review term, modify concept map and so forth. In effect, these organized data instantiate a time-sequenced script that describes which tactics a learner applied to which information and, by looking backward along the timeline for a chosen number of events, the context for any particular event.
Measurements
Trace data are performance-based data learners generate unobtrusively as they apply cognitive and metacognitive operations to information a learner selects (Winne, 1982; Winne, 2010a). nStudy was designed to record extensive, fine-grained, time-stamped traces without intruding on learners’ tasks other than by affording them choices among nStudy’s tools. In contrast to think aloud and self-report data, trace data are not degraded by learners’ unknown sampling of experience, biases in their verbal expression, temporal distance from actual events and other factors that may degrade the accuracy and completeness of learners’ recall, perceptions and interpretations about how they learn.
Trace data can be analyzed in multiple ways and articulated with other data to paint a fuller picture of how learners study and learn (see Winne, Zhou, & Egan, 2010). For example, nStudy notes that offer learners a form for describing goals and a slider for recording an estimate of success can record whether learners explicitly set goals and what goals they set. A simple count of goal notes can index a learner’s propensity to set goals. Because a trace log is a full record of a learner’s observable tool-supported interactions with content, it can be analyzed to identify contexts that (a) precede a learner’s creation of goals and (b) prompt the learner to revisit goals to adjust estimate of success.
Trace data also afford opportunities to measure the presence and qualities of learning strategies by constructing a transition matrix across traces and then a graph of transitions (see Fig. 20.8). Briefly, the transition matrix records tallies that signify a row event is followed by a column event (e.g., A is followed by B) and, after recording a tally, B is the event to be followed by another event (e.g., B is followed by D). Patterns of traces can then be quantified for properties, such as degree of regularity of the pattern, the congruence of one pattern to another, and whether specific neighborhoods of the graph play the same role relative to the graph as a whole (see Winne et al., 2002). This approach to analyzing trace data allows researchers to characterize qualities of a learner’s activity in terms such as the “shape” of learning strategies (linear, cyclical, branching, etc.), levels of activity, and novelty or repetitiveness of responses to interventions or unexpected events. Hadwin, Nesbit, Jamieson-Noel, Code, and Winne (2007) applied this form of analysis to describe learners’ levels and forms of cognitive and metacognitive activity in studying, such as the variability in a learner’s use of tactics and the emphasis a learner placed on metacognitive monitoring.

A trace sequence, its transition matrix, and a graph of the pattern of traces
Interventions
nStudy’s browser, terms, notes, and documents are a vehicles for instructional designers and researchers to provide learners with HTML and rich text content that operationalize various kinds of interventions. For example, hyperlinks in HTML Web pages can define a structure of navigation. Forms designed for notes can provide learners with schemas for arguments or self-generated explanations. Semantic and syntactic properties can be varied in descriptions for provided terms. Questions, designs for headings, advance organizers and typography (e.g., bullet versus number lists; bolding) can be implemented in several of nStudy’s tools.
On the horizon are tools that will extend nStudy into the arenas of (a) learner-driven interactions that directly express SRL and (b) adaptive tutoring.
SRL as a Program of Personal Research
When learners exercise metacognitive control, theory specifies they choose a particular tactic because, in part, they predict it will generate a particular result. For example, learners may believe that highlighting is a form of rehearsal that increases recall of material they highlight. These expectations are hypotheses about relations between learning events and outcomes. Each instantiation of metacognitive control to highlight information generates data to test the hypothesis. Over the span of a school term or an undergraduate course, learners could generate expansive data in a longitudinal field trial to discover “What works?”
We conjecture that SRL is often less productive than it might be because learners are neither trained to research their learning nor do they have easy access to data and tools for analyzing data. Learners could profit from tools that support a program of personal research on learning. For example, suppose a learner is interested to research whether learning is better supported by taking basic notes or notes that use forms for recording information according to particular schemas. Suppose in a review exercise, the learner links each test item to all the notes relevant to that item. Coupled with the log of studying events, it would be possible to analyze achievement as a function of annotations made using the basic form versus tailored forms. While this is a very simple example, the principle has broad scope. Supplemented with tools for analyzing trace data that nStudy records, a learner could examine the complete population of learning activities bearing on how learning events relate to achievement, as well as other dimensions, such as efficiency, interest in content, and so forth.
Just-in-Time Interventions
Suppose the learner has already investigated several research questions about how different study tactics affect learning. Each expression of kinds of traces that the learner researches can be transformed into a rule to identify those traces in future. When the learner records the results of self-focused research on learning—e.g., using notes with forms tailored to tasks promotes learning more than using basic notes—nStudy could be extended to monitor how the student uses basic notes and notes with tailored forms. Should the learner study using only basic notes that exceed some count (e.g., four successive basic notes), nStudy could offer a hint about studying: “Would it be appropriate to develop a note form for this content?” Such just-in-time hints are a subtle form of feedback about how the learner is studying that may elevate and focus metacognitive monitoring, as well as remind the learner of tactics for learning that, in the learner’s personal history, may have a better chance to help reach goals. Importantly, these hints create opportunities for learners to regulate their learning by deciding whether (and how) to adapt learning after the co-regulatory prompt. Leaving decisions in the hands of learners is essential for learning to be self-regulated or co-regulated where learners productively exchange information about adapting their reciprocal and interdependent activities in collaborative tasks (Winne et al., 2013).
Challenges
Our design goal for nStudy was, on the one hand, to collect extensive, fine-grained, time-stamped data that trace cognitive, metacognitive, and motivated actions learners apply to specific information as they study; and, on the other hand, to afford learners a wide range of choices for expressing these learning-related events by offering tools they might want to use and that did not require extensive instruction or necessitate major changes in common studying activities. As one example, consider highlighting. A highlight is a nonspecific tag that is nearly ubiquitous among learners. nStudy extended this affordance by providing a tool with which learners could create and apply any number of specific tags. We reasoned that applying more specific tags traces metacognitive engagement in the form of using multiple standards—the tags—to monitor information’s meaning (e.g., “general law” or “main point”) and possible uses (e.g., “review for test” or “evidence for hypothesis”). As well, when learners create new tags, this is strong evidence for metacognitive monitoring that a current set of tags is insufficient to achieve goals. Moreover, because learners do not naturally highlight very effectively (e.g., Bell & Limber, 2010) and, as might occur in a workspace shared among group members, preexisting highlighting can impair metacognition (Gier, Kreiner, & Natz-Gonzalez, 2009). Thus, nStudy’s design amplifies opportunities for learners to engage in SRL by providing a desirable difficulty that potentially enriches encoding (Thomas & McDaniel, 2007).
A challenge in this regard arises because desirable difficulties require more effort of learners and, in a rational sense, learners strive to balance effort against returns—as we described earlier, we hypothesize they seek to optimize utility. Thus, nStudy affords opportunities for learners to explore the relative utilities of a wide variety of study tactics. But we conjecture we conjecture affordance alone is insufficient. This challenge leads to a major focus for future work, which we describe next.
Early usability testing revealed that learners commonly avoided these cognitively effortful judgments about tags—they just wanted to highlight. For some, marking/highlighting was a first step in a more complex strategy in which they would later return to highlighted material and engage more generative processing. Other learners perceived the effort of classifying marked text outweighed its potential utility. As designers we were confronted with a challenge. If we created the opportunity to simply mark text, we might not see the list of potential ways to classify information they were highlighting; but, if we forced them to classify, they might abandon the tool because it was effortful or ill-matched to their strategic plan. We settled on a middle ground, where learners could simply select “highlight” from the top of a list of recent tags and repeat that “fast mark” throughout their studying. In this way, students were invited to review the list of possible ways of tagging their selections but not forced to do that.
Future
Space constraints prevent fully addressing how nStudy and research can evolve. Here, we highlight a particular issue arising from the preceding section and briefly introduce several avenues for future work.
Feedback About Operations That Generate Achievements
Feedback is a powerful influence on learning (Butler & Winne, 1995; Hattie & Timperley, 2007). Many of today’s state-of-the-art software systems provide feedback about achievements in the domain learners study, such as physics or ecology. However, to our knowledge, no software learning system offer learners feedback about how they learn using any of the formats for knowledge that can represent study tactics and learning strategies: conditional, declarative and procedural (Winne, 2010b). nStudy is poised to accomplish this using the extensive, fine-grained, time-stamped traces it logs about how a learner operates on information in nStudy’s environment.
We are planning supplements to nStudy’s tools that would allow learners to use a controlled vocabulary to ask and receive answers to questions, such as: “How did I study differently for concepts A, B, and C that I know well compared to concepts D, E, and F that I know less well?” nStudy’s response might be a graphical display of traces like that displayed in Fig. 20.8 that shows not merely the unconditional frequency of various operations but conditional (contextual) relations among binary pairs of operations, as well as an overall “strategy.” This sort of question could be elaborated include a time dimension—“… and how did I change my strategy in November compared to September?” A response would show different graphs that depict strategy in a visual way plus an index, ranging from 0 to 1, that quantifies the degree of change. We believe this kind of process feedback is a key to scaffolding productive SRL.
A Grander Vision: The Research Co-Op
nStudy is a shell—any content that can be represented in an HTML format is content that learners can use nStudy to study. All learners need to use nStudy is the Firefox Web browser and an account on nStudy’s server. The data that nStudy gathers about how learners study, regardless of the subject they study or their age, is in a single format. These features afford the research community expansive latitude to pursue research across disciplines and many levels of education yet meld their research in ways not heretofore possible. We echo Winne’s (2006) argument that widespread adoption of systems like nStudy could significantly accelerate research’s production of authentic, useful results. A simple and proven model might be to form a “research co-op” bearing modest resemblance to retail co-op enterprises. Users and researchers, for modest fees that support infrastructure, could avail themselves of massive data warehouses that would support data mining for principles about how to promote learning. Modifications to nStudy that might be suggested from this work can be distributed by upgrading the nStudy software once, on the server, which makes them immediately available at no additional cost.
Supplementing nStudy’s data warehouse with other forms of data, such as measures of achievement and measures of what learners describe about themselves and their approaches to learning (self-reports of motivational constructs, self-reports about studying temporally removed from actual studying, surveys and inventories, and self-reports gathered as studying unfolds as punctuated narrative, i.e., think aloud) would create a resource that we predict would immediately and importantly accelerate harvesting fruit of research on learning.
Notes
- 1.
Researchers far more commonly use the term strategies in this regard but we perceive these cognitive scripts typically provide meager opportunity for strategic judgment; see Winne (2011). Hence, we use a term that reflects a more straightforward If–Then architecture with less complexity, namely, tactics.
- 2.
A mod-click is a right-click in the Windows operating systems and a control-click in the Apple operating system.
References
Bell, K. E., & Limber, J. E. (2010). Reading skill, textbook marking, and course performance. Literacy Research and Instruction, 49, 56–67.
Bjorklund, D. F., Miller, P. H., Coyle, T. R., & Slawinski, J. L. (1997). Instructing children to use memory strategies: Evidence of utilization deficiencies in memory training studies. Developmental Review, 17, 411–442.
Butler, D. L., & Winne, P. H. (1995). Feedback and self-regulated learning: A theoretical synthesis. Review of Educational Research, 65, 245–281.
Gier, V. S., Kreiner, D. S., & Natz-Gonzalez, A. (2009). Harmful effects of preexisting inappropriate highlighting on reading comprehension and metacognitive accuracy. The Journal of General Psychology, 136, 287–300.
Greene, J. A., & Azevedo, R. (2007). A theoretical review of Winne and Hadwin’s model of self-regulated learning: new perspectives and directions. Review of Educational Research, 77, 334–372.
Hadwin, A. F. (2000). Building a case for self-regulating as a socially constructed phenomenon. Unpublished doctoral dissertation, Simon Fraser University, Burnaby, British Columbia, Canada.
Hadwin, A. F., Nesbit, J. C., Code, J., Jamieson-Noel, D. L., & Winne, P. H. (2007). Examining trace data to explore self-regulated learning. Metacognition and Learning, 2, 107–124.
Hadwin, A. F., Oshige, M., Gress, C. L. Z., & Winne, P. H. (2010). Innovative ways for using gStudy to orchestrate and research social aspects of self-regulated learning. Computers in Human Behavoir, 26, 794–805.
Hadwin, A. F., Oshige, M., Miller, M., & Wild, P. (2009). Examining student and instructor task perceptions in a complex engineering design task: Paper proceedings presented for the 6th International Conference on Innovation and Practices in Engineering Design and Engineering Education (CDEN/C 2 E 2 ), Hamilton, ON, Canada: McMaster University.
Hadwin, A. F., Webster, E., Helm, S., McCardle, L., & Gendron, A. (2010). Toward the study of intra-individual differences in goal setting and motivation regulation. Paper presented at the Annual meeting of the American Educational Research Association, Denver, CO.
Hadwin, A. F., & Winne, P. H. (1996). Study skills have meager support: A review of recent research on study skills in higher education. Journal of Higher Education, 67, 692–715.
Hattie, J., Biggs, J., & Purdie, N. (1996). Effects of learning skills interventions on student learning: A meta-analysis. Review of Educational Research, 66, 99–136.
Hattie, J., & Timperley, H. (2007). The power of feedback. Review of Educational Research, 77, 81–113.
Koriat, A., Ma’ayan, H., & Nussinson, R. (2006). The intricate relationships between monitoring and control in metacognition: Lessons for the cause-and-effect relation between subjective experience and behavior. Journal of Experimental Psychology. General, 135, 36–69.
Mayer, R. E. (Ed.). (2005). The Cambridge handbook of multimedia learning. New York: Cambridge University Press.
McCardle, L., Miller, M., Gendron, A., Helm, S., Hadwin, A., & Webster, E. (2010). Regulation of motivation: Exploring the link between students’ goals for motivational state and strategy choice in university tasks. Paper presented at the annual meeting of the Canadian Society for the Study of Education. Montreal, QC.
Miller, M. F. W. (2009). Predicting university students’ performance on a complex task: Does task understanding moderate the influence of self-efficacy? Unpublished Master’s thesis. University of Victoria, Victoria, BC, Canada.
Miller, M. F. W., & Hadwin, A. F. (2010). Supporting university success: Examining the influence of explicit and implicit task understanding and self-efficacy on academic performance. Paper presented at the Annual meeting of the Canadian Society for the Study of Education, Montreal, QC.
Nist, S., & Holschuh, J. (2000). Comprehension strategies at the college level. In R. F. Flippo & D. C. Caverly (Eds.), Handbook of college reading and study strategy research (pp. 75–104). Mahwah, NJ: Lawrence Erlbaum Associates.
Oshige, M. (2009). Exploring task understanding in self-regulated learning: Task understanding as a predictor of academic success in undergraduate students. Unpublished Master’s thesis. University of Victoria, Victoria, BC, Canada.
Pressley, M., Yokoi, L., van Meter, P., Van Etten, S., & Freebern, G. (1997). Some of the reasons preparing for exams is so hard: What can be done to make it easier? Educational Psychology Review, 9, 1–38.
Thomas, A. K., & McDaniel, M. A. (2007). Metacomprehension for educationally relevant materials: Dramatic effects of encoding-retrieval interactions. Psychonomic Bulletin & Review, 14, 212–218.
Webster, E., Helm, S., Hadwin, A. F., Gendron, A., & Miller, M. (2010). Academic goals and self-regulated learning: An analysis of changes in goal quality, goal efficacy, and goal attainment over time. Poster presented at the Annual Meeting of the American Educational Research Association, Denver, CO.
Winne, P. H. (1982). Minimizing the black box problem to enhance the validity of theories about instructional effects. Instructional Science, 11, 13–28.
Winne, P. H. (1997). Experimenting to bootstrap self-regulated learning. Journal of Educational Psychology, 89, 397–410.
Winne, P. H. (2006). How software technologies can improve research on learning and bolster school reform. Educational Psychologist, 41, 5–17.
Winne, P. H. (2010a). Improving measurements of self-regulated learning. Educational Psychologist, 45, 267–276.
Winne, P. H. (2010b). Bootstrapping learner’s self-regulated learning. Psychological Test and Assessment Modeling, 52, 472–490.
Winne, P. H. (2011). A cognitive and metacognitive analysis of self-regulated learning. In B. J. Zimmerman & D. H. Schunk (Eds.), Handbook of self-regulation of learning and performance (pp. 15–32). New York: Routledge.
Winne, P. H., & Hadwin, A. F. (1998). Studying as self-regulated learning. In D. J. Hacker, J. Dunlosky, & A. C. Graesser (Eds.), Metacognition in educational theory and practice (pp. 277–304). Mahwah, NJ: Lawrence Erlbaum Associates.
Winne, P. H., Hadwin, A. F., & Beaudoin, L. P. (2010). nStudy: A web application for researching and promoting self-regulated learning (version 2.0) [computer program]. Burnaby, BC, Canada: Simon Fraser University.
Winne, P. H., Hadwin, A. F., & Perry, N. E. (2013). Metacognition and computer-supported collaborative learning. In C. Hmelo-Silver, A. O’Donnell, C. Chan & C. Chinn (Eds.), International handbook of collaborative learning (pp. 462–479). New York: Taylor & Francis.
Winne, P. H., & Jamieson-Noel, D. L. (2002). Exploring students’ calibration of self-reports about study tactics and achievement. Contemporary Educational Psychology, 27, 551–572.
Winne, P. H., Jamieson-Noel, D. L., & Muis, K. (2002). Methodological issues and advances in researching tactics, strategies, and self-regulated learning. In P. R. Pintrich & M. L. Maehr (Eds.), Advances in motivation and achievement: New directions in measures and methods (Vol. 12, pp. 121–155). Greenwich, CT: JAI Press.
Winne, P. H., & Marx, R. W. (1989). A cognitive processing analysis of motivation within classroom tasks. In C. Ames & R. Ames (Eds.), Research on motivation in education (Vol. 3, pp. 223–257). Orlando, FL: Academic.
Winne, P. H., & Perry, N. E. (2000). Measuring self-regulated learning. In M. Boekaerts, P. Pintrich, & M. Zeidner (Eds.), Handbook of self-regulation (pp. 531–566). Orlando, FL: Academic.
Winne, P. H., Zhou, M., & Egan, R. (2010). Assessing self-regulated learning skills. In G. Schraw (Ed.), Assessment of higher-order thinking skills. New York: Routledge.
Wittrock, M. C. (2010). Learning as a generative process. Educational Psychologist, 45, 40–45.
Zimmerman, B. J. (2008). Investigating self-regulation and motivation: Historical background, methodological developments, and future prospects. American Educational Research Journal, 45, 166–183.
Acknowledgments
Support for this research was provided by grants to Philip H. Winne from the Social Sciences and Humanities Research Council of Canada (410-2007-1159 and 512-2003-1012), the Canada Research Chair Program and Simon Fraser University; and to Allyson F. Hadwin and Philip H. Winne from the Social Sciences and Humanities Research Council of Canada (410-2008-0700).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer Science+Business Media New York
About this chapter
Cite this chapter
Winne, P.H., Hadwin, A.F. (2013). nStudy: Tracing and Supporting Self-Regulated Learning in the Internet. In: Azevedo, R., Aleven, V. (eds) International Handbook of Metacognition and Learning Technologies. Springer International Handbooks of Education, vol 28. Springer, New York, NY. https://doi.org/10.1007/978-1-4419-5546-3_20
Download citation
DOI: https://doi.org/10.1007/978-1-4419-5546-3_20
Published:
Publisher Name: Springer, New York, NY
Print ISBN: 978-1-4419-5545-6
Online ISBN: 978-1-4419-5546-3
eBook Packages: Humanities, Social Sciences and LawEducation (R0)