
Abstract
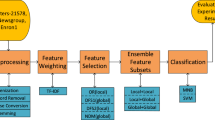
In document-level text mining, feature selection is crucial for lowering ambiguity which in turn enhances classifier performance. The selection of the vital features is crucial, especially for the classification of documents in the morphologically rich Indian regional language Kannada. In this regard, the paper proposes stacked ensemble feature selection method. The proposed method consists of two layers, and it is a heterogeneous ensemble of feature selection methods. In the first layer, Chi-Square and Mutual Information methods are combined. In the second layer, we have XG Boost. These two layers select prominent features and enhance the classifier learning performance. Prominent classifiers like Support Vector Machine (SVM), Multi-Layer Perceptron (MLP), K-Nearest Neighbor (KNN), and Decision Tree (DT) are used in experiments. Further K-Fold experimentations are performed, and their results are analyzed.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3(Mar):1157–1182
Blum AL, Langley P (1997) Selection of relevant features and examples in machine learning. Artif Intell 97(1–2):245–271
Hsu HH, Hsieh CW, Lu MD (2011) Hybrid feature selection by combining filters and wrappers. Expert Syst Appl 38(7):8144–8150
Hoque N, Singh M, Bhattacharyya DK (2018) EFS-MI: an ensemble feature selection method for classification: an ensemble feature selection method. Complex Intell Syst 4:105–118
Hashemi A, Dowlatshahi MB, Nezamabadi-Pour H (2021) A bipartite matching-based feature selection for multi-label learning. Int J Mach Learn Cybern 12:459–475
Hashemi A, Dowlatshahi MB, Nezamabadi-pour H (2021) An efficient Pareto-based feature selection algorithm for multi-label classification. Inf Sci 581:428–447
Hashemi A, Dowlatshahi MB (2020) MLCR: a fast multi-label feature selection method based on K-means and L2-norm. In: 2020 25th International computer conference, computer society of Iran (CSICC). IEEE, pp 1–7
Bolón-Canedo V, Alonso-Betanzos A (2019) Ensembles for feature selection: a review and future trends. Inf Fusion 52:1–12
Tian Y, Zhang J, Wang J, Geng Y, Wang X (2020) Robust human activity recognition using single accelerometer via wavelet energy spectrum features and ensemble feature selection. Syst Sci Control Eng 8(1):83–96
Wang H, He C, Li Z (2020) A new ensemble feature selection approach based on genetic algorithm. Soft Comput 24:15811–15820
Seijo-Pardo B, Porto-Díaz I, Bolón-Canedo V, Alonso-Betanzos A (2017) Ensemble feature selection: homogeneous and heterogeneous approaches. Knowl-Based Syst 118:124–139
Seijo-Pardo B, Bolón-Canedo V, Alonso-Betanzos A (2019) On developing an automatic threshold applied to feature selection ensembles. Inf Fusion 45:227–245
Bolón-Canedo V, Sánchez-Maroño N, Alonso-Betanzos A (2012) An ensemble of filters and classifiers for microarray data classification. Pattern Recogn 45(1):531–539
Guru DS, Suhil M, Pavithra SK, Priya GR (2018) Ensemble of feature selection methods for text classification: an analytical study. In: Intelligent systems design and applications: 17th international conference on intelligent systems design and applications (ISDA 2017) held in Delhi, India, 14–16 Dec 2017. Springer International Publishing, pp 337–349
Ben Brahim A, Limam M (2018) Ensemble feature selection for high dimensional data: a new method and a comparative study. Adv Data Anal Classif 12:937–952
Ansari MZ, Ahmad T, Fatima A (2020) Feature selection on noisy twitter short text messages for language identification. arXiv preprint arXiv:2007.05727
Gandhi H, Attar V (2022) Sentiment of primary features in aspect based sentiment analysis of Hindi reviews. In: Applied computational technologies: proceedings of ICCET 2022. Springer Nature Singapore, Singapore, pp 567–578
Anand M, Sahay KB, Ahmed MA, Sultan D, Chandan RR, Singh B (2023) Deep learning and natural language processing in computation for offensive language detection in online social networks by feature selection and ensemble classification techniques. Theoret Comput Sci 943:203–218
Chandrika CP, Kallimani JS (2022) Authorship attribution for Kannada text using profile based approach. In: Proceedings of the 2nd international conference on recent trends in machine learning, IoT, smart cities and applications: ICMISC 2021. Springer Singapore, pp 679–688
Yang W, Sun B, Liu B (2022) Basic profiling extraction based on XGBoost. In: CCKS 2021-evaluation track: 6th China conference on knowledge graph and semantic computing, CCKS 2021, Guangzhou, China, 25–26 Dec, 2021, Revised selected papers. Springer Singapore, Singapore, pp 52–58
Zhou T, Zhao H, Zhang X (2022) Keyword extraction based on random forest and XGBoost-an example of fraud judgment document. In: 2022 European conference on natural language processing and information retrieval (ECNLPIR). IEEE, pp 17–22
Kasturi Rangan R, Harish BS (2023) KDC: new dataset for Kannada document categorization. In: Machine learning, image processing, network security and data sciences: select proceedings of 3rd international conference on MIND 2021. Singapore, Springer Nature Singapore, pp 633–645
Rangan RK, Harish BS (2021) Kannada document classification using unicode term encoding over vector space. In: Recent advances in artificial intelligence and data engineering: select proceedings of AIDE 2020, vol 1386, p 387
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I (2017) Attention is all you need. In: Advances in neural information processing systems, vol 30
Bahassine S, Madani A, Al-Sarem M, Kissi M (2020) Feature selection using an improved Chi-square for Arabic text classification. J King Saud Univ Comput Inf Sci 32(2):225–231
Kumar HK, Harish BS (2018) Sarcasm classification: a novel approach by using content based feature selection method. Procedia Comput Sci 143:378–386
Chen T, Guestrin C (2016) Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pp 785–794
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Rangan, R.K., Harish, B.S., Roopa, C.K. (2024). Stacked Ensemble Feature Selection Method for Kannada Documents Categorization. In: Swaroop, A., Polkowski, Z., Correia, S.D., Virdee, B. (eds) Proceedings of Data Analytics and Management. ICDAM 2023. Lecture Notes in Networks and Systems, vol 786. Springer, Singapore. https://doi.org/10.1007/978-981-99-6547-2_33
Download citation
DOI: https://doi.org/10.1007/978-981-99-6547-2_33
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-6546-5
Online ISBN: 978-981-99-6547-2
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)