
Abstract
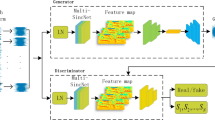
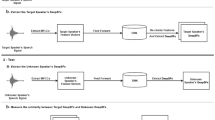
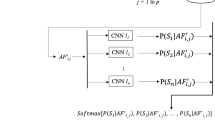
Deep learning algorithms have significantly prevailed as a stand-in for i-vector in numerous applications such as speaker recognition, diarization, segmentation and verification. CNN when fed directly with raw voice fragments have resulted in propitious outcomes. Instead of using conventional hand-crafted features, CNNs learn low-level speech patterns using waveforms, which allows the network to better represent crucial narrow band speaker properties like pitch and formants. These narrow band features are less susceptible to surrounding noise. The design of neural network becomes significant to achieve this purpose. This study suggests the use of SincNet, an unique CNN architecture which enables the first convolutional layer to find deep relevant filters. Band-pass filters are implemented via parameterized sinc functions, on which SincNet is built. The standard CNNs normally learns all elements of each filter, where as the sincnet technique learns only high and low cutoff frequencies directly from raw fed data. This provides a highly compact and effective method to produce a unique filter bank that is precisely tuned for the particular application. Our research on the speaker verification task illustrate that the suggested architecture attains higher speed and performs better than the regular CNN.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others
References
Beigi H, Beigi H (2011) Speaker recognition. Springer
Dehak N, Kenny PJ, Dehak R, Dumouchel P, Ouellet P (2010) Front-end factor analysis for speaker verification. IEEE Trans Audio Speech Lang Process 19(4):788–798
Heaton J (2018) Ian goodfellow, yoshua bengio, and aaron courville: deep learning. The MIT press, p 800. ISBN: 0262035618. Genet Prog Evol Mach 19(1–2):305–307
Kenny P, Stafylakis T, Ouellet P, Gupta V, Alam MJ (2014) Deep neural networks for extracting BAUM-welch statistics for speaker recognition. Odyssey 2014:293–298
Yaman S, Pelecanos JW, Sarikaya R (2012) Bottleneck features for speaker recognition. Odyssey 12:105–108
Variani E, Lei X, McDermott E, Moreno IL, Gonzalez-Dominguez J (2014) Deep neural networks for small footprint text-dependent speaker verification. In: 2014 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 4052–4056
Richardson F, Reynolds D, Dehak N (2015) A unified deep neural network for speaker and language recognition. arXiv preprint arXiv:1504.00923
Zhang C, Koishida K, Hansen JH (2018) Text-independent speaker verification based on triplet convolutional neural network embeddings. IEEE/ACM Trans Audio Speech Lang Process 26(9):1633–1644
Palaz D, Collobert R et al (2015) Analysis of CNN-based speech recognition system using raw speech as input. Technical report, Idiap
Sainath TN, Kingsbury B, Mohamed AR, Ramabhadran B (2013) Learning filter banks within a deep neural network framework. In: 2013 IEEE workshop on automatic speech recognition and understanding. IEEE, pp 297–302
Trigeorgis G, Ringeval F, Brueckner R, Marchi E, Nicolaou MA, Schuller B, Zafeiriou S (2016) Adieu features? End-to-end speech emotion recognition using a deep convolutional recurrent network. In: 2016 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 5200–5204
Muckenhirn H, Doss MM, Marcell S (2018) Towards directly modeling raw speech signal for speaker verification using CNNs. In: 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 4884–4888
Dinkel H, Chen N, Qian Y, Yu K (2017) End-to-end spoofing detection with raw waveform CLDNNs. In: 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 4860–4864
Oord A, Dieleman S, Zen H, Simonyan K, Vinyals O, Graves A, Kalchbrenner N, Senior A, Kavukcuoglu K (2016) Wavenet: a generative model for raw audio. arXiv preprint arXiv:1609.03499
Seki H, Yamamoto K, Nakagawa S (2017) A deep neural network integrated with filterbank learning for speech recognition. In: 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, pp 5480–5484
Haris BC, Pradhan G, Misra A, Prasanna S, Das RK, Sinha R (2012) Multivariability speaker recognition database in Indian scenario. Int J Speech Technol 15:441–453
Carletta J, Ashby S, Bourban S, Flynn M, Guillemot M, Hain T, Kadlec J, Karaiskos V, Kraaij W, Kronenthal M et al (2006) The AMI meeting corpus: a pre-announcement. In: Machine learning for multimodal interaction: second international workshop, MLMI 2005, Edinburgh, UK, 11–13 July 2005, Revised Selected Papers 2. Springer, pp 28–39
Chikkamath S, Nirmala S (2022) Music detection using deep learning with tensorflow. In: ICDSMLA 2020: proceedings of the 2nd international conference on data science, machine learning and applications. Springer, pp 283–291
Chikkamath S, Nirmala S (2021) Melody generation using LSTM and bi-LSTM network. In: 2021 international conference on computational intelligence and computing applications (ICCICA). IEEE, pp 1–6
Ravanelli M, Bengio Y (2018) Speaker recognition from raw waveform with SINCNET. In: 2018 IEEE spoken language technology workshop (SLT). IEEE, pp 1021–1028
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Sanshi, P., Kuruvalli, L.R., Chikkamath, S., Nirmala, R.S. (2023). Deep Learning Framework for Speaker Verification Under Multi Sensor, Multi Lingual and Multi Session Conditions. In: Choudrie, J., Mahalle, P.N., Perumal, T., Joshi, A. (eds) ICT for Intelligent Systems. ICTIS 2023. Smart Innovation, Systems and Technologies, vol 361. Springer, Singapore. https://doi.org/10.1007/978-981-99-3982-4_17
Download citation
DOI: https://doi.org/10.1007/978-981-99-3982-4_17
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-4039-4
Online ISBN: 978-981-99-3982-4
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)