
Abstract
Convolutional simultaneous sparse approximation algorithms are based on the alternating direction approach of multipliers with various sparsity structures. Outdoor VL photos are improved using the NIR images. The NIR images utilised in this study are shown in grayscale and can be combined with the intensity parts of the VL photos, which are typically accessible in red, green, and blue (RGB) format. Using the sparse feature maps with the same supports, we try to approximate the input signals. Utilising two multimodal NIR-VL dictionaries that have already been learned and thus suggested CSSA approach for the problem concerned. An approach for fusing NIR and VL images is based on CSSA and CDL. On the basis of the SSA model, we address the CSSA problem with various sparsity structures as well as the convolutional feature learning problem in multimodal data/signals. We assess the suggested algorithms.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

1 Introduction
Image processing is one of the technologies that has recently experienced significant development. Digital image processing, which is utilised in digital computers, comprises of the modifications that are included in it [1]. Though it primarily focuses on images, the subfield of image processing is known as signals and systems. A common procedure that includes both digital signal processing and image-specific techniques is called digital image processing [2]. The most typical illustration is Adobe Photoshop which is considered as Currently, the most popular tools for processing digital photos.
Digital image processing is the act of processing digital images using a computer. Digital image processing offers fundamental and sophisticated principles for an image processing tutorial [3]. Digital photographs are primarily processed in Adobe Photoshop.
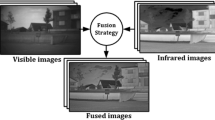
The image fusion technique collects all the essential information from numerous photos and combines it into fewer, usually single, images [4]. This single image is more accurate and instructive than any other image from a single source since it contains all the necessary information. In addition to lowering the amount of data, image fusion strives to provide visuals that are more pertinent and understandable for both human and machine perception [5–7,6,]. The process of combining pertinent information from two or more images into one image is known as multisensor image fusion in computer vision. The input photographs will all be less instructive than the finished image [8, 9]. The expanding array of space-based sensors accessible for uses in remote sensing. Picture fusion can be done in a variety of ways.
2 Literature Survey
2.1 High Dynamic Range Imaging
A remarkably easy way for considerably boosting the dynamic range of practically any imaging system was put out by the researchers [11, 12]. The fundamental idea is to sample the image irradiance's spatial and exposure dimensions simultaneously. Placing an ideal mask next to a traditional image detector array is one of several ways to accomplish this. Adjacent pixels on the detector receive various exposures to the scene due to the mask's pattern of spatially variable transmittance. An effective image reconstruction technique maps the collected image to a high dynamic range image 13. The ultimate result is an imaging system that can produce a significantly greater number of brightness levels and measure a very wide range of scene irradiances, with a minor drop in the number of brightness levels.
2.2 Multi-Exposure Image Fusion
A. Goshtasby developed a technique for combining multiple exposure photos of a still scene shot with a stationary camera to create an image with the most amount of information possible. The technique divides the image domain into uniform blocks and chooses the image inside each block that has the greatest information. Next, monotonically decreasing blending functions with a sum of 1 throughout the entire image domain and centres at the blocks are used to combine the selected images. A gradient-ascent approach is used to calculate the ideal block size and width for the blending functions in order to optimise the amount of information included in the combined image. Finding the image at a specific location that has the most information is the key issue at hand.
2.3 Exposure Fusion
A method for combining a bracketed exposure sequence into a high-quality image without requiring HDR was put out by T. Mertens, J. Kautz, and F. Van Reeth. The acquisition workflow is made easier by skipping the physically-based HDR assembly. This saves time on computation by avoiding camera response curve calibration. Additionally, it permits the sequence to include flash pictures. Utilising straightforward quality indicators like saturation and contrast, this approach combines many exposures. To account for the brightness change in the sequence, this is done in a multi-resolution manner. Using exposure fusion, the desired image sequence is computed. A scalar-valued weight map, which is composed of a collection of quality measurements, directs this procedure. It helps to visualise the input sequence as a collection of pictures.
2.4 Random Walks for Multi-Exposure Image Fusion
The multi-exposure picture fusion problem was approached from a new angle by Rui Shen, Irene Cheng, Jianbo Shi, and Anup Basu. It is thought to be best to strike a balance between the two quality metrics of local contrast and colour consistency using a probabilistic approach. Based on these two metrics, it is computed pixel-by-pixel probabilities that a pixel in the fused image originates from various input images, which are then utilised as fusion weights in the composition step. Local contrast is indicated by the pixel, which is how the fused image is displayed. The colour consistency measure mandates both uniformity with the surrounding natural landscape and consistency within a broad community. This measurement is based on the supposition that neighbouring pixels with comparable colours in the majority of the input images will suggest similar colours.
3 Methods
3.1 Existing Method
The CDL problem can be expressed as follows: minimise D s.t. Dk, D, k = 1 K, where D. Given T sets of N dependent input signals and associated concurrent SRs (and). It is possible to solve problem utilising batch or online CDL methods because it is a common CDL problem. When using online CDL, training samples must be observed sequentially over time, whereas batch CDL requires all training data to be accessible at once. When there are more filters in the dictionary (here K) than there are training samples (here T N), online CDL is also more computationally efficient. The CDL issue can be extended to include learning multimodal convolutional dictionaries if the input signals are multimodal, and the order of modalities is fixed throughout all T sets of training samples. This can be written as n = 1 = 1 = 1 = 1 s.t. D, which has N distinct CDL issues that can be solved. Using the corresponding filters in the multimodal dictionaries, problem can be understood as learning correlated (coupled) characteristics in multimodal data (Fig. 1).

Block diagram
4 Proposed Method
The NIR images are distinguished by high contrast resolutions, which are useful for imaging in low-visibility atmospheric circumstances like fog or haze and for capturing scenes with vegetation. These qualities are utilised to enhance outdoor VL photos using NIR photographs. We provide an NIR-VL image fusion approach based on CSSA and CDL in this section. Both ‘1’ and ‘2,1’ regularizations as well as multimodal dictionaries are used to perform the CSSA. The following list explains each stage of the suggested procedure for merging two identical-sized NIR and VL images (sn and sv, respectively). Due to the NIR images’ greyscale presentation, they can be combined with the intensity components of VL images, which are often provided in using the proposed CSSA technique and two pre-learned multimodal NIR-VL dictionaries, the convolutional SRs Xn and Xv are generated for shn and shv,g, respectively (designated as Dn and Dv). The convolutional SRs are fused using the maxabsolute-value fusion criterion. Fnk and Fvk are fused convolutional SRs that contain only the most significant representation coefficients at each entry. Fvk if |Xvk(I, j)| |Xnk(I, j), otherwise Fvk if |Xnk I j) | > |Xvk I j), otherwise furthermore, the points I j) represent the locations of each pixel in the images shn and shv, whereas | | represents the absolute value of an integer and k = 1 in this example (number of filters in the dictionaries). Then, using the fused greyscale high-resolution component (Figs. 2, 3 and 4).

Visible image

NIR image

Fused image
5 Results
First, a pair of NIR-VL pictures are sparsely approximated using the suggested CSSA algorithms with various sparsity structures. In order to do multifocus and multimodal image fusion tasks, we then apply the suggested methods. The 32 filters of size 8 × 8 in the convolutional dictionaries utilised in the experiments are learned using the online CDL approach. A multifocus picture dataset and an NIR-VL image dataset, each with 10 pairs of images, make up the training data. The RGB-NIR scene dataset and the Lytro dataset, respectively, are used to capture the NIR-VL and multifocus photos. Both visually and through objective evaluation indicators, the fusion results are assessed. The average peak signal-to-noise ratio (PSNR), the structural similarity index (SSIM), average entropy (EN), and the average are the five metrics utilised for objective evaluations.
From the Figs. 5, 6, 7, there are two images: a visible image and an NIR image. The visible image is more amenable to human perception and contains a plethora of textural data. By acquiring considerable thermal radiation data, infrared pictures can be used to emphasise significant targets like cars, people, and other objects even in low light or other extremely hostile situations. An NIR light source is required to create an image since, like visible light, NIR is a reflected energy. During the day, the sun supplies plenty of IR light, but at night, an IR light source is needed to illuminate an area. A final image with more information is obtained when we merge the two input photos, a visible image and an NIR infrared image (Fig. 8, 9, and 10).

Visible image

NIR image

Fused image

Visual image

NIR image

Fused image
To create the fused convolutional SRs, we fuse the convolutional SRs (with identical supports) using the elementwise maximum absolute value rule. The other steps of the two algorithms are identical. The acquired fusion findings show that using CSSA results in significant gains in terms of greater contrast resolutions and better fusing of multifocus edges (boundaries where one side is in focus, and the other side is out of focus). The figure depicts an example of fusion results obtained using the two procedures. The objective evaluation results in Table II also show that CSSA increases the overall performance of the CSA-based multifocus image fusion approach.
6 Conclusion
Based on the alternating direction approach of multipliers, algorithms for convolutional simultaneous sparse approximation with diverse sparsity structures have been presented. We tested the efficacy of the suggested approaches by applying them to two distinct types of picture fusion challenges and comparing the results to those of current image fusion methods. A novel near-infrared and visible light picture fusion approach based on convolutional simultaneous sparse approximation was suggested in particular.
References
Veshki FG, Vorobyov SA (2022) Convolutional simultaneous sparse approximation with applications to RGB-NIR image fusion, arXiv:2203.09913
Shaik F (2022) An enhanced image processing model for earlier detection and analysis of diabetic foot hyperthermia through cognitive approach. In: Gunjan VK, Zurada JM (eds) Modern approaches in machine learning & cognitive science: A walkthrough. Studies in Computational Intelligence, vol 1027. Springer, Cham. https://doi.org/10.1007/978-3-030-96634-8_48
Tropp JA, Gilbert AC, Strauss MJ (2006) Algorithms for simultaneous sparse approximation. part I: greedy pursuit. Signal Process 86(3):572–588
Gunjan VK, Prasad PS, Fahimuddin S, Bigul SD (2019) Experimental investigation to analyze cognitive impairment in diabetes mellitus. In: Kumar A, Mozar S (eds) ICCCE 2018. Lecture Notes in Electrical Engineering, vol 500. Springer, Singapore. https://doi.org/10.1007/978-981-13-0212-1_79
Tropp JA, Gilbert AC, Strauss MJ (2006) Algorithms for simultaneous sparse approximation. part II: convex relaxation. Signal Process 86(3):589–602
Jaya Krishna N, Shaik F, Harish Kumar GCV, Naveen Kumar Reddy D, Obulesu MB (2021) Retinal vessel tracking using Gaussian and Radon methods. In: Kumar A, Mozar S (eds) ICCCE 2020. Lecture Notes in Electrical Engineering, vol 698. Springer, Singapore. https://doi.org/10.1007/978-981-15-7961-5_37
Boßmann F, Krause-Solberg S, Maly J, Sissouno N (2022) Structural sparsity in multiple measurements. IEEE Trans Signal Process 70:280–291
Fahimuddin S, Lavanya D, Manasa T, Maruthi Praveen S, Raveendra Babu M (2023) Image dehazing using improved dark channel and Vanherk model. In: Kumar A, Senatore S, Gunjan VK (eds) ICDSMLA 2021. Lecture Notes in Electrical Engineering, vol 947. Springer, Singapore.https://doi.org/10.1007/978-981-19-5936-3_80
Zheng B, Zeng C, Li S, Liao MG (2022) The MMV tail null space property and DOA estimations by tail-`2,1 minimization. Signal Process 194:108450
Yang B, Li S (2021) Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inf Fusion 13(1):10–19
Veshki FG, Ouzir N, Vorobyov SA, Ollila E (2021) Coupled feature learning for multimodal medical image fusion. arXiv:2102.08641
Fahimuddin S, Subbarayudu T, Vinay Kumar Reddy M, Venkata Sudharshan G, Sudharshan Reddy G (2023) Retinal boundary segmentation in OCT images using active Contour model. In: Kumar A, Senatore S, Gunjan VK (eds) ICDSMLA 2021. Lecture Notes in Electrical Engineering, vol 947. Springer, Singapore. https://doi.org/10.1007/978-981-19-5936-3_82
Li J, Zhang H, Zhang L, Ma L (2015) Hyperspectral anomaly detection by the use of background joint sparse representation. IEEE J Sel Top Appl Earth Obs Remote Sens 8(6):2523–2533
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Obulesu, G., Thulasi, M.S.P., Kusuma, K., Bhavya, G., Naidu, N.K. (2023). Multifocus Image Fusion Based on Convolutional Simultaneous Sparse Approximation. In: Kumar, A., Gunjan, V.K., Hu, YC., Senatore, S. (eds) Proceedings of the 4th International Conference on Data Science, Machine Learning and Applications. ICDSMLA 2022. Lecture Notes in Electrical Engineering, vol 1038. Springer, Singapore. https://doi.org/10.1007/978-981-99-2058-7_9
Download citation
DOI: https://doi.org/10.1007/978-981-99-2058-7_9
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-2057-0
Online ISBN: 978-981-99-2058-7
eBook Packages: Computer ScienceComputer Science (R0)