
Abstract
The current scene graph generation (SGG) task still follows the method of first detecting objects-pairs and then predicting relationships between objects-pairs. This paper introduces a parallel SGG thought that decouples relationship detection and object detection. In detail, we propose an independent visual relationship detection method, ‘Relationship You Only Look Once’ (RYOLO), which calculates relationships directly from the input image. For SGG, we present Similar Relationship Suppression and Object Matching Rules to match relationships and detected objects. In this way, the relationship detection and object detection can be calculated in parallel, and detected relationships can easily cooperate with detected objects to generate diversified scene graphs. Finally, our thought has verified the feasibility on the public Visual Genome dataset, and our method may be the first to attain real-time SGG.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Recently, computer vision has achieved great success in visual perceptual tasks, such as object detection. However, generating cognitive relationships from perceptual objects is still challenging. Scene graph generation (SGG) is an essential method for building relationship graphs between individual objects in the scene. In fact, the scene graph is often used as an introductory module to help high-level visual understanding tasks, such as image captioning [1], visual question answering [2], and visual grounding [3].

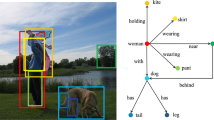
(A) Traditional series SGG thought. (B) Our parallel SGG thought. (C) Independent object detection results calculate the center of the bounding box. (D) Our relationship detection results on the grids. (E) Object matching for scene graph generation. (F) The direction anchor for our relationship detection method.
In the SGG task, one relationship between two objects can be represented as a triple: \({<}subject, relation, object{>}\), such as \({<}man, wear, shirt{>}\). Traditional SGG works [4,5,6,7,8] always relies on a series structure, as shown in Fig. 1(A). In the first stage, an image is fed into an object detection model to get object proposals, and in the second stage, a relationship prediction model is used to predict relationships based on these object proposals. In this case, some SGG works [5, 8] rely on the two-stage object detection [9, 10] to obtain intermediate features of object proposals through RoIAlign. Other SGG works [7, 11] take the bounding box and category from the object detection as input to the predicted relationships. In general, the series structure makes the relationship prediction need wait for object detection processing, which restricts the real-time scene graph generation. In addition, each object-pair (subject and object) must perform one operation to predict the relationship, which is a quadratic number time complexity [4]. A large number of objects detected will seriously slow down the inference speed of SGG. However, for agents such as robots, the surrounding scene is changing in all the time, so a real-time SGG method is of great significance for rapid response of agents.
In this paper, we propose a parallel SGG thought with decoupling object detection and relationship detection for the real time SGG, shown in Fig. 1(B). In our thought, the object detection and the relationship detection are performed in parallel, and the scene graph is generated by combining the two results. For an image, we use a normal object detection method such as YOLOv5 [12] to get the position and category of objects as shown in Fig. 1(C). Meanwhile, we use another independent visual relationship detection method to predict the relationships existing in the image. Each predicted relationship contains a \(start\_position\), an \(end\_position\) and a \(relation\_type\), as shown in Fig. 1(D). Afterward, we use the start and end positions to match the nearest object based on the object center positions from object detection results. Once the start and end positions are both matched by different objects, the triple relationship in the scene graph is established, as shown in Fig. 1(E). The object matched by the start position is the subject-object in the triple relationship, while the object matched by the end position is the object-object in the triple relationship, and the relation type is the predicate. In this way, matching the nearest object is a batch minimum operation that replaces previous objects-pairs predictions and improves operational efficiency. In addition, because the visual relationship detection is independent, it can easily cooperate with any object detection model to generate scene graphs.
The key technology of our SGG thought is the visual relationship detection method. Inspired by the YOLO [13], we propose a novel independent visual relationship detection method RYOLO that can predict relationships from a whole image without intermediate steps such as object proposals [5, 14] or knowledge embedding [15, 16]. In detail, same as common visual tasks, an image is input into a backbone network and get a feature map. The feature map is composed of \(W\times H\) grid cells. As shown in Fig. 1(F), for each grid cell, we preset some direction anchors in the polar coordinate. Each direction anchor contains an initial length \(\rho ^{anchor}\) and an initial radian direction \(\theta ^{anchor}\). One object can be assigned to a unique grid cell based on its center position. Then, the relationship of this object can be expressed as a direction vector from the grid cell, pointing to the center position of another object. Therefore, the neural network will predict direction offsets of the direction anchor \(\varDelta \rho \), \(\varDelta \theta \) and make direction anchors close to direction vectors after regulating by direction offsets. In addition, in order to get the relation type, the neural network will output a confidence score and relation type scores for each direction anchor while predicting direction offsets. Overall, our contribution can be summarized as:
-
We propose a new parallel scene graph generation thought that decouples object detection and relationship detection. We verify the feasibility of this thought on the public dataset and achieve real-time scene graph generation.
-
We propose an independent visual relation detection method RYOLO with preset direction anchors in the polar coordinate. RYOLO can cooperate with any object detection model to generate scene graph.
2 Related Work
From the perspective of the inputting information, we categorize recent SGG researches into three: First, using external knowledge. VRD [17] and UVTransE [15] introduce an external language model to embed word features of objects and relations. GB-NET [6] introduces an external commonsense knowledge graph into SGG. Second, using statistical context information from the dataset, VCTree [18] constructs tree structure with statistical information, while KERN [19] constructs knowledge graph. Third, only using the visual image, IMP [20], Graph R-CNN [4] and FCSGG [21] input the whole image and output the scene graph without additional operation. Our method also falls into this category.
From the perspective of the relationship prediction method, MOTIFS [5], VCTree [18], CogTree [22] construct grouping ordered objects structures and use RNN or LSTM to predict relationships. Graph R-CNN [4], GPS-Net [14] and KERN [19] construct graph structures and use graph neural networks to predict relationships. TDE [23] and PUM [24] put forward new modules, and improve the performance based on previous methods. However, these methods are all based on the series SGG structure: using Faster-RCNN to get object proposals or features, then objects-pairs feature finetunes iteratively for relationship prediction. This structure causes the relationship prediction heavily dependent on the object detection, and the inference speed is slow. Pixels2Graphs [25] and FCSGG [21] predict objects and relationships in one model which tends to the parallel structure. This paper, we propose a parallel SGG thought and introduce RYOLO to detect potential relationships with direction directly from images.

The example of our relationship detection method RYOLO and scene graph generation method. We use the yolov5 backbone for feature extraction and generate multi-scale feature maps through the neck structure. Different direction anchors are preset on feature maps. Each grid tensor contains some clusters and each cluster contains a confidence, a direction offset and some relation type scores. The detected relationships generates a scene graph through similarity relationship suppression (SRS) and object matching.
3 Method
3.1 Independent Relationship Detection
We redesign the output of an excellent object detection work yolov5 [12] and make it can be used for visual relationship detection. We call it ‘Relationship You Only Look Once’, RYOLO. As shown in Fig. 2, the whole image is input into the yolov5’s backbone to extract features. The neck structure can generate multi-scale feature maps, and we finally get F different scale feature maps. We preset a set of direction anchors for each feature map, including \(\rho ^{anchor}\) and \(\theta ^{anchor}\), and direction anchors apply to all grid cells. On each grid cell of the feature map, the grid tensor outputs several clusters, which contains direction offsets \(\varDelta \rho \), \(\varDelta \theta \), confidence c of the relationship, and scores s of each relation type. We will introduce how to get the start position, the end position, and the relation type based on the direction anchor in detail.
Relationship Calculation. On the whole, we can get F feature maps, and we set \(F=3\) means 3 different scale feature maps. For each feature map f with \(f\in F\), it has \(i \times j\) grid cells, while \(i,j\in W_f,H_f\) and W, H are the scale of the feature map. The scale between the input image and the feature map f can be expressed as \(S_f\). Each grid cell on the feature map can be the starting position:
On each feature map f, we preset K direction anchors in the polar coordinate system, and we set \(K=6\) means 6 different directions. For each direction anchor \(d^{anchor}_{fk}\), we can represent as \(d^{anchor}_{fk}=[\rho ^{anchor}_{fk},\theta ^{anchor}_{fk}],f\in F\) and \(k\in K\) with \(\rho ^{anchor}_{fk} \in [0,1]\) and \(\theta ^{anchor}_{fk}\in [0,2\pi ]\). \(\rho ^{anchor}_{fk}\) is the normalized length in the polar coordinate system, while \(\theta ^{anchor}_{fk}\) is the radian direction. In our work, we divide the radian direction \(\theta ^{anchor}\) into K evenly for diverse directions. We hope to predict the short-distance relationship on the large-scale feature map while the long-distance relationship on the small-scale feature map. The larger the feature map, the smaller \(\rho ^{anchor}\). On the feature map f, each grid tensor also contains K predicted clusters. Each cluster contains the direction offset \(\varDelta d_{fkij}=[\varDelta \rho _{fkij},\varDelta \theta _{fkij}]\) for the direction anchor \([\rho ^{anchor}_{fk},\theta ^{anchor}_{fk}]\) on the grid cell i, j, which makes the direction anchor can point to the end position. Therefore, we can calculate the end position by the following formula:
In fact, although we named \(\varDelta \rho \) direction offset, it is actually a scale factor to adjust the length \(\rho ^{anchor}\). \(\varDelta \theta \) add on \(\theta ^{anchor}\) to adjust the radian direction. In this way, each cluster can generate a predicted direction for connection between a start position and an end position. The confidence c in each cluster is used to judge whether the relationship is established. Each cluster also contains scores s independently of the R relation type, which is used to predict the relation type between the start position and end position.
Loss and Training. The loss consists of direction loss, confidence loss, relation loss. We first pick out the \(start\_position_{fij}\) with the relationship, which can generate a direction vector \(d^{vector}_{fij}\). For direction loss \(L_{dir}\), the label direction offset \(\varDelta d^{label}_{fkij} = [\varDelta \rho ^{label}_{fkij},\varDelta \theta ^{label}_{fkij}]\) from the direction anchor \(d^{anchor}_{fkij}\) to the direction vector \(d^{vector}_{fij}\) can be simply expressed as:
We calculate the loss between the predicted direction \(\varDelta d^{pred}_{fkij}\) and the label direction \(\varDelta d^{label}_{fkij}\) through L2 loss, which hopes the predicted direction vector is equal to the label direction vector as much as possible.
For confidence loss \(L_{conf}\), when the \(start\_position_{fij}\) cannot generate direction vectors, we set \(c^{label}_{fij}\) to 0. But when there is a direction vector on the \(start\_position_{fij}\), we compare the distance between the direction vector and direction anchors. We retain direction anchors that close to the direction vector, and set the \(c^{label}_{fkij}\) to 1. Other direction anchors set \(c^{label}_{fkij}\) to 0.
For relation loss \(L_{rel}\), relation types between subjects and objects are not unique in labels. For an object-pair, \({<}man, wears, shirt{>}\) and \({<}man, has, shirt{>}\) may both exist in the label. We set each relation type score \(s^{label}_{fkijr}\) to 1 if the relation type exists in the label for the corresponding cluster. We also use BCELoss to calculate relation loss \(L_{rel}\) and confidence loss \(L_{conf}\).
In summary, the toal loss can be expressed as:
In the Eq. 5, \(N_{conf}\), \(N_{rel}\) and \(N_{dir}\) are used to calculate the average of \(L_{conf}\), \(L_{rel}\) and \(L_{dir}\). Only when \(c^{label}_{fkij}=1\), the corresponding \(L_{rel}\) and \(L_{dir}\) are counted into loss.
During our following training, the size of input images is variable multi-scale similiar with yolov5, and the initial learning rate is 0.04. After 100k interations, the learning rate decay to 0.001. The model is trained end-to-end using SGD optimizer with the batch size of 32.
3.2 Scene Graph Generation
Similar Relationship Suppression. We can get many relationships through our relationship detection RYOLO, and each relationship contains a \(start\_position\), an \(end\_position\), and a \(relation\_type\). We design multiple direction anchors in multi-scale feature maps and multiple directions, but different direction anchors may predict the same relationships. We propose a similar relationship suppression (SRS) method during SGG. In detail, we filter out all relationships by threshold \(t^{c}\), that \(c^{pred}_{fkij}>t^c\). Then, we compare the relationship \({<}start\_position, end\_position, relation\_type{>}\) sorted by \(c^{pred}\) with rest relationships. During the comparison, SRS will suppress similar relationships. The suppression condition can be expressed as:
In suppression condition Eq. 6, \(f'k'i'j'\ne fkij\), and \({t^{d}}\) is the preset distance threshold. If relationships satisfy all three suppression conditions at the same time, low-confidence relationships will be suppressed, and only the highest-confidence relationship will be retained.
Object Matching. To generate a scene graph, we need to employ the results of object detection. In other word, we need to match relationships and objects on the image. The \(start\_position\) or \(end\_position\) will query all center coordinates of detected objects and find the nearest object for matching as the subject-object or object-object, shown in Fig. 1(C). During Object Matching, we use the simple distance threshold to eliminate failed matching between the \(start\_position\) or \(end\_position\) and the center point of objects. The \(start\_position\) and the \(end\_position\) cannot be matched by the same object.
4 Experiment
4.1 Dataset, Model and Metrics
Dataset. We train and evaluate our models on the public VG-150 [23]. VG-150 contains the most frequent 150 object categories and 50 predicate categories from the Visual Genome dataset [26].
Model. We decouple the relationship detection and object detection for SGG. For the object detection, we train independent model yolov5s and yolov5l with different backbone [12]. Similarly, for the relationship detection, we introduce our RYOLO method but use two backbone networks named RYOLOs and RYOLOl. Both Yolov5 and RYOLO are trained in the VG-150 dataset. We will show the impact of different performances object detection models and relationship detection models on SGG.
Metrics. We analyze our method on three standard SGG evaluation tasks: Predicate Classification (PredCls), Scene Graph Classification (SGCls), and Scene Graph Detection (SGDet). The PredCls task only needs to perform our relationship detection and object information can be obtained from label. The SGCls and SGDet tasks need to employ the results of object detection. The conventional metric of SGG is Recall@K (R@K) [17]. Since predicates are not exclusive, Pixels2Graphs [25] proposes No Graph Constraint Recall@K (ng-R@K). Mean Recall@K (mR@K) [18] and No Graph Constraint Mean Recall@K (ng-mR@K) optimize the influence of high-frequency predicates. For verify generalization of SGG, Zero Shot Recall@K (zR@K) [17] and No Graph Constraint Zero Shot Recall@K (ng-zR@K) [23] count triplet relationships that not occurred in the training. In addition, the object detection metric mAP@50 [28] is also displayed as a reference.
4.2 Results and Discussion
Results Analysis. The results of our work are shown in Table 1 and Table 2. We decouple the dependence of relationship detection and object detection in traditional series SGG, so our relationship detection method RYOLO can deal with the PredCls task independently. The traditional SGG methods extract the features of specific objects based on the ground truth bounding box and category, and the predicted relationship is more accurate. RYOLO predicts the relationship from the whole image whether the object bounding box is known or not. The ground truth bounding box and category are only used in the object matching process.
We introduce an additional independent object detection method yolov5 to help RYOLO complete the SGCls and SGDet tasks. From the results, our method cannot bring accuracy improvements in SGG tasks. For a fair comparison with previous works, we divide previous works into three groups: using external knowledge, using statistical context information, and only using visual images. Our method is competitive in SGDet tasks compared with methods in G3. Compared to previous methods in R@K and mR@K metrics, our method performs similarly on SGCls and SGDet tasks. The main reason is that previous methods highly depend on object detection results, and biased detected objects drop performance from SGCls to SGDet. But our method is independent and detects relationships from the whole image. Biased detected object only affect object matching slightly. In the No Graph Constraint condition, each objects-pair can predict multiple possible relation types. Similar to other methods, RYOLO can recall more relationships in this condition.
As for our results of zsR@K and ng-zsR@K, these two metrics are used to judge whether the SGG method can predict the unseen triple relationship in training. They are not common in previous SGG evaluations, and there are limited references. Since our SGG method is independent, it is not restricted by the objects-pairs. From the ng-zsR@K results, our method can predict unseen triple relationships more than the latest fully convolutional scene graph generation method FCSGG. In addition, it seems that SGDet performs better than SGCls when no graph constraint. The reason is that object matching uses detected object positions before Non-Maximum Suppression in SGDet, rather than using ground truth object bounding box in SGCls.

Visualization results of scene graph combined with OWOD [27] and our RYOLOs. In these examples, the color of the bounding box is the same as the color of the text label and each objects-pair only shows the highest-confidence relation.
Advantages. The advantages of our SGG method with parallel thought lie in its inference speed and flexibility. In terms of inference speed, our method has an obvious advantage. To compare the speed with the previous works under the same GPU condition [21], we also perform our method on an NVIDIA GeForce GTX 1080 Ti GPU with batch size 1. Using the combination of RYOLOs and yolov5s, our method realizes real-time scene graph generation (FPS > 30). Compare the fast SGG method FCSGG (HRNetW48-1s) [21], our method improves inference speed by nearly three times with less loss of precision, in Table 1. This is because we adopt a light full convolutional backbone network from yolov5 with less computation and our method supports the parallel structure and can simultaneously detect objects and relationships through multiple processes. In addition, traditional methods with objects-pairs relationship detection have a quadratic number time complexity, but RYOLO detects all relationships at the same time. Object matching is a batch operation to find the minimum position in the matrix operation, and it can maintain high-speed calculation. Furthermore, in the case of a single GPU, the parallel structure can not well reflect the advantages. Object detection yolov5 and relationship detection RYOLO, run in parallel only about 5% faster than running in series, as we show the inference time in Table 1. But nearly 30% faster with multiple GPUs in our experiment.
In terms of flexibility, thanks to the decoupling of object detection and relationship detection, RYOLO can easily cooperate with any object detection model to generate scene graphs. A better object detection model can reduce false detections and missed detections, and improve the accuracy of SGG. In Table 1, we can easily replace the different yolov5 models without retraining the relationship detection model. We believe that this independent method has a more comprehensive and wider practical application value. In addition, we try to replace yolov5 with open-world object detection OWOD [27] for the open-world scene graph generation. As shown in Fig. 3, OWOD can detect unknown objects and mark them as unknown. Similar to human cognition, humans may not recognize a new object but can analyze the relationship between this object and other objects. Combining OWOD and RYOLO in Fig. 3, we can generate some novel relationships, such as \({<}unknow, near, tv{>}\) and \({<}unknow, on, diningtable{>}\). Based on these relationships, the computer can infer unknown attributes through knowledge, such as the unknown object on the diningtable may be tableware.
Limitations. Our method sacrifices accuracy for speed and flexibility. As shown in Fig. 3, there are still some error relationships such as the relationship \({<}person, sitting\ on, car{>}\). Due to our parallel thought, relationships are detected directly from the whole image, the details of the objects themselves will be ignored. Although our relationship detection and object detection are independent, we rely on the consistency of the object center positions detected in the SGG. The current object matching only considers location information from object detection and relationship detection without contextual content. It cannot avoid some false matches. For example, a man and a shirt may fall on the same grid cell, and the nearest object matching may produce a wrong triple \({<}shirt, hold, cup{>}\) rather than \({<}man, hold, cup{>}\). In the long-distance direction prediction in the polar coordinate, a slight shift in the radian causes a huge error in the \(end\_position\).
5 Conclusion
In this paper, we rethink the methods of SGG and introduce a parallel SGG thought with an independent visual relationship detection method RYOLO. In RYOLO, we design direction anchors to directly predict relationships from the image without relying on object detection results. As for SGG, object detection and relationship detection results are correlated through object matching rules to generate triples and the scene graph. This way, we decouple object detection and relationship detection and realize real-time SGG. We expect our method can become a new baseline for the real-time scene graph generation. In the future, we will consider incorporating knowledge and statistical context information to improve the performance of real-time SGG.
References
Gu, J., Joty, S., Cai, J., Zhao, H., Yang, X., Wang, G.: Unpaired image captioning via scene graph alignments. In: CVPR (2019)
Hudson, D.A., Manning, C.D.: Learning by abstraction: the neural state machine. In: NIPS (2019)
Wan, H., Luo, Y., Peng, B., Zheng, W.: Representation learning for scene graph completion via jointly structural and visual embedding. In: IJCAI (2018)
Yang, J., Lu, J., Lee, S., Batra, D., Parikh, D.: Graph R-CNN for scene graph generation. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11205, pp. 690–706. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01246-5_41
Zellers, R., Yatskar, M., Thomson, S., Choi, Y.: Neural motifs: scene graph parsing with global context. In: CVPR (2018)
Zareian, A., Karaman, S., Chang, S.-F.: Bridging knowledge graphs to generate scene graphs. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12368, pp. 606–623. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58592-1_36
Zhang, J., Kalantidis, Y., Rohrbach, M., Paluri, M., Elgammal, A., Elhoseiny, M.: Large-scale visual relationship understanding. In: AAAI (2019)
Lin, X., Li, Y., Liu, C., Ji, Y., Yang, J.: Scene graph generation based on node-relation context module. In: Cheng, L., Leung, A.C.S., Ozawa, S. (eds.) ICONIP 2018. LNCS, vol. 11302, pp. 134–145. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-04179-3_12
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. In: NIPS (2015)
He, K., Gkioxari, G., Dollár, P., Girshick, R.: Mask R-CNN. In: ICCV (2017)
Gkanatsios, N., Pitsikalis, V., Koutras, P., Maragos, P.: Attention-translation-relation network for scalable scene graph generation. In: ICCV Workshops (2019)
Glenn-Jocher, et al.: yolov5 (2021). https://github.com/ultralytics/yolov5
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: unified, real-time object detection. In: CVPR (2016)
Lin, X., Ding, C., Zeng, J., Tao, D.: GPS-Net: graph property sensing network for scene graph generation. In: CVPR (2020)
Hung, Z., Mallya, A., Lazebnik, S.: Contextual translation embedding for visual relationship detection and scene graph generation. IEEE Trans. Pattern Anal. Mach. Intell. 43(11), 3820–3832 (2020)
Gu, J., Zhao, H., Lin, Z., Li, S., Cai, J., Ling, M.: Scene graph generation with external knowledge and image reconstruction. In: CVPR (2019)
Lu, C., Krishna, R., Bernstein, M., Fei-Fei, L.: Visual relationship detection with language priors. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 852–869. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_51
Tang, K., Zhang, H., Wu, B., Luo, W., Liu, W.: Learning to compose dynamic tree structures for visual contexts. In: CVPR (2019)
Chen, T., Yu, W., Chen, R., Lin, L.: Knowledge-embedded routing network for scene graph generation. In: CVPR (2019)
Xu, D., Zhu, Y., Choy, C.B., Fei-Fei, L.: Scene graph generation by iterative message passing. In: CVPR (2017)
Liu, H., Yan, N., Mortazavi, M., Bhanu, B.: Fully convolutional scene graph generation. In: CVPR (2021)
Yu, J., Chai, Y., Wang, Y., Hu, Y., Wu, Q.: CogTree: cognition tree loss for unbiased scene graph generation. In: IJCAI (2021)
Tang, K., Niu, Y., Huang, J., Shi, J., Zhang, H.: Unbiased scene graph generation from biased training. In: CVPR (2020)
Yang, G., Zhang, J., Zhang, Y., Wu, B., Yang, Y.: Probabilistic modeling of semantic ambiguity for scene graph generation. In: CVPR (2021)
Newell, A., Deng, J.: Pixels to graphs by associative embedding. In: NIPS (2017)
Krishna, R., et al.: Visual genome: connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 123(1), 32–73 (2017). https://doi.org/10.1007/s11263-016-0981-7
Joseph, K.J., Khan, S., Khan, F., Balasubramanian, V.: Towards open world object detection. In: CVPR (2021)
Everingham, M., Eslami, S.M.A., Van Gool, L., Williams, C.K.I., Winn, J., Zisserman, A.: The Pascal visual object classes challenge: a retrospective. Int. J. Comput. Vis. 111(1), 98–136 (2014). https://doi.org/10.1007/s11263-014-0733-5
Acknowledgement
The research was supported by the National Natural Science Foundation of China (Grant No. U21A20488) and the ‘10000 Talents Plan’ of Zhejiang Province (Grant, No. 2019R51010). The research was supported by Lab-initiated Research Project of Zhejiang Lab (No. G2021NB0AL03).
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Jin, T. et al. (2023). Independent Relationship Detection for Real-Time Scene Graph Generation. In: Tanveer, M., Agarwal, S., Ozawa, S., Ekbal, A., Jatowt, A. (eds) Neural Information Processing. ICONIP 2022. Communications in Computer and Information Science, vol 1791. Springer, Singapore. https://doi.org/10.1007/978-981-99-1639-9_9
Download citation
DOI: https://doi.org/10.1007/978-981-99-1639-9_9
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-1638-2
Online ISBN: 978-981-99-1639-9
eBook Packages: Computer ScienceComputer Science (R0)