
Abstract
With the increasing growth of amount of learning resources in smart learning environment, it is quite challenging to find suitable resources and learning peers to cater for learners’ different demands. This paper proposes a general architecture of learning recommender system for the smart learning environment. By constructing learner models and resource models, the proposed recommender system aims to recommend learning resources by using the clustering and association rule mining and to recommend peers via social interaction computing. Furthermore, the experiment on real datasets is conducted to demonstrate the effectiveness and usefulness of the approach.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Smart learning environment
- Learning recommender system
- Social interaction computing
- Cluster analysis
- Association rules
16.1 Introduction
With the popularity of the online learning, learners and their learning demands vary from person to person in learning communities. According to different learner’s characteristics, how to provide learning resources and learning peer support services has been paid more and more attention. Meanwhile, with the explosive growth of network information and learning resources, learners face massive information and suffer “cognitive overload,” “learning trek,” and other issues. Under this situation, students often cannot effectively obtain useful knowledge and information.
Recommender systems, one of the branches of online knowledge presentation and navigation, can dispose this problem. The researchers recommend learning resources using different recommend strategies [1–5]. Traditional resource recommends mostly used similarity matching of learner needs and resource attributions to recommend related resource to the learners. The effectiveness of system depends on that it can acquire the character of the learner in more detail. So, it cannot achieve better recommendation quality if learner information is sparse. Educational data mining has become an emerging research field used to extract knowledge and discover patterns from e-learning systems. Learning recommender system can become more effective based on the implicit knowledge and patterns in some situations that learner information can be acquired difficulty.
This paper proposes a learning recommender general architecture. By constructing learner models and resource models, the proposed recommender system aims to recommend learning resources by using the clustering and association rule mining and to recommend peers via social interaction computing.
16.2 The General Architecture of Recommender Systems
The architecture of the learning recommender system is illustrated in Fig. 16.1. And this architecture includes three parts: learner model, resource model, and data processing module. Data processing module is a core computing component. It includes clustering, association rule mining, and social interaction computing.

The architecture of the learning recommender system
The learner model uses the following quadruple:
StuModel = (BasicInfo, Preference, LearnRecord, SocialInfo).
In this model, BasicInfo is basic personal information including learners’ ID, name, age, and vocation. Preference includes learners’ ID, professional fields, professional degree, and learning expectation. LearnRecord includes learners’ ID, time of using the resource, the frequency of using the resource, concerned resources, and the total times of login. SocialInfo is the interactive information of learners including learners’ ID, followers, and interest group.
The resource model uses the following triple:
ResourceModel = (BasicInfo, RecordInfo, EvaluationInfo).
BasicInfo includes static information such as number, name, type, subject, and publisher. RecordInfo includes resource number, the number of comments, the number of people who pay attention to resource, and the number of people who have learned the resource. EvaluationInfo includes each learner’s rating information for resources. RecordInfo and EvaluationInfo are updated dynamically by system according to the learners’ use and feedback.
The two models acquire the data from data collection layer which is in the bottom of the architecture. The data collection layer stores various resource data such as learners’ social network data, behavioral data, and learning preference. Data engine can extract effective information from these data sources to construct learner model and resource model. Interactive calculation calculates learners’ interactive information mainly according to different demands of learning peer recommendations. Clustering calculation uses some clustering algorithms to divide learners into different cluster groups, which is based on learners’ interest and character. Association rules mainly mine accessing behavior of the learners who are in the same cluster to find the association relationship among the resources.
16.3 Social Interaction Computing for Peer Recommendation
Social relationship analysis focuses on interaction relationship among users in the smart learning environments, such as interaction frequency and friendship. On the basis of our previous studies of online learning community activities [6], user credibility networks are constructed toward the various item topics. It consists of three steps: category-based user networking, credibility value assignment based on social ties, and user feature measurement for credibility refinement.
Category-based user networking is for networking users on different topics. Currently, we infer the circle of users according to their concerning items that can be divided into different categories. Credibility value based on social ties is to assign credibility value between users based on the combination of strong ties and weak ties.
User feature is computed based on four indicators, namely expertise, influence, longevity, and centrality. Expertise is used to measure users’ expertise in a specific category. Influence indicates whether a user is influential in a certain category. Longevity indicates an individual’s persistence, which can be computed according to user behaviors. Centrality indicates an individual’s concentration on a specific topic. By combining user credibility network and user rating matrix, this social recommender system can provide learning peers and domain experts’ recommendation.
16.4 Resource Recommendation Method-Based Cluster Analysis and Association Rule Mining
In the learning process, learning resources have some intrinsic orders in similar users’ learning processes, for example, students who major in computer science always choose data structure after they study C language course. Therefore, it is important to mine association rules of resource through clustering students who have similar characteristics. In this way, we can improve the resource recommendation.
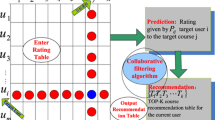
We combine two data mining algorithms: simple k-means clustering algorithm and Apriori association rule algorithm. Simple k-means algorithm is a type of unsupervised algorithm in which items are moved among the set of clusters until the required set is reached. This algorithm is used to classify the dataset, provided the number of clusters is given in prior. Apriori association rule is used to mine the frequent patterns in database. And there has been considerable research using association rules in data mining [7]. The association rule algorithm is employed mainly to determine the relationships between items or features that occur synchronously in the database. The main purpose of implementing the association rule algorithm is to obtain resource using relationships by analyzing the data and to use these relationships as a reference during the recommender process. The model of the recommendation mechanism is shown in Fig. 16.2.

The model of the recommendation mechanism
16.5 Experimental Study
The experiment on real datasets demonstrates the effectiveness and usefulness of the proposed approach. We crawled learner information and their course selection information from the MOOC College (http://mooc.guokr.com) which is the Chinese online MOOC learning community. The dataset contains 2000 learners’ information and 12,076 valid course selection records. As for data processing, firstly, we use clustering algorithm to cluster. Learners who have the similar interest, knowledge level, and learning expectation are combined into the same group through clustering. Then, we use association rule mining to mine course association relationship among each group. Table 16.1 presents the association results of one group. The main interest of this group’s member is computer science, and the knowledge level for the group is intermediate level. This cluster contains 4014 information of courses selected by 372 students and involves about 40 online courses.
Table 16.1 shows course association rules of system mining. System needs to configure mine support and mine confidence. Confidence is a measure of strength of the association rules. In Table 16.1, “A → B Conf” means percentage of course records that contain course A also contain course B together. Support is the percentage of course records that contain course A and course B to the total number of course records. In our study, we configure that the minimum support is 0.1 and minimum confidence is 0.5. As a result, we get the following 15 effective association rules which meet this condition.
From the result of association, it seems that there are high associations among learners’ course choices. For example, “R programming → data scientist’s toolbox conf” is 58.6 %, which means that 58.6 % of learners who have learned “R programming” also have learned “data scientist’s toolbox.” In addition, we also know that “C language programming” and “data structure” have strong correlation. Therefore, we can recommend information for students according to the relevant rules. If a learner has learned “C language programming” and “getting and cleaning data,” we should recommend “R programming,” “data scientist’s toolbox,” “exploratory data analysis,” and “data structure” for him based the association rules.
16.6 Conclusion
In this paper, we propose a general architecture of learning recommender system for smart learning environment. The kernel idea is to adopt data mining approach to recommend learning resources and utilize social interaction computing to recommend learning peers. By combining k-means and Apriori algorithm, the proposed recommender system can recommend suitable resources more easily and effectively. As well, users’ credibility network is constructed for recommending learning peers. The experiment on real datasets demonstrates the effectiveness and usefulness of the proposed approach.
The proposed recommender system is still in its early stage, and more work needs to be done in the future, such as (1) providing sequential-based resource recommendation; (2) considering the implicit attributes of learners; and (3) implementing the recommender system prototype and applying it in the practical settings.
References
Khribi, M. K., Jemni, M., & Nasraoui, O. (2008). Automatic recommendations for e-learning personalization based on web usage mining techniques and information retrieval. In Eighth IEEE International Conference on Advanced Learning Technologies, ICALT’08 (pp. 241–245). IEEE, 2008.
Soonthornphisaj, N., Rojsattarat, E., & Yim-Ngam, S. (2006). Smart e-learning using recommender system. In Computational Intelligence (pp. 518–523). Berlin, Heidelberg: Springer.
Liang, G., Weining, K., & Junzhou, L. (2006). Courseware recommendation in e-learning system. In Advances in Web Based Learning–ICWL 2006 (pp. 10–24). Berlin, Heidelberg: Springer.
Liu, F., & Shih, B. (2007). Learning activity-based e-learning material recommendation system. In Ninth IEEE International Symposium on Multimedia Workshops, ISMW’07 (pp. 343–348). IEEE.
Khribi, M. K., Jemni, M., & Nasraoui, O. (2015). Recommendation systems for personalized technology-enhanced learning. In Ubiquitous Learning Environments and Technologies (pp. 159–180). Berlin, Heidelberg: Springer.
Li, Y., Bao, H., Zheng, Y., Huang, Z. (2015). Social analytics framework to boost recommendation. Online Learning Communities, 3.
Ye, Y. Y. (2015). Research and application of apriori algorithm for mining association rules. Advanced Materials Research, 1079, 737–742.
Acknowledgement
This research work is supported by Special Fund for Beijing Common Construction Project.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Science+Business Media Singapore
About this paper
Cite this paper
Li, Y., Zheng, Y., Kang, J., Bao, H. (2016). Designing a Learning Recommender System by Incorporating Resource Association Analysis and Social Interaction Computing. In: Li, Y., et al. State-of-the-Art and Future Directions of Smart Learning. Lecture Notes in Educational Technology. Springer, Singapore. https://doi.org/10.1007/978-981-287-868-7_16
Download citation
DOI: https://doi.org/10.1007/978-981-287-868-7_16
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-287-866-3
Online ISBN: 978-981-287-868-7
eBook Packages: EducationEducation (R0)