
Abstract
ProtoPNet proposed by Chen et al. is able to provide interpretability that conforms to human intuition, but it requires many iterations of training to learn class-specific prototypes and does not support few-shot learning. We propose the few-shot learning version of ProtoPNet by using MAML, enabling it to converge quickly on different classification tasks. We test our model on the Omniglot and MiniImagenet datasets and evaluate their prototype interpretability. Our experiments show that MAML-ProtoPNet is a transparent model that can achieve or even exceed the baseline accuracy, and its prototype can learn class-specific features, which are consistent with our human recognition.
Yue Wang is the corresponding author of this paper (yuelwang@163.com). Yapu Zhao proposes the idea of combing MAML and ProtoPNet. And Yue Wang proposes the consistency of features (CoF) indicator in this paper. This work is supported by: National Defense Science and Technology Innovation Special Zone Project (No. 18-163-11-ZT-002-045-04); Engineering Research Center of State Financial Security, Ministry of Education, Central University of Finance and Economics, Beijing, 102206, China; Program for Innovation Research in Central University of Finance and Economics; National College Students’ Innovation and Entrepreneurship Training Program “Research and development of interpretable algorithms and prototype system for small sample image recognition”.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Taking advantage of large and high-quality datasets, deep learning models have shown satisfactory results in the field of image classification. However, when sufficient samples with supervised information are not easy to obtain, traditional machine learning methods have difficulty converging to good performance. Therefore, research on few-shot learning has become more popular and has made rapid progress recently. A large number of studies on few-shot learning construct models based on prior knowledge to narrow the hypothetical space to learn quickly for new tasks on smaller datasets [1], such as the Siamese Network [21] constructed by referring to human comparative thinking when recognizing images. Constructed in a similar way, the metric learning model restricts a model to learn a benchmark of classification first and then classify according to the distance from the benchmark [23]. Although the number of studies on few-shot learning has increased, little attention has been given to the interpretability of few-shot learning [2]. The learning model of prototypical networks, which is a branch of metric learning, may provide perspectives for the interpretability of few-shot learning. It constructs distinctive prototypes and makes classification based on comparison with examples, which fits the way of human cognition of new things.
Prototype networks have been applied in few-shot learning models for a long time. Snell et al. [7] map the support set of a class to a higher dimension and take the mean as the prototype of the class. However, this well-known model did not provide interpretability. Here, Chen et al. [8] greatly inspired us. The model, called ProtoPNet, builds prototype layers upon convolutional base layers to scan the prototypical feature regions, and the model is constrained by a loss function to force it to learn prototypical features highly related to the corresponding class. However, this method requires many iterative updates, which make it difficult to obtain good classification results under limited datasets. Can there be any way to help ProtoPNet converge quickly on datasets of new classes?
The MAML proposed by Finn et al. [10] gives us a possible solution. The classifier in MAML acquires the ability to converge faster by training through a large number of different classification tasks. Therefore, by constantly constructing prototypical features in different tasks, ProtoPNet may also achieve good initialization, which means that a transparent image classification model with fast convergence can be obtained. We propose MAML-ProtoPNet, which combines MAML and ProtoPNet, and test our idea on the Omniglot and MiniImagenet datasets. The classification accuracies of our experiments approach or even exceed the baseline performance. We further test the interpretability of prototypical features and prove their interpretability potentials in preliminary experiments.
Contributions
-
We propose a meta-learning version of ProtoPNet by using MAML so that it can work and interpret for new classes of small data.
-
We test our model on the Omniglot and MiniImagenet datasets, and the results approach or even exceed the baseline performance. We further evaluate their interpretability and find that they have learned class-specific features that are consistent with human cognition.
2 Related Work
2.1 Few-Shot Learning
At present, there are three main perspectives to optimize the performance of few-shot learning [1]: data perspective, model perspective and algorithm perspective. These three ideas start from different stages of the machine learning process to achieve optimal results.
Data Perspective.
First, the data dimension is a simple idea to deal with few-shot problems. Data augmentation can reduce the upper bound of the generalization error. Traditional data augmentation methods add training samples by simple transformations, such as rotation and scaling, to the existing datasets [1]. Recently, there have also been some methods used to generate data from similar and larger datasets. For example, Mehrotra et al. [3] applied GAN to few-shot learning and proposed a generative adversarial residual pairwise network. However, data augmentation methods are usually used as an auxiliary method in few-shot learning to expand available training samples.
Model Perspective.
By using prior knowledge, which adds constraints to models, the assumption space can be narrowed. Therefore, fewer samples are needed to search for optima in the narrowed assumption space. For example, CNN networks that train similar but different tasks were constrained to jointly update parameters in Luo et al. [4]. Metric learning models are built on comparison by learned distance functions [5, 6]. This kind of classification based on comparison is more intuitive, suitable for direct reasoning, and has the potential for interpretability. In 2018, Chen et al. [8] proposed a model that decomposed its classification criterion into a weighted sum of similarity scores of meaningful feature regions, which had a higher level of interpretability. However, as we mentioned before, the training cost of this model was high. Gao et al. [9] applied an attention model on smaller datasets to identify prototypes and proposed feature-level attentions. However, their model only told where a query image was highly activated and did not tell where it was similar to the images learned before.
Algorithm Perspective.
Finn et al. [10] proposed model-agnostic meta-learning (MAML), which is model agnostic and can be compatible with any model using gradient descent. To date, MAML has been applied to many models and has produced good performance. After one or several iterations, it can converge quickly [11,12,13]. Nevertheless, little attention is given to the interpretability of this kind of meta-learning. If we apply a transparent model on MAML, which in our work is by applying ProtoPNet [8], we may obtain a model that can not only converge quickly on smaller datasets but also give quantitative interpretability.
2.2 Interpretability
The mainstream interpretability methods can be divided into post hoc interpretability and endogenous interpretability models [19]. Common post hoc interpretability models include decision tree [14], deconvolution, separate representation [15], knowledge distillation [16], etc. Decision trees interpret black box models by fitting classification rules [17], and deconvolution can visualize learned features through convolutions of reverse filters [18]. These models imitate the classification process by fitting black-box models, but the actual working mechanism of the black-box models is still unknown, and most methods are qualitative [19]. The bag-of-words model maps an image to a collection of meaningful patches [20]. Although bag-of-words models can quantitatively analyze interpretability, they require a large number of manual annotations on meaningful areas in images, which are expensive to label and costly to train. Prototypical features, as an alternative to meaningful patches of pictures, can be captured by training prototype networks. When prototypical features are used as comparison benchmarks, quantitative classification criteria can be obtained, which are interpretable, real and intuitive.
3 Proposed Methods
Our model is called MAML-ProtoPNet. It adopts the meta-learning method in the interpretable neural network ProtoPNet proposed in [8]. By learning prototypical features in a meta-learning version, the model can obtain the ability to rapidly construct prototypical features and converge to new tasks.
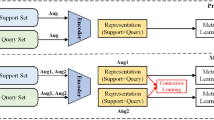
The training process combines MAML and ProtoPNet. The outer loop is simply MAML, which consists of an across-task training, across-task validation and across-task testing process. Every process in an outer loop has several inner loops to learn the current best parameters θ of the classification model. As shown in Fig. 1, the across-task training process in an outer loop contains multiple inner loops starting from the same initial state θ. In an inner loop, we use ProtoPNet as the classification model containing the base convolutional layer, the prototype layer and the fully connected layer (without bias). Each inner loop is a typical classification task based on learned prototypes, which consists of within-task training, prototype projection and within-task testing process. Prototypical features are trained by gradient descent in the within-task training process. The prototype projection process chooses the closest feature value of prototypical features in the training set. The within-task testing process classifies images by using the most distinct feature regions (i.e., the chosen prototypical features) in the training set, and the loss value of a within-task testing process in an inner loop serves as the loss value of that inner loop. As shown in Fig. 1, the across-task training process takes the average of the loss value of multiple inner loops to update the initial parameters θ of the current ProtoPNet model.

Across-task training process
3.1 Adapting ProtoPNet to MAML
We set the inner-loop task to be the n-way k-shot image classification task. As shown in Fig. 2, let x be an image in the training set (support set). In the within-task training process, the base convolutional layers convert x to the feature map f(x) with the shape of (h, w, d). The prototype layer consists of m prototypical features per class \({\text{\{ }}o_i {|} o_i \epsilon class i\} ,\) and each prototypical feature has a shape of (h1, w1, d1), where h1<h, w1<w and d1=d. Each prototypical feature scans the feature map f(x) to calculate the L2 distances. The distance matrix is converted to the similarity matrix, and by global max pooling, we obtain the maximum similarity score between f(x) and prototypical features. The maximum similarity scores lead to the classification scores through the fully connected layers. We refer to the loss function in [8], which encourages \({o}_{i}\) to learn the most relevant features of class i and penalize irrelevant features. The best convergence condition of prototypical features is achieved in the form of the best classification performance.
Necessary Adaptations to MAML.
Since MAML is trained on different classes during each loop, it is difficult to learn the stable prototypical features of each class. Therefore, we need to make necessary adaptations to MAML. First, the pretraining method is adopted in the inner loop: training base convolutional layers first and then adding prototype and fully connected layers after achieving good classification performance. Second, we should change prototypical features during each loop of classification to adapt to MAML. While prototypical features are projected to nearest feature maps, the prediction performance is not affected when the projection does not move much by the proof in [8]. Through these two adaptations, it will be easier for the model to learn prototype features in each inner loop. Hopefully, we can obtain the best initial parameters for few-shot learning in outer loops.

Within-task training process
3.2 Evaluating Models
Interpretability can only be evaluated by human experience. First, we randomly sample an equal number of images from each class in the test set. For each image, we record its top k features given by similarity scores. After we obtain the top k features, the name of a feature is given by human experts by looking at the feature region in the original image, generated by the deconvolution or receptive field methods or simply direct mapping. Using the names of the top k features, we can analyze the interpretability performance of prototypical features.
In datasets that are composed of subjects that have physical meanings, we can evaluate the interpretability of a model through expert annotations and scoring from a preliminary perspective. However, for abstract datasets, expert annotations based on actual semantics might be difficult to carry out. However, we have found two metrics to measure a model’s interpretability. First, machine learned features are annotated based on their positions in their original images by both machine and human expert. After obtaining the labels given by expert and our model, we calculate the matching degree between these two labels and define the score of the matching degree as Consistency of Semantics (CoS). Second, the consistency of the top k features is identified by the machine. We can use the entropy function to measure the inconsistency for abstract recognition. Concretely, we record the percentage pi of a type of feature where there are n types of labeled features. The consistency of Features (called CoF) is defined by Eq. (1).
where logn is the maximum entropy when each of the n types of features has a percentage of 1/n. The more consistency a model identifies the same feature with, the more it is similar to the way humans learn abstract images.
4 Experiments
4.1 Datasets
For few-shot learning, we perform our experiments on Omniglot [22] and MiniImagenet [24].
Omniglot is a dataset composed of 1623 handwritten characters (i.e., classes) collected from 50 alphabets. Each character has 20 samples, which are drawn by 20 different human subjects. It is an abstract dataset. We use data augmentation, which rotates the training and validation datasets in multiples of 90 degrees to make more character classes. Therefore, we use 3200 character classes for training (800 original characters and 1600 characters generated by rotations), 656 character classes for validation (164 original characters and 492 characters generated by rotations), and 659 characters for testing. Both the height and width of an image are 28 pixels.
The MiniImagenet dataset is a small part extracted from the ImageNet dataset. The dataset contains 60,000 color images in 100 actual categories. A typical class contains 600 samples, and the height and width of an image is 84 pixels. There are 64 classes for training, 16 classes for validation and 20 classes for testing.
4.2 Experiment 1: Omniglot Few-Shot Classification
We perform our experiments in the 1-shot and 5-shot on 5-way classification. We construct a four-layer CNN to classify the Omniglot dataset. A convolutional layer is followed by a batch-norm layer, an activation layer (ReLU) and a max-pooling layer (kernel-size = 2, stride = 2) except for the last convolutional layer. The stride of the last max-pooling layer is set to 1. All the layers have 64 filters. The last layer’s feature map is of size 4 × 4 × 64 after calculation. If we further construct a ProtoPNet, we add prototype layers upon the CNN. We let each character class have four prototypical features. Each prototypical feature is of size 1 × 1 × 64 for 64 filters. Since each training task takes 5 classes from the training classes and selects 4 prototypical features, there are 20 prototypical features in total. There is a similarity score between each prototypical feature and the target image. Finally, we have a fully connected layer upon the prototype layers, mapping the similarity scores to the classes. When training the model, we fix the weight from a prototypical feature to its corresponding class to 1 and fix the weights from it to the other classes to –0.5. In this way, we can accelerate the training speed without affecting the classification performance.
In Table 1, we compare the classification performance of MAML-CNN and MAML-ProtoPNet. MAML-CNN is the baseline model that combines MAML and the four-layer CNN. MAML-ProtoPNet is our model that combines MAML and Pro-toPNet. Each score is averaged over 5 classes of multiple tasks of the test set. In the 5-way 5-shot experiment, the scores of MAML-ProtoPNet are very close to those of MAML-CNN. In the 5-way 1-shot experiment, the scores of MAML-ProtoPNet are lower than those of MAML-CNN, but the accuracy and recall scores are still above 0.9. The possible reason why the scores of our model on 5-way 1-shot drops is as follows. While prototypical features of a class can be selected after comparing five images of any other class in the 5-shot case, they are selected only by one image in the 1-shot case, making it difficult to select class-specific features in this case. How-ever, comparing 1 shot and 5 shots, we find that slightly increasing the number of training sets can swiftly improve the performance of ProtoPNet (e.g., the precision score increases from 0.877 to 0.967).
4.3 Experiment 2: MiniImagenet Few-Shot Classification
We perform our experiments in the 1-shot and 5-shot on 5-way classification. The height and width of the input images are set to 224 pixels to match the model’s structure. We choose to take the convolutional layers of VGG-16 [25] as the convolutional base layer, whose structure is shown in Fig. 3. There are five convolutional blocks in total, and each convolution block contains 2 or 3 convolutional layers. Each convolution layer is followed by an activation layer (ReLU), and each convolution block is followed by a max-pooling layer (kernel-size = 2, stride = 2). The last layer’s feature map is of size 7 × 7 × 512 after calculation. We let each category have twenty prototypical features. Each prototypical feature is of size 1 × 1 × 512 for 512 filters. Since each training task takes 5 classes from the training classes and selects 20 prototypical features, there are 100 prototypical features in total. The parameter setting of the fully connected layer is the same as that of Experiment 1.
In Table 2, we compare the classification performance of MAML-VGG and MAML-ProtoPNet. MAML-VGG is the baseline model that combines MAML and the convolutional layers of VGG-16, as shown in Fig. 3. MAML-ProtoPNet is our model. In both the 1-shot and 5-shot experiments, the performance of MAML-ProtoPNet is better than that of MAML-VGG (e.g., the accuracy increases almost 6% from MAML-VGG to MAML-ProtoPNet in the 5-way 5-shot experiment), which shows that the added prototype layer can improve the performance.

Convolutional layers of VGG-16 (activation layers are hidden)
4.4 Experiment 3: Interpretability Analysis on Omngilot
We conduct interpretability verification analysis on 100 classes. We examine 5 test samples with their top 4 prototypical features for each class, therefore 2000 prototypical features in total. Due to our four convolutional layer structure, every image outputs an activation map of size 2 × 2 × 64 while the size of our prototypical feature is set to 1 × 1 × 64. Therefore, prototypical features roughly represent four parts of each image. We visualize prototypical features and use this position of the four parts (upper-left, upper-right, lower-left, lower-right) as the labels of prototypical features. We also obtain feature region labels given by human experts, and then we examine whether the two regions are matched to examine the interpretability of the top 4 prototypical features.
Table 3 shows 5 query samples from different categories and their top 4 prototypical features and images. Prototypical features are built from prototypical images. We can see that almost all prototypical features are from the same class of each query image, which shows prototypical features do learn the typical features that are class-specific. Table 4 examines the consistency of the scores of prototypical features in two dimensions. Consistency of semantics (CoS) defined in 3.2 is the score between labels given by expert and labels given by our model. The CoS score is 0.904, which shows that the meanings of the prototypical features are highly consistent with our human recognition. The CoF defined in 3.2 examines the label consistency of the top 4 features of each query in the same class. The CoF score is 0.811, which shows that the top 4 prototypical features of each query in the same class identify the same areas. Combining the above two discussions on prototype consistency, we may say that the prototypical features in our model learn class-specific features that are consistent with our human cognition on abstract datasets.
4.5 Experiment 4: Preliminary Interpretability Analysis on MiniImagenet
MiniImagenet is composed of images that have practical meanings, so we can further discuss learned prototypical features with expert annotations. We randomly select a 5-way task from the test dataset, which is made up of 5 images for training (support set) and 60 images for testing (query set). Then, we put the task into the MAML-ProtoPNet model to obtain prototypical features for each query and select the top 4 features of the same class according to its corresponding similarity scores. We artificially annotate the top 4 features for all images in the query set referring to the expert annotation rules defined in Table 5 and score the coincidence degree between the extracted prototype feature area and the annotation semantic area for each query. The score of the coincidence degree ranges from 1 to 10.
Table 6 shows the score of the coincidence degree for every label in each class. We can see from Table 6 that class-specific features, such as the ear, face, head, and body, have relevant higher scores than the other features. This condition shows that MAML-ProtoPNet has the potential to learn class-specific features. In addition, most scores of coincidence degree are above 7. Therefore, we might consider that the interpretability shown by MAML-ProtoPNet is consistent with human cognition from a preliminary perspective.
5 Conclusion and Future Work
In this work, we have proposed a meta-learning version of ProtoPNet by using MAML, which is a transparent model and has the ability to quickly converge in different classification tasks. We trained this model on the Omniglot and MiniImagenet datasets for 5-way 1- and 5-shot via a meta-learning method. We have achieved near or above baseline accuracy and obtained a quantitative interpretability of the classification process. We have also discussed the interpretability of prototypical features and proved that they can learn class-specific features in our preliminary experiments.
Our future work will try to compare more advanced and stable models to further verify the feasibility and stability of our model. We will try to apply more model structures to improve the performance of our model and further explore the interpret-ability of learned prototypical features.
Supplementary Material and Code: The supplementary material and code are available at https://github.com/Luoluopista/MAML-ProtoPNet.
References
Wang, Y., Yao, Q., Kwok, J.T., Ni, L.M.: Generalizing from a few examples: a survey on few-shot learning. arXiv: Learning (2019)
Xue, Z., Duan, L., Li, W., Chen, L., Luo, J.: Region comparison network for interpretable few-shot image classification. arXiv preprint arXiv:2009.03558 (2020)
Mehrotra, A., Dukkipati, A.: Generative adversarial residual pairwise networks for one shot learning. ArXiv, abs/1703.08033 (2017)
Luo, Z., Zou, Y., Hoffman, J., Fei-Fei, L.F.: Label efficient learning of transferable representations across domains and tasks. In: Advances in Neural Information Processing Systems, 30 (2017)
Gidaris, S., Komodakis, N. Dynamic few-shot visual learning without forgetting. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4367–4375 (2018)
Suárez, J.L., García, S., Herrera, F.: A tutorial on distance metric learning: mathematical foundations, algorithms, experimental analysis, prospects and challenges. Neurocomputing 425, 300–322 (2021)
Snell, J., Swersky, K., Zemel, R.: Prototypical networks for few-shot learning. In: Advances in Neural Information Processing Systems, 30 (2017)
Chen, C., Li, O., Barnett, A., Su, J., Rudin, C. This looks like that: deep learning for interpretable image recognition. NeurIPS (2019)
Gao, T., Han, X., Liu, Z., Sun, M. Hybrid attention-based prototypical networks for noisy few-shot relation classification. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, no. 1, pp. 6407–6414 (2019)
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: ICML 2017, pp. 1126–1135 (2017)
Jiang, X., et al.: On the importance of attention in meta-learning for few-shot text classification. ArXiv, abs/1806.00852 (2018)
Jamal, M., Qi, G., Shah, M.: Task agnostic meta-learning for few-shot learning. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 11711–11719 (2019)
Phillips, P.J., Hahn, C.A., Fontana, P.C., Broniatowski, D.A., Przybocki, M.A.: Four Principles of Explainable Artificial Intelligence (2020)
Bastani, O., Kim, C., Bastani, H.: Interpreting blackbox models via model extraction. ArXiv, abs/1705.08504 (2017)
Zhou, B., Bau, D., Oliva, A., Torralba, A.: Interpreting deep visual representations via network dissection. IEEE Trans. Pattern Anal. Mach. Intell. 41, 2131–2145 (2019)
Cheng, X., Rao, Z., Chen, Y., Zhang, Q.: Explaining knowledge distillation by quantifying the knowledge. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12922–12932 (2020)
Zhang, Q., Yang, Y., Wu, Y.N., Zhu, S.: Interpreting CNNs via decision trees. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6254–6263 (2019)
Brahimi, M., Mahmoudi, S., Boukhalfa, K., Moussaoui, A. (2019, September). Deep interpretable architecture for plant diseases classification. In: 2019 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), pp. 111–116. IEEE (2019)
Rudin, C.: Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat. Mach. Intell. 1(5), 206–215 (2019)
Qader, W.A., Ameen, M.M., Ahmed, B.I.: An overview of bag of words; importance, implementation, applications, and challenges. In: 2019 International Engineering Conference (IEC), pp. 200–204. IEEE (2019)
Melekhov, I., Kannala, J., Rahtu, E.: Siamese network features for image matching. In: 2016 23rd International Conference on Pattern Recognition (ICPR), pp. 378–383. IEEE (2016)
Lake, B.M., Salakhutdinov, R., Tenenbaum, J.B.: The Omniglot challenge: a 3-year progress report. Curr. Opin. Behav. Sci. 29, 97–104 (2019)
Kulis, B.: Metric learning: a survey. Found. Trends Mach. Learn. 5(4), 287–364 (2013)
Vinyals, O., Blundell, C., Lillicrap, T., Wierstra, D.: Matching networks for one shot learning. In: Advances in Neural Information Processing Systems, 29 (2016)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Zhao, Y., Wang, Y., Zhai, X. (2022). Preliminary Study on Adapting ProtoPNet to Few-Shot Learning Using MAML. In: Wang, Y., Zhu, G., Han, Q., Wang, H., Song, X., Lu, Z. (eds) Data Science. ICPCSEE 2022. Communications in Computer and Information Science, vol 1628. Springer, Singapore. https://doi.org/10.1007/978-981-19-5194-7_11
Download citation
DOI: https://doi.org/10.1007/978-981-19-5194-7_11
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-5193-0
Online ISBN: 978-981-19-5194-7
eBook Packages: Computer ScienceComputer Science (R0)