
Abstract
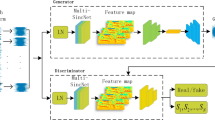
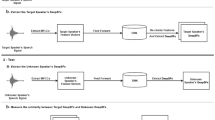
Speaker identification (SI) is the process of recognizing the identity of a speaker according to the acoustic features extracted from a given utterance. Convolutional neural network (CNN) models have been widely used for solving SI tasks. However, the performance of CNN models significantly depends on how the loss function is optimized during the training process. In this paper, we propose a Rectified Adam (RAdam) optimizer-based CNN model for the speaker identification task. Mel-frequency cepstrum coefficient (MFCC) features are considered as the input features in this study. Moreover, in this work, the CNN architecture is improvised with one more dense layer with respect to the earlier CNN model to improve the feature learning ability. The experimental results showed the superiority of the proposed model over the state-of-the-art Adam optimizer-based CNN model and LSTM model in terms of accuracy for speaker identification.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

Notes
- 1.
Regional speaker dataset is available at https://tinyurl.com/sjyjzebk
- 2.
Source code of the proposed model is available at github: https://rb.gy/t2axbi
References
Jahangir R, Teh YW, Nweke HF, Mujtaba G, Al-Garadi MA, Ali I (2021) Speaker identification through artificial intelligence techniques: a comprehensive review and research challenges. Expert Syst Appl 171:114591
PS PK, Yadava GT, Jayanna HS (2017) Text independent speaker identification: a review. In: 2017 2nd international conference on emerging computation and information technologies (ICECIT), pp 1–6
Joshy J, Sambyo K (2016) A comparison and contrast of the various feature extraction techniques in speaker recognition. Int J Signal Process, Image Process Pattern Recog 9:99–108
Mohd Hanifa R, Isa K, Mohamad S (2021) A review on speaker recognition: technology and challenges. Comput Electr Eng 90:107005
Liu L, Jiang H, He P, Chen W, Liu X, Gao J, Han J (2020) On the variance of the adaptive learning rate and beyond. In: 8th international conference on learning representations, ICLR 2020, Addis Ababa, Ethiopia, April 26–30, 2020. OpenReview.net
Toda T, Chen LH, Saito D, Villavicencio F, Wester M, Wu Z, Yamagishi J (2016) The voice conversion challenge 2016. In: Proceedings INTERSPEECH, pp 1632–1636
Antony A, Gopikakumari R (2018) Speaker identification based on combination of MFCC and UMRT based features. Procedia Comput Sci 143:250–257, 8th international conference on advances in computing communications (ICACC-2018)
Utomo YF, Djamal EC, Nugraha F, Renaldi F (2020) Spoken word and speaker recognition using MFCC and multiple recurrent neural networks. In: 2020 7th international conference on electrical engineering, computer sciences and informatics (EECSI), pp 192–197
Mobiny A (2018) Text-independent speaker verification using long short-term memory networks. ArXiv
Jalil AM, Hasan FS, Alabbasi HA (2019) Speaker identification using convolutional neural network for clean and noisy speech samples. In: 2019 first international conference of computer and applied sciences (CAS), pp 57–62
Bhosale RS, Chaudhari NS (2019) Accelerating speech recognition system by Adam optimization and CNN for real time system using GPU. Int J Control Autom 12(4):11–19
Senior A, Heigold G, Ranzato M, Yang K (2013) An empirical study of learning rates in deep neural networks for speech recognition. In: 2013 IEEE international conference on acoustics, speech and signal processing, pp 6724–6728
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Mazumder, A., Ghosh, S., Roy, S., Dhar, S., Jana, N.D. (2022). Rectified Adam Optimizer-Based CNN Model for Speaker Identification . In: Mohanty, M.N., Das, S. (eds) Advances in Intelligent Computing and Communication. Lecture Notes in Networks and Systems, vol 430. Springer, Singapore. https://doi.org/10.1007/978-981-19-0825-5_16
Download citation
DOI: https://doi.org/10.1007/978-981-19-0825-5_16
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-0824-8
Online ISBN: 978-981-19-0825-5
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)