
Abstract
Big data cloud platforms provide users with on-demand configurable computing, storage resources to users, thus involving a large amount of user data. However, most of the data is processed and stored in plaintext, resulting in data leakage. At the same time, simple encrypted storage ensures the confidentiality of the cloud data, but has the following problems: if the encrypted data is downloaded to the client and then decrypted, the search efficiency will be low. If the encrypted data is decrypted and searched on the server side, the security will be reduced. Data availability is finally reduced, and indiscriminate protection measures make the risk of data leakage uncontrollable. To solve the problems, based on searchable encryption and key derivation, a cipher search system is designed in this paper considering both data security and availability, and the use of a search encryption algorithm that supports dynamic update is listed. Moreover, the system structure has the advantage of adapting different searchable encryption algorithm. In particular, a user-centered key derivation mechanism is designed to realize file-level fine-grained encryption. Finally, extensive experiment and analysis show that the scheme greatly improves the data security of big data platform.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Currently, big data storage platforms store user’s data in plain text, which brings the risk of data leakage, and it is difficult for users to protect their stored data from being stolen. At the same time encrypted data storage faces the following problems: if the encrypted data is downloaded to the user’s terminal and then decrypted and searched, the search efficiency will be inefficient. Decrypting and searching the encrypted data on the server will reduce the security [1,2,3,4].
At the same time, when the distributed file system is applied to provide storage services for users, users usually upload and store plaintext data directly, and it is difficult for users to control whether their stored data is leaked or stolen. In addition, the file storage service provider may monitor and analyze the user’s file retrieval behavior, perform correlation analysis on the user’s file content through the keywords retrieved by the user, and then focus on cracking and stealing user’s data [5,6,7,8,9]. Besides, users store plaintext data in third-party organizations, losing the initiative to control data and failing to know whether their data has been stolen or leaked [10,11,12,13].
For example, in June 2017, the analysis report of the Shodan Internet device search engine showed that the Hadoop server was exposed due to insecure configuration and plaintext storage. It involves nearly 4500 servers using the Hadoop Distributed File System (HDFS), with a data volume of up to 5120 TB. The requirements corresponding to the above risks are:
-
1.
File system data encryption protection.
-
2.
The data of the file system can realize the search query of the ciphertext to obtain the corresponding file content.
A feasible solusion is to use the ciphertext computing algorithm such as searchable encryption, homomorphic encryption, etc. They can efficiently perform retrieval operations in ciphertext and also have diverse scenarios, such as medical data, financial data and government data, etc. [13,14,15,16].
In response to the above risks and requirements, we developed our system based on searchable encryption algorithm and hierarchical key management to realize three major functions, including data encryption protection, encrypted search of encrypted data on the storages side, and data security sharing. By classifying users, distributing corresponding master keys, the keys of file contents are derived from users’ master keys and file unique identifiers. Hierarchical and fine-grained control is realized through hierarchical keys, thus, users of corresponding levels can complete file encryption, upload and sharing only by holding encryption keys of corresponding levels, which is simple and convenient.
To sum up, our system can realize ciphertext storage, cipher retrieval and file access control based on user identity level and master key, effectively solve the content security problem of traditional distributed file system, and prevent file content leakage caused by malicious administrators and network attacks.
The rest of the paper is organized as follows: In Sect. 2, we first familiarize with the scheme’s functional interaction model and system architecture. In Sect. 3, we list the usage of our algorithm and deployment of our system. Section 4 present the system analysis and feasibility. Section 5 concludes the paper.
2 Functional Interaction Model and System Architecture
2.1 Functional Interaction Model
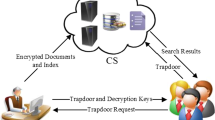
Distributed file system supporting searchable encryption technology mainly provides users with file secure search and storage, Fig. 1 shows the functional model of distributed file system supporting searchable encryption technology proposed for this project. The core parts of functional interaction model mainly includes 3 parts: file data encryption protection, ciphertext search, download and decryption of the file data at the storage end and file secure sharing.
-
1.
Data encryption protection: File data encryption protection means that users generate the encryption keys of files based on file meta data and their own master keys, then encrypt files, generate indexes and encrypt them at the same time, then upload ciphertext files and cipher text index to the cloud server.
-
2.
Ciphertext search: Cipher search of encrypted file data at the storage end means that users generate ciphertext retrieval key value through data keywords and keys, then send the key value to the server, search the ciphertext index of the file through the retrieval algorithm to obtain the corresponding file, finally download and decrypt the retrieved file to obtain the plain text.
-
3.
Data secure sharing: Security sharing of file data means that user A can directly share file ciphertext to user B by sharing the derived key and index, and user B updates its own ciphertext retrieval set, as long as user B’s security level meets the security level of the file, the file can be obtained through ciphertext retrieval, download and decryption of file data.

Functional interaction model.
2.2 System Architecture
As is shown in Fig. 2, our system architecture mainly includes cipher search system client, cipher search service subsystem, key management subsystem and the existed big data platform it relies on (take HDFS as an example in the figure).

System architecture.
-
The cipher search client uploads and downloads files to the HDFS storage system, performs encryption and decryption operations in the background of the client during uploading and downloading. When the client uploads the ciphertext file to the HDFS storage system, it also establishes a cipher keyword index list in the cipher search service subsystem for locating the ciphertext file.
When the client initiates the sharing operation, it distributes the file key to the shared user's client through secure channel and notifies the shared user’s client. After the shared user’s client receives the notification, its client background updates the shared ciphertext keyword index list to the search service subsystem to confirm sharing.
-
The cipher search service subsystem obtain the search key from the key management subsystem, and establishes a ciphertext keyword index list for the user of the client when the client initiates uploading, receiving and sharing operations. It also provides storage, update and query of the index list.
-
The key management subsystem provides file encryption keys for the clients when they perform upload and download operations, provides file encryption keys for shared user clients when sharing, provides search keys for clients when searching. At the same time, key management system provides search keys for search service system to establish, update and search the cipher keyword index.
3 Main Cryptographic Algorithm
3.1 Key Management Algorithm
Suppose SKE = (Setup, Enc, Dec) is a secure traditional symmetric encryption algorithm, \(Hash{:}\{ 0,1\}^{ * } \to \{ 0,1\}^{ * }\) is an anti-collision hash function, key management scheme includes following steps:
-
1.
System boot: Key management center initiate, generate system public parameter Param and master key MK.
-
2.
User register: User \(U_{i}\) use his identity and attributions to initiate registration, key management centre compute user’s root key RK from its master key MK (using IBE scheme to generate secret key), then issue a certificate PK for user as the public key corresponding to RK. Meanwhile, issue hierarchical key \(LK_{u}\) to users according to their secure level, of which \(LK_{u} \in \{ {LK_{1}, LK_{2}, LK_{3} }\}\). Hierarchical keys are divided into several levels, users of same level have the same classification key, let 1st level key be \(LK_{u}\), which is a pseudo-random number generated by using pseudo-random function Rand. The 2nd level key is \(LK_{2}\,{ = }\,Hash(LK_{1} |2)\), 3rd level key is \(LK_{3}\, { = }\,Hash(LK_{2} |3)\), of which | means string concatenation.
-
3.
Encryption key derivation, encryption and management algorithm: A file may have different security levels, in order to improve security levels, users have to encrypt different levels of files with different keys.
A user first generates a file key FK (where \(FK\,{ = }\,Hash(RK|Filename{\text{|LK}}_{u} )\)) by using his root key RK, filename and file security level, of which \(LK_{u}\) corresponds to user’s authorization file security level. Besides, the user randomly choose a string nonce to compute secret key SK for searchable encryption, of which SK = Hash(RK|nonce). The user can use SK to compute cipher index of the file, which is used to identify the owner of the file and facilitate the query operation of other users.
Finally, the user set a password to encrypt the file key FK (that is, \(C_{K}\) = Encrypt(FK, hash(password))).
3.2 File Classification Encryption/Decryption Algorithm
For file encryption, we adopt the method of digital envelope, that is, use symmetric encryption algorithm to encrypt the file, use searchable encryption to generate the cipher index of the file, finally encrypt the file key. Further, we adopt national algorithm of China SM2 in the encryption/decryption procedure.
For example, when it comes to a file with security level A, the user first calculates its file key by using steps in key derivation, that is, \(FK_{{A_{u} }} \,=\, Hash(RK|filename|LK_{u} )\). Then use file key to \(FK \,= \,FK_{{A_{u} }}\) to encrypt file A to get its ciphertext \(C_{F}\). (\(C_{F} \,=\, Enc(FileA,FK_{{A_{u} }} )\)).
Finally, the user use his password key K to encrypt file key, get \(C_{K} \,=\, Enc(FK_{{A_{u} }} )\), stores the final cipher result \(C \,=\, (C_{F} ,C_{K} )\).
When it comes to decryption, user first decrypt file key \(FK \,=\, FK_{{A_{u} }} \,=\, Dec(C_{K} ,K)\), of which K = hash(password). Then restore his original file key \(FK_{{A_{u} }}\) according to his authorization. Finally, restore the file by computing \(File \,=\, Dec(C_{F} ,FK_{{A_{u} }} )\).
3.3 Symmetric Searchable Encryption Algorithm
Suppose user has file collection \(D \,=\, (d_{1} ,d_{2} ,...,d_{n} )\) corresponding unique identifiers \((\overline{d}_{1} ,...\overline{d}_{n} )\), all of them has keywords collection \(W \,=\, (w_{1} ,w_{2} ,...,w_{n} )\), suppose \(SKE_{1}\) and \(SKE_{2}\) are two traditional secure symmetric encryption algorithms, \(f:{\{\mathrm{0,1}\}}^{k}\times {\{\mathrm{0,1}\}}^{l}\to {\{\mathrm{0,1}\}}^{k+{log}_{2}s}\) is a pseudo-random function. \(\pi :{\{\mathrm{0,1}\}}^{k}\times {\{\mathrm{0,1}\}}^{l}\to {\{\mathrm{0,1}\}}^{l}\) and \(\psi :{\{\mathrm{0,1}\}}^{k}\times {\{\mathrm{0,1}\}}^{{log}_{2}s}\to {\{\mathrm{0,1}\}}^{{log}_{2}s}\) are two pseudorandom permutation functions. The main steps listed as follows:
-
1.
Key generation: generate random key \({{K}_{1},{K}_{2},K}_{3}\), separately used for pseudorandom permutation function \(\psi\), pseudorandom function \(f\) and pseudorandom permutation function π, generate key \({K}_{4}\) for \({SKE}_{2}\).
-
2.
Keyword matching: scan the file collection to get corresponding keywords collection \(\delta (D)\), for each \(w \in \delta (D)\), there exist a document subset \(D(w)\) corresponding to this keyword, of which \(D(w) \subseteq D\), we set a global counter \(ctr \,=\, 1\) in the traversal.
-
3.
Construction of file index array A: for \(1\le i\le |\delta (D)|\), construct linked list \({L}_{i}\) corresponding to i-th keyword. Each \({L}_{i}\)’s nodes (expressed as \(N_{i,j}\)) order is random and the length \(|D\left(w\right)|\) may be different. Suppose \(id(D_{i,j} )\) is j-th unique identifier in\(D(w)\), generate each node \(N_{i,j} {\le}id(D_{i,j} )||K_{i,j} ||\psi_{{K_{1} }} (ctr + 1)>\), encrypt node \(N_{i,j}\) with key and write the cipher in position \(\psi_{{K_{1} }} (ctr)\), of which \(K_{i,j}\) is used for encrypting next node \(N_{{i,j{ + }1}}\) while \({\psi}_{K1}(ctr+1)\) is the pointer of next node. Every time the encryption storage cycle is completed, the counter is incremented by 1 (ctr + +). In addition, the pointer and key of the last node in the linked list are empty, that is, \(N_{{i,|D(w_{i} )|}} {\le}id(D_{{i,|D(w_{i} )|}} )||0^{k} ||NULL>\).
Let \(s^{\prime} \,=\, \sum\nolimits_{{w_{i} \in \delta (D)}} {|D(w_{i} )|}\) $, it means adding up the number of documents to which each keyword belongs. if \(s^{\prime} < s\), fill the remaining positions with random strings, s is the upper limit of array A’s element capacity.
-
4.
Construction of head node index \(T\): the size of \(T\) is \({\{\mathrm{0,1}\}}^{l}\times {\{\mathrm{0,1}\}}^{k+{log}_{2}s}\times ||\)), \({|}\Delta |\) is the total number of dictionary set keywords. For all the \(w_{i} \in \delta (D)\), set the index entry of the first node as \(T[\pi_{{K_{3} }} (w_{i} )] \,=\, (addr_{A} (N_{i,1} )||K_{i,0} ) \oplus f_{{K_{2} }} (w_{i} )\). Fill the remaining items \({|}\Delta | - |\delta (D)|\) with random numbers.
-
5.
Encrypt original data: for each document \(d \in D\), compute \(c \leftarrow SKE_{2} .Enc(K_{4} ,d)\), get the final result \(I\,=\,(A,T)\),\(C \,=\, (c_{1} ,...,c_{n} )\).
-
6.
Generate query token: compute \(t \,=\, (\pi_{{K_{3} }} (w),f_{{K_{2} }} (w))\) and send it to cloud server.
-
7.
Cloud search: Parse the query token t as \((\gamma ,\eta )\), where \(\gamma \,{ = }\,\pi_{{K_{3} }} (w_{i} )\), \(\eta \,{ = }\,f_{{K_{2} }} (w_{i} )\), find out if there is a result \(\theta\) at position \(\gamma\) in the head node index T (that is, \(\theta \leftarrow T(\gamma )\)). If \(\theta\) exists, then compute:
$$ \begin{aligned} & \theta { + }\eta \hfill \\ & \, { = }(addr_{A} (N_{i,1} )||K_{i,0} ) \oplus f_{{K_{2} }} (w_{i} ) \oplus f_{{K_{2} }} (w_{i} ) \hfill \\ & \, { = }(addr_{A} (N_{i,1} )||K_{i,0} ) \hfill \\ \end{aligned} $$(1)Use key \(K^{\prime}\) to decrypt the node in position \(addr_{A} (N_{i,1} )\), finally output all the identifiers in list \(L_{i}\) one by one.
-
8.
For each encrypted document, compute \(d\leftarrow {SKE}_{2}.Dec({K}_{4},c)\), of which \({K}_{4}\) is derived as is shown in file classification encryption/decryption algorithm.
3.4 Dynamic Update of Cipher Index
Due to the cipher state exposed to cloud, dynamic update has become an extremely important issue, which is related to security.
When user uploads a new file \({d}_{k}\), which includes keyword \({w}_{n}\) and \({w}_{m}\), of which \({w}_{n}\) is a keyword that has been established in the cloud’s ciphertext index, while \({w}_{m}\) is a new keyword that hasn’t been established.
-
For \({w}_{n}\), user has already constructed head node in the cipher index server, that is, \(T[\pi_{{K_{3} }} (w_{n} )] = (addr_{A} (N_{n,1} )||K_{n,0} ) \oplus f_{{K_{2} }} (w_{n} )\), the file uploading process is equivalent to resubmitting the trapdoor of\({w}_{n}\), which means that the server need to parse out all the identifiers containing\({w}_{n}\).
The original linked list is:
where \(N_{n,j} {\le}id(D_{n,j} )||K_{n,j} ||\psi_{{K_{1} }} (ctr + 1)>\), \({N}_{n,|D({w}_{n})|}{\le}id({D}_{n,\left|D\left({w}_{n}\right)\right|})||{0}^{k}||NULL)>\)
The server will reconstruct the linked list \({L}_{n}\) after parses out all the identifiers, that is reconstruct the tail node and attach a new node, which has the minimum computational overhead.
Generate random key \({K}_{n,|D({w}_{n})|}^{^{\prime}}\), then use it to encrypt the new tail node \({N}_{n,\left|D\left({w}_{n}\right)\right|+1}\) through symmetric encryption algorithm \({SKE}_{1}\). The tail node \({N}_{n,|D({w}_{n})|}\) of original linked list \({L}_{n}\) is updated to
and then attach a new node \({N}_{n,\left|D\left({w}_{n}\right)\right|+1}{\le}id({D}_{n,\left|D\left({w}_{n}\right)\right|+1})||{0}^{k}||NULL>\), of which \(id({D}_{n,\left|D\left({w}_{n}\right)\right|+1})=id({d}_{k})\), at this time the new linked list is:
So when the client updates the server array, it only needs to submit the server:
Equation (4) overwrite the encrypted node in the original position with the new node. Equation (5) overwrite the random string of position \(A\left[{\psi}_{{K}_{1}}\left({ctr}_{|D({w}_{n})|}\right)\right]\) with the new tail node.
-
For \({w}_{m}\), the user has not established the cipher index of \({w}_{m}\) before, thus need to construct new linked list \({L}_{m}\), at this time, the linked list only needs to construct one node \({N}_{m,1}{\le}id({D}_{m,1})||{0}^{k}||NULL>\), where \(id\left({D}_{m,1}\right)=id\left({D}_{n,\left|D\left({w}_{n}\right)\right|+1}\right)=id\left({d}_{k}\right)\), that is, the same identifier corresponds to different keywords.
Under this condition, the head node cipher index needs to be newly constructed:\(T\left[{\pi }_{{K}_{3}}\left({w}_{m}\right)\right]=({addr}_{A}({N}_{m,1})||{K}_{m,0}) \oplus {f}_{{K}_{2}}({w}_{m})\), the node storage position is calculated by client:\({addr}_{A}\left({N}_{m,1}\right)={\psi}_{{K}_{1}}({ctr}_{|{N}_{ij}|}+1)\), of which \({ctr}_{|{N}_{ij}|}\) is the number of filled nodes in array A, besides, the remaining \(s - s^{\prime}\) positions still fill with random strings, \(s^{\prime} = ctr_{{|N_{ij} |}}\).
So when the client updates keyword \({w}_{m}\) in the server array, it only needs to submit the server:
File content encryption only needs to refer to step 5) in Sect. 3.
From the new uploaded items in index update Eq. (4), (5), (6), (7), we can see that every time a new document with k keywords is uploaded, whether it is an existing keyword or a new keyword, it is equivalent to the client re-executing the search process for each keyword, and updating the trapdoor of the keywords at 2k index positions in array A, without downloading the whole cipher index \(I=(A,T)\) locally and updating it totally, thus reducing the computational overhead and bandwidth consumption of ciphertext update.
4 Deployment and System Test
4.1 Deployment
Figure 3 shows the application deployment and network connectivity of different modules of searchable encryption system. The client software is deployed on the user side, which provides encryption and decryption of user files, file indexes and search requests, sends encrypted ciphertext files to the distributed storage system, and sends encrypted search requests to the cipher search service subsystem.
Service side is constructed based on existed big data platform(take HDFS as an example), so users need to provide HDFS storage system and read-write interface for clients to call. Clients directly store ciphertext files in HDFS, and locate ciphertext files stored in HDFS based on ciphertext keyword index list stored in cipher search subsystem.
Cipher search service subsystem is deployed on a separate server, which is thought to be “honest but curious”. It establishes a ciphertext keyword index list for locating ciphertext files stored in HDFS. It responds to the client search request, searches the ciphertext fole location and returns it to the client.
The key management subsystem provides search keys and file encryption keys for client and provides search keys for search service subsystem.

Deployment of cipher search system.
4.2 System Test
Based on the deployment, we can further construct the environment. We adopted Huawei’s big data platform FusionInsight HDFS system, which is mainly used to store encrypted files and cipher index uploaded by users. The performance indexes of the test equipment are shown in Table 1.
Test of Encryption
In terms of encryption efficiency, we perform 10 encryption tests on files of 100 Mb size, record the time consumption of each file encryption and calculate the average time consumption. As is Shown in Fig. 4. We can see that the encryption efficiency is close to 300 Mbps.

Encryption efficiency of the system.
Test of Efficiency
When it comes to search efficiency, considering the index size of keywords is much smallerthat the size of file. We constructed an index of 100 Mb size for retrieval tests, recorded time consumption of search efficiency, and calculated the average time consumption. As is shown in Fig. 5. We can see that the search efficiency is more than 4000 Mbps, All in all, whether it is encryption or search efficiency, even if the network transmission delay is included, the efficiency will be on the order of milliseconds, which will not affect user experience and gives consideration to security and availability.

Search efficiency of the system.
4.3 Advantage Analysis
Our system supports the storage of ciphertext data and the direct query of the stored ciphertext data. In the query process, the storage end can not know what the user’s query content is, nor can it know the user’s file data.
The system supports the data owner to actively share the ciphertext data stored by himself with other users. In the process of sharing, the storage side cannot know the sharing behavior of users, nor can it know the plaintext of sharex file data. Meanwhile, encrypting the search request ensures that the server can’t perform correlation analysis on the user’s search behavior.
Users can completely control their own data through private keys and the storage end cannot know, steal or disclose users’ plaintext data.
The cipher search system is loosely coupled with the big data platform, which means it can be deployed quickly only by providing the file data read-write interface of the big data platform, which is more practicability than other solutions.
5 Conclusion
In this paper, we have proposed a cipher search system for big data platform on the basis of searchable encryption algorithm. Especially, we have constructed a scheme.
that takes into account both the security and efficient use of the data. Meanwhile, we designed user-centric key management and file level fine-grained encryption and decryption, effectively preventing the risk of data leakage from getting out of control, which greatly improve the security of encrypted data storage and utilization. In the future work, we will further extend data protection to other ciphertext calculate algorithms. For instance, we will perform fully homomorphic encryption, order-preserving encryption and secure multi-Party computation in a big data fashion.
References
Li, H., Yang, Y., Dai, Y., Yu, S., Xiang, Y.: Achieving secure and efficient dynamic searchable symmetric encryption over medical cloud data. IEEE Trans. Cloud Comput. 8(2), 484–494 (2020). https://doi.org/10.1109/TCC.2017.2769645
He, K., Chen, J., Zhou, Q., Du, R., Xiang, Y.: Secure dynamic searchable symmetric encryption with constant client storage cost. IEEE Trans. Inf. Forensics Secur. 16, 1538–1549 (2021). https://doi.org/10.1109/TIFS.2020.3033412
Shen, J., Wang, C., Wang, A., Ji, S., Zhang, Y.: A searchable and verifiable data protection scheme for scholarly big data. IEEE Trans. Emerg. Topics Comput. 9(1), 216–225 (2021). https://doi.org/10.1109/TETC.2018.2830368
Chen, G., et al.: Differentially private access patterns for searchable symmetric encryption. In: IEEE Conference on Computer Communications, Honolulu, USA, pp. 810–818 (2018)
Song, Q., et al.: SAP-SSE: protecting search patterns and access patterns in searchable symmetric encryption. IEEE Trans. Inf. Forensics Secur. 16, 1795–1809 (2021). https://doi.org/10.1109/TIFS.2020.3042058
Mishra, P., et al.: Oblix: an efficient oblivious search index. In: IEEE Symposium on Security and Privacy San Francisco, USA, pp. 279–296 (2018)
Liu, X., Yang, G., Mu, Y., Deng, R.H.: Multi-user verifiable searchable symmetric encryption for cloud storage. IEEE Trans. Dependable Secure Comput. 17(6), 1322–1332 (2020). https://doi.org/10.1109/TDSC.2018.2876831
Wang, Y., et al.: Towards multi-user searchable encryption supporting Boolean query and fast decryption. J. Univ. Comput. Sci. 25(3), 222–244 (2019)
Pang, H., Zhang, J., Mouratidis, K.: Scalable verification for outsourced dynamic databases. VLDB Endowment 2(1), 802–813 (2019)
Belguith, S., et al.: Phoabe: securely outsourcing multi-authority attribute based encryption with policy hidden for cloud assisted IOT. Comput. Netw. 133, 141–156 (2018)
Liu, X., et al.: Privacy-preserving multi-keyword searchable encryption for distributed systems. IEEE Trans. Parallel Distrib. Syst. 32(3), 561–574 (2021). https://doi.org/10.1109/TPDS.2020.3027003
Zhang, K., et al.: Lightweight searchable encryption protocol for industrial Internet of Things. IEEE Trans. Industr. Inf. 17(6), 4248–4259 (2021). https://doi.org/10.1109/TII.2020.3014168
Ge, X., et al.: Towards achieving keyword search over dynamic encrypted cloud data with symmetric-key based verification. IEEE Trans. Dependable Secure Comput. 18(1), 490–504 (2021). https://doi.org/10.1109/TDSC.2019.2896258
Wang, H., et al.: Encrypted data retrieval and sharing scheme in space-air-ground integrated vehicular networks. IEEE Internet of Things J. https://doi.org/10.1109/JIOT.2021.3062626
Sultan, N.H., Laurent, M., Varadharajan, V.: Securing organization’s data: a role-based authorized keyword search scheme with efficient decryption. IEEE Trans. Cloud Comput. https://doi.org/10.1109/TCC.2021.3071304
Mante, R.V., Bajad, N.R.: A study of searchable and auditable attribute based encryption in cloud. In: 2020 5th International Conference on Communication and Electronics Systems (ICCES), pp. 1411–1415 (2020). https://doi.org/10.1109/ICCES48766.2020.9137860
Acknowledgements
This work is supported by the Sichuan Science and Technology Program (2021JDRC0077), the Sichuan Province’s Key Research and Development Plan.
“Distributed Secure Storage Technology for Massive Sensitive Data” Project (2020YFG0298), and Applied Basic Research Project of Sichuan Province (No. 2018JY0370).
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Chen, Y., Hao, Y., Yi, Z., Wu, K., Zhao, Q., Wang, X. (2021). Searchable Encryption System for Big Data Storage. In: Zeng, J., Qin, P., Jing, W., Song, X., Lu, Z. (eds) Data Science. ICPCSEE 2021. Communications in Computer and Information Science, vol 1452. Springer, Singapore. https://doi.org/10.1007/978-981-16-5943-0_12
Download citation
DOI: https://doi.org/10.1007/978-981-16-5943-0_12
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-5942-3
Online ISBN: 978-981-16-5943-0
eBook Packages: Computer ScienceComputer Science (R0)