
Abstract
Traffic control has been one of the most common and irritating problems since the time automobiles have hit the roads. Problems like traffic congestion have led to a significant time burden around the world, and one significant solution to these problems can be the proper implementation of the intelligent transport system (ITS). It involves the integration of various tools like smart sensors, artificial intelligence, position technologies and mobile data services to manage traffic flow, reduce congestion and enhance driver's ability to avoid accidents and reduce incidents or adverse weather. Road and traffic sign recognition is an emerging field of research in ITS. Classification problem of traffic signs needs to be solved as it is a major step in our journey toward building semiautonomous/autonomous driving systems. Traditionally, Mobileye had developed its first commercially deployed traffic sign recognition system with Continental AG for the BMW-7 series vehicles, but this technology has not been used much. The purpose of this work focusses on implementing an approach to solve the problem of traffic sign classification by developing a convolutional neural network (CNN) classifier using the GTSRB — German Traffic Sign Recognition Benchmark dataset. Rather than using hand-crafted features, our model addresses the concern of exploding huge parameters and data method augmentations. Our model achieved an accuracy of around 97.6% which is comparable to various state-of-the-art architectures.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
With the rapid increase in population, people are aiming to look for various alternatives to lead a comfortable and easy life. Self-driving car technology is one such development toward this goal and is one of the newest inventions in the transportation system. Almost every day, new advancements in the field of driverless car technologies are taking place. However, self-driving cars are not yet legal on most of the roads. Although some companies have got permission for testing this technology, running a self-driving car is still illegal in almost all countries. According to DOT which is a US Department of Transportation and NHTSA, around 10,000 people lost their lives in 2019 due to motor vehicle traffic accidents. It also estimated that around 94% of the serious crashes are due to human error only including drunk or distracted driving cases. One of the biggest advantages of autonomous systems as these cars is that they remove such risk factors. However, there are still various challenges as they are vulnerable to mechanical issues that can cause crashes. They must know how to identify traffic signs, other vehicles, branches and other various countless objects in the vehicle's path. Based on this identification, the system must make certain decisions to avoid fatal risks and accidents by taking instantaneous actions like slowing down of the vehicle or control acceleration.
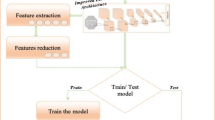
Traffic sign detection and recognition is one of the most important fields in the ITS. Based on the visual impact of traffic signs, self-driving cars can act accordingly and thus automatic recognition can avoid accidents and dangers (Fig. 1).

Convolutional neural network (CNN)
For this problem, our paper proposes a convolutional neural network-based architecture widely for providing high performance in image-based detection tasks. The dataset used for solving this problem is German Traffic Sign Recognition Benchmark (GTSRB) which is a multi-class traffic sign image classification dataset having around 50,000 images of various noise levels. There are several reasons for preferring this model over other state-of-the-art techniques already available. Through dataset analysis, it was observed that it consists of various challenges for which if other techniques or statistical approaches to denoising are applied, it can be computationally very expensive and hence, it is highly unsuitable for real-time applications. On the other hand, neural network-based detection and classification of the noise are computationally effective as well as achieve high performance as far as accuracy and efficiency are concerned. The paper is organized as follows: Sect. 2 explains the attempts done for a similar task. Section 3 presents the methodology used in this paper for the detection as well as classification of traffic signs. Section 4 describes the evaluation metrics used for this task and the results obtained by our methodology. Section 5 refers to the conclusion and discussion of possible extensions of this research.
2 Related Work
A lot of works has already been done in detection and classification of traffic signs for future autonomous vehicle technology. Various convolutional network-based approaches have been used for this task; some of them are described here. In this paper by Garg [1], You Only Look Once (YOLOv2), single-shot detector (SSD) and faster region CNN (faster RCNN) deep learning architectures along with pretrained CNN models were compared for traffic sign detection and classification task. Various pretrained CNN models already trained on ImageNet Dataset were used; YOLOv2 combined with Coco CNN model, SSD combined with inception V2 and faster RCNN combined with ResNet pretrained CNN models were analyzed on the GTSRB dataset. The evaluation parameter used was mean average precision (mAp) and frames per second (FPS). On comparison, it was found out that YOLO is more accurate and faster than SSD and faster RCNN.
Another paper by Wang Canyong [2] proposed a novel and challenging approach of extending SSD algorithm for the traffic sign detection and identification algorithm. During the preprocessing phase, the images were normalized and fed to the VGG-16 front-end framework of the SSD algorithm. The proposed model is composed of five stacked convolution layers, three fully connected layers and a softmax layer. Using a learning rate of 0.001 and batch size of 50 and 20 for train and validation set, respectively, an accuracy rate of 96% was achieved after 20,000 iterations.
Changzhen et al. [3] proposed deep CNNs that were based on Chinese traffic sign detection algorithm using faster RCNN’s region proposal network. There are seven categories of traffic signs in China and the dataset consisting of images from the Internet and roadside scenes from China. The data was augmented by motion blur and applied several levels of brightness on those images. Three different models were trained, namely VGG16, VGG_CNN_M_1024 and ZF. The ZF model had the highest detection efficiency with 60 ms as the average detection time. The model was tested on 33 video sequences captured using a mobile phone and onboard camera. The detection rate of the proposed algorithm was in real time with an efficiency of around 99%.
In another research [4], Xuehong Mao proposed a clustering algorithm based on CNN that was used to separate categories into k different subsets or families. After this, hierarchical CNN was used to train k + 1 classification CNNs, out of which one was for family classification and other k CNNs, corresponding to each family that although achieved 99.67% accuracy, this model was still computationally very expensive. Another research [5] held by Rongqiang Qian proposed an effective feature for the classification Task by using maxpooling positions. They showed how MPP is a better feature through various experiments which indicated that MPPs demonstrate the desirable characteristics of large intraclass variance and small inter-class variance in general but did not improve accuracy further.
Another research team [6] proposed a CNN-ELM model, which integrated the feature learning capacity of CNNs with extreme learning machine (ELM) because of their amazing generalization performance. In this model, firstly CNN was used for learning features and these features were then fed into the fully connected layers that were replaced by ELM for classification. The proposed model trained on GTSRB dataset achieved an accuracy of 99.4% but could not surpass the results of the state-of-the-art algorithms.
In this paper, Cireşan [7] developed a model by combining 25 different CNNs having three convolutional layers and two fully connected layers that could learn more than 88 million parameters. Although it achieved an accuracy of 99.46%, one of the biggest disadvantages of this model was that it used image augmentation due to which a reliable classification accuracy cannot be ensured for unknown data in general.
In this paper, Cireşan et al. [8] proposed a nine-layer CNN along with seven hidden layers consisting of an input layer, three convolutional layers, three maxpooling layers followed by two fully connected layers. In the preprocessing of the data, they cropped the images to equal size. Three different contrast normalization techniques were used in order to reduce high contrast variation in pictures. A grayscale representation of the original images was also produced, and the model was trained on 8 different datasets comprising original as well as sets resulting from three different contrast normalizations of color and grayscale images. Before every epoch in the training phase, images were translated, rotated and scaled based on a uniform distribution over a specified range. A recognition rate of 98.73% was achieved using CNN, and a combination of MLP and CNN achieved a 99.15% recognition rate. Both the models misclassified the ‘no vehicle’ traffic sign.
3 Research Methodology
In this section, we aim to discuss in detail our approach to the proposed CNN model. Section 3.1 refers to the dataset description of GTSRB and its associated statistics. Section 3.2 highlights the challenges faced with analyzing the dataset. Section 3.3 deals with the preprocessing phase overcoming the challenges mentioned previously. Section 3.4 discusses the architecture used and the hyperparameters involved in it.
3.1 Dataset Description
The dataset used for training is generated at the International Joint Conference on Neural Networks (IJCNN) in 2011 for the German Traffic Sign Recognition Benchmark challenge inviting researchers to participate even without some specific domain challenge. This image dataset consists of around 43 classes representing unique traffic sign images. Training set has around 34,799 images (around 67.12%), test set has 12,630 images (around 24.38%), and validation set has 4410 images (8.5%) (Table 1).
3.2 Data Preprocessing
3.2.1 Challenges Faced
3.2.1.1 Low Image Contrast
It can occur due to several factors such as a limited range of sensor sensitivity, bad sensor transmission function and so on. This can be detected by plotting brightness histograms with the values varying from black to white on horizontal axis and number of pixels (absolute or normalized) on the vertical axis. Low image contrast will be observed if either this brightness range given is not fully used or the brightness values are concentrated around certain areas only.
3.2.1.2 Imbalanced Data
As observed from Fig. 2, the data is highly imbalanced as there exists a disproportionate ratio of images in each unique class of traffic sign. Some classes seem to have a lesser number of images than the other which causes class bias as some classes then remain underrepresented. However, there are several approaches to resolve this issue including resampling techniques (oversampling the minority class or undersampling the majority class), generating synthetic samples, changing the performance metric or the algorithm.

Class distribution of the training set
3.2.2 Preprocessing Phase
It aims at solving the mentioned challenges obtained from the dataset by applying various techniques.
3.2.2.1 Data Augmentation
Data augmentation refers to accepting some training images in the form of batches, applying various random transformations to each image present in the batch including random rotation, changes in scale, translations, shearing, horizontal or vertical flips, replacing the original batch with the newly transformed one and finally training the CNN on this new dataset. This is done in order to recognize the target object more effectively as it increases the generalizability of our classifier. Although their appearances might change a bit, still their class labels will remain the same.
OpenCV is used for this task which is a library developed by Intel aimed at real-time computer vision. It is used for performing various image processing operations such as rotation, transformation, translation and soon (Figs. 3, 4, 5 and 6).

Data augmentation

Rotation of images

Translation of image downward

Images after data augmentation
-
1.
Rotation: Images are rotated slightly at around 10 degrees only. More rotation might cause incorrect recognition.
-
2.
Translation: It will move every point in an image by some constant distance in a particular direction. It can also be considered as shifting the origin of the entire coordinate system. Here, this translation shifted the image slightly in downward direction.
-
3.
Bilateral Filtering: It is similar to blurring, but the key difference between them is that blurring smoothens edges whereas a bilateral filter can keep the image’s edges sharp while working on noise reduction. Hence, it is preferred here.
-
4.
Gray Scaling: It is performed so that less information is provided for each pixel that reduces complexity in comparison with a colored image.
-
5.
Local Histogram Equalization: It is applied to increase image contrast.
3.2.2.2 Lass Bias Fixing
To remove the class bias problem, all the classes or unique traffic signs are made to have the same number of image samples which is an arbitrary number that can be obtained on analyzing the dataset from Fig. 2. On observation, a maximum number of records belong to class 2, which is around 2010 records. So, the arbitrary number can be taken as around 4000 which is around twice of 2010 (Fig. 7).

Class distribution after fixing class bias issue
3.3 Activation Function
Activation function is an important part of neural networks as they determine whether information received by a neuron is relevant or should be ignored. It is the nonlinear transformation which is done over the input signal, and its output is then sent to the next layer as input. They are crucial as without them, backpropagation process is not even possible.
3.3.1 ReLU
One of the most commonly used activation functions is ReLU that is rectified linear unit. It is defined as:
One of the biggest advantages of ReLU is that it is nonlinear which makes backpropagation of errors possible and we can have multiple neuron layers activated by ReLU. Also, at a time it activates only a few neurons making the network more efficient as well as easy for computation (Fig. 8).

ReLU activation function
3.3.2 Softmax
Softmax function is another activation function that we mainly use in handling classification problems. It is applied over the final layer of the network which tells how much it is confident in its prediction. This is mainly done by performing two calculations, first exponentiating values received at each node and then normalizing this value by summing up these exponentiated values. The vector returned by the softmax function yields probability scores for each class label since they are easier for interpretation. It is represented by (Fig. 9):

Softmax activation function
3.4 Model Architecture
The CNN architectures are used mostly in image processing applications as it involves processing just like our human brain. They are preferred over feed-forward neural networks as they are capable of capturing the temporal as well as special dependencies as well. In our model, we have built the deep learning model for classifying unlabeled traffic signs using CNN model architecture comprising 4 convolution layers and maxpooling layers. The kernel size is chosen as (3, 3) for these convolutional layers. First, the convolution layer takes an image as input for processing with its shape as (32, 32, 1) as the channels have been preprocessed into grayscale images.
In order to reduce the training time and overfitting, maxpooling layers are then added. Then, two fully connected layers are added which require a one-dimensional vector as input for which flattening is done. In the output layer, we have used the softmax activation function as it is a multi-class classification problem. The model architecture is shown in Fig. 10. This model is run with 700 epochs with GPU for faster processing (Table 2).

Model architecture
4 Evaluation and Results
Accuracy was chosen as the evaluation metric in the German Traffic Sign Recognition Benchmark challenge. Our model was tested on the validation data, and performance results were analyzed with the help of confusion matrix which in simpler terms can be described as a table depicting its confusion while making predictions, also summarizing the performance of any model. With the help of this confusion matrix obtained, accuracy can be obtained as:
where
TP True positive that is the observation is positive and prediction is also positive,
FN False negative that is the observation is positive but the prediction is negative,
TN True negative that is the observation is negative and prediction is also negative,
FP False positive that is the observation is negative but prediction is positive.
Using the proposed model, we have been able to reach a very high accuracy rate of around 97.6%. We also observed that our model starts saturating after 10 epochs. The number of epochs can also be reduced to 10 for decreasing the computation cost.
5 Conclusion and Future Work
In this paper, we developed a CNN architecture for the classification of unique traffic signs for self-driving car technology. We used OpenCV for image augmentation techniques for improving the model performance, and it is also suitable for real-time applications since it involves low computation at every point. For future work, we aim to identify the best architecture along with the best hyperparameters and train our proposed model on a larger dataset. We can try some other preprocessing techniques to improve the model’s accuracy. We can make it a more generalistic system by first using a CNN to localize the traffic signs in realistic scenes and another one to classify them. We can also try some different architectures such as AlexNet or VGGNet and compare their performances.
References
Garg P, Chowdhury DR, More VN (2019) Traffic sign recognition and classification using YOLOv2, Faster RCNN and SSD. In: 10th international conference on computing, communication and networking technologies (ICCCNT) 2019
Canyong W (2018) Research and application of traffic sign detection and recognition based on deep learning. In: International conference on robots & intelligent system (ICRIS) 2018
Changzhen X, Cong W, Weixin M, Yanmei S (2017) A traffic sign detection algorithm based on deep convolutional neural network. In: IEEE international conference on signal and image processing (ICSIP) 2016
Mao X, Hijazi S, Casas R, Kaul P, Kumar R, Rowen C (2016) Hierarchical CNN for traffic sign recognition. In: Intelligent vehicles symposium (IV), 2016 IEEE. IEEE pp 130–135
Qian R, Yue Y, Coenen F, Zhang B (2016) Traffic sign recognition with convolutional neural network based on max pooling positions. In: 2016 12th international conference on natural computation, fuzzy systems and knowledge discovery (ICNC-FSKD). IEEE, pp 578–582
Zeng Y, Xu X, FangY, Zhao K (2015) Traffic sign recognition using extreme learning classifier with deep convolutional features with deep convolutional features. In: The 2015 international conference on intelligence science and big data engineering (IScIDE 2015) vol 9242. Suzhou, China, pp 272–280
Cireşan D, Meier U, Masci J, Schmidhuber J (2012) Multi-column deep neural network for traffic sign classification. In: Neural networks, Elsevier
Ciresan D, Meier U, Masci J, Schmidhuber J (2011) A committee of neural networks for traffic sign classification. In: Dalle Molle Institute for artificial intelligence
Kamal U, Das S, Abrar A, Hasan MK (2017) Traffic-sign detection and classification under challenging conditions: a deep neural network based approach. In: IEEE video and image processing cup 2017
Peng E, Chen F, Song X (2017) Traffic sign detection with convolutional neural networks. In: International conference on cognitive systems and signal processing
Zeng Y, Xu X, Fang Y, Zhao K (2015) Traffic sign recognition using deep convolutional networks and extreme learning machine. In: Intelligence science and big data engineering. Image and video data engineering (IScIDE ). Springer, pp 272–280. https://doi.org/10.1007/978-3-319-23989-7_28
Aghdam HH, Heravi EJ, Puig D (2016) A practical and highly optimized convolutional neural network for classifying traffic signs in real-time. Int J Comput Vis
Zaklouta F, Stanciulescu B (2012) Real-time traffic-sign recognition using tree classifiers. IEEE Trans Intell Transp Syst 13(4):1507–1514. https://doi.org/10.1109/TITS.2012.2225618
Aghdam HH, Heravi EJ, Puig D (2015) A unified framework for coarse-to-fine recognition of traffic signs using bayesian network and visual attributes. In: 10th international conference on computer vision theory and applications (VISAPP), pp 87–96. https://doi.org/10.5220/0005303500870096
Stallkamp J, Schlipsing M, Salmen J, Igel C (2011) The German traffic sign recognition benchmark: a multi-class classification com-petition. In: International joint conference on neural networks
Fleyeh H, Davami E (2011) Eigen-based traffic sign recognition. IET Intel Transport Syst 5(3):190. https://doi.org/10.1049/iet-its.2010.0159
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Kumar, A., Singh, T., Vishwakarma, D.K. (2021). Intelligent Transport System: Classification of Traffic Signs Using Deep Neural Networks in Real Time. In: Singari, R.M., Mathiyazhagan, K., Kumar, H. (eds) Advances in Manufacturing and Industrial Engineering. ICAPIE 2019. Lecture Notes in Mechanical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-15-8542-5_18
Download citation
DOI: https://doi.org/10.1007/978-981-15-8542-5_18
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-8541-8
Online ISBN: 978-981-15-8542-5
eBook Packages: EngineeringEngineering (R0)