
Abstract
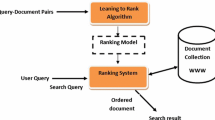
People have realized the importance of finding and archiving information with the computer advents for thousands of years, and storing of large amount of information became possible. It is actually not related to the fetching of the documents, it informs the user on the whereabouts and existence of the documents. In this paper, hybrid model has been used in which the document is classified using the support vector machine (SVM) classifier, and after the condition is applied, if it is satisfied, the extraction of the matched paragraph and the sentence is responsible for the generation of relevant answer. The knowledge base gets updated if condition does not match, and new updated answer will be generated. Finally, the best answer is displayed after ranking by using the PSO optimization. Word2vector is applied for feature extraction. In this paper, comparison of RankSVM, RankPSO and RankHSVM + PSO for the implementation of IR ranking is considered. Here, first SVM is used as a classifier for dividing most relevant and non-relevant results, and afterward PSO is used for the optimization of the result means extraction of the best answer or document. Selection of appropriate parameters is difficult in case of simple SVM, but for the ranking of the answers it gives potential solutions. PSO is used for optimization which has global search capability and is easy to implement and thus to optimize the ranking of document retrieval. We propose the RankHSVM + PSO model to find the fitness function. This technique improves the performance of the system as comparative to other techniques. The result shows that the algorithm applied here improves the value of performance evaluation by 4–5%. TREC 2004 QA DATA dataset is used which contains my datasets. It has a question answering track since 1999. The task was defined in each track. Retrieval of true equivalent test collection for standard retrieval is an open problem. In a retrieval test collection, the unit that is judged the document has a unique identifier.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Telkapalli MK, Fanta H, Appalabatla S (2015) Trends and techniques in information retrieval system (IRS): a comparative study. Int J Adv Res Comput Sci Softw Eng
Cao Y et al. (2006) Adapting ranking SVM to document retrieval. In: Proceedings of the 29th annual international ACM SIGIR conference on research and development in information retrieval. ACM, 2006
Lee JH (1994) Properties of extended Boolean models in information retrieval. In: Proceedings of the 17th annual international ACM SIGIR conference on research and development in information retrieval. Springer, New York, Inc.
Lee DL, Chuang H, Seamons K (1997) Document ranking and the vector-space model. IEEE Softw 14(2):67–75
Jones KS, Steve W, Stephen ER (2000) A probabilistic model of information retrieval: development and comparative experiments: Part 2. Inf Process Manag 36(6):809–840
Kalervo J, Kekäläinen J (2000) IR evaluation methods for retrieving highly relevant documents. In: Proceedings of the 23rd annual international ACM SIGIR conference on research and development in information retrieval. ACM
Kakde PM, Dr. Gulhane SM (2004) A comparative analysis of particle swarm optimization and support vector machines for devnagri character recognition: an android application, Procedia Computer 1877–0509 © 2016 The Authors. Published by Elsevier B.V. This is an open access article under the CC BY-NC-ND license Peer-review under responsibility of the Organizing Committee of ICCCV 2016 https://doi.org/10.1016/j.procs.2016.03.044 Science Direct 7th International Conference on Communication, Computing and Virtualization 2016. Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval, pages 64-71, 2004
Liu T-Y, Xu J, Qin T, Xiong W, Li H, LETOR: benchmark dataset for research on learning to rank for information retrieval
Pandey G, Ren Z, Wang Z, Vaijilainen J, De Rijke M (2018) Linear feature extraction for ranking. Inf Retrieval J Springer link 21(6):481–506
Agbele K, Ayetiran E, BabalolaO (2018) A context-adaptive ranking model for effective information retrieval system. Copyright © 2018 The Author(s). Published by Scientific & Academic Publishing
Fan Q, Liu X, Zhang Y, Bao F, Li S (2018) Adaptive mutation PSO based SVM model for credit scoring. CSAE ‘18, October 22–24, 2018, Hohhot, China © 2018 Association for Computing Machinery. ACM ISBN 978-1-4503-6512-3/18/10…$15.00 https://doi.org/10.1145/3207677.3278014
Pandey S, Mathur I, Joshi N (2019) Information retrieval ranking using machine learning techniques. In: Amity international conference on artificial intelligence (AICAI), IEEE
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Pandey, S., Mathur, I., Joshi, N. (2021). Hybrid Model with Word2vector in Information Retrieval Ranking. In: Khanna, A., Gupta, D., Pólkowski, Z., Bhattacharyya, S., Castillo, O. (eds) Data Analytics and Management. Lecture Notes on Data Engineering and Communications Technologies, vol 54. Springer, Singapore. https://doi.org/10.1007/978-981-15-8335-3_58
Download citation
DOI: https://doi.org/10.1007/978-981-15-8335-3_58
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-8334-6
Online ISBN: 978-981-15-8335-3
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)