
Abstract
As feature data in multimodal remote sensing images belong to multiple modes and are complementary to each other, the traditional method of single-mode data analysis and processing cannot effectively fuse the data of different modes and express the correlation between different modes. In order to solve this problem, make better fusion of different modal data and the relationship between the said features, this paper proposes a fusion method of multiple modal spectral characteristics and radar remote sensing imageaccording to the spatial dimension in the form of a vector or matrix for effective integration, by training the SVM model. Experimental results show that the method based on band selection and multi-mode feature fusion can effectively improve the robustness of remote sensing image features. Compared with other methods, the fusion method can achieve higher classification accuracy and better classification effect.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Remote sensing images can accurately and comprehensively describe the features of ground objects and are widely used in agriculture, geological exploration, environmental monitoring and military reconnaissance [1,2,3,4]. At present, many algorithms are used in identification classification, such as maximum likelihood method [5], minimum distance method [6], artificial neural network [7] (ANN), k-means clustering [8], and so on. Theoretically, the sample size of these methods must be large enough to ensure high-level, but in practice, it is not guaranteed to select enough classification samples. Support vector machine (SVM) method is a new type of data mining method [9], which has outstanding advantages in small sample, nonlinear and high-dimensional pattern recognition. Therefore, it can be widely used in distributed classification research and has achieved good results.
At present, the rapid development of satellite technology and the increasing number of sensors not only improve the quality of remote sensing images, but also result in the coexistence of multiple types and resolutions of remote sensing images. Optical sensor and synthetic aperture radar image, as the most important two kinds of sensor data, have their own advantages and disadvantages. Although they both have excellent performance in ground object identification, they rarely cooperate with each other and fail to make full use of the existing surface information. The fusion technology of remote sensing image came into being. The image fusion technology is classified according to different standards. According to the level of fusion, the fusion method is divided into three categories: pixel level, feature level and decision level. In the research of multi-source remote sensing image fusion method, the pixel-level fusion is widely used in the field of remote sensing image fusion due to its advantages of high computing accuracy, small data change and less information loss.
In the past 20 years, many researchers at home and abroad have proposed many fusion algorithms of different strategies. Ramakrishnan et al. fused panchromatic images with multispectral images using the improved IHS transform, and also discussed the application of fused images in earth science [10]. According to the spectral characteristics and application prospects of multi-spectral bands in Ref. [11], PCA, IHS and HPF methods were compared in maintaining the spectral quality of fusion images. Dupas proposed using Brovery transform and IHS method to fuse SAR images and multi-spectral images for land cover classification [12]. Single sensor data and fusion data are used for classification, and the overall classification accuracy of fusion data is higher than that of pure multi-spectral data. Chen et al. used IHS transformation to merge hyperspectral images with SAR images at hyperspectral resolution to obtain enhanced features of urban areas [13]. The fused image was superimposed on the digital elevation model (DEM) to obtain a three-dimensional image. This integration helps to resolve the ambiguity of different types of land cover. Pal et al. proposed a PCA-based fusion method to improve geological interpretation [14]. FFT method was used to filter SAR images, PCA was used to fuse multi-spectral data, and then the principal component selection method based on features was used to conduct false color synthesis of the fused data. Chandrakanth et al. applied HPF to the frequency domain and fused high-resolution panchromatic and high-resolution SAR images [15]. This method extracted low-frequency details from panchromatic images and high-frequency details from SAR images. Battsengel et al. proposed the fusion of high-resolution optical images and SAR images to improve the accuracy of land cover classification [16]. The method of multiplication was used to fuse the source images, and the fusion method based on BT, PCA and IHS was adopted. The results were compared visually on the basis of classification accuracy. Yang et al. used GS orthogonalization method to integrate optical images and SAR images to improve the classification of coastal wetlands [17]. The above methods are not computationally complex and can produce a fusion product with rich spatial information. However, these methods are highly dependent on the correlation of image fusion, so that the image after fusion has obvious spectral distortion.
In view of the above problems, this paper first selected the bands of Landsat8 images, selected the optimal three bands, and used HSV transform to effectively integrate the multi-spectral image features and sentinel-1 SAR image features in the form of vector or matrix according to the spatial dimension, so as to train the SVM model and obtain better ground object recognition effect.
2 Classification Principle of Support Vector Machines
The mechanism of support vector machine (SVM) is to find an optimal classification hyperplane that meets the classification requirements, so that the hyperplane can maximize the empty space on both sides of the hyperplane while ensuring the classification accuracy. Taking two types of data as examples, the given training set \( \left( {x_{i} ,y_{i} } \right) \), \( i = 1, \ldots ,l;\,x \in R^{n} ,\,y \in \left\{ { + 1, - 1} \right\} \) and hyperplane are denoted as \( \left( {w \cdot x} \right) + b = 0 \). In order for the classifier to correctly classify all samples and have classification intervals, the following constraints need to be met:
We can calculate the classification interval \( 2/\left\| w \right\|, \) so the problem of constructing the optimal hyperplane is transformed into:
In high-dimensional space, if the training sample is indivisible or it is not known whether it is linearly separable, it will allow the introduction of a certain number of misclassified samples, and a non-negative relaxation variable \( \zeta_{i} \) will be introduced. The above problem is transformed into a quadratic programming problem with linear constraints:
However, in actual classification, it is difficult to ensure linear separability between categories. For the case of linear inseparability, SVM introduces a kernel function, maps the input vector to a high-dimensional feature vector space, and constructs the best classification surface in the feature space. Due to the good performance of the RBF kernel function, the radial kernel function is selected as the kernel function of the SVM in practical applications.
3 Classification of Remote Sensing Images Based on Band Selection and Multi-mode Feature Fusion
3.1 Correlation-Based Feature Selection (CFS)
CFS [18] is a classic filtering type feature selection algorithm. It evaluates the influence of each feature on each classification separately by heuristics, so as to obtain the final feature subset. The evaluation method is shown in formula (5):
Among them, \( M_{s} \) represents the evaluation of the feature subset S containing k features; \( r_{cf} \) represents the average correlation between attributes and classification; \( r_{ff} \) represents the average correlation between attributes. The higher the computational correlation between each attribute and the classification attribute, or the lower the redundancy between the attributes, the more positive the evaluation. In CFS, information augmentation is used to calculate correlations between attributes. The method of computing information enhancement will be described below.
Assuming that the attribute is Y, \( \upgamma \) represents each possible Y value, the entropy of Y is calculated from Eq. (6).
For the known attribute X, Y’s entropy is calculated by Eq. (7)
The difference \( {\text{H}}\left( Y \right) - {\text{H}}\left( {Y{ \setminus }X} \right) \) (namely the reduction of feature Y’s entropy) reflects the additional information attribute X provides to attribute Y, also known as information enhancement. The information increment reflects the amount of information provided by X to Y, so the larger the information increment, the stronger the correlation. Since information enhancement is a symmetric measure, its disadvantage is that it tends to select those attributes with more potential values. Therefore, each attribute needs to be information enhanced and normalized to ensure that each attribute can be compared with other attributes so that different attribute selections can get the same result. The method of symmetric uncertainty is used to normalize it into [0, 1].
3.2 HSV Transform Fusion Method
HSV transform is an inverted cone color space composed of Hue, Saturation and Value, which transforms the color space composed of RGB three colors in multi-spectral images [19]. The basic idea of HSV transformation is to replace the brightness Value in the original image with a high-resolution full-color remote sensing image, and then re-sample the Hue and Saturation into the high-resolution size image through interpolation (nearest neighbor method, bilinear interpolation method and cubic convolution interpolation method), and finally convert the image back to the RGB color space.
4 Experiments and Analysis
4.1 Data Source and Preprocessing
Landsat8 remote sensing data from September 10, 2015 and sentinel-1 standard polarization model data were mainly used in this paper. The Sentinel-1 standard polarization model data included a scene on December 23, 2015, with a VV spatial resolution of 15 m and an incidence Angle of 37°. The data processing of this paper mainly includes the following parts:
Landsat8 remote sensing data were imported into ENVI5.3 software, and on the basis of 1:50,000 topographic map, the intersection points of rivers and roads were selected as control points for geometric correction of Landsat8 remote sensing data. Afterwards, the 1–7 bands of Landsat8 remote sensing data were fused with panchromatic bands, and the required study areas were intercepted according to the research needs.
Using the ENVI extension package SAR scape, the Sentinel-1 standard polarization pattern data was radiative scaled, and the amplitude intensity image was converted into the backscattering coefficient image. Then the Lee filtering algorithm of 7 × 7 filter window is used to remove the speckle noise of radar image. The filtered image was converted into a transverse Mercator (UTM) projection and resamped to 30 m. Due to the different sensor of acquired radar image and optical image, the imaging mode of each satellite is different, so the space registration should be carried out. Using ENVI5.3 software, the radar images were registered based on Landsat8 image data dated 10 September 2015.
4.2 Experimental Data and Sample Selection
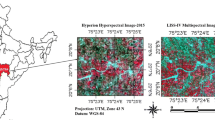
Study area selection, western songnen plains in western jilin province county territory of adlai was in charge of the town, momo, national nature reserve (

 ). According to the distribution of land features in this area, it is divided into 6 categories: unused land, grassland, marsh, wetland, water area, residential land and cultivated land. In this paper, a total of 16 160 pixel-level training samples were selected, among which 30% of each ground object was randomly selected as the verification set, and the remaining data samples were selected as the training set.
). According to the distribution of land features in this area, it is divided into 6 categories: unused land, grassland, marsh, wetland, water area, residential land and cultivated land. In this paper, a total of 16 160 pixel-level training samples were selected, among which 30% of each ground object was randomly selected as the verification set, and the remaining data samples were selected as the training set.
4.3 Classification and Accuracy Verification
SVM classifier using ENVI5.3 remote sensing software. The spectral characteristics of 1–7 bands of Landsat8 remote sensing data, spectral characteristics after band selection (CFS), and spectral characteristics after band selection (CFS) and radar fusion were used respectively to extract wetland information by integrating topographic assistance data and radar image backscattering. The results are shown in Fig. 1 (a), Fig. 1 (b) and Fig. 1 (c). The classification results of 578 measured sample points were selected for accuracy verification, and the error confusion Matrix was established by using the tool ENVI5.3 confusion Matrix. The accuracy evaluation results obtained are shown in Table 1, Table 2 and Table 3 respectively.

(a), (b), (c) Results of extracting wetland information using SVM with three different features
5 Conclusions
Based on the principle of image fusion, from a practical perspective, this paper puts forward a fusion method of multiple modal spectral characteristics and radar remote sensing image. It implemented the image Landsat8 band selection, chose the best three bands, and reused of HSV transform the multispectral image and effective Sentinel-1 SAR radar image fusion, and trained the SVM model, extract the feature information of wetland. Experimental results show that the method based on band selection and multi-mode feature fusion can effectively improve the robustness of remote sensing image features. Compared with other methods, the fusion method can achieve higher classification accuracy and better classification effect.
References
Zhao, M., et al.: A robust delaunay triangulation matching for multispectral/multidate remote sensing image registration. IEEE Geosci. Remote Sens. Lett. 12(4), 711–715 (2015)
Izadi, M., Saeedi, P.: Robust weighted graph transformation matching for rigid and nonrigid image registration. IEEE Trans. Image Process. 21(10), 4369–4382 (2012). A Publication of the IEEE Signal Processing Society
Shahdoosti, H.R., Ghassemian, H.: Fusion of MS and PAN images preserving spectral quality. IEEE Geosci. Remote Sens. Lett. 12(3), 611–615 (2014)
Akhavan-Niaki, H., et al.: Evaluation of spatial and spectral effectiveness of pixel-level fusion techniques. IEEE Geosci. Remote Sens. Lett. 10(3), 432–436 (2013)
Chen, F., Wang, C., Zhang, H.: Remote sensing image classification based on an improved maximum-likelihood method: with SAR images as an example. Remote Sens. Land Resour. 28(1), 75–78 (2008)
Liu, J., Zhang, C., Wan, S.: The classification method of multi-spectral remote sensing images based on self-adaptive minimum distance adjustment. In: Li, D., Chen, Y. (eds.) CCTA 2012. IAICT, vol. 393, pp. 430–437. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-36137-1_50
Yu, X., Dong, H.: PTL-CFS based deep convolutional neural network model for remote sensing classification. Computing 100(8), 773–785 (2018). https://doi.org/10.1007/s00607-018-0609-6
Wu, T., Chen, X., Xie, L.: An optimized K-means clustering algorithm based on BC-QPSO for remote sensing image. In: IGARSS 2017 - 2017 IEEE International Geoscience and Remote Sensing Symposium. IEEE (2017)
Yu, X., Dong, H., Patnaik, S.: Remote sensing image classification based on dynamic co-evolutionary parameter optimization of SVM. J. Intell. Fuzzy Syst. 35(1), 343–351 (2018)
Ramakrishnan, N.K., Simon, P.: A bi-level IHS transform for fusing panchromatic and multispectral images. In: Proceedings of 5th International Conference on Pattern Recognition and Machine Intelligence, pp. 367–372 (2011)
Rokhmatuloh, R., Tateishi, R., Wikantika, K., et al.: Study on the spectral quality preservation derived from multisensor image fusion techniques between JERS-1 SAR and landsat TM data. In: Proceedings of International Geoscience and Remote Sensing Symposium (IGARSS), pp. 3656–3658 (2003)
Dupas, C.A.: SAR and LANDSAT TM image fusion for land cover classification in the Brazilian atlantic forest domain. In: Proceedings of 19th International Congress for Photogrammetry and Remote Sensing, pp. 96–103 (2000)
Chen, C.M., Hepner, G.F., Forster, R.R.: Fusion of hyperspectral and radar data using the IHS transformation to enhance urban surface features. ISPRS J. Photogram. Remote Sens. 58(1), 19–30 (2015)
Pal, S.K., Majumdar, T.J., Amit, K.: ERS-2 SAR and IRS-1C LISS III data fusion: a PCA approach to improve remote sensing based geological interpretation. ISPRS J. Photogram. Remote Sens. 61(5), 281–297 (2007)
Chandrakanth, R., Saibaba, J., Varadan, G., et al.: Fusion of high resolution satellite SAR and optical images. In: International Workshop on Multi-Platform/Multi-Sensor Remote Sensing and Mapping, pp. 1–6 (2011)
Battsengel, V., Amarsaikhan, D., Bat-erdene, T., et al.: Advanced classification of lands at TM and Envisat images of Mongolia. Adv. Remote Sens. 2(2), 102–110 (2013)
Yang, J.F., Ren, G.B., Ma, Y., et al.: Coastal wetland classification based on high resolution SAR and optical image fusion. In: International Geoscience and Remote Sensing Symposium, pp. 886–889 (2016)
Yu, L., Liu, H.: Feature selection for high-dimensional data: a fast correlation-based filter solution. In: Proceedings of the Twentieth International Conference Machine Learning (ICML 2003), Washington, DC, USA, 21–24 August 2003. AAAI Press (2003)
Zhu, Q., Liu, B.: Multispectral image fusion based on HSV and red-black wavelet transform. Comput. Eng. (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Yu, X., Dong, H., Mu, Z., Sun, Y. (2020). Classification of Remote Sensing Images Based on Band Selection and Multi-mode Feature Fusion. In: Zeng, J., Jing, W., Song, X., Lu, Z. (eds) Data Science. ICPCSEE 2020. Communications in Computer and Information Science, vol 1257. Springer, Singapore. https://doi.org/10.1007/978-981-15-7981-3_45
Download citation
DOI: https://doi.org/10.1007/978-981-15-7981-3_45
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-7980-6
Online ISBN: 978-981-15-7981-3
eBook Packages: Computer ScienceComputer Science (R0)