
Abstract
In recent years, natural disasters, such as earthquakes, landslides and others, have caused significant damage to people’s lives and property. Victims are often trapped in collapsed buildings. Thus the development and understanding of modern techniques for disaster relief are of immense current interest and need. As a significant advancement in wireless communication, the emerging UWB Radar Technology is a key technology that UWB is applied in object identification, which is characterized by high resolution, good anti-interference ability and strong penetrability and so on, has been widely used in various fields, including natural disaster detection, through-wall radar imaging, ground penetrating radar technology, medical imaging, target ranging and personnel positioning, disaster relief and so on. In this chapter, the author will describe some algorithms for human detection based on UWB radar sensor network in natural disaster. Firstly, we study the fuzzy pattern recognition and genetic algorithm which is used to identify the multi-status human being after the brick wall. The main characteristic parameters are selected and extracted from the received signal, and each feature parameters corresponding to a sub membership function. Through the genetic algorithm to optimize the sub membership function for constructing the membership function set. According to fuzzy pattern recognition principle of maximum degree of membership function to establish target prediction function, and used MATLAB to carry on the simulation for it. Secondly, we study the stacked denoising autoencoder algorithm in deep learning to study the through wall human target recognition under imbalanced samples of single sensor and multi-sensor data respectively. The experimental results show that the stacked denoising autoencoder algorithm in deep learning adopted herein allows more effective classification and identification of through wall human targets under imbalanced sample conditions than other algorithms, and that the identification effect with multiple sensors under a certain imbalance rate is better than that with a single sensor.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- UWB radar
- Through-wall human being detection
- Fuzzy pattern recognition
- Genetic algorithm
- Imbalanced samples
- Autoencoder
- Deep learning
1 Background of Human Detection Based on Radar Sensor Networks
The first generation of radar was started in the 1920s at the beginning of 1924–1938 years. It used only the reflection of the electromagnetic wave to achieve some simple functions, the frequency range in the tens of megahertz, resolution and accuracy is not high, ranging in scope within one hundred km. The second generation of radar is produced in 1936–1960 years, the development of radar devices and technology is more advanced. The generation of the third generation of radar is in 1971–1990 years or so. This generation of radar uses computers, microprocessors and large scale integrated circuits to improve radar performance, reduce radar volume and weight, and improve the reliability of information processing. The fourth generation of radar came into being after 2000, and this generation of radar is to further reduce the volume and weight of the radar by using smaller, more reliable devices. The UWB technology, originally developed by the Defense Advanced Research and Planning Agency, was called baseband, non-carrier, Pulse communications, or time domain signal transmission until 1989, when the Department of Defense named it Ultra-Broadband. From the emergence of the concept to the 1990s, ultra wide band technology was primarily based on the initial impulse radio technology using pulse width of nanosecond or sub nanosecond as information carrier, and was used primarily for military radar and wireless systems with low cargo and detection rates. Ultra wideband radar can be divided into military and civilian radar in accordance with the purposes, including military radar, warning radar, radar, IFF, mainly for the detection of landmines, detecting the hidden military targets with foliage camouflage dangerous objects; and civilian radar including navigation radar, weather radar, radar, weather radar at weather disasters, especially in monitoring and early warning of sudden disaster weather plays a very important role in [1]. The advantages of UWB are high resolution and multipath fading. Large system capacity, high transmission rate; Low interference, good confidentiality; Precise positioning capability; Low power consumption, long continuous use; Small size, low cost, flexible [2].
UWB radar signal is the radar antenna electromagnetic waves emitted by any direction emission, if there are objects in the direction of the above goals, the reflection of electromagnetic wave reflection, this contains all kinds of information received by the target and the radar antenna, the receiving device to process the signal, obtaining effective information of targets. From the process of radar signal sending and receiving, it can be found that UWB signals will be received after different targets, and there are target characteristics information in the received signals, but there are obvious differences between them. Therefore, extracting the characteristic parameters required for the reaction of the target information in the received signal, which is used in some classification algorithms, classification and identification of target for the ultra wideband radar used to detect around the target, play an important role in hazardous environments or under special circumstances or buried under the wall human rescue.
UWB radar has the advantages of strong penetration, high range resolution, strong clutter suppression, high location accuracy, insensitivity to channel fading and low power consumption. It can penetrate, wall and other media, and detect, track and locate targets behind the wall. At present, the ultra wideband radar in penetration of various materials of wall on the wall after the human target detection has been widely used, has accumulated abundant research achievements in various fields, such as airport security, reconnaissance through terrorists in daily counter-terrorism operations, the police can determine the specific location of the terrorists and hostages with it to provide strong support for the arrest of terrorists and rescue the hostages, trapped in the rubble, fires, earthquakes, avalanches and other emergency situations, rescue personnel can use it to find the location of trapped persons, in order to maximize the life saving time also includes the location, medical monitoring, UWB radar technology has the application of [3,4,5,6] is widely used in military and civil fields. UWB radar is becoming more and more mature for human body target recognition.
2 State of the Art in Target Detection Based on UWB Radar Sensor Networks
Due to its own high-range resolution, wide bandwidth and other outstanding features of UWB radar technology, it has become the best choice for through wall human target recognition. In addition, the UWB pulse itself has a very high propagation energy in the frequency range of the bandwidth and strong wall penetration [7]. Through wall human target recognition has important application value in the field of military and civilian applications. The problem of through wall human target recognition has gradually become the hot spot of scholars at home and abroad. Currently, researchers have made a great deal of research achievements in the field of human target recognition.
In [8], it studied the technology of wall detection for different types of walls. In this chapter, a single-pulse UWB radar is used to detect stationary human targets. A new method based on short-time Fourier transform is proposed. The existing The clutter suppression technique based on singular value decomposition is applied to different types of walls for wall detection. In [7], it applied UWB radar to human body through the wall and proposed a method based on Fast Fourier Transform and S-Transform to detect and identify the life characteristics of human body. The center frequency of vital signal was extracted from the experimental data Accurately locate the location of human targets. Compared with other human detection through the wall, the chapter focuses on the processing and identification of life signals under strong clutter. One can use this method to search for and locate survivors trapped under buildings during earthquakes, explosions or fires. In [9], it used wall-penetrating radar to detect and locate human targets hidden behind obstacles. This chapter introduces a new adaptive detection technology for human detection based on exponential averaging with weighted coefficients. The experiment shows a moving measurement of a human body through the wall to detect and locate the target. The detection of human signal is very challenging, because the signal may be buried by noise using ultra-wideband radar sensor to study the measurement of signal through the wall, the article uses ultra-wideband radar PulsOn 220 through the human body Probing experiments, conducted through two different types of walls, gypsum walls and wooden doors, show the detection of human targets hidden behind walls or in buildings, which is of interest to rescue, surveillance and safety operations [10]. In [11, 12], it used UWB random noise radar for wall penetration monitoring and wall penetration imaging. The experimental results show that the UWB random noise radar can be used to detect and track the human being sheltered by the building wall, and at the same time can conceal the target image. In [13], it proposed an UWB radar based on the empirical mode decomposition of cross-correlation filters, which can effectively detect and locate coal miners. In [14], it developed a UWB-based UWB synthetic aperture radar with the purpose of verifying the penetration ability of the UWB radar cluster and the high-resolution imaging ability of the hidden target. In [15], it used Doppler radar systems to detect stationary human targets obstructed by walls and obstacles, and identifies the presence of human beings by detecting respiratory-induced Doppler signals and the movements of the human arm and wrist. Experimental results show that The Doppler radar system extracts the validity of the Doppler signal corresponding to human activity. In [16], it discussed UWB radar penetration detection technology. Due to the large amount of UWB radar data, compression sensing theory is introduced to collect UWB data. In this chapter, the singular values of compressed radar data are obtained by singular value decomposition and the compressed UWB radar data of the two target states of human body after gypsum wall are collected. The experimental results show that the singular value increases when there is a human target behind the wall when compared to the state without human target behind the wall. In [17], it studied ultra-wideband radar for detecting and locating people or any non-metallic obstacles that are obscured by walls and obstacles. Ultra-wideband sensor networks can be used in targeting and imaging of targets, intrusion detection of surrounding targets, in-vehicle sensing, monitoring of outdoor sports, testing of freeways and bridges, and other civil facilities [18]. Estimation algorithms based on TOA (Time of Arrival) and received signal strength are also used in UWB sensing networks to identify NLOS channels [19]. According to the statistical characteristics of multipath channels in [19], parameters such as average additional delay, mean square delay and value are extracted in the impulse response, and the joint probability density function is used to detect whether the channel is a line-of-sight channel or a non-line-of-sight channel.
3 Through-Wall Human Being Detection Based on Fuzzy Pattern Recognition
3.1 Theory
In this chapter, the UWB radar equipment is used to identify the multi-status human being after the brick wall by the fuzzy pattern recognition and genetic algorithm. Firstly, The main characteristic parameters are selected and extracted from the received signal, and each feature parameters corresponding to a sub membership function. Then, Through the genetic algorithm to optimize the sub membership function for constructing the membership function set. Lastly, According to fuzzy pattern recognition principle of maximum degree of membership function to establish target prediction function, then used MATLAB to carry on the simulation for the experiment results. The algorithm is shown in follow:
Algorithm 1: Through-wall human being detection based on fuzzy pattern recognition |
|---|
Step 1: Extracting feature parameters to construct sub membership function |
Step 2: Using genetic algorithm to optimize the membership function for constructing membership function set |
Step 3: Construction of target prediction function by fuzzy pattern recognition algorithm |
Step 4: Based on the principle of maximum membership degree realize the multi-status target recognition behind the wall |
3.1.1 Selection and Extraction of Characteristic Parameters
The task of feature selection and feature extraction is to determine the data which are meaningful to the classification as characteristic data according to the measured data. These data can not only reflect the similarity of the same pattern, but also reflect the difference of different types of models. The purpose is to constitute characteristics for recognition and identification through feature selection and extraction and to preserve the classified information as much as possible while ensuring certain classification accuracy. The characteristics of recognition objects include physical features, structural features and mathematical features. In this chapter, the mathematical features of data are extracted as the characteristic parameters of through wall multi-status human being detection. There are six kinds of status in through-wall recognition, each status has its corresponding characteristic parameters which mainly comprise the kurtosis, skewness, energy, maximum amplitude, variance and covariance of the received signal. Kurtosis is a measure of the “tailedness” of the probability distribution of a real-valued random variable as shown in formula (3.1). Skewness is a measure of the asymmetry of the probability distribution of a real-valued random variable about its mean as shown in formula (3.2). This chapter selected a total of 36 characteristic parameters, the characteristic parameters of each status are defined as follows:
By extracting the characteristic parameters of the received signal, a set of membership functions for target recognition is constructed.
3.1.2 Genetic Algorithm Theory
The basic idea of genetic algorithm is to encode the optimized parameters first and then process the individuals obtained after the encoding. Therefore, the genetic algorithm can not only optimize and solve the traditional objective function, but also can optimize and solve the structural object, such as using the genetic algorithm to optimize the matrix and graphics [20]. The fitness function is used to evaluate multiple parameters of the search space at the same time, each possible problem is expressed as a chromosome, and then the selection, crossover and mutation operations are performed according to the genetic laws until the termination condition is satisfied.
Since the fuzzy concepts in practical application are various, we cannot define a generic membership function to represent all cases in practical applications. So the quality of membership selection does not have a unified evaluation standard at present. The membership functions commonly used in MATLAB include triangular membership function, trapezoidal membership function, Gaussian membership function, B-Gaussian membership function, bell-shaped membership function, etc. After comprehensive consideration and practical analysis, this chapter selects the Gaussian function as the sub-membership function. The Gaussian function is defined as follows:
Wherein a is the mean, b is the variance, both parameters can be obtained by the genetic algorithm. The membership function set includes 36 sub-membership functions, and 72 parameters need to be optimized. The formula of the membership function set is as follows:
The mean and variance of the Gaussian function are optimized by the genetic algorithm. In this chapter, the population type of the genetic algorithm is double vectors. Suppose the number of the initial population is 150, the variables that need to be optimized are the mean and variance, which represent genes in the heritage algorithm, 72 in total. The range of each variable is 0.1–1.5. The fitness function is defined as follows:

Wherein \( {\text{right}}\_{\text{w}}_{\text{i}} \) refers to the \( {{i}}{\text{th}} \) correctly recognized through-wall no person status. Similarly, \( {\text{right}}\_{\text{h}}_{\text{i}} \) refers to the through-wall normal breathing status, \( {\text{right}}\_{\text{j}}_{\text{i}} \) refers to the through-wall two person normal breathing status, \( {\text{right}}\_{\text{z }}_{\text{i}} \) refers to the through-wall two persons walking 2 m away status, \( {\text{right}}\_{\text{k}}_{\text{i}} \) refers to the through-wall swing arms status, and \( {\text{right}}\_{\text{s}}_{\text{i}} \) refers to the through-wall three persons normal breathing status. Since this chapter uses MATLAB to realize the genetic algorithm, the fitness function is optimized according to the minimum value, therefore this chapter chooses the reciprocal of the total recognition accuracy of all status as fitness function. Individual generic selection is conducted according to the fitness function. In the genetic algorithm, selection, crossover and mutation are the most basic operations. We choose the roulette algorithm as the selection algorithm and select the single point crossover algorithm, the crossover probability being 0.8, the mutation probability being 0.2, and the genetic algebra being 100 generations. The termination condition is that the genetic algorithm will terminate when it reaches the genetic algebra or the fitness value of the parameter individual reaches the ideal result.
3.1.3 Fuzzy Pattern Recognition Theory
The basis of fuzzy pattern recognition is fuzzy mathematics which has only 40 years of history since its inception in 1965. Fuzzy pattern recognition has been an active research field of fuzzy application since the birth of fuzzy mathematics. The research contents comprise computer image recognition, handwritten text automatic recognition, cancer cell recognition, white blood cell identification and classification, disease prediction, classification of various types of information and so on [21].
Definition of fuzzy set: a fuzzy subset A in a given domain of discourse refers that for any \( {\text{x}} \in {\text{X}} \), a number \( {\upmu }_{\text{A}} ( {\text{x}} ) \) is determined. \( {\upmu }_{\text{A}} ( {\text{x}} ) \) is referred to as the degree of membership of x for the fuzzy set A, and \( \upmu_{\text{A}} ({\text{x}}) \in [0,1] \). Mapping \( {\upmu }_{\text{A}} ( {\text{x}} ) : {\text{X}} \to [0,1] , {\text{x}} \to {\upmu }_{\text{A}} ({\text{x}}) \). \( {\upmu }_{\text{A}} ( {\text{x}} ) \) is referred to as the membership function of A, which is used to describe the degree of membership of the factors in the subset A for A. The value of the membership function is referred to as the degree of membership. The larger the degree of membership is, the higher the degree that x affiliates to A will be. The fuzzy subset is usually referred to as the fuzzy set or fuzzy sets.
Representation method of the fuzzy set: In the practical application, there are many ways to represent the fuzzy set. In principle, it is required to show the relationship between all the elements in the domain and its corresponding membership degree. Such methods include the summation representation, the integral representation, ordered pair representation, vector notation and other methods. Methods of Fuzzy Pattern Classification: (1) Direct Method, The method of directly judging the affiliation of the sample by calculating its membership degree is referred to as the membership principle of the pattern classification. Supposing that there are N fuzzy sets \( {\text{A}}_{1} , {\text{A}}_{2} , \ldots ,{\text{A}}_{\text{N}} \) in the domain X and each fuzzy set \( {\text{A}}_{\text{i}} \) has a membership function \( {\upmu }_{{{\text{A}}_{\text{i}} }} ( {\text{x}} ) \), then for any \( {\text{x}} \in {\text{X}} \), if
It will be considered that x is subordinate to \( {\text{A}}_{\text{i}} \). The membership principle is also referred to as the direct method of fuzzy pattern recognition, which is used for recognition of a single pattern. (2) Indirect Method, unlike the membership principle, the near-selection principle is a method for group recognition. Supposing that there are n known types of fuzzy subsets \( {\text{A}}_{1} , {\text{A}}_{2} , \ldots ,{\text{A}}_{\text{n}} \) in the domain x, if \( {\text{i}} \in \left\{ {1,2, \ldots ,{\text{n}}} \right\} \), then
Wherein \( {\upsigma }\left( {{\text{A}},{\text{B}}} \right) = 1 - {\text{C}}\left[ {{\text{d}}\left( {{\text{A}},{\text{B}}} \right)} \right]^{\text{d}} \), C and d are two properly selected parameters, \( {\text{d}}({\text{A}},{\text{B}}) \) can be different distances. Relative to \( {\text{A}}_{1} ,{\text{A}}_{2} , \ldots ,{\text{A}}_{{{\text{i}} - 1}} ,{\text{A}}_{{{\text{i}} + 1}} , \ldots ,{\text{A}}_{\text{u}} \), if B is closest to \( {\text{A}}_{\text{i}} \), B belongs to the category of \( {\text{A}}_{\text{i}} \) pattern.
In this chapter, the method of fuzzy pattern classification is a direct method. The characteristic parameters are extracted from the received signal, and six feature parameters are extracted from each status, including kurtosis, skewness, the maximum amplitude of the received signal, the variance of the received signal and the covariance. The Gaussian function is selected as the sub-membership function, each characteristic parameter of each scene corresponds to a sub-membership function \( {\text{f}}( {\text{x}} ) \), thus six scenes have a total of 36 sub-membership functions, as shown in Table 1.
In this chapter, six kinds of scenes are set up, and six characteristic parameters are extracted in each scene. Therefore, the target is represented by six characteristic parameters, namely \( {\text{S}}_{\text{c}} = \left[ {{\text{S}}_{{{\text{c}}_{1} }} , {\text{S}}_{{{\text{c}}_{2} }} , {\text{S}}_{{{\text{c}}_{3} }} , {\text{S}}_{{{\text{c}}_{4} }} , {\text{S}}_{{{\text{c}}_{5} }} , {\text{S}}_{{{\text{c}}_{6} }} } \right] \), \( {\text{c}} = 1,2, \ldots ,6 \), where \( {\text{S}}_{{{\text{c}}_{1} }} \) represents Kurtosis, \( {\text{S}}_{{{\text{c}}_{2} }} \) represents Skewness, \( {\text{S}}_{{{\text{c}}_{3} }} \) represents the maximum amplitude of the received signal, \( {\text{S}}_{{{\text{c}}_{4} }} \) represents the energy of the received signal, \( {\text{S}}_{{{\text{c}}_{5} }} \) represents the variance of the received signal, and \( {\text{S}}_{{{\text{c}}_{6} }} \) represents the covariance of the received signal. According to the mean value a and the variance b of the sub-membership functions obtained by the genetic algorithm, the membership function set is constructed by the sub-membership functions. The membership function set F is as follows:
Substitute F into the target prediction formula to obtain the prediction function Y:
Y is a matrix in 1 * 6. Elements in Y are \( \left[ {{\text{Y}}_{1} ,{\text{Y}}_{2} ,{\text{Y}}_{3} ,{\text{Y}}_{4} ,{\text{Y}}_{5} ,{\text{Y}}_{6} } \right] \). According to the maximum membership principle, if
It is determined that the data y is subordinate to \( {\text{Y}}_{\text{i}} \). In this chapter, UWB radar mainly extracts the characteristic parameters related to the target from the received signal as the input signal of target recognition in the first place. The characteristic parameters extracted in this chapter mainly comprise kurtosis, skewness, energy, maximum amplitude value, variance and covariance. Then, the Gaussian function is chosen as the membership function, the mean and variance of the Gaussian function are optimized by the genetic algorithm, the membership function set of the target recognition is constructed by the characteristic parameters. Finally the target recognition category is determined according to the maximum membership degree of the fuzzy pattern recognition theory to complete the through-wall multi-status human target recognition.
3.2 Experiments and Analysis
3.2.1 Experimental System
In this chapter, six kinds of scenes are set up, including the through-wall no person status, normal breathing status of one person, swing arms status of one person, normal breathing status of two persons, waking 2 m away status of two persons and normal breathing status of three persons. Experiments mainly adopt the fuzzy pattern recognition algorithm and the genetic algorithm to identify multiple status of human being behind the wall. The experimental device used in this chapter is the P410 MRM radar device from Time Domain, as shown in Fig. 1. The device’s frequency range is 3.1–5.3 GHz, the center frequency is 4.3 GHz, and PC adopts the Windows7 system. In all of the above scenes, the human targets are 1 m away from the wall, and the P410 radar device is 20 cm away from the wall. The radar device is placed on a tripod, and its distance from the ground is half of height of the measured wall, as shown in Fig. 2.

Time domain

UWB P410 in monostatic mode
Except for the different status, other environments of all experimental scenes are set to the same. The basic idea of the human target recognition behind the brick wall is to process the received signal of the UWB radar device and extract the characteristic parameters related to the target information from the received signal. The waveforms of the received signals of the through-wall multiple status are as shown in Fig. 3.

The waveforms of the received signal
In this chapter, the characteristic parameters are extracted from the received signal, and six characteristic parameters are extracted from each status, including kurtosis, skewness, the maximum amplitude, energy, the variance and the covariance. The Gaussian function is selected as the sub-membership function, each characteristic parameter of each scene corresponds to a sub-membership function \( {\text{f}}( {\text{x}} ) \), thus six scenes have a total of 36 sub-membership functions. The mean and variance of the sub-membership functions are obtained by the genetic algorithm. In this chapter, six kinds of scenes are set up, and six characteristic parameters are extracted in each scene. Therefore, the target is represented by six characteristic parameters, namely \( {\text{S}}_{\text{c}} = \left[ {{\text{S}}_{{{\text{c}}_{1} }} ,{\text{S}}_{{{\text{c}}_{2} }} ,{\text{S}}_{{{\text{c}}_{3} }} ,{\text{S}}_{{{\text{c}}_{4} }} ,{\text{S}}_{{{\text{c}}_{5} }} ,{\text{S}}_{{{\text{c}}_{6} }} } \right],{\text{c}} = 1,2, \ldots ,6 \), where \( {\text{S}}_{{{\text{c}}_{1} }} \) represents Kurtosis, \( {\text{S}}_{{{\text{c}}_{2} }} \) represents Skewness, \( {\text{S}}_{{{\text{c}}_{3} }} \) represents the maximum amplitude of the received signal, \( {\text{S}}_{{{\text{c}}_{4} }} \) represents the energy of the received signal, \( {\text{S}}_{{{\text{c}}_{5} }} \) represents the variance of the received signal, and \( {\text{S}}_{{{\text{c}}_{6} }} \) represents the covariance of the received signal. The optimized mean value a and variance b of the sub-membership functions obtained by the genetic algorithm, the distribution is as shown in Fig. 4.

Mean and variance distribution diagram of sub-membership function
Respectively substituting a and b into formula (3.13) to get the membership function set F, then we substituting the measured data S into formula (3.10) and determining the through-wall status of the measured S according to the maximum membership principle of formula (3.11).
3.2.2 Results and Analysis
In this chapter, six different status of through wall human being are selected for data analysis. Under each scene, one set of data is randomly selected as shown in Table 2, in which \( {\text{S}}_{1} \) is the through-wall no person status, \( {\text{S}}_{2} \) is the through-wall normal breathing status, \( {\text{S}}_{3} \) is the through-wall swing arms status, \( {\text{S}}_{4} \) is the through wall normal breathing status of two persons, \( {\text{S}}_{5} \) is the through-wall walking 2 m away status of two persons, \( {\text{S}}_{6} \) is the through-wall normal breathing status of three persons. The data of the above five types of status are substituted into the target prediction function, the results of the identification as shown in Table 3.
We known the type of data of six groups with \( {\text{S}}_{1} \), \( {\text{S}}_{2} \), \( {\text{S}}_{3} \), \( {\text{S}}_{4} \), \( {\text{S}}_{5} \) and \( {\text{S}}_{6} \), then we are substituted the six groups into the target prediction function of this chapter. The data are analyzed according to the maximum membership principle of the fuzzy pattern recognition. Wherein among the six data of \( {\text{Y}}_{1} \), 1.4338 is the largest, and it is judged as the through-wall no person status and the recognition result is correct; among \( {\text{Y}}_{2} \), 2.0204 is the largest, it is judged as through-wall normal breathing status and the recognition result is correct; among \( {\text{Y}}_{3} \), 2.7567 is the largest, it is judged as the swing arms status, and the recognition result is correct; among \( {\text{Y}}_{4} \), 1.9121 is the largest, it is determined as the normal breathing status of two persons and the recognition result is correct; among \( {\text{Y}}_{5} \), 0.3845 is the largest, it is determined as the status of walking around of two persons and the recognition result is correct; among \( {\text{Y}}_{6} \), 2.5262 is the largest, it is determined as the swing arms status according to the maximum membership principle. However, since \( {\text{S}}_{6} \) belongs to the normal breathing status of three persons, thus the judgment result is incorrect. Due to the fact that the difference between normal breathing of three persons and the swing arms status is small, there is the possibility of wring judgment. This chapter considers that the normal breathing status of three persons wrongly determined as the swing arms status is still in a reasonable range. In this chapter, the data of six kinds of through-wall status are randomly selected to conduct the analysis.
In this chapter, 500 sets of data are received for testing each status, and each set of data contains 1152 data points. In the 500 sets of data for each status, we uniformly choose 50 sets of data as the training data and verification data, a total of 300 sets of data, and these 300 sets of verification data are substituted into the target prediction function of the fuzzy pattern recognition algorithm proposed in this chapter. Wherein the recognition accuracy of the through-wall no person status is 98%; the recognition accuracy of the through-wall normal breathing status is 82%; the recognition accuracy of the through-wall swing arms status is 96%; the recognition accuracy of the through-wall two person normal breathing status is 94%; and the recognition accuracy of the through-wall two person walking 2 m away status is 96%. This chapter successfully and accurately recognized five different through-wall status. The ROC curve is utilized to analyze the experiment result which shows that the ROC curve is closer to the upper left corner. It represents that the algorithm has a high precision. The ROC curve of the pattern recognition conducted to multiple through-wall status through the fuzzy pattern recognition algorithm is shown in Fig. 5. The classification effect of the first five status has achieved the prospective target:

ROC graphs of five through-wall status
In this chapter, We use classification algorithm of data mining tool to compare with the fuzzy pattern recognition algorithm. WEKA (Waikato Environment for Knowledge Analysis) is a data mining tool. There are a lot of different classification algorithms including the decision trees algorithm, Naive Bayes algorithm, Logistic algorithm, AdaBoost algorithm, artificial Neural network algorithm, KNN algorithm and so on [22]. We choose KNN, J48 and ZeroR in WEKA to compare with ours in this chapter under the condition that the data training set is completely identical to the testing set. The experimental results are shown in Table 4. It can be clearly seen from Table 4 the target recognition based on the through-wall multi-status of human being. According to the comparison of recognized status amount, the fuzzy pattern recognition algorithm proposed in this chapter can better recognize five types of through-wall human status. The KNN classification algorithm in Weka recognized five status, but the recognition accuracy of each status was far lower than that of the fuzzy pattern recognition algorithm proposed in this chapter; J48 recognized four status; ZeroR recognized six status, but compared with the first five status, the accuracy of the algorithm is much lower than that of the algorithm proposed in this chapter. According to the comparison based on the recognition accuracy, the accuracy of the algorithm proposed in this chapter is higher than the other three algorithms. Therefore, the proposed algorithm is obviously superior to the other three algorithms.
3.3 Conclusions
We mainly processes with the signals of the receiving end of the UWB radar device, and extracts the characteristic parameters related to target information, including kurtosis, skewness, energy of the received signal, amplitude value, variance and covariance. Then these six characteristic parameters are substituted into the fuzzy pattern recognition algorithm and the genetic algorithm as the target parameters to construct the target prediction function needed for recognition and recognize the target according to the maximum membership principle of fuzzy pattern recognition. Experimental results show that the algorithm can effectively distinguish the through-wall no person status, the through-wall normal breathing status, the through-wall swing arms status, the through-wall two person normal breathing status and the through-wall status of walking around of two persons. The results have very important theoretical significance and practical application value. The difference between the through-wall slow breathing status of three persons and the swing arms status is small, so there is the possibility of wrong judgment, we will do further research. This chapter compares the fuzzy pattern recognition algorithm with KNN, J48 and ZeroR, and it can be clearly seen that the proposed algorithm is superior to the other three algorithms. A more effective algorithm will be established in the next step to analyze and process various through-wall status and enables it to be applied in the complicated actual environment.
4 Through Wall Human Target Recognition Under Imbalanced Sample Based on Deep Learning
This section we proposed to apply the autoencoder algorithm in the deep learning network model to the through wall human target recognition under imbalanced sample conditions. The autoencoder algorithm extracts the concise data feature expression by automatically learning the intrinsic features in the data. Autoencoder network based on the addition of denoising coding and sparse constraints and other conditions to extract more effective feature expression to improve classification recognition rate. Then the training set data is input to the depth network for training. After the model training is completed, the test set data are input into the trained network for testing, and the classification result is obtained.
4.1 Network Construction and Training
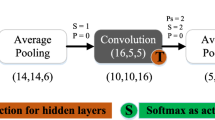
In this section, we used a four-layer stacked denoising autoencoder network consisting of an input layer, two hidden layers and an output layer to perform experiments, as shown in Fig. 6. This section of the stacked denoising autoencoder network training process: First, by layer-by- layer greedy training method in turn training each layer of the network, the entire depth of the neural network pre-training, that is, the first use of the original input to train the first layer of autoencoder network parameters, and then the output of the hidden layer of the autoencoder as the next input of an autoencoder, so that one by one training layer by layer learning network parameters of each layer, after unsupervised pre-training, in order to allow autoencoder network has the function of classification and identification needs to add a classifier after the last hidden layer of the autoencoder neural network, and then use supervised learning to adjust the parameters of the classifier by using the labeled samples to fine-tune and minimize the error of the prediction target. Constantly adjust the parameters of the entire network. In addition, it is also possible to fine-tune the parameters of all layers and improve the result simultaneously by supervised learning of a multi-layer neural network. Network training steps are as follows:

Stacked denoising autoencoder network structure
Algorithm 2: Stacked denoising autoencoder |
|---|
Input: training set, testing set. |
Output: testing error rate. |
(1) construct a four-layer stacked denoising autoencoder deep network; |
(2) feed the data into the first layer of the network, so that the output is equal to the input; |
(3) minimize the reconstruction error between the original input and the reconstructed output to obtain the first hidden layer; |
(4) output of the first hidden layer is used as the input of the next layer, and the input is equal to the output; |
(5) repeat step 3, obtain the second hidden layer; |
(6) output of the second hidden layer is used as the input of the classifier; |
(7) use the labeled data to fine-tune the network and minimize the reconstruction error; |
(8) get the test result. |
In order to improve the performance of the network, the number of neuron nodes in each layer, noise parameters, sparse penalty parameters, batches and iterations are set according to the actual situation of the experiment. In addition, we also added regularization restrictions and Dropout technology to improve the classification results. Then the training set data is input to the depth network for training. After the model training is completed, the test set data are input into the trained network for testing, and the classification result is obtained.
4.2 Simulation Experiments and Results
In this experiment, we use the Time domain company developed P410 UWB radar equipment. The radar is showed in Fig. 7.

P410 UWB radar
We set up an experimental scenario as shown in Fig. 8. The material of the wall is a brick wall, a thickness of 23.5 cm. The P410 UWB radar is placed 20 cm from the brick wall. In this experimental environment, we collected five kinds of human body state data after the wall: no person behind the wall; one person breathes slowly behind the wall; one person walks behind the wall; two persons rapid breathing status behind the wall; and one person waving status behind the wall. We collected 500 pulses in each state and set the pulse sampling point to 1000. Experimental scene is as follows:

Experimental scene
In practical applications, such as detecting terrorists through walls and judging the specific positions of terrorists and hostages in daily anti-terrorist operations, search and rescue personnel are looking for trapped persons in emergencies such as fires, earthquakes and avalanches. In these applications, the data for someone is crucial to us. We selects the experimental data from the collected five kinds of state data as a training set and a test set, in which we set as the majority of categories in the unmanned state, the other categories for the minority categories, we will make the experiment unattended data quantity more than any other state, so our experimental dataset is an imbalanced dataset. The range of some data may be particularly large, resulting in slow network convergence and long training time. Before training the network generally need to normalize the data processing. At the same time, in order to facilitate training and improve training speed, the entire data set can be batch-processed, that is, multiple sample data can be integrated into data blocks. If there are 1000 samples, each sample is 200 dimensions, 100 samples of data can be integrated into one data block, the size of each data block is 100 * 200, there are 10 such data blocks to form a three-dimensional array, Size is 100 * 200 * 10. Research shows that modularizing data can improve convergence speed.
From the collected multi-state data, five types of human body state data are selected as the training set and the test set respectively. Since we define the majority of samples when the unmanned state behind the wall is based on experiments, the number of unmanned state samples in the experiment is greater than that of several other states. In other words, the sample when no one is behind the wall is the majority, and the other states are the minority. In order to test the algorithm, we chose the most class (negative class) data for the unmanned state behind the wall, one waved behind the wall, one slow breathing, two rapid breathing state for the minority class (positive class). We used MATLAB software tools as experimental platform. The distribution of the experimental data samples for various states is shown in Tables 5, 6, and 7
In different imbalanced ratios, we choose KNN and J48 algorithm compared with the autoencoder we use, and we used the ROC curve to evaluate the experimental results. The ROC curve results of the three algorithms under different imbalance ratios are shown in Fig. 9. The closer the ROC curve is to the upper left corner, the higher the accuracy of the classification algorithm. It can be seen from Fig. 9 that under different imbalance ratios, the autoencoder algorithm has a better classification effect than other algorithms.


The ROC curve under different imbalance ratio. Red lines: the ROC curve of KNN algorithm. Green lines: the ROC curve of J48 algorithm. Blue lines: the ROC curve of AE algorithm (Color figure online)
4.3 Multi-sensor Data Simulation and Results
In the distance of four meters in length, moving the equidistance radar, collected at 40 cm every two walls after the unmanned state and the wall when a person walking around the data, as a point of data collected a total of 10 points two states of the experimental data. In this experimental environment, we collected 500 pulses in each state and set the pulse sampling point to 1000. We use a few samples (positive) when no one is behind the wall, and a majority sample (negative) when one moves around the wall. During the experimental data selection, the multi-sensor data is distributed under a single sensor. The distribution of multi-sensor data positive and negative samples is shown in Table 8. The single-sensor data distribution is shown in Table 9.
Under the multiple sensors, we choose the two state data when no one is behind the wall and the one when the person walked behind the wall. After the experimental data selection is completed, we first normalize the training set and the test set data, and then use the normalized data to conduct the experiment, and finally input the data to the network to obtain the experimental result. The same experimental data collected in a single sensor under unmanned state and behind the wall in one of two states, the training set and the test set the same amount of data with multiple sensors. We compare the results obtained with the classification of the same two data sets under the same sensor and the same state.
We used the ROC curve to evaluate the experimental results, the closer the ROC curve is to the upper left corner, the higher the accuracy of the classification algorithm. We compared the multi-sensor data results with the single sensor experiment results. The ROC curves of the two experimental results under different imbalance ratios are shown in Fig. 10. As can be seen from Fig. 10, as the imbalance ratio increases, the experimental results show that the multi-sensor data is better than a single sensor in certain imbalance ratio.

The ROC curve under different imbalance ratio. Red lines: the ROC curve of multi-sensor data experiment. Blue lines: the ROC curve of single sensor data experiment (Color figure online)
References
Kumar A, Liang Q, Li Z, Zhang B, Wu X (2012) Experimental study of through-wall human being detection using ultra-wideband (UWB) radar. Globecom workshops (GC Wkshps), 2012 IEEE
Sahu KN, Satyam M, Naidu CD, Sankar KJ (2015) UWB propagation modeling of human being behind a concrete wall for the study of cardiac condition. In: International conference on electrical, 2015, pp 1–5
Yarovoy AG, Ligthart LP, Matuzas J et al (2006) UWB radar for human being detection. IEEE Aerosp Electron Syst Mag 21(3):10–14
Attiya AM, Bayram A, Safaai-Jazi A et al (2004) UWB applications for through-wall detection. In: IEEE international symposium: antennas and propagation society, 2004. IEEE, vol 3, pp 3079–3082
Lubecke VM, Boric-Lubecke O, Host-Madsen A et al (2007) Through-the-wall radar life detection and monitoring. In: IEEE/MTT-S international microwave symposium. IEEE, pp 769–772
Chernyak V (2008) Detection problem for searching survivors in rubble with UWB radars. In: European radar conference, 2008. EuRAD 2008. IEEE, pp 44–47
Li J, Zeng Z, Sun J, Liu F (2012) Through-wall detection of human being’s movement by UWB radar. IEEE Geosci Remote Sens Lett 9(6):1079–1083
Singh S, Liang Q, Chen D et al (2011) Sense through wall human detection using UWB radar. EURASIP J Wirel Commun Netw 2011(1):20
Zetik R, Crabbe S, Krajnak J et al (2006) Detection and localization of persons behind obstacles using M-sequence through-the-wall radar. Proc SPIE 6201:145–156
Kumar A, Li Z, Liang Q et al (2014) Experimental study of through-wall human detection using ultra wideband radar sensors. Measurement 47:869–879
Lai CP, Narayanan RM (2010) Ultrawideband random noise radar design for through-wall surveillance. IEEE Trans Aerosp Electron Syst 46(4):1716–1730
Lai CP, Narayanan RM (2005) Through-wall imaging and characterization of human activity using ultrawideband (UWB) random noise radar. Proc SPIE 5778:187
Sun J, Li M (2011) Life detection and location methods using UWB impulse radar in a coal mine. Int J Min Sci Technol 21(5):687–691
Jovanoska S, Thoma R (2012) Multiple target tracking by a distributed UWB sensor network based on the PHD filter. In: International conference on information fusion, 2012, pp 1095–1102
Narayanan RM, Shastry MC, Chen PH et al (2010) Through-the-wall detection of stationary human targets using Doppler radar. Prog Electromagn Res B 20:147–166
Zhang B, Wang W (2013) Through-wall detection of human being with compressed UWB radar data. EURASIP J Wirel Commun Netw 2013(1):162
Levitas B, Matuzas J (2006) UWB radar for human being detection behind the wall. In: International radar symposium, 2006. IRS 2006. IEEE, 2007, pp 85–88
Marano S, Gifford WM, Wymeersch H, Win MZ (2010) NLOS identification and mitigation for localization based on UWB experimental data. IEEE J Sel Areas Commun 28(7):1026–1035
Chong CC, Watanabe F, Inamura H (2008) NLOS identification and weighted least-squares localization for UWB systems using multipath channel statistics. EURASIP J Adv Signal Process 2008(1):36
Gudmundsson M, El-Kwae EA, Kabuka MR (1998) Edge detection in medical images using a genetic algorithm. IEEE Trans Med Imaging 17(3):469–474
Qu W, Wang J, Zheng J, Li G, Teng J (2006) Fuzzy pattern recognition for stress field of box-type steel structure. Earthq Eng Eng Vibr 26(5):177–182
Zhao X, Zhang H (2012) Summary: expression classification algorithm and emotional space model. Int J Digit Content Technol Appl 6(3):37–44
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Wang, W. (2019). Human Detection Based on Radar Sensor Network in Natural Disaster. In: Durrani, T., Wang, W., Forbes, S. (eds) Geological Disaster Monitoring Based on Sensor Networks. Springer Natural Hazards. Springer, Singapore. https://doi.org/10.1007/978-981-13-0992-2_8
Download citation
DOI: https://doi.org/10.1007/978-981-13-0992-2_8
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-0991-5
Online ISBN: 978-981-13-0992-2
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)