
Abstract
Compression index is very important in the design of geotechnical engineering such as consolidation settlement prediction and construction design. However, measuring compression index is very complex and time-consuming. In addition, it is very difficult to collect unbroken core samples from underground. Artificial neural network has been adopted in some geotechnical applications and has achieved some success. In this paper, artificial neural network (ANN) models are developed for estimating compression index by basic soil parameters based on 2859 soil test data. All of the marine soil samples, which are divided into three subsets to train the optimum model, are collected from Dalian Artificial Island and compression index and other parameters are measured in soil mechanical laboratory as well. At last, the optimized ANN model structure and suitable inputs are determined followed by the comparison between empirical formulas predictions and ANN models output. It is revealed that ANN models perform better than empirical formulas with respect to the accuracy of compression index prediction.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Compression index can be used to calculate consolidation settlement issues in some geotechnical engineering designs, which can affect the security and economy of construction projects. It is obtained from slope of the curve of void ratio versus logarithm of effective pressure and is conventionally determined by oedometer test. Moreover, compression index reflects compressibility of soil. Void ratio change of specimen occurs as a consequence of dissipation of pore water pressure under various applied stresses of oedometer test condition, in which the lateral strain is limited. Though oedometer test is widely used, it is more time-consuming than tests to obtain basic parameters such as unit weight, plastic index and so on. Beyond that, it is difficult to obtain good quality samples from silted floor and deep soils in oedometer test.
It is generally known that the relationship between compression index and soil basic parameters (water content, density, specific gravity, void ratio, saturation, dry density, liquid limit, plastic limit, plastic index) is nonlinear and complex. Thus, indirect prediction of compression index is useful, time saving, and easy to conduct. Through previous geotechnical engineers’ and researchers’ exploration and research from amounts of tests, some empirical formulas have been developed. As we know, if an issue can not be built a physical model, a regression model is an effective method. However, most of the regression models simplify the number of parameters, thus only adopting single or dual parameter models to predict compression index. As a result, formulas’ prediction accuracy is limited.
More recently, artificial neural networks (ANNs) as a form of artificial intelligence have been used to some geotechnical engineering and structure engineering problems[1,2,3], the performance of which is more superior than the traditional method. Many parameters, such as preconsolidation pressure [1], unsaturated shear strength [2], pile settlement [4], California bearing ratio of fine grained soils [5], the unconfined compressive strength of compacted granular soils [6], subsurface soil layering and landslide risk [7], compaction parameters of fine-grained soils [8], and stress-strain relationship of geomaterials [9]. In addition, Ozer and Park predicted compression index based on other parameters using ANN model [3, 10]. However, these two studies faced the native construction, and few studies focus on Chinese marine soils to predict their compression index. Thus, this paper will adopt ANN method to predict compression index of Dalian marine soils. In addition, the ANN model in this paper is more steady because that there is 2859 data (much more than other studies) in this paper.
In this paper, ANN models are constructed to forecast the compression index of Dalian marine soils. We treat ANN as an indirect tool to measure the compression index of Dalian marine soils from other basic parameters. And this paper simplify and optimize parameters to predict compression index. Results indicate that the ANN model is an effective method to predict compression index issue and then to guide the geotechnical design.
2 Data and Preprocessing
2.1 Case Study and Sample Preparation
All specimens of marine soils in this paper are taken from Dalian Artificial Island. This project locate in Jinzhou Gulf and floor area is 24 km2. The distance from the artificial island to coastline is 3000 m. To complete this reclamation project, 60 million m3 of muck, 300 million m3 of soils and stones were filled in this area. And an airport will be constructed in the future. Thus, it is necessary to evaluate the soil mechanical property to meet the construction requirement. By means of drilling to obtain specimens and then put them into a prefabricated metal cylinder as SL237-199 (China) recommends.
2.2 ANN Model
The advantage of ANN is that it can solve complex nonlinear issues. BP neural network is one of widely used ANN models, which information transfer direction is back propagation. What’s more, the initial weight and bias are given random and treat MSE(mean square error) as cost function, weight’s and bias’s adjusting are based on MSE value and corresponding Levenberg-Marquardt. Classical ANN model has three kinds of layers: input layer, hidden layer and output layer, and every layer has its own neural nodes. The number of input layer and output layer base on concrete issue, in addition, the hidden layer’s node number depends on computational training.
2.3 Preprocessing of Database
To predict the compression index more accurately, this paper explores the factors affecting the compression index by reviewing literature. This study takes water content, density, specific gravity, void ratio, saturation, dry density, liquid limit, plastic limit, and plastic index into account as model inputs. In this paper, 2859 data are divided into training, validation, and testing subsets, with proportions of 70% (2003 data), 15% (428 data), and 15% (428 data), respectively. ANN models get the best result when their training set has the most extensive data range in general. To achieve this demand, this paper employs the random method to divide sample data as proportions mentioned above. Training set is used to train network and obtain weights and bias between layers. Validation set is used to assess network’s performance and avoid over fitting. Testing set is adopted to test the network’s prediction availability.
3 Result and Discussion
3.1 Results of ANN Model with Nine Parameters as Inputs
According to previous training projects, a series of computational experiments have been completed to predict the compression index. Moreover, the result of each ANN model has been summarized in Table 1. As shown in Table 1, R2 value of training subset is larger than validation’s and testing’s, while the RMSE value is opposite. Basically, training subset performs better than validation subset and testing subset. Specifically, model result of 8 nodes in the single hidden layer is better than others under logsigmoid-linear transfer function. And the model with 9 nodes performs best under tansigmoid-linear transfer function. In addition, the model with 13 nodes presents the best performance when using logsigmoid-tansigmoid function. Comparing the three models mentioned above, the one with 13 nodes under logsigmoid-tansigmoid function is more superior than the other two, with R2 equaling 0.948023 and RMSE equaling 0.044533 in the testing subset.
To explore the performance of ANN model with double hidden layers, Firstly, the nodes of single hidden layer’s ANN model is optimized, which suppose number N. Secondly, the N is set as the nodes of first layer of two hidden layers’ ANN model. Thus, this paper sets 13 nodes in the first hidden layer and 8–25 nodes in the second hidden layer respectively by using different transfer functions: logsigmoid-tansigmoid-(linear/tansigmoid). After ten times’ computational experiments for each model, we summarize the results and list the best one under different transfer functions, which are shown in Table 2. It can be seen that the model with 8 nodes in its second hidden layer has the highest R2 (0.948749) and lowest RMSE when the transfer function is logsigmoid-tansigmoid-tansigmoid. As expected, the predicting ability of double hidden layers is better than the single one.
Observing the performance of each ANN model, we discover that the gap among R2 and RMSE is small. Besides, all models have high R2 and small RMSE. Both of observations above indicate that data are large enough to present a statistical regularity between the compression value and basic parameters.
Figure 1(a) and (b) depict the comparison results of experimental and predicted compression index. We find that most of data points are distributed around the y = x function line apart from a few data points, which reveals the fact that test values of Cc is very close to its prediction values. Therefore, we can conclude that ANN can build a relatively accurate model to predict Cc value through soil basic parameters. In addition, the performance of ANN model with double layers is better than the model with single layer when inputs contain nine parameters.

Comparison of experimental and predicted compression index (a) (9-13-1 logsigmoid-tansigmoid ANN model) and (b) (9-13-8-1 logsigmoid-tansigmoid-tansigmoid ANN model)
3.2 Results of ANN Model with Four or Five Parameters as Inputs
Although the ANN model with nine parameters as inputs has acquired a series satisfactory results, its structure is too complex to get the simple weight and bias. Consequently, it is difficult to extend these ANN models. In order to simplify the ANN model, this paper just adopts density, void ratio, water content, liquid limit, and plastic limit as model inputs. As we know, soil contains air, water, and soil grain. So parameters of saturation, dry density, and specific gravity can reflect the soil’s physic properties. However, we do not have to spare time to measure them since they can be derived based on density, void ratio, and water content, which can be obtained easily from soil experiments and have been proven that they have strong correlation with the compression index. Thus, these three parameters (density, void ratio, and water content) are included as inputs in the model. Moreover, liquid limit and plastic limit reflect the soil’s grain composition and thus affect the soil’s compressibility. In conclusion, all of these five parameters have strong representative. To explore the performance of ANN model and compare the performance of different model inputs components, this paper conducts ANN training in a way of following computational scheme. Results of ANN models with best performance under different transfer functions and model inputs are described in Tables 3, 4 and 5. According to them, the ANN model with 15 nodes in its hidden layer achieves the best performance when model inputs include water content, density, void ratio, and liquid limit. Moreover, it is also better than the 9-13-8-1 (logsigmoid-tansigmoid-tansigmoid) ANN model, which testing subset’s prediction was R2 = 0.949486 and RMSE = 0.043902. And 9-13-8-1 means that there are 9 nodes in input layer, 13 nodes in the first hidden layer, 9 nodes in the second hidden layer, and 1 node in the output layer. Next we will emphasize the situation of the double hidden layers ANN model with these 4 parameters (wn, eo, \( \rho \), wl).
For estimating performance of the double hidden layers ANN model with the 4 parameters (wn, eo, \( \rho \), wl), node number of the first hidden layer is determined as 15. In terms of node number of the second hidden layer, it ranges from 4 to 15, with one added once. Moreover, the transfer function between the second layer and output layer is tansigmoid or linear. Then computational experiments are conducted. The best results of double hidden layer ANN models under different transfer functions are listed in Table 6.
From Table 6, we can see that the model with tansigmoid as the transfer function performs best with R2 equaling 0.947089 and RMSE equaling 0.044931 in the testing subset when the node number of the second hidden layer is 8. For the situation, in which the transfer function is linear, the model result is optimal with R2 equaling 0.947951 and RMSE equaling 0.044564 in the testing subset when the node number of the second hidden layer is 10 and testing subset’s R2 = 0.947089 and RMSE = 0.044931. However, comparing with the ANN model whose structure is 4-15-1 and transfer function is tansigmoid-linear, the prediction ability of both of them is a little bit weaker. And 4-15-1 means that there are 4 nodes in input layer, 15 nodes in the first hidden layer, and 1 node in the output layer.
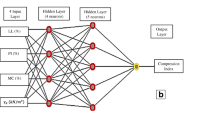
Figure 2 is the comparison outcome between predicted values of the compression index and experimental values. Comparing with Figs. 1(a) and 2(b), despite of similar prediction ability exhibited by these three ANN models, 4-15-1 transigmoid-linear ANN model is more superior to the other two due to its simplicity. And its ANN architecture is given in Fig. 3.

Comparison of experimental and predicted compression index (4-15-1 tansigmoid-linear ANN model)

Optimal ANN architecture (4-15-1 tansigmoid-linear)
4 Conclusion
-
1.
In addition to those phenomenon, prediction ability of the ANN model with double hidden layers is better than that of single layer model when nine parameters as ANN inputs. And 9-13-8-1 structure with logsigmoid-tansigmoid-tansigmoid as transfer function obtains the best prediction ability, which R2 equaling 0.948749 and RMSE equaling 0.044221.
-
2.
For simplifying the ANN model inputs, thereby making it more accessible, we constrain parameters in ANN models just to be density, water content, void ratio, and liquid limit. Consequently, the model with R2 = 0.949486 and RMSE = 0.043902 is proved to has the strongest prediction ability, better than the best outcome in 9 inputs ANN model structure And this ANN model’s structure is 4-15-1 and transfer function is tansigmoid-linear.
-
3.
As can be seen from the result of every ANN model, ANN is an useful tool to solve the nonlinear geotechnical issues. Overall, it is necessary to establish a nationwide database to analyze the relationship of parameters and furtherly guide the practical project applications.
References
Çelik, S., Tan, Ö.: Determination of preconsolidation pressure with artificial neural network. Civil Eng. Environ. Syst. 22(4), 217–231 (2005)
Lee, S.J., Lee, S.R., Kim, Y.S.: An approach to estimate unsaturated shear strength using artificial neural network and hyperbolic formulation. Comput. Geotech. 30(6), 489–503 (2000)
Park, H.I., Lee, S.R.: Evaluation of the compression index of soils using an artificial neural network. Comput. Geotech. 38(4), 472–481 (2011)
Pooya, N.F., Jaksa, M.B., Kakhi, M., et al.: Prediction of pile settlement using artificial neural networks based on standard penetration test data. Comput. Geotech. 36(7), 1125–1133 (2009)
Taskiran, T.: Prediction of California bearing ratio (CBR) of fine grained soils by AI methods. Adv. Eng. Softw. 41(6), 886–892 (2010)
Kalkan, E., Akbulut, S., Tortum, A., et al.: Prediction of the unconfined compressive strength of compacted granular soils by using inference systems. Environ. Geol. 58(7), 1429–1440 (2008)
Farrokhzad, F., Barari, A., Ibsen, L., et al.: Predicting subsurface soil layering and landslide risk with Artificial Neural Networks: a case study from Iran. Geologica Carpathica 62(5), 477–485 (2011)
Sivrikaya, O., Soycan, T.Y.: Estimation of compaction parameters of fine-grained soils in terms of compaction energy using artificial neural networks. Int. J. Numer. Anal. Meth. Geomech. 35(17), 1830–1841 (2011)
Zhao, H., Huang, Z., Zou, Z.: Simulating the stress-strain relationship of geomaterials by support vector machine. Math. Prob. Eng. 2014, 1–7 (2014)
Ozer, M., Isik, N.S., Orhan, M.: Statistical and neural network assessment of the compression index of clay-bearing soils. Bull. Eng. Geol. Env. 67(4), 537–545 (2008)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix (Weights and Bias of 4-15-1 Tansigmoid-Linear ANN Model)
Appendix (Weights and Bias of 4-15-1 Tansigmoid-Linear ANN Model)
W1 | |||
|---|---|---|---|
2.622903 | 4.083057 | −1.22764 | 0.896845 |
1.350291 | −2.33406 | −2.70143 | −3.50748 |
−2.33836 | 0.22522 | −4.40407 | 1.415465 |
0.909055 | −2.85348 | −6.9055 | −2.61151 |
3.461982 | −4.91683 | 0.374592 | 0.850418 |
3.920666 | 0.637272 | 4.992674 | −0.48619 |
−0.19546 | −3.75934 | 1.610851 | −5.08277 |
1.247785 | −0.73106 | 1.083275 | −1.26217 |
−1.05275 | −1.7319 | 2.852696 | 3.852191 |
−5.53328 | −1.61691 | −4.20678 | 6.063494 |
−0.08983 | −1.33851 | −4.45048 | 3.358993 |
−2.61411 | −0.58812 | −2.32164 | 4.178343 |
−1.96377 | 0.219849 | −1.37967 | −4.30137 |
6.408356 | −0.77561 | 2.902883 | 0.558393 |
−3.26617 | −1.40982 | 3.581199 | −0.82867 |
B1 | W2 | B2 |
|---|---|---|
−1.57088 | −6.10517 | −0.02331 |
0.054728 | −5.15034 | |
1.280595 | 4.743402 | |
−4.86217 | −6.31247 | |
2.788758 | −7.68178 | |
1.180403 | −1.18919 | |
1.596082 | −1.75728 | |
−2.98951 | 0.639066 | |
−1.87916 | 2.290802 | |
−1.14495 | −2.59815 | |
2.56238 | −1.5928 | |
−1.47991 | −3.87658 | |
1.482598 | −4.67425 | |
0.774307 | 2.109405 | |
−0.10101 | −5.39566 |
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Xue, Z., Tang, X., Yang, Q. (2018). Predicting Compression Index Using Artificial Neural Networks: A Case Study from Dalian Artificial Island. In: Li, L., Cetin, B., Yang, X. (eds) Proceedings of GeoShanghai 2018 International Conference: Ground Improvement and Geosynthetics. GSIC 2018. Springer, Singapore. https://doi.org/10.1007/978-981-13-0122-3_23
Download citation
DOI: https://doi.org/10.1007/978-981-13-0122-3_23
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-0121-6
Online ISBN: 978-981-13-0122-3
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)