
Abstract
The aims of this paper are to develop a linear and nonlinear model in time series to forecast electricity consumption of the lowest household category in East Java, Indonesia. The installed capacity in the lowest household customer category has various power, i.e. 450 VA, 900 VA, 1300 VA, and 2200 VA. ARIMA models are family of linear model for time series analysis and forecasting for both stationary and non-stationary, seasonal and non-seasonal time series data. A nonlinear time series model is proposed by hybrid ARIMA-ANN, a Radial Basis Function using orthogonal least squares. The criteria used to choose the best forecasting model are the Mean Absolute Percentage Error and the Root Mean Square Error. The ARIMA best model are ARIMA ([1, 2], 1, 0) (0, 1, 0)12, ARIMA (0, 1, 1) (0, 1, 0)12, ARIMA (0, 1, 1) (0, 1, 0)12, ARIMA (1, 0, 0) (0, 1, 0)12 respectively. The ANN architecture optimum are ANN (2, 12, 1), ANN (1, 12, 1), ANN (1, 12, 1), and ANN (1, 12, 1). The best models are ARIMA ([1, 2], 1, 0) (0, 1, 0)12, ARIMA (0, 1, 1) (0, 1, 0)12, ANN (1, 12, 1), and ANN (1, 12, 1) in each category respectively. Hence, the result shows that a complex model is not always better than a simpler model. Additionally, a better hybrid ANN model is relied on the choice of a weighted input constant of RBF.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In the last decade, machine learning has growth rapidly as tool for making prediction. Basically, the most algorithms in machine learning are developed from classical statistical method. In the statistical perspective, machine learning frames data in the context of a hypothetical function (f) that the machine learning algorithm aims to learn. Given some input variables (Input) the function answers the question as to what is the predicted output variable (Output). For categorical data prediction, hundreds algorithm classifier can be applied in many software [1]. In the future, the feature of machine learning algorithm will be standardized, simple, specialized, composable, scalable yet cost effective in order to realize the goal of completely automated machine learning utilities, which will become an integral part of the modern software application [2].
One situation in making prediction by machine learning are dealing with the time series data. The input variables in time series data are observations from the time lag previously. There are many machine learning models for time series forecasting [3]. There is good paper to survey recent literature in the domain of machine learning techniques and artificial intelligence used to forecast time series data [4].
This paper aims to develop model for a linear and nonlinear model in time series machine learning to forecast electricity consumption of the lowest household category in East Java, Indonesia. ARIMA models are family of linear model for time series analysis and forecasting for both stationary and non-stationary, seasonal and non-seasonal time series data. A nonlinear time series model is proposed by hybrid ARIMA-ANN, a Radial Basis Function Neural Networks architecture within orthogonal least squares estimation. Radial Basis Fuction (RBF) neural networks is a class of feed forward network that use a radial basis function as its activation function [9]. The orthogonal least squares procedure choses radial basis function centers one by one in a rational way until an adequate network has been constructed [10].
The installed capacity in the lowest household customer category has various power, i.e. 450 VA, 900 VA, 1300 VA, and 2200 VA. Some papers previously have devoted to develop forecasting model for electricity. Two-level seasonal model based on hybrid ARIMA-ANFIS to forecast half-hourly electricity load in Java-Bali Indonesia [5]. The results show that two-level seasonal hybrid ARIMA-ANFIS model with Gaussian membership function produces more accurate forecast values than individual approach of ARIMA and ANFIS model for predicting half-hourly electricity load, particularly up to 2 days ahead. Meanwhile, the electricity forecasting for industrial category in East Java has been forecasted using ARIMA model [6].
2 Data and Method
The data is from PLN (Perusahaan Listrik Negara/National Electricity Company) as central holding company to serve and maintain supply and distribute electricity across Indonesia. The data is electricity consumption from the lowest household category (R1) in East Java and the time period is from January 2010–December 2016. The customer from the lowest household category is divided by various installed capacity, 450 VA, 900 VA, 1300 VA, and 2200 VA.
The forecasting method of individual series will be used by ARIMA model. ARIMA models, abbreviation of Autoregressive Integrated Moving Averaged, were popularized by George Box and Gwilym Jenkins in the early 1970s. ARIMA models are family of linear model for time series analysis and forecasting for both stationary and non-stationary, seasonal and non-seasonal time series data. There are four steps in ARIMA modelling are, model identification, parameter estimation, diagnostic checking and finally model is used in prediction purposes. There are model classification in the family of ARIMA [7].
-
Model Autoregressive (AR)
A pth-order of autoregressive or AR (p) model can be written in the form,
-
Model Moving Averages (MA)
A qth-order of moving averages or MA (q) model can be written in the form
-
Model Autoregressive Moving Average (ARMA)
A pth order of Autoregressive and qth order of Moving Average or ARMA (p, q) model can be written in the form,
-
Model Autoregressive Integrated Moving Average (ARIMA)
By taking difference to the original, a pth order Autoregressive of and qth order of Moving Average, notated by ARIMA (p, d, q), the model will be
-
Model Seasonal Autoregressive Integrated Moving Average (SARIMA)
Seasonal ARIMA usually are notated by ARIMA (p, d, q) (P, D, Q)S. The general form of Seasonal ARIMA can be written as,
Hybrid ARIMA-ANN is hybridisation of ARIMA and radial basis function (RBF) neural networks. RBF is a class of feed forward network that use a radial basis function as its activation function and a traditionally used for strict interpolation in multidimensional space [8], composed by three layers i.e. an input layer, a hidden layer, and an output layer. The input layer applies an orthogonal least squares procedure to choose the radial basis function centers in the input layer and a weighted input constant [9]. The hidden layer of RBF is nonlinear, whereas the output layer is linear. RBF network employs to modelling time series is \( y\left( t \right) \) as the current time series value. The idea is to use the RBF network [10]
as the one step-ahead predictor for \( y\left( t \right) \), where the inputs to the RBF network
are past observation of the series. The nonlinearity \( \phi \left( \cdot \right) \) within the RBF network is chosen to be the gaussian function (8) and the RBF network model writes as (9)
The weighted input constant of RBF is proposed by using measure of dispersion, it applied to build a radial basis function in the hidden layer are semi interquartile range, inter quartile range, range, and standard deviation [11].
The criteria used to choose the best forecasting model are the Mean Absolute Percentage Error (MAPE) and the Root Mean Square Error (RMSE) [7].
3 Results
The short description regarding the electricity consumption is presented in Table 1. The table shows that the largest contributor to total consumption is from 900 VA power capacity as well as the smallest is from 2200 VA category. This is caused by the customer number of 900 VA is the largest and the customer number of 2200 VA is the smallest. Only around 9.84% the percentage of customer is from 1300 VA and 2200 VA.
Before starting the modeling procedure, electricity consumption data is divided into two parts, namely data in-sample and out-sample. The in-sample data is used to determine the modeling, while the out-sample data is used for model selection. The in-sample data uses data from January 2010 to December 2015, while the out-sample data uses data from January 2016 through December 2016.
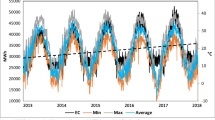
Figure 1 shows the time series plot of the electricity consumption for each category. Obviously, the pattern of each series is trend and non-stationary. From the Fig. 1, it is not clear whether there is seasonal pattern or not for each series data. So, the monthly boxplot in Fig. 2 is presented to help to identify the seasonal pattern. By observing the line between monthly means of each box plot, each series looks have the similar pattern.

Individual time series plot

Monthly boxplot individual time series
Clearly that the time series plot shows that the data is non-stationary and have seasonal pattern. Therefore, it is need to make the data become stationary before constructing the forecasting model. For this purpose, it will be taken d = 1 for non-seasonal, D = 1 for seasonal and S = 12 for seasonal. It can be shown that the data become stationary as shown in Annex 1.
Model Identification.
As mentioned previously, the first step in ARIMA modeling is model identification based on stationary series data. By using Autocorrelation (ACF) and Partial Autocorrelation (PACF) plot, the tentative models can be proposed, especially order the ARIMA model. The ACF and PACF of each series data set is shown in Annex 1 and the tentative best models of each series is presented in Table 2.
Model estimation.
Then, based on tentative ARIMA model, the parameter of each model will be estimated. The coefficient in each model, for both seasonal and non-seasonal, must satisfy the significant criteria (Annex 2).
Model checking.
This involve the residual examination by using Ljung-Box test to check whether white noise or not and checking the p-value of the coefficient, then the significant model can be determined. Table 2 shows residual of the candidate best models already meet the white noise properties.
The best model.
The best model would be selected by identifying model with the minimum MAPE and RMSE. Table 2 also shows the MAPE and RMSE of each best candidate model. Therefore, it can be identified easily, which model is the best. Table 3 present the best model of each series and its model specification. All the best models are seasonal models. These results correspond to the initial hypothesis at the identification stage that the best model is likely to be seasonal.
Forecasting.
Based on the best model, then it will be computed forecasting electricity consumption of each individual series for 2017 year. Table 4 presented the forecasting of each series as well as Fig. 3 shows the interval forecasting of each individual series.

Interval forecasting of each individual series
The forecasting result in Table 4 corresponds to the short data description as presented Table 1. The forecasting capacity 900 VA is highest in each month as well as forecasting of 2200 VA is lowest. In addition, the forecast results also generate an increasing trend from the previous years. Then, Fig. 4 presented the time series plot of forecasting results along with the upper and lower limits to be better understand the variation from month to month, what’s going down and what month is up. Interestingly, forecasting in February resulted in minimum values.

Interval forecasting of each individual series
Hybrid ARIMA-ANN.
The standard ARIMA model will be compared to Hybrid ARIMA-ANN. This model is built by the hybridization of ARIMA and RBF. The input is determined by the order of autocorrelation or partial autocorrelation of ARIMA model. The hidden layer is composed by the measure of dispersion constant as the width, determined by the seasonality pattern, and proceed by the orthogonal least squares. The measure of dispersion is determined by semi interquartile range (SIR), interquartile range (IQR), range, and standard deviation. The output layer is linear process as a univariate forecasting.
The architecture optimum.
Based on Table 5, the architecture optimum is built by the measure of dispersion constant and proceed by the orthogonal least squares method. The architecture optimum is shown in Annex 2 (Table 6).
Forecasting.
Based on the architecture optimum, it will be computed a univariate forecasting electricity consumption of each individual series in 2017. Table 7 presents the forecasting of each series as well as Fig. 4 shows the interval forecasting.
Comparation model.
Based on the best model in each series, the best models are ARIMA ([1, 2], 1, 0) (0, 1, 0)12, ARIMA (0, 1, 1) (0, 1, 0)12, ANN (1, 12, 1), and ANN (1, 12, 1) respectively. It shows that a complex model is not always better than a simpler model. Hence, a better hybrid ANN model is relied on the choice of a weighted input constant of RBF. In addition, hybrid model forecasting results have a smaller variation compared to the ARIMA model. This can be seen in Fig. 4. Time series plot of forecasting results from month to month shows small changes. In addition, forecasting results also show a different pattern with the original data plot. If the time series of the original data in general shows an upward trend pattern, then the forecasting result of the hybrid model shows the pattern tends to go down as in forecasting 2200 VA.
4 Conclusion and Further Research
There are four individual series of electricity consumption, 450 VA, 900 VA, 1300 VA and 2200 VA. The time series machine learning to forecast each series is ARIMA model and the best model is ARIMA ([1, 2], 1, 0) (0, 1, 0)12, ARIMA (0, 1, 1) (0, 1, 0)12, ARIMA (1, 1, 0) (0, 1, 0)12, and ARIMA (1, 0, 0) (0, 1, 0)12 respectively. It is also noted that the largest contribution to household electricity is from 900 VA category. Meanwhile, the hybrid ARIMA-ANN forecasting generates an architecture and an architecture optimum i.e. ANN (2, 12, 1) using semi interquartile, ANN (1, 12, 1) using range, ANN (1, 12, 1) using semi interquartile, and ANN (1, 12, 1) using range respectively. The comparation model shows that there is an inconsistent model because a complex model doesn’t work better in two series of electricity consumption i.e. the 450 VA series and the 900 VA series.
If the electricity consumption of each category is summed up, then it will produce the total household electricity consumption. This time series data is called hierarchical time series data. The alternative method can be used for this type of time series data is hierarchical time series model by applying the top-down, bottom up and optimal combination approach [12]. These approaches could be considered to be applied to this data in the next research.
References
Delgado, M.F., Cernadas, E., Barro, S., Amorim, D.: Do we need hundreds of classifiers to solve real world classification problems? J. Mach. Learn. Res. 15, 3133–3181 (2014)
Cetinsoy, A., Martin, F.J., Ortega, J.A., Petersen, P.: The past, present, and future of machine learning APIs. In: JMLR: Workshop and Conference Proceedings, vol. 50, pp. 43–49 (2016)
Ahmed, N.K., Atiya, A.F., Gayar, N.E., Shishiny, H.E.: An empirical comparison of machine learning models for time series forecasting. Econom. Rev. 29(5–6), 594–621 (2010)
Krollner, B., Vanstone, B., Finnie, G.: Financial time series forecasting with machine learning techniques: a survey. In: ESANN 2010 Proceedings, European Symposium on Artificial Neural Networks - Computational Intelligence and Machine Learning, Bruges (Belgium), 28–30 April 2010. D-Side Publishing (2010). ISBN 2-930307-10-2
Suhartono, Puspitasari, I., Akbar, M.S., Leem, M.H.: Two-level seasonal model based on hybrid ARIMA-ANFIS for forecasting short-term electricity load in Indonesia. In: IEEE Proceeding, International Conference on Statistics in Science, Business and Engineering (ICSSBE) (2012). https://doi.org/10.1109/ICSSBE.2012.6396642
Saputri, I.A.: Forecasting of Electricity in Industrial Sector at PT PLN East Java: Final Assignment, June 2016. Department Of Statistics, Faculty of Mathematics and Natural Sciences (2016)
Cryer, J.D., Chan, K.: Time Series Analysis With Application in R, 2nd edn. Springer Science Business Media, New York (2008). https://doi.org/10.1007/978-0-387-75959-3
Sivanandam, S.N., Sumathi, S., Deepa, S.N.: Introduction Neural Networks Using Matlab 6.0. Tata McGraw-Hill, New Delhi (2006)
Beale, M.H., Demuth, H.B., Hagan, M.T.: Neural Network Toolbox User’s Guide R2011b. The MathWorks Inc., Natick (2011)
Chen, S., Cowan, C.F., Grant, P.M.: Orthogonal least squares learning algorithm for radial basis function networks. IEEE Trans. Neural Netw. 2(2), 302–309 (1991)
Mann, P.S.: Statistics for Business and Economics. Wiley, Hoboken (1995)
Hyndman, R.J., Ahmed, R.A., Athanasopoulos, G., Shang, H.L.: Optimal combination forecasts for hierarchical time series. Comput. Stat. Data Anal. 55, 2579–2589 (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendices
Annex 1. ACF and PACF Plot


Annex 2. The Architecture Optimum of Hybrid ARIMA-ANN

Rights and permissions
Copyright information
© 2017 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Wibowo, W., Dwijantari, S., Hartati, A. (2017). Time Series Machine Learning: Implementing ARIMA and Hybrid ARIMA-ANN for Electricity Forecasting Modeling. In: Mohamed, A., Berry, M., Yap, B. (eds) Soft Computing in Data Science. SCDS 2017. Communications in Computer and Information Science, vol 788. Springer, Singapore. https://doi.org/10.1007/978-981-10-7242-0_11
Download citation
DOI: https://doi.org/10.1007/978-981-10-7242-0_11
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7241-3
Online ISBN: 978-981-10-7242-0
eBook Packages: Computer ScienceComputer Science (R0)