
Abstract
App store provides rich information for software vendors and customers to understand the market of mobile applications. However, app store analysis don’t consider some vital factors such as version number, app description and app name currently. In this paper we propose an approach that App Store Analysis can be used to predict app downloads. We use data mining to extract app name and description and app rank information etc. from the Wandoujia App Store and AppCha App Store. We use questionnaire and sentiment analysis to quantify some app nonnumeric information. We revealed strong correlations app name score, app rank, app rating with app downloads by Spearman’s rank correlation analysis respectively. Finally, we establish a multiple nonlinear regression model which app downloads defined as dependent variable and three relevant attributes defined as independent variable. On average, 59.28 % of apps in Wandoujia App Store and 66.68 % of apps in AppCha App Store can be predicted accurately within threshold which error rate is 25 %. One can observe the more detailed classification of app store, the more accurate for regression modeling to predict app downloads. Our approach can help app developers to notice and optimize the vital factors which influence app downloads.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- App store
- Spearman’s rank correlation analysis
- Regression analysis
- Regression model
- App downloads prediction
1 Introduction
The App downloads increases rapidly in App Stores. As of this writing, Wandoujia App Store, AppCha App Store offer tens of thousands apps downloaded by customer daily. We can extract some crucial information from those App Stores. Then we analyze these information to find some relevant factors which influence downloads. App Developers can be noticed that those factors’ optimization for high app downloads which indicates profits.
App downloads is an important indicator for usage of app and crucial factor determining the income from this app, so the App Store Downloads analysis is necessary for us.
The features of App Store analysis include:
-
(a)
It provides app ranking analysis that can visualize historical ranking, daily ranking, and featured ratings for the top apps across major mobile app stores.
-
(b)
It also gives app publishers analytics dashboard to track their app downloads, revenues, rankings and reviews across multiple app stores.
Analysis of user feedback allows application vendors to assess customer response to their mobile apps in the market and to figure out plans to enhance the products in the new release.
In our paper we take app rating and user comments into consideration.
App stores provide a rich source of information about apps concerning their name, description, version, rank, rating, price, and popularity attributes. App rating is available concerning the ratings accorded to apps by the users who downloaded them. App price is available, giving price of apps. App description information is available in the descriptions of apps, but it is in free text format, so data mining is necessary to extract the technical details. App version is app version number currently, which is available. App rank is real time app rank in app store. App Popularity is number when we search app name on Google the entries it return.
In this paper we mined the Wandoujia and AppCha App store for data to support App Store Downloads Analysis. Then we quantified data and made Spearman’s rank correlation analysis to select relevant attributes with app downloads. Last, we established regression model formula to predict app downloads.
Unlike the traditional app analysis, our paper presents new attributes, such as app version number, app popularity. Some app stores although have app rating, its user comment is also important metric. We used app comment sentiment analysis algorithm to quantify user’s comment as a value. To our best knowledge, very few studies were focused on make regression model for each category, even few from over one app store platform. This paper makes regression model from two app store and get some surprising conclusion according to their results comparison.
The primary contributions of this paper are:
-
1.
We quantified App name score and descriptions via questionnaire and sentimental value of App comments (reviews) via sentiment analysis algorithm.
-
2.
We made Spearman’s rank correlation analysis to select top 3 relevant attributes with app downloads from app name score, description score, rank, version number, comment sentiment value.
-
3.
We established a non-linear regression model while top 3 relevant attributes defined as independent variable and app downloads defined as dependent variables.
2 Related Works
Harman et al. [1] used the data mining approach to do the Spearman’s rank correlation analysis of each factor, such as app prices, user ratings and downloads rank. Take the BlackBerry app store for example, 32108 non-free applications data preprocessing and Spearman’s rank correlation analysis did by University College of London. All the applications classified into 19 large category according to their different types and functions explored. One can get that App Price, Rating whose spearman’s rho with app downloads are positive, while the user rating’s spearman’s rho with app downloads is a significant positive correlation.
Pagano and Maalej [2] on the basis of the conclusions of the acquired abroad, expanding a broad study on app design. After got ratings and downloads are positively correlated and app characteristics determine app ratings, we completely set aside app price factors. The kind of app is divided into three categories, are practical (Practical), dependent (Addictive) and Efficient (Effective), then we find feature can make App got high users scores from these three categories respectively. We proposed App design philosophy for UCD (user-center design) and given design criteria for each app category.
Lim and Bentley [3], Kimbler [4] investigated the user feedback in AppStore as an empirical study. User feedback and user involvement are crucial for modern software organizations. Users increasingly rate and review apps in application distribution platforms, called app stores. While part of this feedback is superficial and at most has an impact on download numbers, others include useful comments, bug reports, user experience, and feature requests. This can help developers to understand user needs, extending the application in a ‘democratic’ fashion, towards crowdsourcing requirements.
User reviews become crucial information gradually, much work has focused on it. Fu [5] collected and studied over 13 million user reviews from Google Play, proposed an integrated system to analyze user reviews from three different levels. Guzman [6] presented an approach for extracting app features mentioned in user reviews and their associated sentiments.
3 App Store Analysis Framework
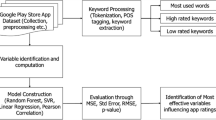
Figure 1 displays the four phases of our analysis on app store including data collection and parsing phase, data quantification, correlation analysis and regression analysis shown in Fig. 1.

Overall app analysis framework
Phase 1 (Data Collection and Parsing)
The goal of this step is to download available data from app store web sites. We implemented a web crawler to collect raw data from Wandoujia App Store [7] and AppCha [8] App Store respectively. Our crawler downloads app information in the following two steps. First, it retrieves all information of every category and sub-category from the App Stores. Then, it scans each subcategory page to collect the list of URLs of all the apps in each subcategory. Following to the URLs of the apps, the crawler can further fetch raw app data by visiting the webpage of the apps.
In the parsing phase, we extract the attributes of the apps by parsing the raw data according to customized search rules. These rules are designed based on identified HTML tags, each of which represents a unique sign for each attribute of the apps. For example, one can extract the name of the apps by searching the value of <span> HTML tag with ‘class=title’ in Wandoujia App Store. One can also obtain the name of the apps by searching the value of <h1> HTML tag in AppCha App Store.
This process cannot be entirely automated because some attributes field must be manually refined due to the loss or unexpected of app information. For example, the value of an app price should be numeric, but sometimes the retrieved value of the price field shows ‘Free’. In such a situation, we have to manually assign a zero value to the field to meet the requirements in AppCha App Store.
Phase 2 (Data Quantification)
Questionnaire for Evaluating App Name and Description.
As an important and intuitive aspect of a mobile app, the name and description of the app may have a significant influence on customers whether to download it. When a customer looks for an app for his needs, he often searches the directory of an App Store using the keywords pertaining to the app’s features and locates the best app candidates. If he encounters the apps with the attractive name or satisfying app description, the good impression may stimulate him to download the app and try it out in his smart phone. Therefore, the app name and description can be regarded as potentially valuable indicators for predicting the popularity of the app.
In order to evaluate customer perception of the name and description of Apps, we took a survey approach to investigate the popularity of the name the description among potential customers. We designed and distributed a questionnaire for users on the Diaoyanbao website (http://www.diaoyanbao.com/) to rate the name of every app in our database. To get a better feedback, this questionnaire is 10-points. The scoring criteria of App’s name is: are attractive (out of 3 points), is impressive (out of 3 points), if people desire to download (out of 4 points). In order to avoid interference in individual cases, this questionnaire limited a tester answering the questionnaire should not exceed three times. This survey we distributed 1050 questionnaires and tack back 927 valid questionnaires.
Quantification of App description is same as app name. The difference is scoring criteria: are articulate (out of 3 points), this description whether to allow people to know functions and features of App (out of 3 points), if people desire to download (out of 4 points).
Sentimental Analysis for User Reviews.
User reviews on a specific app demonstrate their experience of using this app and significant impact the download number of this app. Some app stores implement user rating based on the summary of user reviews. It is very important for app vendors to achieve good user ratings to convince potential users to download their apps. Therefore, user ratings and reviews are closed related and can be used as primary factors to predict user downloads.
Wandoujia, one of the two app stores we investigated, doesn’t provide explicit user rating to customers. To find out how user feedbacks affect app downloads in that case, we have to analyze user sentiments in user reviews about apps to quantitatively determine if users are praising an app or complaining about the apps.
We apply lexical sentiment analysis which uses dictionaries of words annotated with their semantic orientation (polarity and strength) and incorporates intensification and negation in Wandoujia App Store. The success of lexical sentiment analysis heavily depends upon the accuracy of sentiment dictionary. We conducted frequency statistics on the user reviews used Chinese sentiment dictionary called Hownet [9, 10] Dictionary.
Released by CNKI. Based on this extended dictionary, one can run the following sentiment analysis algorithm (Algorithm 1) to calculate each app review’s sentiment scores [11–13].
Phase 3 (Spearman’s Rank Correlation Analysis)
In order to determine the primary factors affecting app download, we adopt the Spearman’s rank correlation analysis [4] for measuring statistical dependence between the downloads and other independent variables such as App Name, Description, App Ranking, App Rating and User Reviews. The Spearman’s rho can indicate the significance of the correlation between two variables.
Phase 4 (Regression Analysis)
After determining the primary factors, one can develop a prediction model for estimating app downloads via regression analysis. Such a model enables vendors and customers to understand how app ranking or other factors can influence app downloads in the market. We remove irrelevant factors according to their Spearman’s rho with app downloads. The remaining factors defined as independent variables, app downloads defined as dependent variable. Then, we make nonlinear regression to establish a model for app downloads prediction.
For the multiple nonlinear regression, one can use ordinary least squares for optimizing the regression formula to predict app downloads approximately. While the number of independent variables over one regression defined as multiple regression. We transform non-linear regression into a linear regression via change variable, and then use statistical device for linear processing. According to the experience acquired, we can get output and input variables expression, but its coefficient is unknown. We determine the final input-output coefficients based on several times’ observations. Last, you can get a preliminary non-linear regression model based on least squares method to obtain the coefficient values.

Table 1 shows the example of user reviews’ sentiment value computed by Algorithm 1.
4 Experimental Result Analysis
4.1 Spearman’s Rank Correlation Analysis
Spearman’s rank correlation analysis is used to identify the significant relevance between each attribute with app downloads.
For Wandoujia App Store, we investigated the relevance of the five features (i.e. App Name Score, App Description Score, Rank, Version Number, Comment Sentiment Value) with app downloads. Figure 2 shows the Spearman’s rho of each attribute. Clearly, Comment Sentiment Value and App Name Score attributes have more positive impact on app downloads for every kind of app. Rank is negatively related to app downloads. The correlation values of both Version Number and Description Score have little influence on app downloads.

Spearman’s rho between each attribute and app downloads in Wandoujia App Store
For AppCha App Store, we investigated the relevance of the five features (i.e. App Name Score, Price, Rating, Rank, Update Times) with app downloads. Figure 3 shows the Spearman’s rho of each attribute. Clearly, Rating and App Name Score attributes have positive impact on app downloads for every kind of app. And interestingly, Rank is negatively related to app downloads. The correlation values of both Price and Update Times stay close to the zero value, which indicates that both features have little inflence.

Spearman’s rho between each attribute and app downloads in AppCha App Store
4.2 Regression Analysis
-
(1)
Wandoujia App Store
From Fig. 2, one can observe that the three major factors including App Rank, Comment Sentiment Value, Name Score are more relevant with App Downloads than the other attributes. Therefore, we select these primary attributes to develop a multiple nonlinear regression model for predicting app downloads. Table 2 displays the variables in the regression model where App Rank, Comment Sentiment Value, Name Score are defined as independent variables and app downloads is defined as the dependent variable.
We trained the regression model with 1739 apps instances in Wandoujia App Store. The multiple nonlinear regression formula is shown in:
The rest of 1676 app instances are utilized as testing data to verify the accuracy of regression model. The validation result shows that the prediction model has a very poor performance: only 10 % apps can achieve the prediction error rate at less 50 %. Therefore, the nonlinear regression model is not applicable for the whole Wandoujia app store, app downloads. We have to examine the effectiveness of the multiple nonlinear regression model in each category instead of the entire app store.
Based on the category defined by the Wandoujia app store, we trained non-linear regression models for every category. Table 3 displays the accuracy of these models. In average, the model is capable of giving a good estimation of download numbers for 54.42 % app instances within seven categories.
Here, we present Video & Image category as an example of the category-specific regression models as its prediction accuracy is the highest among them. The regression formula trained over 249 app instances of the Video group is shown below:
The rest of 249 app instances are utilized as testing data to verify the accuracy of regression model.
Figure 4 demonstrates the testing result. Although the prediction model seems to give a reasonable estimation for app downloads, the threshold for the error rate is still pretty high to 50 %, thus failing to ensure the high accuracy of the prediction.

Comparison between app downloads and prediction result (Apps belonging to the Video & Image category) (Color figure online)
Figure 5 shows that downloads prediction error is over large while app downloads is over 2000 thousands, this implies app prediction is not effective. Meanwhile, downloads prediction error is also large while app downloads is under 1000. So, we may remove some app instances which app downloads under 1000 and over 2000 thousands.

Downloads prediction error of apps at category level (Color figure online)
After eliminating the data samples under 1000 and over 2000 thousands, which often yield high predication errors, we trained the regression model with 170 app instances of Video & Image category again. Then the regression formula is:
The rest of 169 app instances as testing data to verify the accuracy of regression model. Figure 6 shows the improved prediction result.

Comparison between app downloads and prediction within a narrowed range of download number (Apps belong to Video & Image) (Color figure online)
Table 4 displays the accuracy of this model. In average, the model is capable of giving a good estimation of download numbers for 59.28 % app instances within seven categories. The threshold for the error rate is 25 %, thus it can ensure the high accuracy of the prediction. But when the app downloads is under 1000 and over 2000 thousands, we can trained the regression model for these two exceptions.
After Spearman’s rank correlation analysis, one can observe App name score, Rank, Comment sentiment value are still relevant attributes with app downloads when app downloads under 1000, Rank is not any longer a relevant attributes with app downloads while app downloads over 2000 thousands.
When app downloads is under 1000:
The regression formula is:
Table 5 displays the prediction accuracy when app downloads under 1000. In average, the model is able to give a good estimation of download numbers for 74.16 % app instances within seven categories. The threshold for the error rate is also 25 %, thus it can ensure the high accuracy of the prediction when app downloads under 1000.
When app downloads is under 2000 thousands:
The regression formula is:
Table 6 shows the prediction accuracy when app downloads over 2000 thousands. In average, the model is capable of giving a perfect prediction of app downloads for 83.28 % app instances within seven categories. The threshold for the error rate is also 25 %, thus it can ensure the high accuracy of the prediction when app downloads over 2000 thousands.
-
(2)
AppCha App Store
From Fig. 3, one can observe that the three major factors including App Rank, App Rating, App Name Score are more relevant with App Downloads than the other attributes. Therefore, we select these primary attributes to develop a multiple nonlinear regression model for predicting app downloads.
Table 7 displays the accuracy of regression models which app downloads between 100 and 10000 in AppCha App Store. In average, the model is capable of giving a good estimation of app downloads for 66.68 % app instances within 24 categories. The threshold for the error rate is also 25 %, thus it can ensure the high accuracy of the prediction in AppCha App Store.
One can observe that App Rank, App Rating (App Comment Sentiment Value), App Name Score is more relevant to App Downloads than other attributes. Figure 7 shows variance of each attribute’s Spearman’s rho with app downloads in Wandoujia and AppCha Store.

Variance of each attribute’s spearman’s rho with downloads in Wandoujia and AppCha Store (Color figure online)
Apparently, the variance of Spearman’s rho on Wandoujia is much higher than that on AppCha App Store. The fluctuations of each attribute on Wandoujia is much higher than AppCha App Store, implying that the more detailed classification, the more stable of various factors. Regression model established on AppCha to predict app downloads is more accurate than Wandoujia, which indicated regression model established on AppCha is closer to real downloads scenes.
Figure 8 shows the reflection of categories from Wandoujia to AppCha App Store. One can observe that prediction accuracy is higher in AppCha than Wandoujia App Store correspondingly, thus it implies the more detailed classification for App Store, the more useful for app downloads prediction using regression model.

Reflection of categories from Wandoujia to AppCha App Store
5 Conclusion and Future Works
App stores provide a software development space and market place where we can extract some useful information and dispose it to get conclusion we want.
We have proposed an approach to extract name, comment, description, version name, rank of app in two app stores. Some information are not digital, so we quantify it via questionnaire and sentiment analysis. Then we make Spearman’s rank correlation analysis about each attribute with downloads. According to spearman’s rho, we select the more relevant attributes to regression modeling. In modeling phase, app downloads regarded as dependent variable, relevant attributes as independent variable.
We found a multiple nonlinear regression model formula to predict app downloads of each app category. These models are capable of giving a good estimation of download numbers for 59.28 % app instances within seven categories in Wandoujia App Store and 66.68 % app instances within 24 categories in AppCha App Store averagely. The threshold for the error rate is 25 %. But former models just suitable for appropriate app downloads. We adopt another regression models to predict app downloads when downloads too little or too large. One can observe that prediction accuracy is 0.7416 and 0.8238 when app downloads is under 1000 and over 2000 thousands respectively in Wandoujia App Store averagely.
We can conclude that the more detailed classification of app platform, the more accurate for regression modeling to predict app downloads.
In the future, we also intend to consider other attributes app image, app tag etc. because of various factor to influence app downloads. We will optimize comment sentiment analysis algorithm for basis of segment location currently. The relative sensitivity of our model regressed for App downloads predication is not high, and the model is based on the App subcategories, universality is not strong. Future research can focus on the optimization model, we will try to further improve the accuracy and universality of the model.
References
Harman, M., Jia, Y., Zhang, Y.: App store mining and analysis: MSR for app stores. In: 2012 9th IEEE Working Conference on Mining Software Repositories (MSR), pp. 108–111, 2–3 June 2012
Pagano, D., Maalej, W.: User feedback in the appstore: an empirical study. In: 2013 21st IEEE International Requirements Engineering Conference (RE). IEEE (2013)
Lim, S.L., Bentley, P.J.: Investigating app store ranking algorithms using a simulation of mobile app ecosystems. In: 2013 IEEE Congress on Evolutionary Computation (CEC), pp. 2672–2679, 20–23 June 2013
Kimbler, K.: App store strategies for service providers. In: 2010 14th International Conference on Intelligence in Next Generation Networks (ICIN), pp. 1–5, 11–14 October 2010
Fu, B., Lin, J., Li, L., et al.: Why people hate your app: making sense of user feedback in a mobile app store. In: Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1276–1284. ACM (2013)
Guzman, E., Maalej, W.: How do users like this feature? A fine grained sentiment analysis of app reviews. In: 2014 IEEE 22nd International Requirements Engineering Conference (RE), pp. 153–162. IEEE (2014)
Wandoujia App Store [EB/OL]. http://www.wandoujia.com/apps
AppCha App Store [EB/OL]. http://www.appcha.net/
Goul, M., Marjanovic, O., Baxley, S.; Vizecky, K.: Managing the enterprise business intelligence app store: sentiment analysis supported requirements engineering. In: 2012 45th Hawaii International Conference on System Science (HICSS), pp. 4168–4177, 4–7 January 2012
Severance, C.: Toward developing an education app store. Computer 44(8), 107–109 (2011)
Zhao, Y., Niu, K., He, Z., Lin, J., Wang, X.: Text sentiment analysis algorithm optimization and platform development in social network. In: 2013 Sixth International Symposium on Computational Intelligence and Design (ISCID), pp. 410–413, 28–29 October 2013
Li, S., Zhang, H., Xu, W., Chen, G., Guo, J.: Exploiting combined multi-level model for document sentiment analysis. In: 2010 20th International Conference on Pattern Recognition (ICPR), pp. 4141–4144, 23–26 August 2010
Sui, H., You, J., Zhang, H., Zhou, W.: Sentiment analysis of Chinese micro-blog using semantic sentiment space model. In: 2012 2nd International Conference on Computer Science and Network Technology (ICCSNT), pp. 1443–1447, 29–31 December 2012
Acknowledgment
This work was supported in part by grant from State Key Laboratory of Software Development Environment (Funding No. SKLSDE-2015ZX-03) and NSFC (Grant No. 61532004).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Science+Business Media Singapore
About this paper
Cite this paper
Wang, S., Wu, W., Zhou, X. (2016). App Store Analysis: Using Regression Model for App Downloads Prediction. In: Che, W., et al. Social Computing. ICYCSEE 2016. Communications in Computer and Information Science, vol 623. Springer, Singapore. https://doi.org/10.1007/978-981-10-2053-7_19
Download citation
DOI: https://doi.org/10.1007/978-981-10-2053-7_19
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-2052-0
Online ISBN: 978-981-10-2053-7
eBook Packages: Computer ScienceComputer Science (R0)