
Abstract
This paper summarize our work so far on reliability based design optimization (RBDO) by using metamodels and present some new ideas on RBDO using support vector machines. Design optimization of complex models, such as non-linear finite element models, are treated by fitting metamodels to computer experiments. A new approach for radial basis function networks (RBFN) using a priori bias is suggested and compared to established RBFN, Kriging, polynomial chaos expansion, support vector machines (SVM), support vector regression (SVR), and least square SVM and SVR. Different types of computer experiments are also investigated such as e.g. S-optimal design of experiments, Halton- and Hammersley sampling, and different adaptive sampling approaches. For instance, SVM-supported sampling is suggested in order to improve the limit surface by putting extra sampling points at the margin of the SVM. Uncertainties in design variables and parameters are included in the design optimization by FORM- and SORM-based RBDO. By establishing the most probable point (MPP) at the limit surface using a Newton method with an inexact Jacobian, Taylor expansions of the metamodels are done at the MPP using intermediate variables defined by the iso-probabilistic transformation for several density distributions such as lognormal, gamma, Gumbel and Weibull. In such manner, LP- and QP-problems are derived which are solved in sequence until convergence. The implementation of the approaches in an in-house toolbox are very robust and efficient. This is demonstrated by solving several examples for a large number of variables and reliability constraints.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
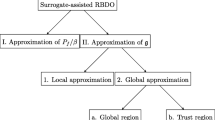
Over a period of many years an in-house toolbox named MetaBox for metamodel-based simulations and optimization with and without uncertainties has been develop during different research projects. Today, the toolbox contains several approaches for DoE, a bunch of metamodels packed together as an ensemble of metamodels, and methods for simulations and optmizations with uncertainties such as Monte Carlo, FORM, SORM and RBDO. This paper presents the current status of the toolbox concerning metamodel-based RBDO. An overview of available options in MetaBox is given in Fig. 1.
The project of MetaBox was initiated by simulating rotary draw bending using artificial neural networks (ANN) [1]. It was concluded that several hidden layers are needed in order to get satisfactory results. Shortly after, we started to develop a successive response surface methodology using ANN [2, 3]. This approach has proven to be very efficient for screening and generating proper DoEs. Methods for DoE of non-regular spaces were developed in [4, 5]. In particular, the S-optimal DoE presented in this paper has proven to be very useful. Work on metamodel-based simulations with uncertainties was initiated in [6]. Then, work on metamodel-based optimization with uncertainties was started, during several years [7,8,9,10] a framework for metamodel-based RBDO was developed. Meanwhile, several metamodels were also implemented in MetaBox such as Kriging, RBFN [11,12,13], polynomial chaos expansion (PCE), SVM [14] and SVR.
The outline of the paper is as follows: in Sect. 2 a short overview of implemented metamodels in MetaBox is given, in Sect. 3 the main ideas of FORM- and SORM-based RBDO as well as our implemented SQP-based RBDO algorithm are presented, in Sect. 4 a well-known benchmark is studied using different choices of DoEs and metamodels with and without uncertainties. Finally, some concluding remarks are given.

Available options in MetaBox (www.oru.se).
2 Metamodels
Let us assume that we have a set of sampling data \(\{\hat{\varvec{x}}^i,\hat{f}^i\}\) obtained from design of experiments. We would like to represent this set of data with a function, which we call a response surface, a surrogate model or a metamodel. One choice of such a function is the regression model given by
where \({\varvec{\xi }}={\varvec{\xi }}({\varvec{x}})\) is a vector of polynomials of \({\varvec{x}}\) and \({\varvec{\beta }}\) contains regression coefficients. By minimizing the sum of squared errors, i.e.
where \(X_{ij}= \xi _j(\hat{\varvec{x}}^i)\) and N is the number of sampling points, then we obtain optimal regression coefficients from the normal equation according to
Examples of other useful metamodels are Kriging, radial basis functions, polynomial chaos expansion, support vector machines and support vector regression. The basic equations of these models as implemented in MetaBox are presented in the following.
2.1 Kriging
The Kriging model is given by
where the first term represents the global behavior by a linear or quadratic regression model and the second term ensures that the sample data is fitted exactly. \({\varvec{R}}={\varvec{R}}({\varvec{\theta }})=[R_{ij}]\), where
Furthermore, \({\varvec{\theta }}^*\) is obtained by maximizing the following likelihood function:
and
2.2 Radial Basis Function Networks
For a particular signal \(\hat{\varvec{x}}^k\) the outcome of the radial basis function network can be written as
where \(N_{\varPhi }\) is the number of radial basis functions, \(N_{\beta }\) is the number of regression coefficients in the bias,
Both linear and quadratic regression models are used as bias. Furthermore, \(\varPhi _i=\varPhi _i(\hat{\varvec{x}}^k)\) represents the radial basis function.
Thus, for a set of signals, the corresponding outgoing responses \({\varvec{f}}=\{f^i\}\) of the network can be formulated compactly as
where \({\varvec{\alpha }} = \{\alpha _i\}\), \({\varvec{\beta }}=\{\beta _i\}\), \({\varvec{A}}=[A_{ij}]\) and \({\varvec{B}}=[B_{ij}]\). If we let \({\varvec{\beta }}\) be given a priori by the normal equation as
then
Otherwise, \({\varvec{\alpha }}\) and \({\varvec{\beta }}\) are established by solving
2.3 Polynomial Chaos Expansion
Polynomial chaos expansion by using the Hermite polynomials \(\varphi _n=\varphi _n(y)\) can be written as
where \(M+1\) is the number of terms and constant coefficients \(c_i\), and \(N_{\text{ VAR }}\) is the number of variables \(x_i\). The Hermite polynomials are defined by
For instance, one has
The unknown constants \(c_i\) are then established by using the normal equation. A nice feature of the polynomial chaos expansion is that the mean of \(f({\varvec{X}})\) in (14) for uncorrelated standard normal distributed variables \(X_i\) is simply given by
2.4 Support Vector Machines
Let us classify the sampling data in the following manner:
where \(\tilde{f}\) is a threshold value. The soft non-linear support vector machine separate sampling data of different classes by a hyper-surface on the following format:
where \(k({\varvec{x}}^i,{\varvec{x}})\) is a kernel function, and \(\lambda ^{*}_i\) and \(b^*\) are obtained by solving
The least-square support vector machine is established by solving
where \({\varvec{y}}=\{y^1;\ldots ;y^N\}\), \(\gamma =1/C\), \({\varvec{1}}=\{1;\ldots ;1\}\) and
2.5 Support Vector Regression
The soft non-linear support vector regression model reads
where \(\lambda ^i\), \(\hat{\lambda }^i\) and \(b^*\) are established by solving
Finally, the corresponding least square support vector regression model is established by solving
where \(\gamma =1/C\), \({\varvec{1}}=\{1;\ldots ;1\}\) and
is a matrix containing kernel values.
3 Reliability Based Design Optimization
By using the metamodels presented in the previous section it is straight-forward to set up any design optimization problem as
For instance the metamodel \(f=f({\varvec{x}})\) might represent the mass of a design and \(g=g({\varvec{x}})\) is a metamodel-based limit surface for the stresses obtained by finite element analysis.
A possible draw-back with the formulation in (27) is that it is not obvious how to include a margin of safety. For instance, what is the optimal safety factor to be included in g? An alternative formulation that includes a margin of safety is
where \({\varvec{X}}\) now is treated as a random variable, \(\mathrm {E}[\cdot ]\) designates the expected value of the function f, and \(\mathrm {Pr}[\cdot ]\) is the probability that the constraint \(g\le 0\) being true. \(P_s\) is the target of reliability that must be satisfied.
3.1 FORM
An established invariant approach for estimating the reliability is the first order reliability method (FORM) suggested by Hasofer and Lind. The basic idea is to transform the reliability constraint from the physical space to a space of uncorrelated standard Gaussian variables and then find the closest point to the limit surface from the origin. This point is known as the most probable point (MPP) of failure. The distance from the origin to the MPP defines the Hasofer-Lind reliability index \(\beta _{\text{ HL }}\), which in turn is used to approximate the probability of failure as
Assuming that \({\varvec{X}}\) is normal distributed with means collected in \({\varvec{\mu }}\) and \({\varvec{\sigma }}\) containing standard deviations, the MPP is obtained by solving
3.2 SORM
The approximation in (29) is derived by performing a first order Taylor expansion at the MPP and then evaluating the probability. Second order reliability methods (SORM) is obtained by also including the second order terms in the Taylor expansion. Based on these higher order terms the FORM approximation of the reliability is corrected.
For instance, by letting \(\lambda _i\) denoting the principle curvatures of a second order Taylor expansion of g, we can correct (29) by using e.g. Tvedt’s formula, i.e.

3.3 SQP-based RBDO Approach
Recently, a FORM-based SQP approach for RBDO with SORM corrections was proposed in [10]. For non-Gaussian variables, we derive the following FORM-based QP-problem in the standard normal space:
where

Here, \(\beta _t=\varPhi ^{-1}(P_s)\) is the target reliability index which can be corrected by a SORM approach as presented above or any Monte Carlo approach. The optimal solution to (32), denoted \(\eta _i^*\), is mapped back from the standard normal space to the physical space using
Then, a new QP-problem is generated around \({\varvec{\mu }}^{k+1}\) and this procedure continues in sequence until convergence is obtained. The QP-problem in (32) is solved using quadprog.m in Matlab.

Different design of experiments.
4 Numerical Examples
In order to demonstrate the metamodel-based RBDO approach presented above, we consider the following well-known benchmark:
where \(\mathrm {VAR}[X_i]=0.3^2\). A small modification of the original problem is done by taking the square of the objective function. This problem was recently considered in [10] by solving (32) sequentially. The example was in that work also generalized to 50 variables and 75 constraints for five different distributions simultaneously (normal, lognormal, Gumbel, gamma and Weibull). The analytical solution for two variables with normal distribution is obtained to be (3.4525, 3.2758) 45.2702 with our RBDO algorithm. The corresponding deterministic solution is (3.1139, 2.0626) 26.7965.
Now, we will consider (34) to be a “black-box”, which we treat by setting up design of experiments and metamodels. The quality of the metamodel is dependent on the choice of DoE. Figure 2 presents four useful strategies of DoEs. In Fig. 2a we adopt successive screening to set up the DoE, in Fig. 2b we use space-filling with a genetic algorithm by maximizing the distance to the closest point, and in the other two figures we apply Halton and Hammersley sampling. For these four sets of sampling data, we set up 12 different metamodels automatically and then find the deterministic solution for each metamodel-based problem of our “black-box”. The solutions are presented in Table 1. One concludes that the solutions depend on the choice of DoE and metamodel. For many combinations the corresponding “black-box” solution is very close to the analytical one.

Left: successive screening using Halton sampling, right: adaptive sampling using MPP and SVM.
The choices of DoE strategy and metamodel is even more pronounced when we perform metamodel-based RBDO. In Fig. 3, we set up the DoE for RBDO by first performing successive screening with Halton sampling, then this DoE is augmented by adding the sampling points (green dots) based on the optimal solutions (deterministic and RBDO solution) and the active most probable points as well as points (red dots) along the limits surface based on a global SVM [14]. The corresponding metamodel-based RBDO solutions are presented in Table 2 as well as the corresponding solutions for the successive factorial DoE presented in Table 1. One concludes that the choices of augmented successive Halton sampling and RBFN, PCE or SVR produce the best performance. For these choices the metamodel-based “black-box” solution is close to the analytical one.
5 Concluding Remarks
A framework for metamodel-based RBDO has been developed and implemented in MetaBox. Several options of DoEs, metamodels and optimization approaches are possible. In a near future, optimal ensemble of metamodels will also be available as an option.
References
Strömberg, N.: Simulation of rotary draw bending using Abaqus and a neural network. In: Proceedings of Nafems Nordic Conference on Component and System Analysis using Numerical Simulation Techniques - FEA, CFD, MBS, Gothenburg, 24–25 November 2005
Gustafsson, E., Strömberg, N.: Shape optimization of castings by using successive response surface methodology. Struct. Multi. Optim. 35, 11–28 (2008)
Gustafsson, E., Strömberg, N., Successive response surface methodology by using neural networks. In: Proceedings of the 7th World Congress on Structural and Multidisciplinary Optimization, Seoul, Korea, 21–25 May 2007
Hofwing, M., Strömberg, N.: D-optimality of non-regular design spaces by using a bayesian modification and a hybrid method. Struct. Multi. Optim. 42, 73–88 (2010)
Hofwing, M., Strömberg, N.: D-optimality of non-regular design spaces by using a genetic algorithm. In: Proceedings of 8th World Congress on Structural and Multidisciplinary Optimization, Lisbon, Portugal, 1–5 June 2009
Hofwing, H., Strömberg, N.: Robustness of residual stresses in castings and an improved process window. In: Proceedings of the 35th Design Automation Conference, ASME, San Diego, USA, 30 August–2 September 2009
Strömberg, N., Tapankov, M.: Sampling- and SORM-based RBDO of a knuckle component by using optimal regression models. In: Proceedings of the 14th AIAA/ISSMO Multidisciplinary Analysis and Optimization Conference, Indianapolis, Indiana, 17–19 September 2012
Strömberg, N.: RBDO with non-Gaussian variables by using a LHS- and SORM-based SLP approach and optimal regression models. In: Proceedings of the 3rd International Conference on Engineering Optimization, Rio de Janeiro, Brazil, 1–5 July 2012
Strömberg, N.: Reliability based design optimization by using a SLP approach and radial basis function networks. In: Proceedings of the ASME 2016 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference IDETC/CIE, Charlotte, North Carolina, USA, 21–24 August 2016
Strömberg, N.: Reliability-based design optimization using SORM and SQP. Struct. Multi. Optim. 56, 631–645 (2017)
Amouzgar, K., Rashid, A., Strömberg, N.: Multi-Objective optimization of a disc brake system by using SPEA2 and RBFN. In: Proceedings of 39th Design Automation Conference, ASME, Portland, Oregon, USA, 4–7 August 2013
Amouzgar, K., Strömberg, N.: An approach towards generating surrogate models by using RBFN with a priori bias. In: Proceedings of 40th Design Automation Conference, ASME, Buffalo, New York, USA, 17–20 August 2014
Amouzgar, K., Strömberg, N.: Radial basis functions as surrogate models with a priori bias in comparison with a posteriori bias. Struct. Multi. Optim. 55, 1453–1469 (2017)
Strömberg, N.: Reliability-based design optimization by using support vector machines. In: Proceedings of ESREL - European Safety and Reliability Conference, Trondheim, Norway, 17–21 June 2018
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Strömberg, N. (2019). Reliability Based Design Optimization by Using Metamodels. In: Rodrigues, H., et al. EngOpt 2018 Proceedings of the 6th International Conference on Engineering Optimization. EngOpt 2018. Springer, Cham. https://doi.org/10.1007/978-3-319-97773-7_22
Download citation
DOI: https://doi.org/10.1007/978-3-319-97773-7_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-97772-0
Online ISBN: 978-3-319-97773-7
eBook Packages: EngineeringEngineering (R0)