
Abstract
Many consensus clustering methods ensemble all the basic partitionings (BPs) with the same weight and without considering their contribution to consensus result. We use the Normalized Mutual Information (NMI) theory to design weight for BPs that participate in the integration, which highlights the contribution of the most diverse BPs. Then an efficient approach K-means is used for consensus clustering, which effectively improves the efficiency of combinatorics learning. Experiment on UCI dataset iris demonstrates the effective of the proposed algorithm in terms of clustering quality.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
There is no single clustering algorithm can performs best for all data sets [1], and can discover all types of cluster shapes and structures [2]. Consensus clustering approached are able to integrate multiple clustering solutions obtained from different data sources into a unified solution, and provide a more robust, stable and accurate final result [3]. However, the previous research still has some limitations.
Firstly, high quality BPs are beneficial to the performance of consensus clustering yet the partitions with poor quality will lead to worse consensus result. But most studies tend to integrate all BPs, and they do not filter poor BPs. Secondly, the diversity between BPs also have great impact on consensus clustering, diverse BPs which means the BP that has different mutual information with other BPs will have different contribution to the consensus result. However, there are few references explore impact of the number of BPs to consensus clustering neither did they take into account the diversity of BPs into the integration process.
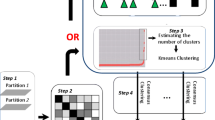
We proposed weight-improved K-means-based consensus clustering (WIKCC). Firstly, we design weight for each BP participating in the integration. Specifically, we generate multiple BPs and measure the quality of each BP using normalized Rand index \( R_{n} \) [6], and sort the BPs in the increasing order of \( R_{n} \), then we explore the influence of the number of BPs on consensus clustering, based on the above exploration we can choose an appropriate number of better BPs for consensus clustering, which can minimize the number of BPs in quality assurance. After that we construct the co-occurrence matrix with the selected BPs, and calculate the similarity of two BPs with Normalized Mutual Information (NMI) method [4] according to the co-occurrence matrix. Then weight of each BP is designed according to NMI values which reflect a single BP to overall BPs’ similarity. K-means-based method [2] make special attention for its simplicity and high efficiency. So we transform consensus clustering to K-means clustering.
2 Weight Design Based on the Normalized Mutual Information
Mutual information is used to measure the shared information of the two distributions. We compute the NMI between two BPs, and the greater the value of NMI means the lower difference, which will result in lower \( {\text{w}}_{\text{i}} \).
Given two BPs results \( \uppi_{\text{i}} \) with \( {\text{K}}_{\text{i}} \) clusters, \( \uppi_{\text{i}} = \left\{ {{\text{C}}_{1}^{{\left( {\text{i}} \right)}} ,{\text{C}}_{2}^{{\left( {\text{i}} \right)}} , \ldots ,{\text{C}}_{{{\text{K}}_{\text{i}} }}^{{\left( {\text{i}} \right)}} } \right\} \) and \( \uppi_{\text{j}} \) with \( {\text{K}}_{\text{j}} \) clusters, \( \uppi_{\text{j}} = \left\{ {{\text{C}}_{1}^{{\left( {\text{j}} \right)}} ,{\text{C}}_{2}^{{\left( {\text{j}} \right)}} , \ldots {\text{C}}_{{{\text{K}}_{\text{j}} }}^{{\left( {\text{j}} \right)}} } \right\} \) the mutual information between two results is defined as follows:
For a single BP the average mutual information can be defined as:
Where \( {\text{h}} \in \left\{ {1,2, \ldots ,{\text{k}}_{\text{i}} } \right\} \), \( {\text{l}} \in \left\{ {1,2, \ldots ,{\text{k}}_{\text{j}} } \right\} \) is one of the cluster result label of \( \uppi_{\text{i}} \) and \( \uppi_{\text{j}} \), \( \left| {{\text{C}}_{\text{h}}^{{\left( {\text{i}} \right)}} } \right| \), \( \left| {{\text{C}}_{\text{l}}^{{\left( {\text{j}} \right)}} } \right| \) respectively represent the number of the data set belong to cluster \( {\text{C}}_{\text{h}}^{{\left( {\text{i}} \right)}} \) in \( \uppi_{\text{i}} \) and \( {\text{C}}_{\text{l}}^{{\left( {\text{j}} \right)}} \) in \( \uppi_{\text{j}} \), \( \left| { {\text{C}}_{\text{h}}^{{\left( {\text{i}} \right)}} \cap {\text{C}}_{\text{l}}^{{\left( {\text{j}} \right)}} } \right| \) is the number of the dataset belong both to \( {\text{C}}_{\text{h}}^{{\left( {\text{i}} \right)}} \) and \( {\text{C}}_{\text{l}}^{{\left( {\text{j}} \right)}} \), r is the number of the BPs.
The greater \( H\left( {\pi_{i} } \right) \) indicate that cluster member \( \pi_{i} \) share more information with other cluster members. The weight is defined as:
The normalized form is defined as:
The weight is bigger as the greater diversity between two base clustering.
3 The Weight-Improved K-Means-Based Consensus Clustering
In this section, we first introduce the co-occurrence matrix which is used for records the situation of sharing dataset between two BPs. Table 1 shows an example.
In Table 1, BPs: \( \pi^{*} \) and \( \pi_{i} \) contain k and \( k_{i} \) clusters respectively, \( n_{{KK_{i} }}^{\left( i \right)} \) represents the number of the objects that belongs to both \( C_{K} \) and \( C_{{K_{i} }}^{\left( i \right)} \), then let \( n_{{k_{ + } }} = \sum\nolimits_{j = 1}^{{K_{i} }} {n_{kj}^{\left( i \right)} } ,1 \le j \le K_{i} ,1 \le k \le K,P_{kj}^{\left( i \right)} = n_{kj}^{\left( i \right)} /n,p_{k + } = n_{k + } /n ,and \,p_{ + j}^{\left( i \right)} = n_{ + j}^{\left( i \right)} /n \). We can obtain a normalized co-occurrence matrix (NCM), based on which we can compute the centroid of the K-means clustering.
K-means algorithm cannot directly run on the co-occurrence matrix, so a binary data set is introduced to represent the result of r BPs. The binary data set \( X_{l}^{\left( b \right)} = \{ x_{l}^{\left( b \right)} |1 \le l \le n\} \) as follows:
Where \( x_{l}^{\left( b \right)} \) is an n \( \times \sum\nolimits_{i = 1}^{r} {K_{i} } \) binary data set matrix with \( \left| {x_{l,i}^{\left( b \right)} } \right| = 1 \).
We use the K-means algorithm to integrate the BPs, suppose r BPs are integrated to a result \( \pi^{*} \), \( m_{k} \) represent the centroid of the \( C_{k} \;in\;\pi^{*} \) as follows:
The centroids of the K-means on \( X^{b} \) are represented as follows:
The centroids can be computed by the Co- occurrence matrix, and \( m_{k} \) is a vector of \( \sum\nolimits_{i = 1}^{r} {k_{i} } \) dimension. The element in the vector is computed by the number of shared data set between current cluster and all of the clusters of BPs.
By using the co-occurrence matrix and the binary data set the consensus clustering are transformed to the K-means clustering, that is:
As shown in Fig. 1. In BPs generation phase, classic partition clustering method K-means is used, different initial number of cluster k, to generate diversified BPs. In consensus clustering phase, after generating the BPs and computing the weight for each clustering member, we can obtain the weighted co-occurrence matrix, and then we can get the weighted binary dataset \( X^{\left( b \right)\prime } \), by running K-means on weighted binary dataset \( X^{\left( b \right)\prime } \), we can get final consensus result \( \pi^{*} \).

Algorithm WIKCC
4 Experimental Results
We present experiment on UCI dataset iris. The normalized Rand index (\( {\text{R}}_{\text{n}} \)) [6] is adopted. Its value usually range between [0,1]. The higher value, indicate that the higher quality of clustering. We demonstrate the cluster validity of WIKCC by comparing it with two well-known consensus clustering algorithms the K-means-based algorithm (KCC) [2], the hierarchical algorithm (HCC) [5].
4.1 Quality of BPs
We run K-means algorithm 100 times with the initialized number of clusters randomized within [K, \( \sqrt n \)] to generate 100 basic partitionings (BPs) for consensus clustering; K is the true class of data set, n is the number of the instances, the squared Euclidean distance is used for the distance function, the quality of each BPs is measured by \( R_{n} \), the distribution of quality of BPs is shown as Fig. 2.

Clustering quality distribution of BPs
As can be seen in Fig. 2, the distribution of the clustering quality of the BPs show that there is a large proportion of BPs with poor quality, but only quite a small proportion of BPs with relatively high quality. This shows that the incorrect pre-specified number of classes will lead to weak clustering result.
4.2 Exploration of Impact Factors
In order to In order to determine a suitable number of BPs for WIKCC, we explore the influence of the number of BPs on consensus clustering. In the above experiment, r BPs have generated, and r = 100. We randomly select a part of BPs to obtain the subset \( \prod^{\text{r}} \), with r = 10, 20, …, 90. For each r we do KCC [2] algorithm 100 times to get 100 consensus clustering result. The distribution of the quality of consensus clustering result for different subset is shown as Fig. 3.

Impact of the number of BPs to the consensus clustering
As shown in Fig. 3, when r < 50, the quality of the consensus result present increasing trend with the increase of r, but when r > 50 the result fluctuate in a mall range and nearly tend to be stable, it imply that 50 may be the appropriate number of BPs for WIKCC. Based on above exploration we chose the BPs with the quality of the top 50 BPs for WIKCC.
4.3 WIKCC versus Other Clustering Methods
We compare the WIKCC with KCC and HCC, we choose top 50 better BPs for each method and run on the iris dataset for 10 times.
We can see in Fig. 4. The WIKCC shows significantly higher than KCC, and outperforms better than the HCC in term of the quality of consensus clustering. In addition, comprising the Figs. 2 and 4, we can see that consensus clustering is much better than almost all the basic clustering result obtained by K-means, this indicates that, the consensus clustering method can find the real cluster structure more accurately than a single traditional clustering algorithm by integrating the commonality of many basic clustering results, so it can obtain a more stable and accurate clustering result by ensemble multiple weak BPS.

WIKCC versus KCC and HCC
5 Concluding Remarks
We explore the influence of the number of BPs on the consensus clustering and chose appropriate number better BPs for WIKCC. The weight is designed by the NMI method between two BPs based on co-occurrence matrix. Finally, the experiment on iris demonstrates that WIKCC outperforms the state-of-the-art well-known KCC and HCC algorithms in terms of clustering quality. In the future, we will explore the more other factors that have influence on the performance of KCC, and we will consider more other factors when designing the weights.
References
Strehl, A., Ghosh, J.: Cluster ensembles—a knowledge reuse framework for combining multiple partitions. J. Mach. Learn. Res. 3(12), 583–617 (2002)
Wu, J., Liu, H., Xiong, H., et al.: K-means-based consensus clustering: a unified view. IEEE Trans. Knowl. Data Eng. 27(1), 155–169 (2015)
Yu, Z., Luo, P., You, J., et al.: Incremental semi-supervised clustering ensemble for high dimensional data clustering. IEEE Trans. Knowl. Data Eng. 28(3), 701–714 (2016)
Vinh, N.X., Epps, J., Bailey, J.: Information theoretic measures for clusterings comparison: is a correction for chance necessary? In: Proceedings of the 26th Annual International Conference on Machine Learning, pp. 1073–1080. ACM (2009)
Fred, A.L.N., Jain, A.K.: Combining multiple clusterings using evidence accumulation. IEEE Trans. Pattern Anal. Mach. Intell. 27(6), 835–850 (2005)
Tan, P.-N., Steinbach, M., Kumar, V.: Introduction to Data Mining. Addison-Wesley, Reading (2005)
Acknowledgment
Projected supported by National Natural Science Foundation of China (61472231, 61170038, 61502283, 61640201), Jinan City independent innovation plan project in College and Universities, China (201401202), Ministry of education of Humanities and social science research project, China (12YJA630152), Social Science Fund Project of Shandong Province, China (11CGLJ22, 16BGLJ06).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG
About this paper

Cite this paper
Wang, Y., Xiang, L., Liu, X. (2018). Weight-Improved K-Means-Based Consensus Clustering. In: Zu, Q., Hu, B. (eds) Human Centered Computing. HCC 2017. Lecture Notes in Computer Science(), vol 10745. Springer, Cham. https://doi.org/10.1007/978-3-319-74521-3_6
Download citation
DOI: https://doi.org/10.1007/978-3-319-74521-3_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-74520-6
Online ISBN: 978-3-319-74521-3
eBook Packages: Computer ScienceComputer Science (R0)