
Abstract
Consumer behaviour is often perceived through the notion of consideration sets. However, realistic modelling of consumer choice processes identifies impeding factors, including ignorance and non-specificity. In this chapter, the appeasement of these factors and the role of consideration sets are considered through the utilisation of the nascent Dempster-Shafer/Analytic Hierarchy Process (DS/AHP) method of choice analysis. The central element in the DS/AHP analysis is the body of evidence (BOE), with certain BOE constructed at different stages in the analysis, then a number of different sets of results can be found. The chapter is attempting to convey a more realistic approach for the individual consumer to undertake the required judgement making process. The investigation is based on a group of consumers and their preferences on a number of cars over different criteria. The notion of consideration sets is shown to be fundamental within DS/AHP, and a novel approach to the aggregation of the preferences from the consumers is utilised. A notional approach to the identification of awareness, consideration and choice sets is described, based on the levels of belief and plausibility in the best car existing in a group of cars, which could be compared with the algorithm developed by Gensch and Soofi (Int J Res Mark 12: 25–38, 1995).
The authors would like to thank Dr. Helena Pestana and Ms. Camila Mello for their outstanding assistance during the last stage of preparation and submission of the paper. We are grateful to both.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


Introduction
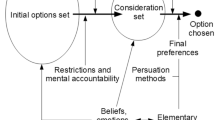
For an individual consumer, the ability to undertake choice is an empowerment of his or her own thought process. Any technique utilised should attempt to allow the consumer to control their contribution without being forced to undertake judgements simply to obey the respective technique’s remit, an acknowledgement of the well-known bounded rationality problem (Simon 1955; Miller 1956). Both internal and external constraints may exist which inhibit a consumer’s choice process. Internal constraints relate from the consumer, including ignorance and non-specificity in their knowledge to a problem. External constraints are those placed on the consumer such as time constraints and information overload (Hogarth 1980).
Consumers use various criteria to analyse their options when they are making a purchase decision. Within multi-criteria decision-making (MCDM), a number of methods have been developed to aid a decision-maker (consumer) in their choice process (Manrai 1995), including multi-attribute utility models (Lock and Thomas 1979; Arora and Huber 2001; Analytis et al. 2014) and the Analytic Hierarchy Process—AHP (Saaty 1977; Benitez et al. 2015). In the case of Analytic Hierarchy Process (AHP), it contends to enable a consumer to deconstruct the problem in question, with the judgement making between the considered decision alternatives (DAs), made sequentially over the different criteria. In this paper, a nascent method of multi-criteria decision-making analysis (Park et al. 2015; Dede et al. 2016) is exposited, namely, Dempster-Shafer/Analytic Hierarchy Process (DS/AHP) (Beynon et al. 2000; Beynon 2002; Wang et al. 2016), with a model structure similar to AHP but analytical foundation based on the Dempster-Shafer theory of evidence—DST (Dempster 1968; Shafer 1976; Taroun and Yang 2013).
Within the extant literature, the issue of consideration sets is an active and ongoing area of consumer research (Roberts and Nedungadi 1995; Roberts and Lattin 1997; Beaman 2013; Goodman et al. 2013; Carson and Louviere 2014). Using DS/AHP, two directions of understanding consideration sets are exposited. Firstly, those which are memory-based and brought to the problem by a consumer (Desai and Hoyer 2000). Secondly, the results from a DS/AHP analysis are in the form of levels of preference on different-sized groups of decision alternatives, DAs (future consideration and choice sets). An aim of this paper is to highlight the notion of consideration sets as a fundamental aspect to the DS/AHP methodology. Further, the elucidation of the benefit of utilising DS/AHP with respect to the internal and external constraints associated with the understood choice process. With a number of consumers considered in the problem, the DS/AHP method incorporates a novel approach for the aggregation of evidence from consumers.
The chapter describes related consumer choice theory with respect to consideration sets, followed by discussion on evaluation and choice. The research focus is then briefly described. It then briefly introduces the Dempster-Shafer theory followed by an exposition of the DS/AHP method within a car choice problem. Results from the DS/AHP method are then presented, followed by interpretation of DS/AHP as an analysis tool in consumer choice MCDM. Finally conclusions are presented as well as directions for future research.
Formation of Consideration Sets
In order to evaluate alternatives, a consideration set has to be formed in the mind of each potential consumer. Many studies have tackled the subject of consideration sets (CS). They have different focuses and investigate many factors associated with the formation or the evaluation of consideration sets. Punj and Brookes (2002) proposed that the manner in which a purchase decision is initiated has an important influence on subsequent product evaluation and choice. Specifically, they proposed that the problem recognition “event” and the consequent retrieval of pre-decisional constraints from memory significantly influence the ensuing processes of external information search and consideration sets formation. Their results suggested that the type of pre-decisional constraints that are activated as a consequence of the problem recognition event significantly influences the “route” consumers follow through the remainder of the purchase process.
Costly search can result in consumers restricting their attention to a subset of products—the consideration set—before making a final purchase decision. The search process is usually not observed, which creates econometric challenges. Pires (2016) shows that inventory and the availability of different package sizes create new sources of variation to identify search costs in storable goods markets. To evaluate the importance of costly search in these markets, he estimates a dynamic choice model with search frictions using data on purchases of laundry detergent. Pires’s estimates show that consumers incur significant search costs, and ignoring costly search overestimates the own-price elasticity for products more often present in consideration sets and underestimates the elasticity of frequently excluded products. Companies employ marketing devices, such as product displays and advertising, to influence consideration sets. These devices have direct and strategic effects, which this author explores using the estimates of the model. Pires finds that using marketing devices to reduce a product’s search cost during a price promotion has modest effects on the overall category revenues, and decreases the revenues of some products.
Gensch and Soofi (1995) proposed an information-theoretic algorithm for estimating the CS. The algorithm estimates the choice probabilities in the awareness sets according to the maximum entropy principle which by use of a multinomial logit model, computes an individual information index for each set, identifies the weak or unacceptable alternatives for each individual and reduces each awareness set to a consideration sets. The average of the selected alternative probabilities was proposed as a statistic by which the predictive quality of various consideration sets can be compared. They found that the predictive power of the multinomial logit is in identifying the weak (non-considered) alternatives rather than predicting the chosen alternative amongst the choices in the consideration sets. The proposed algorithm enables researchers to empirically implement choice set reduction for a given data set using an information criterion.
Several heuristics, including conjunctive, disjunctive, lexicographic, linear additive and geometric compensatory, can be used by individuals in the formation of considerations sets. Most results agree that the conjunctive heuristic is the most often used decision model by consumers (Laroche et al. 2003), suggesting that a brand will be included in a consideration set if it meets the cut-off points in all salient dimensions.
The number of alternatives, which will be evaluated, will vary. Consideration is driven by search costs, opportunity costs and evaluation costs; consideration sets are larger as variance of a brand’s utility over purchase occasions increases (Hauser and Wernerfelt 1990). The brand and product category experience of a specific consumer may also affect the size of the CS (Johnson and Lehmann 1997). A consideration set does not necessarily contain several brands, since a consumer will decide to stop searching for more alternatives if a further search for possible solutions is not perceived to be potentially cost-effective (Lapersonne et al. 1995; Eliaz and Spiegler 2011). Certain consumers may therefore make a decision with a consideration set of size one, and it has been suggested that this phenomenon is rather frequent and the factors predicting the consideration of a single brand have been examined (Lapersonne et al. 1995). It has been also suggested that consideration sets with larger number of alternatives do not necessarily lead to better decisions (Diehl 2004).
Allenby and Ginter (1995) investigated consideration sets with respect to in-store displays and feature advertising, within which they highlight on occasions consumers do not expend sufficient mental effort to arrive at a well-defined set of considered decision alternatives. Shapiro et al. (1997) focused on a research study of incidental advertisement exposure by examining whether incidental exposure to an advertisement increases the likelihood that a product/service depicted in the ad will be included in a consideration set.
Consumers often have to create consideration sets when purchasing goals are not well defined. In these situations, the contents of a consideration sets depend on a combination of two motives. First, consumers prefer to create consideration sets of easy-to-compare alternatives. It is easier to compare alternatives that have alignable attributes or alternatives that have overlapping features. Second, consumers prefer to create consideration sets that have a high likelihood of containing their optimal alternative. For example, when the set of available alternatives requires the consumer to make trade-offs between benefits (i.e., to be compensatory), the consumer often delays making a decision about which benefits are preferable, and the consideration sets tends to contain a more diverse set of alternatives (Chakravarti and Janiszewski 2003; Hauser et al. 2010).
Horowitz and Louviere (1995) presented evidence that operational consideration sets are simply indicators of preference. They argue that for the choice settings they have investigated, choice need not be modelled as a two-step process in which a consideration step precedes choice. They contended that modelling choice this way may lead to a misspecified model that makes erroneous forecasts.
Evaluation and Choice
Consumers evaluate a number of alternatives. The academic literature on cognitive psychology has also devoted several studies to the analysis of memory sets and the concept of “chunking”. For example, the research showing how retention of multiple features as visual chunks may be achieved with and without long-term memory (Raffone and Wolters 2001); the chunking theory of expert memory (Chase and Simon 1973); experiments on latencies and chess relations, inter-chunk intervals, chunk boundaries and retrieval structures (Gobet and Simon 1998a); and motor chunks (Verwey 2003; Wright et al. 2010; Verwey et al. 2016). Verwey (2003) defended the notion that coding of longer keying sequences involves motor chunks for the individual sequence segments and information on how those motor chunks are to be concatenated.
Punj and Brookes (2001) focused on the effects of the consumer decision process on produce evaluation and choice. They have analysed the influence of product-related decision constraints on external information search. They have also formulated some implications on the way consideration sets are formed through their experimental research study. Jeongwen and Chib (1999) analysed the capabilities of accounting for heterogeneity in consideration sets and in the parameters of the brand choice model. The action related to brand choice heterogeneity in ignoring the consideration sets is surely likely to impact on the marketing mix.
Cherenev and Carpenter (2001) examined consumer inferences about product attributes that are unobservable at the time of the decision. Extant research predicts that in the absence of an explicit correlation between product attributes, consumers will infer that the brand that is superior on the observable attributes is also superior on the unobservable attributes. These authors proposed an alternative inference strategy that makes the counter-intuitive prediction that the apparently superior brand is inferior on the unobservable attributes. These authors refer to these inferences as “compensatory inferences” and asserted that they are associated with consumers’ intuitive theories about the competitive nature of a market. Results suggested that consumers’ reliance on compensatory inference strategy is likely to depend on the strength of their market efficiency beliefs and that the strength of compensatory inferences depends on the availability of other bases for inference.
Hastak and Mitra (1996) reported on an experiment designed to investigate the effects of brand cues on subsequent retrieval and consideration of other brands in a product category. Prabhaker and Sauer (1994) presented a conceptual framework for analysing the process by which consumers evaluate brand quality based on multiple cues. These authors focused on the use of hierarchical versus non-hierarchical heuristics by consumers in making overall brand evaluations, as well as on the modelling of individual differences amongst consumers.
Previous research on brand name utilisation in consumer judgements has yielded mixed results. Maheswaran et al. (1992) attempted to understand brand name effects within the framework of the heuristic-systematic model. Results showed that low-task importance subjects’ evaluations were influenced only by brand name valence. High-task importance subjects’ evaluations were affected only by attribute importance in the incongruent conditions, whereas both attribute importance and brand name valence influenced evaluations in the congruent conditions (Guest et al. 2016). Their findings indicated that both consumers’ level of motivation and the extent to which brand name based expectations are confirmed by subsequent processing of attribute information, moderate brand name utilisation. Mitra (1995) focused on the dynamics of consumers’ consideration sets over a series of purchase occasions and suggested some new measures of composition and stability of the consideration sets. The proposed measures were: the number of brands considered at least once, the standard deviation of consideration sets frequencies and the average discordance in consideration sets composition. This author examined how this stability in consideration sets composition was affected by information in advertising. Higher perceived dispersion of brand-utilities resulting from exposure to differentiating advertising is expected to lead to more stable consideration sets over occasions.
Building on the notion that buyers have a category-specific consideration sets of price-quality tiers, Nowlis and Simonson (2000) proposed that sales promotions and the choice set composition (or the choice context) have compensatory effects on brand switching between price-quality tiers. Mehta et al. (2003) offered an econometric framework that models consumer’s consideration sets formation as an outcome of the costly information search behaviour. The proposed structural model dealt with price uncertainty and was estimated using scanner data.
Academic researchers for a number of years have examined the impact of familiarity on consumer decision biases and heuristics. For example, Park and Lessig (1981) studied subjects at three different familiarity levels and results revealed interesting differences in perceptual category breadth, usage of functional and non-functional product dimensions, decision time and confidence. Desai and Hoyer (2000) studied the composition of memory-based consideration sets in terms of their descriptive characteristics, namely stability, variety and preference dispersion. These authors assessed the characteristics of memory-sets relative to occasion and location familiarity. Two experiments investigated by Butler and Berry (2001) demonstrated significant priming for unfamiliar labels and established that priming was unaffected by changing the product type with which the brand name was associated. Also, priming on both auditory and visual versions of the preference judgement task was reduced by changes in modality. Aurier et al. (2000) proposed a theoretical framework and an operationalisation of the concept of consideration sets in relation with usage context. Taking into account the consumer usage situation enables the researcher to analyse the influence of two main components on consideration sets size: context of consumption and familiarity (depth and breadth). These authors showed that CS size varies significantly across consumption contexts and were positively correlated to the breadth of familiarity. Moreover, they found an inverted U relation between the depth of familiarity and consideration sets size.
Chiang et al. (1998) proposed an integrated consideration sets-brand choice model that is capable of accounting for the heterogeneity in consideration sets and in the parameters of the brand choice model. The model was estimated by an approximation Free Markov chain Monte Carlo sampling procedure and was applied to a scanner panel data. They found that ignoring consideration sets heterogeneity understates the impact of marketing mix and overstates the impact of preferences and past purchase feedback even when heterogeneity in parameters is modelled; the estimate of consideration sets heterogeneity was robust to the inclusion of parameter heterogeneity; when consideration sets heterogeneity was included, the parameter heterogeneity took on considerably less importance.
Brown and Carpenter (2000) examined how consumers sometimes treat trivial attributes as though they were critically important in the sense that they have a significant impact on choice. The valence of the effect can depend on whether a positive or negative reason provides a clearer justification for preferring a single brand over its competitors. Thus, the same trivial attribute can generate a positive or negative valuation depending on the choice setting. Such valuation is not always driven by inferences about the attribute itself but can reflect transitory reasoning about the brand as a whole based on the way it is differentiated from its competitors.
Brand choice can be viewed as a two-step process. Households first construct a consideration sets, which does not necessarily include all available brands, and then make a final choice from this set. Vroomen et al. (2003) put forward an econometric model for this two-step process, where they have taken into account that consideration sets usually are not observed. Their model is an artificial neural network, where the CS corresponds with the hidden layer of the network. They discussed representation, parameter estimation and inference. Their results showed that the model improves upon one-step models, in terms of fit and out-of-sample forecasting.
Kivetz and Simonson (2000) examined the mechanisms underlying the impact of incomplete information on consumer choice. The studies included within and between subjects, tests of preference intransitivity, written explanations of choices, think-aloud protocols of choices and choice difficulty. Furthermore, buyers tend to interpret missing attribute values in a way that supports the purchase of the option that is superior on the common attribute. Findings also indicated that choosing from sets with missing information could affect buyer tastes and purchase decisions made subsequently.
Luce et al. (1999) explored whether choice patterns were sensitive to the potential of relevant trade-offs to elicit negative emotion. They have examined on how emotional trade-off difficulty may influence choice, as well as discussing on how the potential of a particular attribute to elicit emotional trade-off difficulty can be measured or manipulated.
Mattila (1998) presented a study which examined the propensity of consumers to rely on heuristic ones when making satisfaction judgements in a repeated-purchase context. They analysed the impact of mood states at the information-encoding for on-line and memory-based judgements, as well as examining whether information-processing efficiency can provide insight into the initial-judgement effect in a consumer behaviour context.
The literature indicating that person, context and task-specific factors cause consumers to utilise different decision strategies has generally failed to affect the specialisation of choice models used by practitioners and academics alike, who still tend to assume a utility maximising, omniscient, indefatigable consumer. Swait and Adamowicz (2001) introduced decision strategy selection, within a maintained compensatory framework, into aggregate choice models via latent classes, which arise because of task complexity; it demonstrates that within an experimental choice task, the model reflects changing aggregate preferences as choice complexity changes and as the task progresses.
Arora and Huber (2001) proposed aggregate customisation as an approach to improve individual estimates using a hierarchical Bayes choice model, with two simulation studies to investigate conditions that are most conducive to aggregate customisation. The simulations were validated through a field study showing that aggregate customisation results in better estimates of individual parameters and more accurate predictions of individuals’ choices.
Many individual decisions take place in a group context wherein group members voice their choices segmentally. Ariely and Levav (2000) proposed that choices reflect a balancing of two classes of goals: goals that are strictly individual and goals that are triggered by the existence of the group. They found support for goal balancing, and in one of the three studies undertaken, it was demonstrated that individual choices in a group context are also aimed at satisfying goals of information gathering and self-presentation in the form of uniqueness. However, Hamilton (2003) suggested that people are influenced by others in the selection of certain alternatives, but the degree of this influence will vary, depending on the conditions. For example, people often resist influence when they recognise that somebody is attempting to persuade them.
Prices for grocery items differ across stores and time because of promotion periods. Consumers therefore have an incentive to search for the lowest prices. However, when a product is purchased infrequently, the effort to check the price every shopping trip might outweigh the benefit of spending less. Seiler (2013) proposes a structural model for storable goods that takes into account inventory holdings and search. The model is estimated using data on laundry detergent purchases. He finds search costs play a large role in explaining purchase behaviour, with consumers unaware of the price of detergent on 70% of their shopping trips. Therefore, from the retailer’s point of view raising awareness of a promotion through advertising and displays is important. This author also finds that a promotion for a particular product increases the consumer’s incentive to search. This change in incentives leads to an increase in category traffic, which from the store manager’s perspective is a desirable side effect of the promotion.
Erdem et al. (2003) develop a model of household demand for frequently purchased consumer goods that are branded, storable and subject to stochastic price fluctuations. Their framework accounts for how inventories and expectations of future prices affect current-period purchase decisions. The authors estimate their research model using scanner data for the ketchup category. The results indicate that price expectations and the nature of the price process have important effects on demand elasticities. Long-run cross-price elasticities of demand are more than twice as great as short-run cross-price elasticities. Temporary price cuts (or “deals”) primarily generate purchase acceleration and category expansion, rather than brand switching.
Research Focus
Most individuals screen alternatives on more than one attributes, mostly in well-known characteristics of the brands rather than novel characteristics (Gilbride and Allenby 2004). From the discussion above, it is clear that individuals are influenced by the characteristics of the product/brand and the price when making purchasing decisions. Furthermore, the personal characteristics and the experience of a certain consumer in a buying situation could be of influence. These aspects of the customer behaviour are the key focus of this study. They are examined with the use of the DS/AHP.
DS/AHP introduces a number of novel measures describing the judgement-making undertaken in the consumer choice process. These measures include the notion of belief and plausibility in the results, together with the levels of conflict and non-specificity in the judgements made. These measures aid in the identification of the awareness, consideration and choice sets associated with the decision-making group. Within consumer behaviour, the belief and plausibility measures are related to additive and subtractive choice framing (Shafir 1993).
The utilisation of Dempster-Shafer (DST) in DS/AHP brings an allowance of ignorance throughout the judgement-making process, which may encapsulate the notions of incompleteness, imprecision and uncertainty (Smets 1994). An example of the incompleteness is in preference judgements not having to be made on individual DAs; this could be due to forestalling or doubt by the consumer (Lipshitz and Strauss 1997). While the antecedents of the possible presence of ignorance are not the subject of this paper, the technique does acknowledge its presence in the preference judgements made. The implication here is that a consumer may not exactly know what the reasons are for their possible non-specificity in the judgements they make.
Dempster-Shafer Theory
Central to the DS/AHP method of multi-criteria decision-making (MCDM) utilised here is the Dempster-Shafer theory of evidence (DST). The origins of DST came from the seminal work of Dempster (1968) and Shafer (1976) and considered as a generalisation of Bayesian theory that can robustly deal with incomplete and imprecise data (Shafer 1990). DST offers a number of advantages (in MCDM), including the opportunity to assign measures of belief to focal elements (groups of DAs), and allow for the attachment of belief to the frame of discernment (all DAs). Bloch (1996) presents a description of the basic principles of DST including its main advantages (see also Bryson and Mobolurin 1999).
More formally, let Θ = {h 1, h 2, …, h n } be a finite set of n hypotheses (frame of discernment). A basic probability assignment or mass value is a function m: 2Θ → [0, 1] such that m(∅) = 0, (∅—empty set) and \( \sum \limits_{x\in {2}^{\varTheta }}m(x) \) = 1 (the notation 2Θ relates to the power set of Θ). Any subset x of the frame of discernment Θ for which the mass value m(x) is non-zero is called a focal element and represents the exact belief in the proposition depicted by x. A collection of mass values is denoted a body of evidence (BOE), with m(Θ) considered the amount of ignorance (also called uncertainty) within the BOE m(⋅), since it represents the level of exact belief that cannot be discerned to any proper subsets of Θ (Bloch 1996).
Further measures of total belief can be found. A belief measure is a function Bel: 2Θ → [0, 1], and is drawn from the sum of exact beliefs associated with focal elements that are subsets of the focal element x 1 in question, defined by Bel(x 1) = \( \sum \limits_{x_2\subseteq {x}_1}m\left({x}_2\right) \) for x 1 ⊆ Θ. It represents the confidence that a proposition y lies in x 1 or any subset of x 1. Moreover, m(x 1) measures the assignment of belief exactly to x 1, with Bel(x 1) measuring the total assignment of belief to x 1 (Ducey 2001). A plausibility measure is a function Pls: 2Θ → [0, 1], defined by Pls(x 1) = \( \sum \limits_{x_2\cap {x}_1=\varnothing }m\left({x}_2\right) \) for x 1 ⊆ Θ. Clearly Pls(x 1) represents the extent to which we fail to disbelieve x 1, the total assignment which does not exclude x 1.
DST provides a method to combine different sources of evidence (BOEs), using Dempster’s rule of combination. This rule assumes that these sources are independent. Then the function [m 1 ⊕ m 2]: 2Θ → [0, 1], defined by:
is a mass value, where x 1 and x 2 are focal elements. An important feature in the denominator part of [m 1 ⊕ m 2], is \( \sum \limits_{x_1\cap {x}_2=\varnothing }{m}_1\left({x}_1\right){m}_2\left({x}_2\right) \), often denoted by k, considered representative of conflict between the independent sources of evidence. The larger the value of k the more conflict in the evidence, and less sense there is in their combination (Murphy 2000). In the limit k = 1 (complete conflict), it indicates no focal elements intersect between sources of evidence, and the combination function is undefined (Bloch 1996).
Other functions have been constructed which aim to extract further information from a BOE. For a summary discussion of these functions, see Klir and Wierman (1998). A Non-specificity measure (denoted N(⋅)) within DST was introduced by Dubois and Prade (1985), defined as N(m(⋅)) = \( \sum \limits_{x_1\in {2}^{\varTheta }}m\left({x}_1\right){\log}_2\mid {x}_1\mid \). Hence N(⋅) is considered the weighted average of the focal elements, with m(⋅) the degree of evidence focusing on x 1, while log2|x 1| indicates the lack of specificity of this evidential claim. The general range of this measure (Klir and Wierman 1998) is [0, log2|Θ|], where |Θ| is the number of DAs in the frame of discernment. Measurements such as non-specificity are viewed as species of a higher uncertainty type, encapsulated by the term ambiguity, Klir and Wierman (1998) state:
“the latter (ambiguity) is associated with any situation in which it remains unclear which of several alternatives should be accepted as the genuine one.”
Exposition of DS/AHP Method Within a Car Choice Problem
The research experiment chosen for this study was based on the conduct of a group discussion with 11 consumers—3 couples and 5 single individuals. The focus of the experiment was on their preferences to a number of different makes of cars. The car choice problem considered here is an often investigated problem and closely inset in the general study of consumer brand choice (Punj and Brookes 2001). This problem brings with it the notion of emotional decision-making (Luce et al. 1999), where familiarity with the problem and the social stereotypes are prevalent. Also the implication of brand cues, with the advertisement on the different makes of cars influential in the judgements made by a consumer (Hastak and Mitra 1996; Shapiro et al. 1997; Wedel and Pieters 2000; Sharpanskykh and Zia 2012).
The ages of the members of the decision-making group ranged from 25 to 60. The majority of the participants had a university degree and the group as a whole had a good level of education. The moderation of the group discussion was performed by both of the researchers in order to ensure a required level of investigator triangulation. A number of projective techniques were used in particular through the utilisation of pictorial information and visual aids pertaining to the subject under investigation: the formation of consumer consideration sets with regard to choice criteria utilised in car purchase decision-making.
The pairing of the stimuli focused on three analytical dyads shown to the participants in three folders (one for each dyad), containing extensive information and pictures about each car model under study, as suggested by Raffone and Wolters (2001). Each car model was labelled with a letter and the comparative dyads were designed in terms of level of consumer familiarity (Aurier et al. 2000), product diversity as well as price-quality tiers. Therefore, the first dyad to be analysed included SMART and IGNIS (a new model just launched), whereas the second grouping dealt with ALFA 156 and VOLVO S60, and, finally, the last pairing contained a “sports car” cluster—TOYOTA MR2 and BMW 3. The setting of these research stimuli was also designed to manipulate brand name valence as well as testing the subjects’ processing task. Furthermore, the selected research design rested upon the notion that buyers have category specifics based on “mentally defined” price-quality tiers, following the experiment of Gobet and Simon (1998a) and Verwey (2003). The five criteria selected for analysis of consumers’ decision-making with regard to car purchase were comfort, economy, performance, price and safety.
Time was spent introducing DS/AHP to the participants (consumers), including the types of judgement-making required (weight allocation). After having analysed all the provided information for the dyads for a considerable period of time, a very short research instrument was applied in order to gauge and quantify their perceptions related to choice criteria leading to the potential formation of consideration sets. The rest of this section exposits the DS/AHP analysis on the judgements made by the 11 consumers. Firstly, this includes an elucidation of the judgements made by a single consumer and the construction of the subsequent results describing the choice process in identifying the best car (or cars).
Each consumer was allowed to control the level of judgement making, to what they felt confident to undertake (Chase and Simon 1973). The participants were informed that the levels of preference for each criterion analysed should be considered in relation to all the available cars known to the respondents. No cars were allowed to appear in more than one group identified over a single criterion, and not all cars needed to have judgements made on them. Within the DS/AHP analysis of the car choice problem, the six cars SMART, IGNIS, ALFA 156, VOLVO S60, TOYOTA MR2 and BMW 3 considered are labelled A, B, C, D, E and F, respectively, collectively defined the frame of discernment Θ. The judgements made from one individual consumer (labelled DM1) are reported in Fig. 10.1.

Hierarchy of DS/AHP model of judgements on best car made by DM1
In Fig. 10.1, a hierarchical structure (as in AHP) is used to present the judgements made by DM1. Moving down from the focus “best car” to the identified groups of DAs over each criterion, there are two different sets of judgements made by DM1. Firstly, there is the set of criterion priority values (CPVs); these indicate the level of importance or perceived knowledge a consumer has towards the criteria.
In this study the participants were asked to allocate a weight of between 0 and 100 towards each criterion based on their perceived importance, which are then normalised, so they sum to unity (Beynon 2002). If a participant decided to assign a value of 0 to any criterion, then he/she was not required to make judgements for that criterion on the cars considered. Normalising the weights shown in Fig. 10.1, the CPVs (from DM1) for the criteria, comfort (p 1,C), economy (p 1,E), performance (p 1,PE), price (p 1,PR) and safety (p 1,S) are 0.2449, 0.1429, 0.2449, 0.1224 and 0.2449, respectively. With the CPV assigned for each criterion, it is required for DM1 to make preference judgements towards groups of cars on those criteria with positive CPVs.
For each criterion, a number of groups of cars are identified and assigned a (positive) preference scale value (Fig. 10.1). In this paper a seven-unit scale is used (integer values 2, 3, …, 8), to allow a consumer to discern levels of preference between groups of cars identified (ranging from “moderately preferred” to “extremely preferred”). This positively skewed measurement-scaling procedure was tailored to the prerequisites of DS/AHP and is in line with the well-known work of Miller (1956) and Beynon (2002). Table 10.1 reports a presentation of the relative meaning of the verbal statements to the associated numerical values (with certain verbal statements not given).
In Table 10.1, the numeric values from two to eight indicate from the associated verbal statements an increase in the level of preference on groups of cars. For example, in the case of the price criterion, the group of cars {B, D} has been assigned the numerical scale value 5. This indicates the group of cars {B, D} has been identified by DM1 as strongly preferred when compared to the whole set of cars considered (frame of discernment Θ) with respect to the price criterion. This approach to preference judgement making, to a frame of reference is not uncommon (Lootsma 1993). Beynon (2002) showed that for a single criterion, if a list of d focal elements (groups of cars) s 1, s 2, …, s d is identified and assigned with the scale values of a 1, a 2, …, a d , respectively, defining m(⋅) as the relevant mass values making up the criterion BOE for the specific criterion, then
where Θ is the frame of discernment and p is the associated CPV. The measure m(Θ) is defined the level of local ignorance here, since it is the value assigned to Θ, based on the judgements towards a single criterion only. Furthermore, these belief values were found without direct comparison between identified groups of DAs. This relates to the incompleteness in judgements, which is acknowledged and incumbent in the concomitant ignorance.
Results
With respect to the “best car” problem, defining m 1,C(⋅) as the criterion BOE for the judgements made by DM1 on the comfort criterion, from Fig. 10.1, s 1 = {A, B}, s 2 = {C}, s 3 = {D, E} and s 4 = {F} with a 1 = 3, a 2 = 4, a 3 = 6 and a 4 = 8, respectively. For a general CPV p 1,C, then
These mass values are dependent only on the value p 1,C, for the comfort criterion p 1,C = 0.2449, hence m 1,C({A, B}) = 0.1029, m 1,C({C}) = 0.1371, m 1,C({D, E}) = 0.2057, m 1,C({F}) = 0.2743 and m 1,C(Θ) = 0.2800. Using the more general values of m 1,C(⋅), Fig. 10.2a illustrates the effect of the CPV p 1,C on the comfort BOE (also shown in Fig. 10.2b is the respective graphs for the price criterion BOE defined m 1,PR(⋅) with associated CPV p 1,PR).

BOE m 1,C(⋅) and m 1,PR(⋅) values as p 1,C and p 1,PR go from 0 to 1
In Fig. 10.2a, as p 1,C tends to 0 (little importance), more belief value would be assigned to the associated local ignorance m 1,C(Θ) and less to the identified groups of cars. The reciprocal is true, as p 1,C tends to 1 when there is perceived importance on the comfort criterion so the level of local ignorance decreases. The values of m 1,C(⋅) for when p 1,C = 0.2449 are also confirmed in Fig. 10.2a. In Fig. 10.2b a similar set of graphs are constructed for the mass values making up the BOE of the price criterion (with general CPV p 1,PR). The graphs representing the m 1,PR(⋅) values for the identified groups of cars in Fig. 10.2b are closer together than in Fig. 10.2a. Inspection of the judgements made by DM1 in Fig. 10.1 elucidates the range of scale values used on the comfort criterion is larger than those scale values used on the price criterion. For the price criterion with p 1,PR = 0.1224, then m 1,PR({A}) = 0.1890, m 1,PR({E, F}) = 0.1654, m 1,PR({C}) = 0.1417, m 1,PR({B, D}) = 0.1181 and m 1,PR(Θ) = 0.3858, as shown in Fig. 10.2b.
Criterion BOE can be found for the other three criteria, economy, m 1,E(⋅); performance, m 1,PE(⋅); and safety, m 1,S(⋅), based on the judgements made by DM1 shown in Fig. 10.1 (using their respective CPV: p 1,E = 0.1429, p 1,PE = 0.2449 and p 1,S = 0.2449):
- Economy::
-
m 1,E({A}) = 0.1944, m 1,E({C, E}) = 0.1111, m 1,E({D}) = 0.1389, m 1,E({F}) = 0.1667 and m 1,E(Θ) = 0.3888.
- Performance::
-
m 1,PE({A}) = 0.0736, m 1,PE({C}) = 0.2209, m 1,PE({D}) = 0.1472, m 1,PE({E, F}) = 0.2577 and m 1,PE(Θ) = 0.3000.
- Safety::
-
m 1,S({A}) = 0.0554, m 1,S({C}) = 0.1107, m 1,S({D}) = 0.2214, m 1,S({E}) = 0.1661, m 1,S({F}) = 0.1937 and m 1,S(Θ) = 0.2527.
The goal for DM1 is to consolidate their evidence on the best car to choose, based on all the criteria considered. Using DS/AHP, this necessitates the combining of the associated criterion BOE using Dempster’s combination rule presented in section “Evaluation and Choice”. In Table 10.2, the intermediate values from the combination of the two criterion BOEs, comfort m 1,C(⋅) and price m 1,PR(⋅), are reported. That is, from Dempster’s combination rule the combination is made up of the intersection and multiplication of focal elements and mass values, respectively, from the two different criteria BOE considered.
To illustrate, for the individual mass value m 1,C({A, B}) = 0.1029 and m 1,PR({A}) = 0.1890 from the comfort and price criterion BOE respectively, their combination results in a focal element {A, B} ∩ {A} = {A} with a value 0.1029 × 0.1890 = 0.0194. The ∅ present in Table 10.2 is the empty set and the sum of these values (in italics) represents the level of associated conflict (see k definition in section “Dempster-Shafer Theory”) in the combination of these two criterion BOE, in this case k = 0.2875. The final mass value constructed for a particular focal element is illustrated for the {A} focal element, which is given by:
To re-iterate, Dempster’s rule of combination is used to aggregate the evidence from a consumer’s judgements on the five different criteria considered. Defining m 1,CAR(⋅) as the post-combination consumer BOE from all the criterion BOEs for DM1, its associated focal elements (groups of cars) and mass values are reported in Table 10.3.
In Table 10.3, 12 groups of cars (focal elements including Θ) and mass value, making up the consumer BOE for DM1. To illustrate, the focal element m 1,CAR({B, D}) = 0.0084, implies the exact belief in the group of cars {B, D} including the best car from the combined evidence is 0.0084. Furthermore, the level of ignorance m 1,CAR(Θ) = 0.0276, from the combination of all the judgements of DM1 towards their choice of best car. To consider total beliefs to groups of cars, the belief (Bel) and plausibility (Pls) functions utilised on m 1,CAR(⋅) associated with DM1. Rather than present the belief and plausibility values for each possible subgroup of cars considered (62 in number) a specific reduced number are described. Moreover, Table 10.4 reports those groups of cars that have the largest belief and plausibility values from all those groups of cars of the same size.
To illustrate the results in Table 10.4, considering all groups of cars made up of three cars, those with the largest belief and plausibility values are {D, E, F} in both cases, with Bel({D, E, F}) = 0.7080 and with Pls({D, E, F}) = 0.7519. These values are calculated from the information reported in Table 10.3 and are constructed as shown below:
and
The results in Table 10.4 highlight the use of DS/AHP to identify a reduced number of cars to possibly further consider. For the “best car” problem here, if considering finding only the single best car, the measures of belief and plausibility both indicate the car F (BMW 3) is best, based on all the judgements from DM1. This discussion and results in Table 10.4 illustrate the possible role of DS/AHP as a method to identify choice sets from consideration and/or awareness sets (see section “Dempster-Shafer Theory” for further discussion).
To offer information on the homogeneity and intensity of the consumer’s choice process, the conflict levels between the judgements made by DM1 over the different criteria can be calculated (see Table 10.5). With respect to DS/AHP, the level of conflict relates to how different the judgements made are over the different criteria (see section “Evaluation and Choice”).
In Table 10.5, the higher the conflict value (within the domain [0, 1]), the more conflict there exists between the criteria. The most conflict evident is between the comfort and safety criteria (with k = 0.3844). From section “Evaluation and Choice”, since the conflict levels are relatively low between criteria, it strengthens the validity of the results found from the combination of the five criterion BOEs to produce the consumer BOE.
A further measure defined in section “Evaluation and Choice” is non-specificity; here it relates to the level of grouping apparent in the groups of cars identified for preference by DM1 over the different criteria. From section “Evaluation and Choice”, with six cars considered, the domain on the level of non-specificity is [0, 2.5850]. In Table 10.6, the levels of non-specificity on the judgements made by DM1 over the five criterion BOEs and the final consumer BOE are reported.
From Table 10.6, the largest and least levels of non-specificity amongst the criterion BOE are associated with the price (1.2808) and safety (0.6532) criteria respectively. To illustrate the calculation of these non-specificity values (N(⋅)), for the price criterion:
A comparison between the judgements made on the price and safety (and other) criteria (given in Fig. 10.1) shows the price criterion includes two groups of cars identified with two cars in each, whereas only singleton groups of cars are identified with the safety criterion. Following the premise that information chunk boundaries have psychological reality (Gobet and Simon 1998a). One further important factor is the value of the associated CPV, since with a low CPV more mass value is assigned to Θ, hence a higher non-specificity value. The non-specificity of the consumer BOE \( {m}_{1, CAR}\left(\cdot \right),N\left({m}_{1, CAR}\left(\cdot \right)\right) \) = 0.1596, is lower than the non-specificity levels for the individual criterion BOE. This is a direct consequence of the utilisation of Dempster’s combination rule, which apportions mass values to smaller groups of cars through the intersection of groups of cars from the different criterion BOE (see Table 10.2).
To set against the analysis on DM1 so far described, a further series of results are briefly reported based on the judgements of a second consumer (labelled DM2), see Fig. 10.3.

Best car judgements over the five criteria from DM2
DM2s’ judgements are considerably less specific than those with DM1 (see Figs. 10.1 and 10.3), with larger-sized groups of cars were identified by DM2 over the five criteria. Incidentally the judgements made by DM2 are consistent with the dyad grouping of the cars presented to the consumers. With the cars grouped by {A, B}, {C, D} and {E, F} suggesting a level of brand name valence by this consumer, their judgements exhibit influence by the price-quality tiers of the three dyad groups of cars, reinforcing the notion of flat chunk organisation and its relation to retrieval structures. As with DM1, the criterion BOE graphs for the comfort and price criteria for DM2 are reported in Fig. 10.4.

BOE m 2,C(⋅) and m 2,PR(⋅) mass values as p 2,C and p 2,PR go from 0 to 1
Comparing the results reported in Figs. 10.2 and 10.4, the separation between the m 2,C({E, F}) and m 2,C({A, B, C, D}) lines in Fig. 10.4a is a consequence of the large difference between the scale values 3 and 7 assigned to the two groups of cars {A, B, C, D} and {E, F}, respectively. The non-specificity levels on the criterion BOEs for DM2 are reported in Table 10.7 and exhibit consistently higher values than those associated with DM1 (see Table 10.6). This is a consequence of the larger-sized groups of cars identified across all the criteria by DM2. A further consequence of the less specific judgements made is the non-specificity of consumer BOE for DM2 (1.1368) is considerably larger than that for DM1 (0.1596).
While the views of the individual consumers are of interest, the combination of the evidence from the eleven consumers would offer information on the overall levels of belief towards the identification of the best car(s) from the six cars considered over the five criteria. That is, the combination of all the consumer BOEs from the 11 consumers enables a novel approach to the evaluation of results from group decision-making with DS/AHP. This is undertaken by the utilisation of Dempster’s combination rule described in section “Evaluation and Choice”. For brevity we do not present the final group BOE from all consumers; instead the best groups of cars of different sizes based on the belief and plausibility measures are reported in Table 10.8.
From Table 10.8, irrespective of whether belief and plausibility measures are considered, the same group of cars is identified for each specific size of group. The best single car is identified as the car D (VOLVO S60), if a choice set of say three cars was considered, then the group of cars {C, D, F} should be chosen. The results in Table 10.8 exhibit the possible consideration or choice sets that the consumers could further consider (see section “Dempster-Shafer Theory” for further discussion).
At each stage of the DS/AHP analysis certain BOE are constructed and can be combined in a number of different ways to allow further understanding of the prevalent judgements made. For example, each consumer BOE was found from the combination of criterion BOEs, and the group BOE found from the combination of the consumer BOEs. To gauge a measure on the judgements made specifically over the different criteria, the criterion BOEs associated with a single criterion from the 11 consumers can be combined. The result is five BOEs. Table 10.9 reports their concomitant levels of non-specificity.
An inspection of the results in Table 10.9 shows the criterion with overall least and largest levels of non-specificity in the judgements made are safety (0.0510) and economy (0.3215), respectively. This result is interesting in that overall safety was judged on most discernibly in terms of both the grouping of cars under this criterion and the level of CPV each consumer assigned to it, whereas the economy criterion was most non-specific. This could be a direct consequence of the information made available to the consumers not including all that was necessary for them to make more specific judgements. The combined judgements of the 11 consumers over the different criteria are next exposited in Table 10.10. That is, for each criterion using the defined combined BOE, the different-sized groups of cars with highest belief and plausibility values (not given) are shown.
From Table 10.10, in terms of a single best car to identify, three of the five criteria (comfort, economy and safety) all suggest the car D as best choice of car. With cars F and A identified as best from the criteria performance and price respectively (based on belief or plausibility values). The results from the price criterion are interesting and also in some way different to those from the other criteria. That is (considering only the belief value), the best two cars to consider under the price criterion are A and B—the cheapest two of the six cars considered. Also (for the price criterion) the best four cars to further consider are A, B, C and D, the cheapest four of the six cars. The reader is reminded the six cars considered were presented to the consumers in the dyad groups {A, B}, {C, D} and {E, F} based primarily on their prices.
The results presented here show the individual consumers generally followed this dyadic grouping. This highlights the effect of brand cues, which in this case were in the form of the folders containing extensive information and pictures about each car. Indeed, with the price clearly included in the cue information, the results on the price criterion indicate the consumers have exhibited “mentally defined” price-quality tiers during their judgement making. This finding is supported by the research study conducted by Mehta et al. (2003).
Interpretation of DS/AHP as an Analysis Tool in Consumer Choice MCDM
A DS/AHP analysis was undertaken on a car choice problem. Throughout, the judgements made and results considered have been with respect to groups of cars. This places the notion of consideration sets as a fundamental tool in DS/AHP. The allowance of a consumer to discern groups of cars does place the control in the level of judgement making squarely with the consumer. This is strengthened with the allowance to not include in their judgements all cars present over particular criteria. Importantly on a criterion, these cars are not simply ignored, but included with all the other cars and a value assigned to them, represented by local ignorance. The criteria priority values representing the level of knowledge (or importance) of the criteria enable a consumer to indicate no knowledge on a criterion and hence requiring no further judgements on this criterion (Aurier et al. 2000).
The results from the DS/AHP analysis is in the form of a BOE (Racioppi et al. 2015; Beynon 2006; Han et al. 2013) which enables the identification of a single best car or best group of cars of a certain size (number of cars). This identification is based on the two measures, belief and plausibility. While relatively novel to consumer choice theory, they do attempt to elucidate different approaches to the identification of best groups of cars (consideration sets). The belief function represents the confidence that the best car does exist in the group of cars it describes. Whereas the plausibility function represents the extent to which we fail to disbelieve the best car does exist in the group of cars the value describes. These two functions have connection with the consumer choice process as suggested in Park et al. (2000), whose title included the phrase “choosing what I want versus rejecting what I do not want” (Chakravarti and Janiszewski 2003; Sharpanskykh and Zia 2012). Indeed, a decision on the choice of whether to utilise the belief or plausibility values may came from whether the consumer has undertaken their judgements in a subtractive or additive option framing (Shafir 1993).
Within the area of consideration sets, the ability to find the levels of belief or plausibility on groups of cars could aid in the elucidation of groups of cars representing a consumer’s awareness, consideration and choice sets. That is, from investigating the changes in the largest levels of belief and plausibility on groups of cars of different sizes, this evidence can suggest the sizes and content of groups of cars associated with the varying consideration sets. To illustrate, for DM1 whose judgements were elucidated in section “Research Focus”, Fig. 10.5 reports the results from Table 10.4 in a form to elucidate the level of change in belief and plausibility values between best groups of cars of different sizes.

Visual representation of the groups of cars with largest levels of Bel and Pls
In Fig. 10.5, the relative change in the levels of (largest) belief or plausibility to groups of cars of different sizes is clearly exposited. A notional attempt in Fig. 10.5 is given to the understanding of the effect of the belief and plausibility values in elucidating the possible awareness, consideration and choice sets. That is, the shaded regions relate to bounds on levels of belief or plausibility, which may discern groups of cars into awareness, consideration and choice sets. In general, as the levels of these measures increase so more cars are included in each of the best groups of cars identified. In this case, in Fig. 10.5, two (notional) bounds are utilised; these are between awareness and consideration sets with a boundary value 0.9 and between consideration and choice sets with a boundary value 0.55.
With these boundary values, the group of objects immediately below the boundary values is of particular importance. Also with this convention defined here, the awareness set is the group of all cars considered in the problem, the frame of discernment Θ. It follows, considering only the belief values, the group of cars {C, D, E, F} is the first group of cars with a belief value below the awareness and consideration sets boundary value of 0.9 (Bel({C, D, E, F}) = 0.8606) and is then defined the consideration set. To explain this result from the view of the judgements made by DM1, the two cars not included in this identified consideration set are A and B, which from Fig. 10.1 overall were the two cars given the least amount of preference judgement on them. This may be due to non-inclusion in many identified groups (in the case of car B) or on the generally low levels of preference assigned to them (in the case of car A, with the exception of the price criterion). Using the plausibility value the group of cars {C, D, E, F} with Pls({C, D, E, F}) = 0.8966 would also be considered the concomitant consideration set.
A similar argument follows for the boundary between the regions describing the consideration and choice sets (Gobet and Simon 1998b). From Fig. 10.5, for the belief value, the group of objects {E, F} would be identified (Bel({E, F}) = 0.5070) as the choice set since its level of belief is the largest below the 0.55 boundary value employed here. In this case, based on the plausibility value the group of cars {F} would be identified as the choice set, which is different from (included in) the choice set based on the belief value. As a general rule, if the same boundary values were used for belief and plausibility levels then the number of cars in a plausibility-based best group of cars is less than or equal to the number of cars in a group based on the belief value.
Due to the novelty of the method employed here, the boundary values utilised are notional. In the future with the application of this method increasing, a fuller understanding on the boundary values to consider would be apparent. However, this would depend on the number of cars in the awareness set and so on.
Conclusions
Understanding how consumers choose specific brands is critical for companies, especially when the available number of brands competing with one another is large. This paper has utilised a nascent approach to multi-criteria decision-making, namely, DS/AHP in the area of consumer choice. The paper has attempted to convey a more realistic approach for the individual consumer to undertake the required judgement-making process. Importantly, the DS/AHP method allows the consumer to control the intensity of the judgement making they perform. The results (intermediate and final) elucidate a plethora of information for the consumer choice problem to be gauged on.
The central element in the DS/AHP analysis is the body of evidence (BOE), with certain BOE constructed at different stages in the analysis, then a number of different sets of results can be found. The descriptive measures conflict and non-specificity allow a novel insight into the judgement making by the individual members of a decision-making group. Further analysis could include the investigation of the levels of conflict between the individual members of the group and looking into the possible identification of subgroups of a group with the most similar series of judgements.
Allowance exists for each consumer to assign levels of positive preference to groups of cars. The results also included information on groups of cars; hence the notion of consideration sets is firmly implanted in the fundamentals of DS/AHP. Moreover, the idea of consideration sets is exhibited in the judgement-making opportunities of the consumer and in the interpretation of the final results. A notional approach to the identification of awareness, consideration and choice sets is described, based on the levels of belief and plausibility in the best car existing in a group of cars, which could be compared with the algorithm developed by Gensch and Soofi (1995).
It is hoped this first DS/AHP analysis in a consumer choice problem, has shown it to be a novel and lucrative method of analysis. Its ability to allow the decision-maker to make judgements to the level of their ability as well as offer results that can identify a number of different aspects of the whole decision-making process.
References
Allenby, G. M., & Ginter, J. L. (1995). The Effects of In-store Displays and Feature Advertising on Consideration Sets. International Journal of Research in Marketing, 12, 67–80.
Analytis, P., Kothiyal, A., & Katsikopoulos, K. (2014). Multi-Attribute Utility Models as Cognitive Search Engines. Judgment and Decision making, 9(5), 403–419.
Ariely, D., & Levav, J. (2000). Sequential Choice in Group Settings: Taking the Road Less Travelled and Less Enjoyed. Journal of Consumer Research, 27(3), 279–290.
Arora, N., & Huber, J. (2001). Improving Parameter Estimates and Model Prediction by Aggregate Customization in Choice Experiments. Journal of Consumer Research, 28(2), 273–283.
Aurier, P., Jean, S., & Zaichkowsky, J. L. (2000). Consideration Set Size and Familiarity with Usage Context. Advances in Consumer Research, 27, 307–313.
Beaman, C. P. (2013). Inferring the Biggest and Best: A Measurement Model for Applying Recognition to Evoke Consideration Sets and Judge Between Multiple Alternatives. Cognitive Systems Research, 24, 18–25.
Benitez, J., Delgado-G, X., Izquierdo, J., & Pérez-G, R. (2015). Consistent Completion of Incomplete Judgments in Decision Making Using AHP. Journal of Computational and Applied Mathematics, 290, 412–422.
Beynon, M. (2002). DS/AHP Method: A Mathematical Analysis, Including an Understanding of Uncertainty. European Journal of Operational Research, 140(1), 149–165.
Beynon, M. J. (2006). The Role of the DS/AHP in Identifying Inter-Group Alliances and Majority Rule Within Group Decision Making. Group Decision and Negotiation, 15(1), 21–42.
Beynon, M. J., Curry, B., & Morgan, P. H. (2000). The Dempster-Shafer Theory of Evidence: An Alternative Approach to Multicriteria Decision Modelling. Omega, 28(1), 37–50.
Bloch, B. (1996). Some Aspects of Dempster-Shafer Evidence Theory for Classification of Multi-Modality Images Taking Partial Volume Effect into Account. Pattern Recognition Letters, 17, 905–919.
Brown, C. L., & Carpenter, G. S. (2000). Why Is the Trivial Important? A Reasons-Based Account for the Effects of Trivial Attributes on Choice. Journal of Consumer Research, 26(4), 372–385.
Bryson, N., & Mobolurin, A. (1999). A Process for Generating Quantitative Belief Functions. European Journal of Operational Research, 115(3), 624–633.
Butler, L. T., & Berry, D. C. (2001). Transfer Effects in Implicit Memory and Consumer Choice. Applied Cognitive Psychology, 15(6), 587–601.
Carson, R., & Louviere, J. (2014). Statistical Properties of Consideration Sets. Journal of Choice Modelling, 13, 37–48.
Chakravarti, A., & Janiszewski, C. (2003). The Influence of Macro-Level Motives on Consideration Set Composition in Novel Purchase Situations. Journal of Consumer Research, 30(September), 244–258.
Chase, W. G., & Simon, H. K. (1973). Perception in Chess. Cognitive Psychology, 4, 55–81.
Cherenev, A., & Carpenter, G. S. (2001). The Role of Market Efficiency Intuitions in Consumer Choice: A Case of Compensatory Inferences. Journal of Marketing Research, 38(3), 349–361.
Chiang, J., Chib, S., & Narasimhan, C. (1998). Markov Chain Monte Carlo and Models of Consideration Set and Parameter Heterogeneity. Journal of Econometrics, 89(1–2), 223–248.
Dede, G., Kamalakis, T., & Sphicopoulos, T. (2016). Theoretical Estimation of the Probability of Weight Rank Reversal in Pairwise Comparisons. European Journal of Operational Research, 252(2), 587–600.
Dempster, A. P. (1968). A Generalization of Bayesian Inference (with Discussion). Journal of the Royal Statistical Society. Series B, 30(2), 205–247.
Desai, K. K., & Hoyer, W. D. (2000). Descriptive Characteristics of Memory-Based Consideration Sets: Influence of Usage Occasion Frequency and Sage Location Familiarity. Journal of Consumer Research, 27(3), 309–323.
Diehl, K. (2004,August). When Two Rights Make a Wrong: Searching Too Much in Ordered Environments. Journal of Marketing Research, XLII, 213–322.
Dubois, D., & Prade, H. (1985). A Note on Measures of Specificity for Fuzzy Sets. International Journal of General Systems, 10(4), 279–283.
Ducey, M. J. (2001). Representing Uncertainty in Silvicultural Decisions: An Application of the Dempster-Shafer Theory of Evidence. Forest Ecology and Management, 150, 199–211.
Eliaz, K., & Spiegler, R. (2011). Consideration Sets and Competitive Marketing. Review of Economic Studies, 78(1), 235–262.
Erdem, T., Imai, S., & Keane, M. P. (2003). Brand and Quantity Choice Dynamics Under Price Uncertainty. Quantitative Marketing and Economics, 1(1 March), 5–64.
Gensch, D. H., & Soofi, E. S. (1995). Information-Theoretic Estimation of Consideration Sets. International Journal of Research in Marketing, 12, 25–38.
Gilbride, T., & Allenby, G. (2004). A Choice Model with Conjunctive, Disjunctive, and Compensatory Screening Rules. Marketing Science, 23(3), 391–406.
Gobet, F., & Simon, H. A. (1998a). Expert Chess Memory: Revisiting the Chunking Hypothesis. Memory, 6(3), 225–255.
Gobet, F., & Simon, H. A. (1998b). Pattern Recognition Makes Search Possible: Comments on Holding (1992). Psychological Research, 61(3), 204–209.
Goodman, J., Broniarczyk, S., Griffin, J., & McAlister, L. (2013). Help or Hinder? When Recommendation Signage Expands Consideration Sets and Heightens Decision Difficulty. Journal of Consumer Psychology, 23(2), 165–174.
Guest, D., Estes, Z., Gibbert, M., & Mazunrsky, D. (2016). Brand Suicide? Memory and Linking of Negative Brand Names. PloS One, 11(3), e0151628.
Hamilton, R. (2003). Why Do People Suggest What They Don Not Want? Using Context Effects to Influence Others’ Choices. Journal of Consumer Research, 29, 492–506.
Han, D., Han, C., & Deng, Y. (2013). Novel Approaches for the Transformation of Fuzzy Membership Function into Basic Probability Assignment Based on Uncertainty Optimization. International Journal of Uncertainty Fuzziness and Knowledge-Based Systems, 21(2), 289–322.
Hastak, M., & Mitra, A. (1996). Facilitating and Inhibiting Effects of Brand Cues on Recall, Consideration Set and Choice. Journal of Business Research, 37(2), 121–127.
Hauser, J. R., & Wernerfelt, B. (1990). An Evaluation Cost Model of Evoked Sets. Journal of Consumer Research, 16(March), 383–408.
Hauser, J., Toubia, O., Evgeniou, T., Befurt, R., & Dzyaburra, D. (2010). Disjunctions of Conjunctions, Cognitive Simplicity, and Consideration Sets. Journal of Marketing Research, 47(3), 485–496.
Hogarth, R. M. (1980). Judgement and Choice (2nd ed.). New York: Wiley.
Horowitz, J. L., & Louviere, J. J. (1995). What Is the Role of Consideration Sets in Choice Modeling? International Journal of Research in Marketing, 12(1), 39–54.
Jeongwen, C., & Chib, S. (1999). Markov Chain, Monte Carlo and Models of Consideration Set and Parameter Heterogeneity. Journal of Econometrics, 89(1/2), 223–249.
Johnson, M. D., & Lehmann, D. R. (1997). Consumer Experiences and Consideration Sets for Brands and Product Categories. Advances in Consumer Research, 24, 295–301.
Kivetz, R., & Simonson, I. (2000). The Effects of Incomplete Information on Consumer Choice. Journal of Marketing Research, 37(4), 427–448.
Klir, G. J., & Wierman, M. J. (1998). Uncertainty-Based Information: Elements of Generalized Information Theory. Heidelberg: Physica-Verlag.
Lapersonne, E., Laurent, G., & Le Goff, J.-J. (1995). Consideration Sets of Size One: An Empirical Investigation of Automobile Purchases. International Journal of Research in Marketing, 12(1), 55–66.
Laroche, M., Kim, C., & Marsui, T. (2003). Which Decision Heuristivs Are Used in Consideration Set Formation? Journal of Consumer Marketing, 20(3), 192–209.
Lipshitz, R., & Strauss, O. (1997). Coping with Uncertainty: A Naturalistic Decision-Making Analysis. Organisational Behaviour and Human Decision Processes, 69(2), 149–163.
Lock, A. R., & Thomas, H. (1979). Appraisal of Multi-Attribute Utility Models in Marketing. European Journal of Marketing, 13(5), 294–307.
Lootsma, F. A. (1993). Scale Sensitivity in the Multiplicative AHP and SMART. Journal of Multi-Criteria Decision Analysis, 2, 87–110.
Luce, M. F., Payne, J. W., & Bettman, J. R. (1999). Emotional Trade-off Difficulty and Choice. Journal of Marketing Research, 36(2), 143–159.
Maheswaran, D., Mackie, D. M., & Chaiken, S. (1992). Brand Name as a Heuristic Cue: The Effects of Task Importance and Expectancy Confirmation on Consumer Judgments. Journal of Consumer Psychology, 1(4), 317–336.
Manrai, A. K. (1995). Mathematical Models of Brand Choice Behaviour. European Journal of Operational Research, 82, 1–17.
Mattila, A. (1998). An Examination of Consumers’ Use of Heuristic Cues in Making Satisfaction Judgments. Psychology and Marketing, 15(5), 477–501.
Mehta, N., Rajiv, S., & Srinivasan, K. (2003). Price Uncertainty and Consumer Search: A Structural Model of Consideration Set Formation. Marketing Science, 22(1), 58–84.
Miller, G. A. (1956). The Magical Number Seven, Plus or Minus Two: Some Limits on Our Capacity for Processing Information. The Psychological Review, 63, 81–97.
Mitra, A. (1995). Advertising and the Stability of Consideration Sets Over Multiple Purchase Occasions. International Journal of Research in Marketing, 12(1), 81–94.
Murphy, C. K. (2000). Combining Belief Functions When Evidence Conflicts. Decision Support Systems, 29, 1–9.
Nowlis, S. M., & Simonson, I. (2000). Sales Promotions and the Choice Context as Competing Influences on Consumer Decision Making. Journal of Consumer Psychology, 9(1), 1–16.
Park, C., & Lessig, V. P. (1981). Familiarity and Its Impact on Consumer Decision Biases and Heuristics. Journal of Consumer Research, 8(12), 223–331.
Park, C. W., Jun, S. Y., & MacInnis, D. J. (2000). Choosing What I Want Versus Rejecting What I Do Not Want: An Application of Decision Framing to Product Option Choice Decisions. Journal of Marketing Research, XXXVII, 187–202.
Park, D., Kim, Y., Um, M. J., & Choi, S. U. (2015). Robust Priority for Strategic Environmental Assessment with Incomplete Information Using Multi-Criteria Decision Making Analysis. Sustainability, 7(8), 10233–10249.
Pires, T. (2016, September). Costly Search and Consideration Sets in Storable Goods Markets. Quantitative Marketing and Economics, 14(3), 157–193.
Prabhaker, P. R., & Sauer, P. (1994). Hierarchical Heuristics in Evaluation of Competitive Brands Based on Multiple Cues. Psychology and Marketing, 11(3), 217–235.
Punj, G., & Brookes, R. (2001). Decision Constraints and Consideration-Set Formation in Consumer Durables. Psychology and Marketing, 18(8), 843–863.
Punj, G., & Brookes, R. (2002). The Influence of Pre-decisional Constraints on Information Search and Consideration Set Formation in New Automobile Purchases. International Journal of Research in Marketing, 19, 383–400.
Racioppi, V., Marcarelli, G., & Squillante, M. (2015). Modelling a Sustainable Requalification Problem by Analytic Hierarchy Process. Quality and Quantity, 49(4), 1661–1677.
Raffone, A., & Wolters, G. (2001). A Cortical Mechanism for Binding in Visual Working Memory. Journal of Cognitive Neuroscience, 13(6), 766–785.
Roberts, J. H., & Lattin, J. M. (1997). Consideration: Review of Research and Prospects for Future Insights. Journal of Marketing Research, XXXIV, 406–410.
Roberts, J., & Nedungadi, P. (1995). Studying Consideration in the Consumer Decision Process: Progress and Challenges. International Journal of Research in Marketing, 12, 3–7.
Saaty, T. L. (1977). A Scaling Method for Priorities in Hierarchical Structures. Journal of Mathematical Psychology, 15, 59–62.
Seiler, S. (2013, June). The Impact of Search Costs on Consumer Behavior: A Dynamic Approach. Quantitative Marketing and Economics, 11(2), 155–203.
Shafer, G. (1976). A Mathematical Theory of Evidence. Princeton: Princeton University Press.
Shafer, G. (1990). Perspectives in the Theory of Belief Functions. International Journal of Approximate Reasoning, 4, 323–362.
Shafir, E. (1993). Choosing Versus Rejecting: Why Some Options are Better and Worse Than Others. Memory and Cognition, 21(4), 546–556.
Shapiro, S., MacInnis, D. J., & Heckler, S. E. (1997). The Effects of Incidental ad Exposure on the Formation of Consideration Sets. Journal of Consumer Research, 24(1), 94–104.
Sharpanskykh, A., & Zia, K. (2012). Emotional Decision Making in Large Crowds. In Y. Demazeau, J. Müller, J. Rodríguez, & J. Pérez (Eds.), Advances on Practical Applications of Agents and Multi-Agent Systems (pp. 191–200). Heidelberg: Springer.
Simon, H. A. (1955). A Behavioral Model of Rational Choice. Quarterly Journal of Economics, 69(1), 99–118.
Smets, P. (1994). What Is Dempster-Shafer’s Model? In R. R. Yager, M. Fedrizzi, & J. Kacprzyk (Eds.), Advances in the Dempster-Shafer Theory of Evidence (pp. 5–34). New York: Wiley.
Swait, J., & Adamowicz, W. (2001). The Influence of Task Complexity on Consumer Choice: A Latent Class Model of Decision Strategy Switching. Journal of Consumer Research, 28(1), 135–148.
Taroun, A., & Yang, J.-B. (2013). A DST-Based Approach for Construction Project Risk Analysis. Journal of the Operational Research Society, 64(8), 1221–1230.
Verwey, W. B. (2003). Effect of Sequence Length on the Execution of Familiar Keying Sequences: Lasting Segmentation and Preparation? Journal of Motor Behavior, 35(4), 343–354.
Verwey, W., Groen, E., & Wright, D. (2016). The Stuff that Motor Chunks Are Made of: Spatial Instead of Motor Representations? Experimental Brain Research, 234(2), 353–366.
Vroomen, B., van Nierop, E., & Franses, P. H. (2003). Modeling Consideration Sets and Brand Choice Using Artificial Neural Networks. European Journal of Operational Research, 154, 206–217.
Wang, J., Hu, Y., Xiao, F., Deng, X., & Deng, Y. (2016). A Novel Method to Use Fuzzy Soft Sets in Decision Making Based on Ambiguity Measure and Dempster-Shafer Theory of Evidence: An Application in Medical Diagnosis. Artificial Intelligence in Medicine, 69, 1–11.
Wedel, M., & Pieters, R. (2000). Eye Fixations on Advertisements and Memory for Brands: A Model and Findings. Marketing Science, 19(4), 297–312.
Wright, D., Rhee, J., & Vaculin, A. (2010). Offline Improvement During Motor Sequence Learning Is Not Restricted to Developing Motor Chunks. Journal of Motor Behavior, 42(5), 317–324.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 The Author(s)
About this chapter

Cite this chapter
Beynon, M.J., Moutinho, L., Veloutsou, C. (2018). An Exposition of the Role of Consideration Sets in a DS/AHP Analysis of Consumer Choice. In: Moutinho, L., Sokele, M. (eds) Innovative Research Methodologies in Management. Palgrave Macmillan, Cham. https://doi.org/10.1007/978-3-319-64394-6_10
Download citation
DOI: https://doi.org/10.1007/978-3-319-64394-6_10
Published:
Publisher Name: Palgrave Macmillan, Cham
Print ISBN: 978-3-319-64393-9
Online ISBN: 978-3-319-64394-6
eBook Packages: Business and ManagementBusiness and Management (R0)