
Abstract
The current trend of computer vision and image processing systems in biomedical field is the application of the Computational Intelligence (CI) approaches, which include the use of tools as machine learning and soft computing. The CI approaches bring a new solution to automatic feature extraction for a particular task. Based on that techniques, we have proposed in this work a semi-automated method for the glaucoma monitoring through retinal images. Glaucoma is a disease caused by neuro-degeneration of the optic nerve leading to blindness. It can be assessed by monitoring Intraocular Pressure (IOP), by the visual field and the aspect of the optic disc (ratio cup/disc). Glaucoma increases the rate of cup/disc (CDR), which affects the loss of peripheral vision. In this work, a segmentation method of cups and discs regions is proposed in a semi-supervised pixel-based classification paradigm to automate the cup/disc ratio calculation for the concrete medical supervision of the glaucoma disease. The idea is to canvas the medical expert for labeling the regions of interest (ROI) (three retinal images) and automate the segmentation by intelligent region growing based on machine learning. A comparative study of semi-supervised and supervised methods is carried out in this proposal, by mono approaches (decision tree and SETRED) and multi-classifiers (Random Forest and co-Forest). Our proposition is evaluated on real images of normal and glaucoma cases. The obtained results are very promising and demonstrate the efficacy and potency of segmentation by the multi-classifier systems in semi-automatic segmentation.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


Keywords
- Pixel-based classification
- Semi-supervised learning
- Semi-automatic segmentation
- Fuzzy C-means
- co-Forest
- Glaucoma monitoring
1 Introduction
The majority of applications in the field of medical diagnostic aid require the acquisition of imaging data of various natures: radiologies, scanner or MRI examinations, ultrasound imaging, video, etc. A fundamental task in the processing of this data is segmentation, i.e., the extraction of structures of interest in images, in 2D or 3D format. This information serves, in particular, as a basis for the visualization of organs, the classification of objects, the generation of simulation models, or surface or volumetric measurements. In this work, we are interested in the annotation of images at the pixel level by a semi-automatic segmentation approach. This method requires more or less important interaction of the expert. This type of tool is useful either to process the data directly or to define a reference result that can be applied for the evaluation of automatic segmentation methods.
Automatic image segmentation aims at the automated extraction of objects characterized by a border (contour). Its purpose is to cluster pixels according to predefined criteria, usually the gray levels or the texture. The pixels are thus grouped into regions, which constitute a partition of the image. Nevertheless, this task remains difficult to achieve especially in the cases where the edges of an object are missing and/or there is a low contrast between the regions of interest (ROI) and the background.
Segmentation of retinal images, mainly the fundus images, is an important step in the medical monitoring of glaucoma. Indeed, the diagnosis of glaucoma is determined by doctors in studying many factors: family history, the intraocular pressure, the thickness of the central cornea, the appearance of the anterior chamber angle, the optic nerve configuration including nerve fiber layer, and the optic nerve function. For now, the diagnosis cannot be based on a single analysis. For example, looking for a high intraocular pressure is the first step to detect glaucoma. However, one-third of patients with glaucoma have normal intraocular pressure. Most glaucoma screening tests are time consuming and require the intervention of glaucoma specialists and the use of diagnostic equipment. Consequently, new automated techniques for diagnosing glaucoma at an early stage, combining precision and speed, are required.
Many approaches have been proposed in the literature for the segmentation of the fundus of the eye images in order to extract the region of the optical disc. These works can be distributed within the families of approaches such as segmentation methods, feature extraction techniques, and classification methods that include supervised and unsupervised algorithms.
Supervised segmentation using methods such as neural networks and support vector machines (SVMs) lead to high precision, but generally, these techniques require a large amount of labeled data for their learning, and the unavailability of labeled data due to the boring task of labeling pixels and images, or the unavailability of experts (e.g., medical imaging), make the task particularly difficult, expensive, and slow to acquire in real applications. On the other hand, unsupervised learning methods such as K-Means and C-Fuzzy Means (FCM) suppress labeling costs but perform less than supervised methods. To solve these problems, we propose a semi-supervised learning (SSL) approach for the segmentation of the cup and disc regions in the objective of medical monitoring by the calculation of the CDR ratio.
The availability of unlabeled data and the difficulty of obtaining labels, make the semi-supervised learning methods gain great importance. With the goal of reducing the amount of supervision required compared to supervised learning, and at the same time improving the results of unsupervised clustering to the expectations of the user. The question that arises is whether the knowledge of points with labels is sufficient to construct a decision function that can correctly predict the labels of unlabeled points. Different approaches propose to deduct unlabeled points of additional information and include them in the learning problem. Several semi-supervised algorithms such as self-training [36], Co-training [6], Expectation Maximization (EM) [27], and in the last few years, the ensemble method co-forest [12, 25] have been developed, but none of them were used for semi-supervised segmentation.
A method of segmentation and automatic recognition of regions cups and discs for measuring the CDR report in a semi-supervised context is proposed here. The intervention of an ophthalmologist expert is important in identifying cups and discs areas in retinal image. For this, the expert will realize a windowing of 5% of the image data set (3 retinal images). This approach helps to automate the segmentation of glaucoma’s parts using intelligent techniques.
Thus, a comparative study of several techniques is proposed. The principle is based on a region growing by classifying the neighboring pixels from the pixels of interest of the image using semi-supervised learning. The points of interest are detected by the Fuzzy C-Means (FCM) algorithm. Four classifiers with different principle are applied in this work: Decision Tree (mono-supervised classifier), Random Forest (supervised ensemble method) SETRED (method of self-learning in SSL), and the algorithm co-Forest (Ensemble method in SSL). This study will adapt the best approach to the segmentation of retinal images with minimal intervention of the medical expert.
This work is organized as follows: in Sect. 2, a review of some segmentation and pixel-based classification methods of the retinal images is performed. We explain then in Sect. 3, the general process of our proposed approach and its different steps (characterization, pretreatment and SSL classification methods). After that, we validate our approach and the choices we have made in an experimental phase. Moreover, we show the capacity of our approach to automatic segmentation by applying several methods. Finally, we come to an end with a conclusion that summarizes the contributions made and the tracks defining possible opportunities for future work as well as the difficulties faced with the realization of this work.
2 State of the Art
Glaucoma is an eye disease associated with abnormal increase in the pressure of the ocular fluid. This abnormal pressure leads gradually and most often painless to irreversible visual impairment. It can be evaluated by monitoring the appearance of the optic disc (CDR Disc Cup Report).
The CDR value increases with the increase of neuro-degeneration and retinal vision is lost completely in the CDR value = 0.8. Several methods for extracting features from images of the eye funds are reported in the literature [1, 7, 17, 19, 23, 28]. The techniques described in the literature for the location of the optical disc are generally intended to identify either the approximate center of the optical disc or to place it in a specific region, such as a circle or a square. Lalonde et al., used the Canny detector [23] Ghafar et al. [17], the Hough transform to detect the optical disc (OD). Bock et al. [7], called for the concept of principal component analysis (PCA), bitsplines and Fourier analysis for feature extraction and Support Vector Machines (SVM) as classifier for predicting glaucoma.
The retinal image automatic analysis is becoming an important screening tool for the early detection of eye diseases. The manual review of the Optical Disc (OD) is a standard procedure used to detect glaucoma. The best way to control the glaucoma disease is by using the digital retinal camera. These images are stored in RGB format, which is divided into three channels: red, green, and blue. Other studies have focused on image processing techniques to diagnose glaucoma based on the CDR evaluation of retinal color images.
Madhusudhan et al. [26] have developed a system for processing and automatic image classification based on the usual practice in clinical routine. Therefore, three different image processing techniques namely multi-thresholding segmentation methods based on active contours region are proposed for the detection of glaucoma. Mohammad et al. [29] have presented an approach which includes two main steps. First, a pixel-based classification method for identifying pixels which may belong to the boundary of the optic disc. Second, a match-up of the circular template to estimate the approximation of the circular edge of the optical disc. The characteristics of the used pixels are based on the texture which is calculated from the local picture intensity differences. The Fuzzy C-Means (FCM) and Naive Bayes are used to group and classify image pixels.
Chandrika et al. [11] adopted an automatic identification technique of optical disc retinal images by calculating the ratio CDR. In the first place, a threshold is applied and then the image segmentation is performed using k-means and the Gabor wavelet transform. Second, the contour smoothing of the disc and the optical cup is performed using different morphological characteristics.
More conventionally, Hatanaka et al. [18] proposed a method to measure the ratio cup/disc with a vertical profile on the optical disc. The edge of the optical disc is then detected by using a Canny edge detection filter. The resulting profile is made around the center of the optical disc in the vertical direction. Thereafter, the edge of the vertical area on the cup profile is determined by a thresholding technique.
Joshi et al. [20] implement an automatic technique for the parameterization of the optical disc (OD) according to the segmented cup and disc regions obtained from the monocular retinal images. A new OD segmentation method is proposed, integrating the information of the local image around each point of interest in the multidimensional function space. This is in order to provide robustness against the variations found in and around the OD region. A method of segmentation of the cup is also proposed, it is based on anatomical evidence such as vessel bends at the border of the cup, deemed relevant by experts in glaucoma. A multi-step strategy is used to obtain a reliable subset of vessel bends called r-bends followed by a fitting to derive the desired cup boundary.
Burana-Anusorn et al. [10] have developed an automatic approach for the calculation of CDR ratio from images of the eye funds. The idea is to extract the optical disc by using a contour detection approach and the level set approach by individual variation. The optical cup is then segmented using a color component analysis method and method of thresholding level set. After obtaining the contour, a step of adjusting by ellipse is introduced to smooth the obtained results. The performance of this approach is assessed by comparing the automatically calculated CDR with that calculated manually. The results indicate that the approach of Burana-Anusorn et al., reached a precision of 89% for the analysis of glaucoma. As a consequence, this study has a good potential in automated screening systems for early detection of glaucoma.
Recently, Khalid et al. [22] have proposed the deployment of dilation and erosion with fuzzy c-means (FCM) as an effective technique for segmentation cup and optical disc color images of the eye funds. Previous works have identified the green channel as the most suitable because of its contrast. Hence, at first, the extracted green channel is segmented with FCM. In another test, all the images are pretreated with dilation and erosion to remove the vascular network. Segmentation is assessed on the basis of the labels described by ophthalmologists. The CDR measures are calculated from the diameter ratio of the cup and segmented disc. The assessment shows that the omission of the vernacular area improves the sensitivity, specificity, and accuracy of the segmented result.
Sivaswamy et al. [35] were interested in the problem of segmentation of the optic nerve head (ONH) which is of crucial importance for the assessment of automated glaucoma. The problem of segmentation involves segmenting the optical disc and the cup of ONH region. The authors highlighted the difficulty to evaluate and compare the performances of existing methods due to the lack of a reference data set. On that account, a complete set of retinal image data which include normal and glaucoma eyes by manual segmentations of several experts was implemented. Both evaluation measures based on size and contour are shown to evaluate a method on various aspects of the problem of the evaluation of glaucoma.
From the literature study, several approaches are carried out to determine mostly the cup and have focused on image processing techniques to diagnose glaucoma based on the CDR evaluation of retinal color images. Computational Intelligence (CI) approaches are alternative solutions for traditional automatic computer vision and image processing methods; they include the use of tools as machine learning and soft computing. In this study, we have proposed a new CI approach for the segmentation process by an iterative learning algorithm to achieve a semi-automatic classification procedure that promises to be more accurate than traditional supervised pixel-based methods. A comparative study will be conducted between mono and ensemble classifier to analyze their impact on the accuracy of prediction in pixel classification task.
3 The Proposed Approach
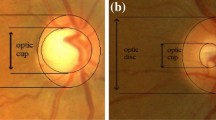
The aim is to automatically recognize cups and discs regions (Fig. 1) that are essential for measuring the progression of glaucoma. To do this, we propose an approach based primarily on a semi-supervised pixel-based classification.

Glaucomatous papillary excavation (increasing the ratio cup/disc)
The intervention of an ophthalmologist expert is important in identifying the disc and cup retinal image. We were inspired by the principle proposed by Reza et al. [4] in the step where the expert is appealing to windowing the region of interest on a minimum of images. In our application, we randomly select three images (5% of the image data set), the labeling step is made by tagging three windows (disc, cup, and background). Thereafter, a characterization phase takes part, where each pixel is represented by a color features.

The proposed approach to semi-automatic segmentation process
Our contribution is the application of semi-supervised classification techniques on pixels appraised by the doctor to form a robust and reliable hypotheses that allows pixel-based classification. The proposed algorithm is illustrated in Fig. 2. The idea is to realize at first a preprocessing that allows us to score some pixel in cups and discs regions using the fuzzy c-means method. For a better learning, a classification will be applied to the vicinity of each region of interest that was marked in the preprocessing phase. This phase will be conducted by four different classification approaches (Decision trees [9], Random Forests [8], SETRED self-training algorithm [24], and Random Forests in semi-supervised learning co-Forest [25]).
3.1 Feature Extraction Methods
Color Spaces
Different color spaces have been used in pixel-based classification for segmentation purposes, but many of them share similar characteristics. Therefore, in this work, we are interested in five more representative color spaces that are commonly used in image processing [16]: RGB, LUV, HSV, HSL, YUV.
RGB Color Space
The RGB space is a fundamental and commonly used color space in various computer vision application, it is about describing color by three components: red, green, and blue. Components are combined in various ways to reproduce different colors in the additive model.
HSV Color Space
In the work of [21], they define the Hue as the property of a color that varies in passing from red to green, the Saturation as the property of a color that varies in passing from red to pink, the Value (also called Intensity or Lightness or Brightness) as the property that varies in passing from black to white. The HSV is a linear transformation of RGB to high intensity at white lights, ambient light, and surface orientations relative to the light source.
LUV Color Space
The aim of LUV color space is to produce a more linear color space. Perceptual linear means a variation of the same quantity of color has to produce a variation of which the same visual importance.
YUV Color Space
The YUV space is mainly used for analog video, this representation model is used in the PAL and NTSC video standards. The luminance is represented by Y, whereas the chrominances U and V are derived from the transformation of the RGB space.
Table 1 summarize the characterization parameters of each color space.
3.2 Points of Interest Detection
Considering the time computing, especially in a semi-supervised context, has led us to propose a phase detection process known as points of interest. The objective of this phase is to minimize the computation time and the other to start learning semi-supervised via voltage pixels belonging to our target. We propose the implementation of cluster centers by fuzzy C-means method “FCM”.
Fuzzy C-means method (FCM) is an unsupervised fuzzy clustering algorithm. From the C-Means algorithm (C-means), it introduced the concept of fuzzy set in the definition of classes: each point in the data set for each cluster with a certain degree, and all clusters are characterized by their center of gravity. Like any other clustering algorithms, it uses a criterion of minimizing the intra-class distance and maximizing the inter-class distances, but giving a degree of membership in each class for each point. This algorithm requires prior knowledge of the number of clusters and generates classes through an iterative process by minimizing an objective function.
The whole FCM process [5, 14] can be described in the following steps:

3.3 Classification Methods
With the availability of unlabeled data and the difficulty of obtaining labels, semi-supervised learning methods have gained great importance. Unlike supervised learning, the semi-supervised learning is the problems with relatively few tagged data and a large amount of unlabeled data. The question is then whether the mere knowledge of the items with labels is sufficient to construct a decision function that can correctly predict the labels of unlabeled points. Different approaches propose to deduct untagged items, additional information and include them in the learning problem.
In this classification part, we focus on improving the performance of supervised classification using unlabeled data (SSL). We set up the first semi-supervised classification under the classification problems, limited to the use of methods of sets in semi-supervised classification. Therefore, we propose in this work to apply the method set type of multi-classifier systems compared to single-supervised learning classifiers methods and semi-supervised: Decision tree [9], Random Forests [8], SETRED auto-learning algorithm [24], and Forests in semi-supervised learning co-Forest [25].
Decision Trees
Decision trees (DT) represent a very effective method of supervised learning. The goal of DT is to partition a set of data into the most homogeneous groups possible from the point of view of the variable to be predicted. As input, we use a set of data to classify and get a tree, which resembles very much to an orientation diagram, as output. A decision tree consists of a root that is the starting point of the tree, nodes, and branches that connect the root with the nodes, the nodes between them and the nodes with the leaves. There are several algorithms present in the literature, such as: CART [9], ID3 Quinlan86 And C4.5 [32]. In this work, we limit ourselves to the application of the CART algorithm (Classification and Regression Tree).
Self-Training Paradigm
SETRED (self-training with data editing) is the most popular algorithm proposed by Li et al. [24]. Here, the authors studied the potential of data editing techniques as a confidence measure which allows it to reduce the risk of adding mislabeled data to the training set. This paradigm is an iterative mechanism. Its principle is to train a supervised classifier on labeled pixels to predict the labels of unlabeled pixels. Afterward, it iteratively enriches the labeled set by adding newly labeled examples with high confident predictions from the unlabeled data (confidence data). In SETRED, the CEWS (Cut Edge Weight Statistic) [30] rule is applied to measure the confidence level on unlabeled examples. The main steps to calculate the confidence measure are as follows:
The Nearest Neighbor Rule
The nearest neighbor rule (NNR) was proposed by Fix and Hodges [15], it is a nonparametric method where the classification is obtained for an unlabeled data taking into account the class of its nearest neighbor in the learning samples. The calculation of the similarity between data is based on distance measurements. Afterward, this rule was developed to \(k-NNR\), k represents the size of the neighborhood. The label of a non-classified data is that of the majority class among the labels of its k nearest neighbors.
The Relative Neighborhood Graph
The neighborhood graph is a computational geometry tool that has been exploited in many machine learning applications. By definition, a neighborhood graph \(G = (V, E)\) [13] associated with a set of labeled pixel whose vertices S compose the set of edges E. Each pixel in a neighborhood graph is represented by a vertex, existing in the edge between two vertices \( x_i \) and \( x_j \) if Eq. 1 is verified.
With: \(dist(x_i,x_j)\): the distance between \(x_i\) et \(x_j\).
The Cut Edge Weight Statistic
Using the previous definition to construct a relative neighborhood graph, Muhlenbach et al. [30] exploited the edge information to calculate a statistical weight in order to cut edges of different classes. The SETRED [24] algorithm follows this principle for the confidence measure.
In the first step, a supervised hypothesis is learned using the labeled pixels. Second, the application of the cut edge weight statistic [30] algorithm, to calculate the ratio \( R_i \) by the Eqs. (2, 3, 4, 5). To judge whether the data is well ranked, the ratio \( R_i \) must be greater than a threshold that is set by the user. For more information, one may consult [24, 30].
With:
Ensemble Method: Random Forests
Random Forest (RF) is a predictor that combines a set of decision trees. In the specific case of CART models (binary tree), Breiman [8] proposes an improvement of bagging with a random forest induction algorithm Forest-RI (Random Input) which uses the “Random Feature Selection” method proposed by Amit and Geman [3]. The induction of the trees is done without pruning and according to the CART algorithm [9], however, at each node, the selection of the best partition based on the Gini index is done only on a subset of attributes (usually equal to the square root of the total number of attributes) selected randomly from the original space of features [34]. The global prediction of the random forest is calculated by taking the majority of votes of each of its trees. This algorithm is defined by Breiman as follows (Algorithm 1) [8]:

The Random Forest in Semi-supervised Learning “co-Forest” Algorithm
co-Forest is an algorithm that extends the paradigm of co-Training [6] using Random Forest [8]. It was introduced by Li and Zhou [25] in the application to the detection of micro-calcifications in the diagnosis of breast cancer. This ensemble method uses \( N \ge 3\) classifiers instead of 3 by Tri-training [37]. The \(N-1\) classifiers are used to determine confidence examples, called concomitant ensemble = \( h_i = H_ {N-1} \). Confidence of an unlabeled pixels can be simply estimated by the degree of agreement on the labeling, i.e., the number of classifiers which are agreements assigned by \( h_i \) label.
The functioning of co-Forest can be summarized in the following steps (Algorithm 2):

To insure the success of this ensemble method, two conditions must be satisfied:
-
Each individual predictor should be relatively good,
-
Each individual predictor should be different from each other.
Even more simple, it is necessary for the individual predictors to be good classifiers, and where a predictor is wrong, the other must take over without making mistakes.
For maintaining the diversity in co-Forest, the application of Random Forest can inject random learning. To affirm this condition, the authors of co-Forest have set a threshold for the labeling of U, where the only U pixels whose total weight is smaller than \(e_{i, t-1}. W_{i, t-1} / e_{i,t}\) will be selected.
In summary, the principle of co-Forest (Fig. 3) consists of N random trees that are first learned on bootstrap set of L to create a random forest. Then, at each iteration, each random tree will be refined with the newly labeled samples selected by its concomitant set, only when the confidence of the labeled examples exceeds a certain threshold \(\theta \). This method will reduce the chances of used biased tree in a Random Forest when we use unlabeled data. More details on the co-Forest algorithm are in the papers [12, 25, 33].

Schematic diagram of co-Forest algorithm
4 Results and Experiments
The retinal image database was constructed from local real images acquired within the eye clinic (clinic LAZOUNI Tlemcen). Eye Backgrounds RTVue XR 100 Avanti Edition of Optovue company provides RGB color images of size \(1609\,\times \,1054\) pixels. One hundred and three retinal images of the eye funds have been used to test the proposed segmentation algorithm. The ground truth is achieved by using the average segmentation provided by two manual different experts in ophthalmology. We built a learning base, where the expert selects three regions: cup, disc (ROI: regions of interest) and bottom (stopping criterion) (Fig. 4).

a Cup, b Disc and c background
In our experiments, we have selected 5% of the database (3 images) to achieve learning. The expert ophthalmologist intervenes in the labeling of these three images by size windowing [576–50466 pixels], allowing a better understanding of areas of interest. In the semi-supervised learning portion, a classification is applied to the vicinity of a degree equals to 50. The application of all methods (Random Forest and co-Forest) with a number of trees equal to 100 being was chosen. The evaluation is carried out with a cross-validation equals to 5. The details of the experimental parameters are summarized in Table 2.
Table 3 summarizes the classification performance by the four approaches supervised and semi-supervised on 20 test images for the recognition of regions cup and disc. The results achieved by the overall approaches Random Forest and co-Forest guarantee greater precision of segmentation of the two target regions. However, poor results were obtained by the decision tree CART but the semi-supervised mode has improved the performance for the method SETRED-CART. Our approach by the algorithm co-Forest realizes the best segmentation performance for both regions and especially the cup area that is most difficult to extract. These results allow us to consolidate our proposal and affirm its rigor and robustness for-pixel-based classification by region growing task by semi-supervised learning.

Examples of automatic segmentation image by the various techniques
4.1 Discussion
For completeness, and to establish a visual assessment of the performance of our approach, we have randomly selected six images of the test basis (Fig. 5) to discuss the performance and quality of segmentation by four single and multi-classifier approaches supervised mode and semi-supervised namely, respectively, the decision tree and Random Forest and the method SETRED and co-Forest.
Thus, a comparative study of several techniques is proposed. The principle is based on a region growing classifying the neighboring pixels from the pixels of interest of the image semi-supervised learning. In our process, we have used the Fuzzy C-Means (FCM) algorithm to detect the pixels of interest, in order to achieve the segmentation of target regions. The pixels of interest generate by FCM in the pictures \(\text {N}^{\circ }\) 2, 3, and 4 (Fig. 5) leads to poor segmentation by the use of mono-classifiers (CART and SETRED); unlike the multi-classifiers (Random Forest and co-Forest) was able to successfully separate the cup region.
Another advantage of using the methods together is the network power separation vessel and the bottom region as clearly shown in pictures 2, 3 and 4 (Fig. 5). However, as we can also see in the image 3 (Fig. 5), the contribution of non-labeled pixels to the overall method co-Forest has allowed proper identification disc unlike the Random Forest. We also notice in the image 1 (Fig. 5) misclassification of pixels of the whole cup approaches except the algorithm co-Forest.
As a whole, this work has allowed us to see a multitude of research avenues that are available for automatic segmentation of images. The idea to extrapolate the region segmentation by pixel-based classification semi-supervised learning context by the approach co-Forest allowed us to exploit the non-labeled data in the establishment of the set-prediction model. In this sense, non-labeled data has reinforced the recognition of regions of interest for a report cup/disc calculated approximating that of the ophthalmologist.

The cup/disc ratio comparison between the expert and proposed methods calculation. From 1–8 normal, from 9–15 glaucoma
A comparison of the cup/disc reports performed by an ophthalmologist and the proposed methods on fifteen random images is shown in Fig. 6. Differences in the ophthalmologist’s CDR ratios compared to the proposed supervised methods (CART and Random Forest) are widely discarded in cases of glaucoma and normal cases. Even though the CDR ratios calculated by the ensemble approach are closer to the optimal (expert measure).
However, our results for the semi-supervised algorithms co-Forest and SETRED were slightly different in the value of the ophthalmologist, but our method co-Forest tended to show smaller variations in normal cases and glaucoma cases, with almost similar extent to that of the expert.
5 Conclusion
Machine learning (ML) can be used in both image processing and computer vision but it has found more use in computer vision than in image processing. The goal of machine learning is to optimize differentiable parameters so that a certain loss/cost function is minimized. The loss function in ML can have a physical meaning in which case the features learned can be quite informative but this is not necessarily the case for all situations. Computational Intelligence (CI) approaches are alternative solutions for automatic computer vision and image processing systems; they include the use of tools as machine learning and soft computing. The aim is to have an complete autonomy of the computer, but this might not be easily achievable. In this work, we have demonstrated that the semi-supervised learning might be the best solution. Indeed, we have proposed a method of automatic segmentation of disc and cup regions in retinal images by pixel-based classification in semi-supervised learning.
The objective is to involve the expert learning of our model for a better discrimination of regions of interest. Evaluation and segmentation of images tests are performed using the algorithm Fuzzy C-Means. A growth of region is developed by classifying the neighboring pixels by applying four classifiers: Decision Tree, Random Forest, the method SETRED and co-Forest.
The results are very convincing and encouraging, showing a great capacity for recognition and segmentation of target regions, this being clearer by applying the Random Forest in semi-supervised learning co-Forest , heuristics of these ensemble methods allows, using multiple classifiers, to greatly explore the solution space, and by aggregating all predictions, we will take a classifier that considers all this exploration. The contribution of non-labeled data in the establishment of the prediction model can reinforce learning and recognition of relationships between pixels and region.
However, there are some points that deserve some discussion and further development in future works. One must say that the main limitation of our method is the long time processing. Further work to reducing the constraints over time achieving is currently underway to an complete autonomy. One of the proposed solutions to deal with this problem is the parallel programming. Indeed, our algorithm allows us to use a master/slave architecture. In another way, we are currently developing a new semi-automatic segmentation approach based on superpixel-by-superpixel classification [2], where superpixels should both increase the speed and improve the quality of the results.
References
Abdel-Razik Youssif, A.H., Ghalwash, A., Abdel-Rahman Ghoneim, A.: Optic disc detection from normalized digital fundus images by means of a vessels’ direction matched filter. IEEE Trans. Med. Imaging 27(1), 11–18 (2008). doi:10.1109/TMI.2007.900326
Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., Susstrunk, S.: Slic superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 34(11), 2274–2282 (2012). doi:10.1109/TPAMI.2012.120
Amit, Y., Geman, D.: Shape quantization and recognition with randomized trees. Neural Comput. 9(7), 1545–1588 (1997)
Azmi, R., Norozi, N., Anbiaee, R., Salehi, L., Amirzadi, A.: IMPST: a new interactive self-training approach to segmentation suspicious lesions in breast MRI. J. Med. Signals Sensors 1(2), 138–148 (2011)
Bezdek, J.C.: Pattern Recognition with Fuzzy Objective Function Algorithms. Kluwer Academic Publishers, Norwell (1981)
Blum, A., Mitchell, T.: Combining labeled and unlabeled data with co-training. In: Proceedings of the Eleventh Annual Conference on Computational Learning Theory, COLT’98, New York, NY, USA, pp. 92–100 (1998)
Bock, R., Meier, J., Nyul, L.G., Hornegger, J., Michelson, G.: Glaucoma risk index: automated glaucoma detection from color fundus images. Med. Image Anal. 14(3):471–481. doi:10.1016/j.media.2009.12.006. http://www.sciencedirect.com/science/article/pii/S1361841509001509 (2010)
Breiman, L.: Random forests. Mach. Learn. 45, 5–32 (2001)
Breiman, L., Friedman, J.H., Olshen, R.A., Stone, C.J.: Classification and Regression Trees. Chapman and Hall, New York (1984)
Burana-Anusorn, C., Kongprawechnon, W., Sintuwong, S., Tungpimolrut, K.: Image processing techniques for glaucoma detection using the cup-to-disc ratio. Thammasat Int. J. Sci. Technol. 18(1) (2013)
Chandrika, S., Nirmala, K.: Analysis of CDR detection for glaucoma diagnosis. Int. J. Eng. Res. Appl. (IJERA) NCACCT-19: ISSN: 2248-9622 (2013)
Deng, C., Guo, M.: A new co-training-style random forest for computer aided diagnosis. J. Intell. Inf. Syst. 36(3), 253–281. http://dblp.uni-trier.de/db/journals/jiis/jiis36.html#DengG11 (2011)
Devroye, L., Györfi, L., Lugosi, G.: A Probabilistic Theory of Pattern Recognition. Springer, New York (1996)
Dunn, J.: A fuzzy relative of the isodata process and its use in detecting compact, well-separated clusters. J. Cybern. 3, 32–57 (1974)
Fix Jr., E.: Discriminatory analysis: nonparametric discrimination: consistency properties. Technical Report Project 21-49-004, Report Number 4, USAF School of Aviation Medicine, Randolf Field, Texas (1951)
Foley, J.D., van Dam, A., Feiner, S.K., Hughes, J.F.: Computer Graphics: Principles and Practice, 2nd edn. Addison-Wesley Longman Publishing Co. Inc., Boston (1990)
Ghafar, R., Morris, T., Ritchings, T., Wood, I.: Detection and characterization of the optic disc in glaucoma and diabetic retinopathy. In: Medical Image Understand Annual Conference, London, UK, pp. 23–24, Sept 2004
Hatanaka, Y., Noudo, A., Muramatsu, C., Sawada, A., Hara, T., Yamamoto, T., Fujita, H.: Automatic measurement of vertical cup-to-disc ratio on retinal fundus images. In: Proceedings of the Second International Conference on Medical Biometrics, ICMB’10, pp. 64–72. Springer, Berlin, Heidelberg (2010). doi:10.1007/978-3-642-13923-9_7
Hoover, A., Kouznetsova, V., Goldbaum, M.: Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response. IEEE Trans. Med. Imaging 19(3), 203–210 (2000). doi:10.1109/42.845178
Joshi, G.D., Sivaswamy, J., Krishnadas, S.R.: Optic disk and cup segmentation from monocular color retinal images for glaucoma assessment. IEEE Trans. Med. Imaging 30(6), 1192–1205 (2011). doi:10.1109/TMI.2011.2106509
Kakumanu, P., Makrogiannis, S., Bourbakis, N.: A survey of skin-color modeling and detection methods. Pattern Recogn. 40(3), 1106–1122 (2007). doi:10.1016/j.patcog.2006.06.010
Khalid, N.E.A., Noor, N.M., Ariff, N.M.: Fuzzy c-means (FCM) for optic cup and disc segmentation with morphological operation. Procedia Comput. Sci. 42(0), 255–262. doi:10.1016/j.procs.2014.11.060. http://www.sciencedirect.com/science/article/pii/S1877050914014987 (2014). Medical and Rehabilitation Robotics and Instrumentation (MRRI2013)
Lalonde, M., Beaulieu, M., Gagnon, L.: Fast and robust optic disc detection using pyramidal decomposition and hausdorff-based template matching. IEEE Trans. Med. Imaging 20(11), 1193–1200 (2001). doi:10.1109/42.963823
Li, M., Zhou, Z.H.: SETRED: self-training with editing. In: Ho, T.B., Cheung, D.W.L., Liu, H. (eds.) PAKDD. Lecture Notes in Computer Science, vol. 3518, pp. 611–621. Springer (2005)
Li, M., Zhou, Z.H.: Improve computer-aided diagnosis with machine learning techniques using undiagnosed samples. Trans. Syst. Man Cybern. Part A 37(6), 1088–1098 (2007). doi:10.1109/TSMCA.2007.904745
Madhusudhan, M., Malay, N., Nirmala, S., Samerendra, D.: Image processing techniques for glaucoma detection. In: Abraham, A., Mauri, J., Buford, J., Suzuki, J., Thampi, S. (eds.) Advances in Computing and Communications, Communications in Computer and Information Science, vol. 192, pp. 365–373. Springer, Berlin, Heidelberg (2011). doi:10.1007/978-3-642-22720-2_38
Maeireizo, B., Litman, D., Hwa, R.: Co-training for predicting emotions with spoken dialogue data. In: Proceedings of the 42th Annual Meeting of the Association for Computational Linguistics (ACL-2004) (2004)
Mendonca, A., Campilho, A.: Segmentation of retinal blood vessels by combining the detection of centerlines and morphological reconstruction. IEEE Trans. Med. Imaging 25(9), 1200–1213 (2006). doi:10.1109/TMI.2006.879955
Mohammad, S., Morris, D., Thacker, N.: Texture analysis for the segmentation of optic disc in retinal images. In: 2013 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 4265–4270 (2013). doi:10.1109/SMC.2013.727
Muhlenbach, F., Lallich, S., Zighed, D.A.: Identifying and handling mislabelled instances. J. Intell. Inf. Syst. 22(1), 89–109 (2004)
Muramatsu, C., Hatanaka, Y., Ishida, K., Sawada, A., Yamamoto, T., Fujita, H.: Preliminary study on differentiation between glaucomatous and non-glaucomatous eyes on stereo fundus images using cup gradient models. In: Proceedings of SPIE 9035:903,533–903,533–6 (2014). doi:10.1117/12.2043409
Quinlan, J.R.: C4.5: Programs for Machine Learning. Morgan Kaufmann (1993)
Settouti, N., El Habib Daho, M., El Amine Lazouni, M., Chikh, M.: Random forest in semi-supervised learning (co-forest). In: 2013 8th International Workshop on Systems, Signal Processing and their Applications (WoSSPA), pp. 326–329 (2013). doi:10.1109/WoSSPA.2013.6602385
Sirikulviriya, N., Sinthupinyo, S.: Integration of rules from a random forest. In: International Conference on Information and Electronics Engineering IPCSIT, vol. 6. IACSIT Press, Singapore (2011)
Sivaswamy, J., Krishnadas, S.R., Joshi, G.D., Jain, M., Tabish, A.U.S.: Drishti-GS: retinal image dataset for optic nerve head(ONH) segmentation. In: IEEE 11th International Symposium on Biomedical Imaging, ISBI 2014, 29 Apr–2 May 2014, Beijing, China, pp. 53–56 (2014). doi:10.1109/ISBI.2014.6867807
Yarowsky, D.: Unsupervised word sense disambiguation rivaling supervised methods. In: Proceedings of the 33rd Annual Meeting on Association for Computational Linguistics, Association for Computational Linguistics, ACL’95, Stroudsburg, PA, USA, pp. 189–196 (1995). doi:10.3115/981658.981684
Zhou, Z.H., Li, M.: Tri-training: exploiting unlabeled data using three classifiers. IEEE Trans. Knowl. Data Eng. 17(11), 1529–1541 (2005). doi:10.1109/TKDE.2005.186
Acknowledgements
The completion of this research could not have been possible without the participation and the support of LIMOS, CNRS, UMR 6158, 63173, Aubiere, France. Their contributions are sincerely appreciated and gratefully acknowledged. However, we would like to express our deep appreciation and indebtedness to the ophthalmic clinic “CLINIQUE LAZOUNI” for providing reel medical database that greatly assisted our work.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG
About this chapter
Cite this chapter
Settouti, N., El Habib Daho, M., Bechar, M.E.A., Lazouni, M.A., Chikh, M.A. (2018). Semi-automated Method for the Glaucoma Monitoring. In: Hassanien, A., Oliva, D. (eds) Advances in Soft Computing and Machine Learning in Image Processing. Studies in Computational Intelligence, vol 730. Springer, Cham. https://doi.org/10.1007/978-3-319-63754-9_11
Download citation
DOI: https://doi.org/10.1007/978-3-319-63754-9_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-63753-2
Online ISBN: 978-3-319-63754-9
eBook Packages: EngineeringEngineering (R0)