
Abstract
By applying key notions of evolutionary economics, this study develops an analytical framework to explain the differentiated evolutionary paths of convergence and divergence in the economic growth across China’s provinces since 1978. We adopt the nonparametric approach in the study, including both univariate and multivariate kernel density estimation. We find evidence that the convergence in economic growth across provinces does not take shape. Instead, a divergence exists in the economic growth of China. Furthermore, the evolutionary dynamics revealed by our kernel estimation suggests that the disparity of the economic growth rate continuously increases since 1978, not only among different provinces, but also among different areas within a single province.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others

1 Introduction
Whether economic growth will converge or diverge has been perplexing economists and policymakers for a long time. The research on convergence and divergence can be traced back to the neoclassical models of growth. For instance, Barro and Sala-i-Martin identify the β-convergence distribution and σ-convergence (\( {\lim}_{\mathrm{t}\to \infty }{\sigma}_t^2={\sigma}^2 \)) by employing the neoclassical growth model (Barro and Sala-i-Martin 1992). Taking one step forward, Young et al. (2008) provide evidence that β-convergence serves as a sufficient condition for σ-convergence.
However, neoclassical economists have not reached a consensus on this issue so far. Findings on the convergence estimation have been mixed and largely inconclusive. On one hand, Barro and Sala-i-Martin (1992) provide evidence on convergence by studying the American economy from 1963 to1986. Researchers who employ OLS and 3SLS to analyze the USA or OEDC countries also reach the conclusion of convergence or conditional convergence (e.g., de La Fuente 2003; Higgins et al. 2006; Young et al. 2008). On the other hand, researchers adopting other methods drew different conclusions, which generally support club convergence (e.g., Corrado et al. 2005; Pittau and Zelli 2006; Krause 2015) or divergence (e.g., Acemoglu 2009; Caggiano and Leonida 2009). These researchers use various econometric inferences, including regression, density estimation, or ACF (autocorrelation function), and different datasets consisting of world-wide countries, OECD countries, or EU countries.
Similarly, findings of most China-based studies are mixed as well. Some researchers provide evidence on convergence (e.g., Shi and Zhao 2011; Zhang 2004) or conditional convergence (e.g., Cai and Wang 2002; Wu 2006; Xu and Li 2004; Zou and Zhou 2007). In these studies, researchers employ regression, SGMM or DEA approach, respectively, to analyze Chinese province-level data. In contrast, Cai and Du (2000) find that while China’s economic growth is featured by club convergence, there is no significant absolute convergence based on the data from 1978 to 1998. The similar results are obtained by Xu and Shu (2005) with 1D kernel density estimation. Additionally, some other researchers draw the conclusion of divergence (Fan 2006; Ou et al. 2006; Wang and Fan 2004) or inter-provincial divergence in China through DEA estimation (Yan and Wang 2004; Zhang and Gui 2008).
In short, all these substantive differences in the empirical findings imply that it is merited to revisit the issue of convergence using other theoretical perspectives. Interestingly, the evolutionary theory provides such an alternative theoretical lens that has the potential to reconcile the controversies and contradictions. The evolutionary theory places a key emphasis on the dynamics during the evolutionary process. Put differently, it stresses that economic processes be path-dependent to the extent that future action is largely constrained by historical development (Bathelt and Glückler 2003). More specifically, the evolutionary school of economic thinking is strongly related to such key evolutionary notions as selection, path-dependency, chance and increasing returns (Boschma and Lambooy 1999), which can be well utilized to investigate the spatial clustering of the industry and regional disparities. By integrating these evolutionary thoughts into the current study, we take an econometric approach to delineate the evolutionary dynamics in the regional economic development in China, with a particular focus on the issue of convergence/divergence.
2 An Evolutionary Perspective on China’s Regional Disparity
Since China implemented the economic reform and opening-up policy, its economy has been growing fast for nearly 40 years. GDP grows 14 times since 1978, making China the second largest economy in this world. However, there exists a great disparity in the regional economic development across different provinces in China, especially between the inland provinces and the coastal ones.
Mechanisms of selection and chance play a critical role in the success of the eastern provinces in China. One major factor driving China’s economic growth is institutional changes. Almost all the experimentations of marketization policies began in the coastal area. As a consequence, the implementation of reform and opening-up policies encouraging trials and discoveries makes the economic growth in the eastern area remarkably faster than that in the western area which was then dominated by the planning economy. The reform from the 1980s through 1990s in the twentieth century endowed the eastern area with the unprecedented chance to outperform the middle and western area. Even though the firm cannot make globally rational decision in the market competition due to information imperfection, the inherent bias in the entrepreneur’s calculation, and the ever-changing market environment, the market does select the winner that can approximate global rationality. During this selection process, it is the pioneering marketization in the eastern area that makes more winners selected from this area than from other areas. As the economic reform unfolds, such disparities among regions gradually widen, which results in an increasingly evident phenomenon of divergence.
Additionally, the presence of increasing returns is to some extent held responsible for the growth disparities between the eastern and other areas in China. The concept of increasing returns is often associated with other concepts such as the lock-in effect (Grabher 1993) and knowledge spillover (Caniëls and Verspagen 2001). The apparent policy advantage of the eastern area attracts a great number of firms to agglomerate, which is further reinforced by the rapid growth in this area. Consequently, numerous firms agglomerate in the eastern area and even start to create their own regional milieu to support their goals (Bathelt and Glückler 2003). At the same time, the rate and character of technological advance is greatly influenced by certain institutional structures supporting R&D and/or other innovation activities. This policy-technology interaction makes the eastern area take a lead in economic growth. With the widening gap in economic growth between the eastern and other areas, a divergence inevitably appears.
It takes different ways for path dependency to play a role at different stages of the evolutionary process of China’s economic growth. Path dependency means that the technological and organizational change is a cumulative process, constraining firms in the possibilities of what they can do, by what they have done in the past (Laursen 2000). At first, the policy of economic reform and opening-up was piloted in China’s coastal areas and then implemented nationally. At this specific stage of the evolutionary process, the growth of the eastern area greatly benefited from taking a lead in shaping new growth paths and calculation routines for firms to coping with challenges and opportunities in the new market environment. Therefore, this early stage of the economic growth is featured by increasing divergence across different areas. Later on, with the diffusion of both policies and technologies, the negative effect of path-dependency gradually occurred as a result of adhering to the outdated calculation routine by firms which neglected the changes in the market and institutional environment. In other words, the outdated path dependency made many pioneering firms in the eastern area at a disadvantageous position in the competition. In contrast, the less-developed provinces in the middle and western area made good use of the late-comer advantage to create path dependency more appropriate to the new institutional environment and the new pattern of economic growth. At this later stage of the evolutionary process, path dependency enables the less-developed areas to accelerate to catch up with the eastern area, and may eventually allow economic convergence to emerge.
This study contributes to the literature in the following three aspects. First, we adopt multivariate kernel density estimation to well capture the evolutionary dynamics in the process of economic growth. Many of the extant studies depend on the 1D kernel density estimation, instead of a multivariate one, to conduct cross-sectional tests. Consequently, these studies cannot analyze the evolution process of the GDP per capita, and are likely to lead to arbitrary results. Given the complicated situation of the economic development and institutional environment in contemporary China, it is critically important to detect whether convergence, club convergence, or divergence exists across provinces. Therefore, departure from most of the existing studies, we employ both 1D and 2D kernel density estimation to analyze the evolution dynamics of the China’s province-level GDP per capita at different time points.
Second, the combined use of critical bandwidth (CB) and Silverman test allows us to determine whether the density distribution estimated via the kernel density estimation is unimodal or multimodal, and to analyze the development of club convergence and de-clubbing based on the CB value. As such, we provide an objective and statistical method to distinguish different patterns.
Third, the neoclassical AK model is only utilized to describe the characteristics of increasing returns. Although the evolutionary perspective casts doubt on the assumption of rationality, it is still necessary to figure out to which parameters and variables the growth pathway is related before we can conduct empirical analysis. Therefore, we build our theoretical model by combining neoclassical models with the evolutionary analysis of increasing return and institutional factors, aiming to explain the stable long-term evolution and lay a mathematical foundation for our empirical analysis.
3 The Emergence and Explanation of Divergence Among Regional Economies in China
To address the evolution process, a model of explicit distribution dynamics has been advocated by several authors (e.g., Quah 1996, 2002). Distribution dynamics can be evaluated according to two aspects: shape dynamics and intra-distribution mobility. Although this approach is controversial as it is too sensitive to the sample size and the selection of time intervals (Kremer et al. 2001), it is still more powerful in analyzing complicated economic convergence and the evolution of GDP compared with the regression estimation which was used by Laursen (2000) to analyze the patterns of export and technological specialization.
In this study, we introduce the preferential policy granted by the central government as a parameter into our model, and take into account of the difference in technological level between regions. The application of AK model is in accordance with the investment-driven growth pattern in China, as it is emphasized in this model that capital input promotes growth. Additionally, the conclusion derived from the AK model fits well with the data on China’s economic growth.
As for the representative household, we employ the CES type of utility function to depict the ‘agent’s consumption and saving behavior’.
Where a t , w t, and c t represent household asset, received wage and consumption, respectively. Drawing on the present-value Hamilton equation, we can derive the first-order condition for maximizing household consumption:
We further get the consumption at period t:
As for the representative firm, we adopt parameter τ to describe how the government preferential policy distorts market system, as it is a critically import factor in the regional economic growth in China. When τ is equal to zero (τ ∈ [0,1), no policy intervention is exerted on the market. The higher the value of τ, the stronger the government intervention (distortion) in the capital market. It is noted that a considerable number of regional growth policies in China tend to provide preferential land and taxation policies, so as to attract business and investment.
Where C t is firm cost. The government preferential policy leads to the increase in the rate of return on capital, which enables the regional capital to generate a higher net return on capital investment \( {r}_t=r-\delta =\frac{A}{1-\tau }-\delta \), where δ is a depreciation rate.
The firm’s increment of capital stock and GDP per capita are given by:
Solving the differential equation \( {\dot{k}}_t \) at period t, the growth rate of per capita GDP is equal to that of per capita capital stock:
Although we cannot identify the exact difference between the rate of time preference (ρ) and the inter-temporal substitution rate of consumption among different areas (θ), the difference in policies (τ) and the difference in technologies (A) among areas can be directly observed. The government preferential policy distorts the market mechanism, leading to the high return and high growth of capital in the coastal area, where the first mover advantage and advanced technological level (A) ensure a relatively high rate of productivity acceleration. At the same time, the coastal area obtains sufficient and cheap labor, which in turn leads to rapid growth, an obvious consequence for this region.
However, we note that even if similar areas enact the same incentive policy, it is not necessary that these areas result in the same development path, due to the inherent uncertainty within the economic system. Second, since the regional technological level A, ρ, θ and τ are not deterministic variables, we need to view the domestic per capita GDP as a stochastic process. From Eq. (1), we can derive the following result:
where W t = W(t; A, τ, θ, δ, ρ), represents a random variable with unknown probability distribution. Furthermore, the stochastic process y t satisfies the Markov assumption with probability distribution function Ft, and F t+s is expressed as the F t ’s mapping based on F t ’s own space:
where M s is probability transition function that describes the probability that the stochastic distribution y t at period t transiting to y t+s over a time interval of S. And M s is connected with W t . To make Eq. (2) hold, the expression of yt should contain only first order lag terms and no higher lag terms.
Taking Eq. (2) to the limit as t→∞ provides the ergodic (long-run) density implied by the transition function. It can be found as the solution to:
In order to understand the dynamics of regional economic growth, we can use the data on y t and y t+s , and employ kernel density estimation to estimate their probability density.
4 The Kernel Density Estimation
In this section, we will focus on describing the probability distribution of y t and the dynamics of distribution function.
Considering the stochastic process y t in Eq. (1) and expressing the stochastic distribution function of y t at period t as F y,t+s , we have the following estimation function for F y,t:
where i = 1, 2, 3 … n ∈ I represents the sample identity, namely, the identity label for provinces, and S(u) is the indicative function. We then obtain the following estimation of a probability density function of y t :
Here, the expression within the summation symbol denotes the number of sample points within the interval of [y t − h, y t +h]. We thus can set an appropriate weight function K, assigning weights to the sample point i defined by the Euclidean distance |y t − y i,t | ≤ h. As such we can obtain the estimation of a density function. That is, the kernel density estimate in this study is expressed as follows:
Equation (2) is expanded from one dimension to multiple dimensions and used for empirical analysis. Since the probability density function can be estimated as Lebesgue measure on Rd, the kernel density estimation equation of the point range {y i } can be redefined as:
where h is bandwidth, the size of which influences how well the density curve fits the sample. Generally speaking, the smaller the value of h, the better the density curve fits. K, the kernel function, is in nature a kind of weight function. We use Gauss kernel in the following estimation: \( K(u)={\left(2\pi \right)}^{-\frac{1}{2}}{e}^{-{u}^2/2} \). Researchers may also choose Epanechikov kernel or other kernel functions (Quah 1996). However, in practice, when considering the goodness of fit, it is generally accepted that the selection of bandwidth is far more important than the selection of kernel function (Weißbach and Gefeller 2004). The selection of bandwidth usually follows the standard of minimizing the asymptotic integrated mean square error (AIMSE). For instance, one can adopt direct insertion method or cross validation method defined by the minimum residual sum of squares.
In this study, we adopt the rule-of-thumb method to select the bandwidth:
In calculation, this method is corresponding to a ‘rule-of-thumb’ algorithm proposed by Silverman (1981) and Scott (1992). To minimize AIMSE, we simplify the bandwidth selection function under the assumption that the data follow a normal distribution.
5 Empirical Analysis of Regional Economic Divergence and Its Pattern in China
5.1 Methodology and Data Sources in Estimating Divergence
The basic methods for estimating convergence/divergence include cross-sectional, time series and panel data method. Cross-sectional method is questioned as it is vulnerable to the ad hoc selection, and it does not allow time series method to deal with multiple cross-sectional samples. Relatively speaking, the panel data model allows researchers to make sufficient use of the cross-sectional and time information in the data, and employ cointegration and/or ADF test. However, it is noteworthy that the selection of exogenous variables is somewhat arbitrary, which may make the results of empirical analysis depart from the conclusion derived from the theoretical model.
The multivariate non-parametric kernel density estimation is suitable for analyzing the phenomenon of convergence, particularly club convergence, or multimodal convergence. This method overcomes the drawbacks of parametric models and does not need to preset the model structure and parameters.
All the data on provinces, autonomous regions and municipalities are obtained from China Statistical Yearbook and China Compendium of Statistics from 1978 to 2013. In the convergence estimation, we use data on all the 31 provinces, municipalities and autonomous regions in China’s mainland.
5.2 The Distribution of Inter-Provincial Per Capita Real GDP Based on the Univariate Kernel Density Model
Figure 1 presents the results of the univariate kernel density estimation based on the data on real GDP per capital in 1978, 1990, 2000, 2010 and 2013. Here, all data have been standardized.

Distribution curve of inter-provincial GDP per capita (Year 1978, 1990, 2000, 2010 and 2013)
As Fig. 1 shows, after China embarked on economic reform, its GDP per capita, based on the price of year 1978, continuously increases, and the inter-provincial disparity, measured by the difference in GDP per capita, widens at the same time. In the 1980s, the curves of GDP per capita across provinces are rather concentrated, whereas they gradually separate from each other since 1990s. At the early stage of reform and opening-up, the average GDP per capita is very low (461 RMB yuan in 1978 and 524.8 RMB yuan in 1980), and the regional GDP per capita is concentrated around the mean level. In recent years, however, the aggregate level of GDP per capita increases from 1083.2 yuan in 1990 to 2940.8 yuan in 2000, and further to 10771.89 RMB yuan in 2013. Moreover, the disparity in GDP per capita GDP across regions increases.
Based on the mean of the probability density curve, it is found that the curve kurtosis shifts to the right continuously, and the variance in the provincial-level data increases. The gap between the curves becomes increasingly apparent since 1990s. We cannot infer whether there is absolute convergence or club convergence (i.e., bimodal distribution or multimodal distribution). However, we can conclude that since the implementation of reform and opening-up policies, China’s economic growth is characterized by growing GDP per capita, and a process of divergence of economic growth across provinces.
5.3 The Multivariate Estimation and Dynamics of Inter-Provincial Convergence in China
The multivariate kernel density estimation provides the straightforward description of the dynamics of inter-provincial convergence in China. This is conducive to gaining a better understanding of whether there is twin-peak or multi-peak in the inter-provincial economic growth. Aziz and Duenwald (2001) estimate growth dynamics based on China’s provincial-level data. However, they make comparisons based on the provincial data of 2 years, which makes their sample points largely limited.
In our estimation, we set the transition period to cover 5 years and 10 years, respectively. This is because there are abundant data on the inter-provincial per capita GDP, and the growth rate of post-reform China is faster than that of the 117 countries in Quah’s study. Therefore, if time interval is set to be too long, one may run the risk of overlooking some features of the transition in the dynamic process. We use Gauss kernel in the estimation, and the bandwidth is determined by using the rule-of-thumb method. The variable is expressed as 2 two-dimensional matrices: lny t and lny t+5 , lnyt and lny t+10 denoting the logarithm value of per capita GDP at period t, period t+5 and period t+10, respectively. N = 962 represents the size of sample points (including all the provincial-level data points on per capita GDP from 1978 to 2013). The estimation results are presented in Fig. 2.

The inter-provincial dynamics of the real GDP per capita (Year 1978–2013), s = 5
As is shown in Figs. 2 and 3, there is no club convergence in the changing process of provincial GDP per capita, and the dynamic process of the disparity in provincial GDP per capita is still characterized by a unimodal distribution. Instead, the disparity across provinces further widens. The ridge projection of the probability density curve in the right panel of Fig. 2 is just a little higher than 45° (\( 1=\frac{\mathrm{d}\left({\mathrm{lny}}_{\mathrm{t}+\mathrm{s}}\right)}{d\left(\mathit{\ln}{y}_t\right)}=\frac{{\dot{y}}_{t+s}}{y_{t+s}}/\frac{{\dot{y}}_t}{y_t} \)), which suggests that both low- and high-income areas experience economic growth at a relatively high rate, and it shows no sign of decelerating by so far. This means that for both the regions with low GDP and those with high GDP, the probability for them to maintain this acceleration is higher than that to cut their economic growth rate. As a result, the disparity across regions will keep widening, which is in consistent with the result of univariate density estimation. There is a unimodal structure on the projection chart of the growth dynamics of GDP per capita, and this suggests that there is not yet a convergence in the process of growth in provincial GDP per capita in China.

The inter-provincial dynamics of the real GDP per capita (Year 1978–2013), s = 10 and 20
To further test this conclusion, we also conduct bivariate kernel density estimation with longer time spans (10-year and 20-year term, respectively), which yields the same conclusion that there is no multimodal distribution, hence no club convergence. Although there is a tendency of deviation along the periphery of the probability density chart of the 20-year term, there is only one center.
5.4 Detecting the Club Convergence
Given that the foregoing analysis rejects the hypothesis of convergence, it still remains unanswered whether there exists divergence in a general sense or club convergence.
It allows us to determine whether the probability density curve is unimodal or multimodal by using the critical bandwidth (CB) in the kernel density estimation. The CB is expressed as follows:
For instance, when the probability density curve is a mixture distribution composed of m different probability density curves, we can calculate the smallest bandwidth fitting the m modes of the estimated kernel density, namely the critical bandwidth. Additionally in a kernel density estimation of f(x) with a Gaussian kernel, the number of modes is a right-continuous decreasing function of the bandwidth (Silverman 1981). Hence, it is possible for us to use the CB value to find whether there is club convergence or a de-club phenomenon.
Specifically, f(x) is the density of standardized income per capita with at most two modes, and it is observed at two time points, t = 1, 2. The critical bandwidths for unimodality at t = 1 and t = 2 can be calculated as CB1 and CB2, respectively. In such a case, there is club convergence if and only if CB2 > CB1, or de-clubbing if and only if CB2 < CB1.
Furthermore, Silverman proposes a method to test multimodality which depends on the value of Silverman test with the help of a bootstrap procedure. This method can be used to track the changes in the modes of the probability density curve estimated via the kernel density estimation, and determine whether club convergence or de-clubbing trend occurs.
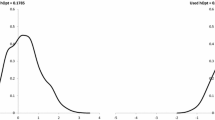
Figure 4 presents the kernel density estimates of the standardized real GDP per capita from 1978 to 2013, where the variance increases over time. Moreover, a peak can be easily observed, and there are some bumps in the tail area, on which we next run the Sliverman multimodality test and calculate the CB value.

Distribution curve of inter-provincial GDP per capita over time (Year 1978–2013)
We calculate the critical bandwidth of the kernel density estimation of the province-level GDP per capita in China from 1978 to 2013. By drawing a bootstrap sample of the China’s provinces including 5000 data points with replacement, we calculate the corresponding Silverman test statistic, where the null hypothesis is that there exists at most one mode. As is shown in Fig. 5, the CB value rises transitorily between 1991 and 1998 from 0.9188 to 1.0476, which results in a short-time multimodality of the distribution of the GDP per capita. This helps explain why some researchers argue that there is club convergence across provinces in China (e.g., Xu and Shu 2005). In contrast, the CB value declines in other time periods, suggesting a de-club status for the provincial real GDP per capita in China. The results of the Silverman test also show that a statistically significant multimodality occurs for the China’s economic growth between 1997 and 2004 (i.e., the p-value of the Silverman multimodality test < 5%). After this time period, this trend inverses, which does not provide support for the club convergence any more.

Critical bandwidth and Silverman modality test (Year 1978–2013)
6 Conclusion
Based on the analytical results, we find that there is no convergence of the provincial economic growth in China, regardless of using univariate or multivariate kernel density estimation.
It is shown by the divergence estimation that the regional economic growth in post-reform China is featured by a considerable level of disparity. Although the overall economy grows rapidly and continuously, the economy of the eastern coastal regions (high-income regions) grows much faster than that of the western regions (low-income regions). Moreover, the differences in growth rate across regions tend to increase. Therefore, there exists no convergence of economic growth across provinces, instead there is a divergence in China.
References
Acemoglu D (2009) Introduction to modern economic growth. MIT Press, Cambridge, MA
Aziz J, Duenwald C (2001) China’s provincial growth dynamics. International Monetary Fund, Washington, DC
Barro RJ, Sala-i-Martin X (1992) Convergence. J Polit Econ 100(2):223–251
Bathelt H, Glückler J (2003) Toward a relational economic geography. J Econ Geogr 3(2):117–144
Boschma RA, Lambooy JG (1999) Evolutionary economics and economic geography. J Evol Econ 9(4):411–429
Caggiano G, Leonida L (2009) International output convergence: evidence from an autocorrelation function approach. J Appl Econ 24(1):139–162
Cai F, Du Y (2000) Convergence and divergence of regional economic growth in China. Econ Res J (in Chinese) 10:30–37
Cai F, Wang D (2002) Comparative advantages: differences, changes and their impact on regional disparity. Soc Sci China (in Chinese) 5:41–54
Caniëls MC, Verspagen B (2001) Barriers to knowledge spillovers and regional convergence in an evolutionary model. J Evol Econ 11(3):307–329
Corrado L, Martin R, Weeks M (2005) Identifying and interpreting regional convergence clusters across Europe. Econ J 115(502):C133–C160
de La Fuente A (2003) Convergence equations and income dynamics: the sources of OECD convergence, 1970–1995. Economica 70:655–671
Fan J (2006) Industrial agglomeration and difference of regional labor productivity: Chinese evidence with international comparison. Econ Res J (in Chinese) 11:72–81
Grabher G (1993) The weakness of strong ties: the lock-in of regional development in the Ruhr area. In: Grabher G (ed) The embedded firm: on the socio-economics of industrial networks. Routledge, London, pp 255–277
Higgins MJ, Levy D, Young AT (2006) Growth and convergence across the United States: evidence from county-level data. Rev Econ Stat 88(4):671–681
Krause M (2015) The millennium peak in club convergence—a new look at distributional changes in the wealth of nations. J Appl Econ 32:621–642. https://doi.org/10.1002/jae.2542
Kremer M, Onatski A, Stock J (2001) Searching for prosperity. Carn-Roch Conf Ser Public Policy 55(1):275–303
Laursen K (2000) Do export and technological specialisation patterns co-evolve in terms of convergence or divergence? Evidence from 19 OECD countries, 1971–1991. J Evol Econ 10(4):415–436
Ou X, Shen Z, Wang R (2006) Spatial structure evolution of regional economic growth and its inequality in China since 1978. Sci Geogr Sin (in Chinese) 26(6):641–648
Pittau MG, Zelli R (2006) Empirical evidence of income dynamics across EU regions. J Appl Econ 21(5):605–628
Quah DT (1996) Convergence empirics across economies with (some) capital mobility. J Econ Growth 1(1):95–124
Quah DT (2002) Spatial agglomeration dynamics. Am Econ Rev 92(2):247–252
Scott DW (1992) Multivariate density estimation: theory, practice and visualization. Wiley, New York
Shi X, Zhao S (2011) The regional economic convergence and its mechanism in China: 1978–2009. J Quant Tech Econ (in Chinese) 1:51–62
Silverman BW (1981) Using kernel density estimates to investigate multimodality. J R Stat Soc Ser B Methodol 43(1):97–99
Wang X, Fan W (2004) Analysis on the regional disparity in China and the influential factors. Econ Res J (in Chinese) 1:33–44
Weißbach R, Gefeller O (2004) A rule-of-thumb for the variable bandwidth selection in kernel hazard rate estimation. Technical Report//Universität Dortmund, SFB 475 Komplexitätsreduktion in Multivariaten Datenstrukturen
Wu Y (2006) A spatial econometric analysis of China’s provincial economic growth convergence. J Quant Tech Econ (in Chinese) 12:101–108
Xu X, Li X (2004) Convergence in Chinese cities. Econ Res J (in Chinese) 5:40–48
Xu X, Shu Y (2005) Physical capital, human capital, and regional twin-peak convergence in China. J World Econ (in Chinese) 28(1):47–57
Yan P, Wang B (2004) Technical efficiency, technical progress & productivity growth: an empirical analysis based on DEA. Econ Res J (in Chinese) 12:55–65
Young AT, Higgins MJ, Levy D (2008) Sigma convergence versus beta convergence: evidence from US county-level data. J Money Credit Bank 40(5):1083–1093
Zhang H (2004) The application of the augmented Solow model diversities and convergence among Chinese provinces. China Econ Q (in Chinese) 3(3):605–618
Zhang X, Gui B (2008) The analysis of total factor productivity in China: a review and application of Malmquist index approach. J Quant Tech Econ (in Chinese) 6:111–122
Zou W, Zhou H (2007) The estimation and analysis on the China’s inter-provincial growth disparities (1978–2002): an empirical study based on the counterfactual income approach. Manage World (in Chinese) 7:37–46
Acknowledgements
The authors would like to thank the anonymous reviewers for their constructive and helpful comments on an earlier draft of this paper. The authors are grateful for the financial support from the National Natural Science Foundation of China, No. 71473169, No. 716731947 and No. 71473168 for Xiang Deng, No. 71402151 for Jing Song, and the Humanities and Social Sciences of Ministry of Education in China (No. 13XJA790002) for Jianping Li.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this chapter
Cite this chapter
Deng, X., Li, J., Song, J. (2017). Convergence or Divergence: A Nonparametric Analysis on China’s Regional Disparity. In: Pyka, A., Cantner, U. (eds) Foundations of Economic Change. Economic Complexity and Evolution. Springer, Cham. https://doi.org/10.1007/978-3-319-62009-1_6
Download citation
DOI: https://doi.org/10.1007/978-3-319-62009-1_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-62008-4
Online ISBN: 978-3-319-62009-1
eBook Packages: Economics and FinanceEconomics and Finance (R0)