
Abstract
In recent years social networks have increasingly been used to study political opinion formation, monitor electoral campaigns and predict electoral outcomes as they are able to generate huge amount of data, usually in textual and non structured form. In this paper we aim at collecting and analysing data from Twitter posts identifying emerging patterns of topics related to a constitutional referendum that recently took place in Italy to better understand and nowcast its outcome. Using the Twitter API we collect tweets expressing voting intentions in the four weeks before the elections obtaining a database of approximately one million tweets. We restrict the data collection to tweets that contain hashtags referring to the referendum, therefore we are sure to include in the analysis only relevant text. On this huge volume of data, we perform a topic modelling analysis using a Latent Dirichelet Allocation model (LDA) to extract frequent topics and keywords. Analysing the behaviour of frequent words we find that connected to voting in favour of the constitutional reform there are positive words such as future and change while connected to voting against it there are words such ad fear and risk.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Twitter is a social network for microblogging where users can exchange short messages of 140 characters called “tweets”. It has approximately 1.3 billion users worldwide and 320 million active users per month. One of the most significant benefits of social media like Twitter is the capacity to generate a huge amount of data, enabling better predictive modelling. Through social interaction tracking and analysis, the data can be used to find out patterns and trends leading to some conclusions with prediction purposes related to several different areas like consumer behaviours, business decisions, or election results. Two of the main advantages that social networks offer are that data is freely available on the web and they allow to monitor users’ opinion and preferences almost real-time. As a consequence, the use of Twitter to monitor political opinion formation and predict electoral outcomes has increasingly gained attention in the last decade. A large number of studies analyse the use of social media as devices to assess the popularity of politicians (Gloor et al. 2009), track political alignment and produce forecasts of election results (Ribeiro Soriano et al. 2012). Some of these works rely on very simple techniques, focusing on the volume of data related to parties or candidates. Others have tried to improve this stream of research by means of sentiment analysis, as understanding the opinion of potential voter trough social media can allow to target political campaigns and improve election forecasts. In this respect, the analysis of online sentiment has for example been used for event-monitoring, where the aim is to monitor reactionary content in social media during a specific event such as a political speech or debate of an influential politician. An example is the work of Diakopoulos and Shamma (2010), who characterised the 2008 US presidential debate in terms of Twitter sentiment. Tumasjan et al. (2010) is another example where the authors use sentiment analysis from social networks to monitor German federal election that took place in 2009. They found that the share of volume on Twitter accurately reflected the distribution of votes in the election between the six main parties. Our work is also related to the one of Bermingham and Smeaton (2011), where the authors use a recent Irish General Election as a case study for investigating the potential to model political sentiment through mining of social media. Their approach combines sentiment analysis, using supervised learning, and volume-based measures. They evaluate their results against the conventional election polls and find that social analytics using both volume-based measures and sentiment analysis are good predictors of election outcomes. For a recent review of state-of-the-art related literature see Ceron et al. (2015). Our contribution consists in collecting and analysing Twitter data related to a referendum that recently took place in Italy, where voters were asked whether to approve a constitutional reform that would change the distribution of powers between the state and the regions. In particular we monitored Twitter posts related to the referendum and classified them as either in favour or against the reform. We use a topic modelling analysis, and in particular we estimate a Latent Dirichelet Allocation model (LDA) to identify main topics and keywords used to discuss the referendum in the four weeks before the vote took place. Moreover, we monitor voting intentions of users and use the total volumes of tweets to predict the outcome of the referendum.
The paper is organized as follows: Sect. 2 describes the data collection process and the dataset, Sect. 3 present results on the topic modelling and frequent term analysis and Sect. 4 presents some concluding remarks.
2 The Dataset
Our research concerns the constitutional referendum took place in Italy on December 4th 2016. We recorded tweets between November 9th and December 12th, approximately four weeks before and one after the vote, building a new database containing a total of 1.020.844 tweetsFootnote 1 As it is commonly done in the literature, we decided to collect and analyse only posts containing specific hashtags. These are a sort of labels used in social networks that allow users to find information on a specific topic or content. To decide which hashtags to include in our analysis we monitored Twitter posts talking about the referendum, but also other media such as newspapers, television programs and the national news. We collected all tweets containing the following five hashtags: #referendumcostituzionale, #iovotono, #bastaunno, #iovotosi, #bastaunsi.

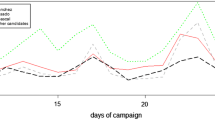
Total Twitter volumes (black line) and volumes divided by pro and against the referendum. Total Twitter volumes (black line) and volumes divided by pro and against the referendum.
Figure 1 reports the volume of collected tweets. Dates are on the x-axis and the number of tweets is on the y-axis; the analysed period is from November 9th to December 12th and the dashed vertical line corresponds to December 4th, the day of the elections. The black time series gives an idea of the total number of tweets related to the referendum, as each data-point is the daily sum of the five hashtags: #referendumcostituzionale, #iovotosi, #iovotono, #bastaunsi, #bastaunno. On November 9th, when we start monitoring tweets, the total number of tweets is approximately 20.000 while on the election day, tweets talking about the referendum reach 100.000. The blue line corresponds to the sum of the number of tweets containing the hashtags #iovotosi and #bastaunsi while the red line is the daily total number of tweets with the hashtags #iovotono and #bastaunno. As shown in the plot, the red time series is always above the blue one, showing that most of Twitter users are against the constitutional reform. On December 2nd the total number of tweets pro constitutional reform is 23.670 while the total number of tweets against it is 38.402, which corresponds to 62%.
3 Topic Modelling Analysis and Frequent Terms
To analyse the text and terms contained in the tweets, we apply a topic modelling analysis allowing the probabilistic modelling of term frequency occurrences in documents. These models extend classical methods in natural language processing such the unigram model and the mixture of unigram models (Nigam et al. 2000) or the Latent Semantic Analysis (Deerwester et al. 1990). An introduction to topic models is given in Steyvers and Griffiths (2007) and Blei and Lafferty (2009). In particular, in our analysis we use the Latent Dirichlet Allocation model, henceforth LDA, that is a Bayesian mixture model for discrete data where topics are assumed to be uncorrelated. We fit this model using the R package topicmodels, that provides codes to fit an LDA model using a variational expectation-maximization (VEM) algorithm as implemented by Blei et al. (2003); for all the details see Hornik and Grün (2011). Figure 2 shows the result of the estimation of an LDA model obtained using the document-term matrix in the time period from November 9th to December 12th.

Topic modelling analysis using a Latent Dirichelet Allocation model (LDA).
We run several different configurations models and we choose to present the results using 6 topics, and the 7 most likely terms for each of them. As we can see from the plot, there are two peaks on November 14th and 21st, and a major one in all topics in the days immediately before the election; this simply reflects the fact that there is a “last minute” boom of users discussing about the elections. Note that many words are present in more than one topic, while the hastag “iovotono” is in all the topics, confirming that most tweets are against the constitutional reform. Then we focus on tweets containing the hashtags #bastaunsi, #iovotosi, #bastaunno and #iovotono and we build two distinct term-document matrices, one for positive and one for negative tweets, allowing us to register the frequency of words in the tweets; terms with less than three characters are discarded. Figure 3 plots the most frequent words contained in the tweets with the hashtags #bastaunsi and #iovotosi and #bastaunno and #iovotono, respectively on the left and on the right; the frequency of terms is displayed in percentage terms. Analysing the most frequent words an interesting pattern emerges. Most of the words connected to #bastaunsi and #iovotosi, in favour of the constitutional reform, are terms connected to positive and optimistic sentiments. For example, frequent words are change, future and pride, respectively cambiare, futuro and orgoglio, while on the other hand words in the tweets containing the hastags #bastaunno and #iovotono are linked to negative sentiments such as risk, danger and complaint, respectively rischio, pericolo and denuncia. We studied the importance of words contained in the tweets using different visualization methods (as for example tag clouds in which the displayed size of words is proportional to their frequency) but we omit these plots for lack of space as they convey the same message displayed in the previous barplots.

Most frequent words contained in the tweets containing the hashtags #bastaunsi and #iovotosi (left) and #bastaunno and #iovotono (right).
Furthermore, we use the percentage of tweets against the constitutional reform as a rough estimate of the outcome of the referendum. The actual outcome of the referendum was 59% against the constitutional reform and 41% in favour of it, therefore the reform was not implemented. We notice that using the volumes of tweets as proxies of votes we are correctly able to predict the election results. In fact, on December 2nd, the day with the highest number of tweets, we calculate that the share of tweets against the reform was 62%, producing a prediction error of only 3%.
4 Concluding Remarks
In this paper we use a newly constructed database to analyse Twitter posts and confirm the ability of social media to nowcast the electoral campaign and to forecast electoral results. Analysing Twitter posts related to a constitutional reform that recently took place in Italy, we perform a topic modelling analysis using a Latent Dirichelet Allocation model to track the main topics and keywords during the electoral campaign. From the analysis we are able to find out words with topics revealing sentiments related either with the positive or the negative results. In particular we can see an interesting pattern emerging from the analysis of the most frequent words, namely the positive and optimist sentiments related with the yes, and the negative sentiments related with the no. As future researches, these patterns can be analysed in comparison with the volume of Twitter posts, which has been used before the referendum to correctly predict the outcome of the elections. Finally, we are aware that these results should be taken as suggestive rather than conclusive and using Twitter volumes as a proxi of votes is a very simple measure; one of the main problems is that we need to rely on a representative sample and the population of Twitter users does not necessarily match the population of voters. Despite the limits of using Twitter to predict electoral outcomes, we believe our results provide reasons to be optimistic about the capability of social networks to become a useful tool to monitor, analyse and predict public opinion formation, as a supplement to traditional off-line tools.
Notes
- 1.
We collected this information using the Twitter API trough the R package twitteR. The R package used is available at the following link: https://cran.r-project.org/web/packages/twitteR/index.html.
References
Bermingham, A., Smeaton, A.F.: On using twitter to monitor political sentiment and predict election results (2011)
Blei, D.M., Lafferty, J.D.: Topic models. Text Mining Classif. Clustering Appl. 10(71), 34 (2009)
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent dirichlet allocation. J. Mach. Learn. Res. 3, 993–1022 (2003)
Ceron, A., Curini, L., Iacus, S.: Using social media to fore-cast electoral results: a review of state-of-the-art. Ital. J. Appl. Stat. 25(3), 237–259 (2015)
Deerwester, S., Dumais, S.T., Furnas, G.W., Landauer, T.K., Harshman, R.: Indexing by latent semantic analysis. J. Am. Soc. Inform. Sci. 41(6), 391 (1990)
Diakopoulos, N.A., Shamma, D.A.: Characterizing debate performance via aggregated twitter sentiment. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, pp. 1195–1198. ACM (2010)
Gloor, P.A., Krauss, J., Nann, S., Fischbach, K., Schoder, D.: Web science 2.0: Identifying trends through semantic social network analysis. In: International Conference on Computational Science and Engineering, CSE 2009, vol. 4, pp. 215–222. IEEE (2009)
Hornik, K., Grün, B.: topicmodels: an r package for fitting topic models. J. Stat. Softw. 40(13), 1–30 (2011)
Nigam, K., McCallum, A.K., Thrun, S., Mitchell, T.: Text classification from labeled and unlabeled documents using em. Mach. Learn. 39(2–3), 103–134 (2000)
Ribeiro Soriano, D., Garrigos-Simon, F.J., Lapiedra Alcamí, R., Barberá Ribera, T.: Social networks and web 3.0: their impact on the management and marketing of organizations. Manag. Decis. 50(10), 1880–1890 (2012)
Steyvers, M., Griffiths, T.: Probabilistic topic models. Handb. Latent Semant. Anal. 427(7), 424–440 (2007)
Tumasjan, A., Sprenger, T.O., Sandner, P.G., Welpe, I.M.: Predicting elections with twitter: what 140 characters reveal about political sentiment. In: ICWSM, vol. 10(1), pp. 178–185 (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG
About this paper
Cite this paper
Fano, S., Slanzi, D. (2018). Using Twitter Data to Monitor Political Campaigns and Predict Election Results. In: De la Prieta, F., et al. Trends in Cyber-Physical Multi-Agent Systems. The PAAMS Collection - 15th International Conference, PAAMS 2017. PAAMS 2017. Advances in Intelligent Systems and Computing, vol 619. Springer, Cham. https://doi.org/10.1007/978-3-319-61578-3_19
Download citation
DOI: https://doi.org/10.1007/978-3-319-61578-3_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-61577-6
Online ISBN: 978-3-319-61578-3
eBook Packages: EngineeringEngineering (R0)