
Abstract
Many advanced automated systems have been proposed for the diagnosis of Alzheimer’s Disease (AD). Most of them use Magnetic Resonance Imaging (MRI) as input data, since it provides high resolution images of the structure of the brain. Usually, Computer Aided Diagnosis (CAD) systems are based on massive univariate test and classification, although many strategies based on signal decomposition have been proposed for feature extraction in MRI images. In this work, we propose a novel analysis technique comprising the texture analysis of different cortical and subcortical structures in the brain. The procedure shows promising results, achieving up to 81.3% accuracy in the diagnosis task, and up to 79.6% accuracy using only one texture measure at the most discriminant region. These results prove the ability of textural analysis in the characterization of structural neurodegeneration of the brain, and paves the way to future longitudinal and conversion analyses.
Data used in preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (https://adni.loni.usc.edu). As such, the investigators within the ADNI contributed to the design and implementation of ADNI and/or provided data but did not participate in analysis or writing of this report. A complete listing of ADNI investigators can be found at: http://adni.loni.usc.edu/wp-content/uploads/how_to_apply/ADNI_Acknowledgement_List.pdf.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others
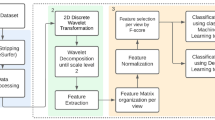


1 Introduction
Alzheimer’s Disease (AD) is the most common neurodegenerative disorder in the world, with more than 46 million people affected [2]. With the current population ageing in developed countries, this number is expected to increase up to 131.1 millions by 2050 [2]. Therefore, an early diagnosis is needed for an early intervention and improving the life expectancy and quality of life of the affected subjects and their families.
Currently, one of the most extended techniques to explore neurodegeneration in AD is Magnetic Resonance Imaging (MRI). It provides us a non-invasive tool to explore the internal structure of the brain and the distribution of Gray Matter (GM) and White Matter (WM), which usually has a correlation with neurodegeneration [3, 11], in contrast to other neuroimaging modalities, such as Single Photon Emission Computed Tomography (SPECT) or Positron Emission Tomography (PET), which require the injection of a radiopharmaceutical. Analysis of these images is usually performed visually or using semiquantitative tools to assess the degree of neurodegeneration.
In contrast to traditional visual and semiquantitative analysis of images, many fully automated systems for analysing MRI images have been proposed. Apart from the widely extended Voxel Based Morphometry (VBM) [3], numerous feature extraction algorithms have been proposed. Some recent approaches include decomposition via Principal Component Analysis (PCA) [8, 25], Independent Component Analysis (ICA) [17], Partial Least Squares (PLS) [22], or projecting information of the brain to a bidimensional plane using Spherical Brain Mapping (SBM) [14, 18]. In a recent review [10], a wide variety of algorithms using shape, volume and texture analysis were reported for the diagnosis of AD. Of these, texture analysis has already been used in the analysis of neuroimaging of different modalities with great success [13, 16, 28].
In this work, we propose a system that combines brain region segmentation of T1-weighted images using a strategy based on atlas masking, and a posterior texture analysis of each region. These features extracted at each region are used to quantify which combination of measures and regions are useful to characterize neurodegeneration in AD.
This article is organized as follows. First, the methodology used to analyse MRI images, and evaluate our system is detailed in Sect. 2. Later, in Sect. 3, the results are presented. Finally, we draw some conclusions about our system at Sect. 4.
2 Methodology
2.1 Atlas Segmentation
In our work we wanted to test the hypothesis that structural changes in different areas of the brain can predict changes in neurodegeneration, and therefore, be related to Alzheimer’s Disease (AD). We will compute the structural changes at different regions using a naive atlas segmentation.
Atlas segmentation is a technique that uses a brain atlas, such as the Automated Anatomical Labelling (AAL) [26], the Montreal Neurological Institute (MNI) or IBASPM [1], to mask out different regions in images registered to the same space. Since in our case, T1-weighted images are registered to the MNI space, we have applied the IBASPM atlas to extract regions to which a subsequent texture analysis has been applied.
The IBASPM atlas consist of 90 cortical and subcortical regions divided by hemisphere, that have been set using three elements: gray matter segmentation, normalization transform matrix (the matrix used to map voxels from individual to the MNI space) and the MaxPro MNI atlas (Fig. 1).

Some axial cuts of the IBASPM atlas.
2.2 Haralick Texture Analysis
Texture analysis is usually based on the computation of a Gray-Level Co-occurrence (GLC) matrix. This matrix is defined over an image to be the distribution of co-occurring values at a given offset. Mathematically, we can define the co-occurrence matrix over a \(n\times m\) bidimensional image \(\mathbf {I}\) as:
where i and j are the different gray levels. For simplicity, the image is usually quantized to \(N_g\) gray levels. In this work we have used \(N_g=16\).
The parametrization of the GLC matrix using the offsets (\(\varDelta x, \varDelta y\)) can make it sensitive to rotation. Therefore, we will use different offsets at different angles to get to some degree of rotational invariance. For simplicity, we will use the same distance d in all directions, and therefore, we can rewrite the offset vector \(\varDelta _\mathbf {p}\) as:
Using this parametrization, it is easy to expand the GLC matrix to a three-dimensional image \(\mathbf {I}\) of size \(n\times m\times k\), parametrized this time by a 3D offset [20]:
We use thirteen spatial directions to compute every GLCM in the 3D space [20]. In this work we will use \(d=\lbrace 1, 2, 3\rbrace \), and therefore, \(3\times 13=39\) GLC matrices will be computed for each region. To extract features from these GLC matrices, let us define the probability matrix \(\mathbf {P}\) as:
With this new matrix of probabilities, we can compute the thirteen Haralick Texture measures that were defined in the original Haralick paper [7], with the following expressions:
where \(f_1\) is the Angular Second Moment (ASM), \(f_2\) is Contrast, \(f_3\) is Correlation, \(f_4\) is Sum of Squares: Variance, \(f_5\) is the Inverse Difference Moment, \(f_6\) is the Sum Average, \(f_7\) is the Sum Variance, \(f_8\) is Sum Entropy, \(f_9\) is Entropy, \(f_{10}\) is Difference Variance and \(f_{11}\) is Difference Entropy.
For the last two texture measures, \(f_{12}\) and \(f_{13}\), let us define:
Let us also note \(H_X\) and \(H_Y\) the entropies of \(p_x\) and \(p_y\) respectively, and:
where \(H_{XY}\) is their joint entropy, \(H_{XY1}\) and \(H_{XY2}\) would be the join entropy of X and Y assuming independent distributions.
With all these notations, the last two measures, known as Information Measures of Correlation (IMC-1 and IMC-2) can be defined as:
and \(f_{12}\) and \(f_{13}\) are Information Measures of Correlation (IMC-1 and IMC-2).
Having 39 GLC matrices per region from which 13 measures are computed, we will obtain 507 measures per region, and having 90 region, this makes a total of 45630 measures per patient. In one of the experiments, we have used all these measures in the classification task, therefore a strategy to perform feature selection is desired.
2.3 Feature Selection
Different feature selection methods have been proposed throughout the literature [15]. These methods use statistical measures to assess significance of the Haralick measures. To do so, either a parametrical or empirical approach can be used. In this work, we have used both approaches.
For the parametrical approach, the widely known independent two-sample t-test has been used. This test computes the t-statistic for each element in the feature vector, and then, its statistical significance can be estimated by using the t-distribution. The t-statistic is computed as:
where \(\sigma _{X_i}^2\) is the variance and \(\bar{X}_i\) is the average within class i.
On the other hand, we can use the Kullback-Leibler (KL) divergence to assess statistical significance, by computing the KL measure as in [24]:
and then perform a battery of permutation tests so that we can obtain the empirical distribution of the KL values for each feature, from which the p-values can be obtained.
2.4 Database and Preprocessing
Data used in the preparation of this article were obtained from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database (https://adni.loni.usc.edu). The ADNI was launched in 2003 as a public-private partnership, led by Principal Investigator Michael W. Weiner, MD. The primary goal of ADNI has been to test whether serial magnetic resonance imaging (MRI), positron emission tomography (PET), other biological markers, and clinical and neuropsychological assessment can be combined to measure the progression of mild cognitive impairment (MCI) and early Alzheimers disease (AD). For up-to-date information, see www.adni-info.org.
The database used in this article was extracted from the ADNI1: Screening 1.5T (subjects who have a screening data) and contains 1075 T1-weighted MRI images, comprising 229 NOR, 401 MCI and 188 AD images. In this work, only the first session of 188 AD and 229 subjects was used. The images were spatially normalized using the SPM software [6], after a skull removing procedure.
2.5 Evaluation
We have evaluated the texture measures by means of a classification analysis. In this analysis, different sets of measures from the train set are used to train a Support Vector Classifier (SVC) [27], and performance results are estimated by testing the SVC with the test set. In this work, we have used a 10-Fold cross validation strategy [9]. In this strategy, we divide the whole dataset in 10 parts (folds), and each of them are used as a test set to the SVC when training with the remaining 9. The procedure is repeated 10 times and performance values of accuracy, sensitivity and specificity (and their corresponding standard deviations) are obtained.
We have evaluated our system in two different experiments:
-
Experiment 1: We test our system with only one feature at a time, and evaluate the performance obtained with that feature. Each feature is one texture measure at a certain distance and offset for a given region. From these performance values, we can obtain an estimation of which texture measures provide a higher discrimination.
-
Experiment 2: We pool together all values measures computed in all regions, in all directions and offset vectors. Then, we apply hypothesis testing to select the most significant measures at different p thresholds.
3 Results and Discussion
3.1 Experiment 1
Multiple performance results (90 regions, 13 texture measures, 13 offset and 3 distances) have been computed for this experiment. We cannot detail all 45630 accuracy, sensitivity or specificity values, but we examine the distribution of those using a boxplot.

Boxplot of the distribution of the accuracies obtained using all texture measures in each region.
In Fig. 2, we show a boxplot of the distribution of the accuracy values obtained using all texture measures in each region. We can see that higher performance is obtained at the Hippocampus and surrounding regions, especially at the right Hippocampus. The parahippocampal lobes and amygdalas (especially the left amygdala) get notable results. The hippocampal and parahippocampal lobes have received high interest in the literature, since it plays a relevant role in memory. Particularly, Gray Matter loss due to neurodegeneration has been consistently reported in many works [4, 5]. This neurodegeneration probably leads to a change in some of the texture measures used here, therefore, it reveals the usefulness of texture measures in the parametrization of AD.
We will focus then on the analysis of which texture measures perform better within the Hippocampus, our area of interest. For this purpose, we pool again the performance values obtained at the right Hippocampus and plot them at Fig. 3 after grouping them by texture measure.

Boxplot of the distribution of the accuracies obtained using different texture measures at the Hippocampus R.
In Fig. 3, one measure clearly stands out: Angular Second Moment. Other measures such as Inverse Difference Moment and Entropy obtain good, although more variable, performance.
3.2 Experiment 2
In this experiment, we test the performance that can be achieved using all measures and selecting the most significant ones by means of a hypothesis test. We have used two different strategies to assess significance: the Student’s t-test and the Kullback-Leibler (KL) divergence. Table 1 displays the values obtained for the different strategies, compared to the performance of using all measures computed at the right Hippocampus.
We can se that the selection improves the system’s ability to detect changes related to AD, when compared to using the measures computed at each region, or even using the best measure at the best scoring region.
When compared to a commonly used voxel-wise baseline, Voxels As Features (VAF) [23], we can see that it clearly outperforms the typical approach where segmented GM and WM maps are used. When using the whole segmented T1-weighted image, the difference is smaller, although both the system using feature selection and the one using only one texture measure at the hippocampus still achieve better performance, but this time, providing a significant feature reduction of two magnitude orders (from more than half a million voxels to thousands of measures).
These results highlights the prospective of using texture measures to characterize per-region structural changes due to neurodegeneration in MRI images. This is a preliminary analysis of the utility of these texture measures, using the more traditional Haralick texture analysis. Other more advanced techniques have been developed in the late 90s and the 2000s, for example the Local Binary Patterns (LBP) [19], the watershed transform [12] or the orientation pyramid (OP) [21]. These algorithms have previously shown to outperform the Haralick texture features, and are valid candidates to improve AD diagnosis and its possible application to model the progression of AD, which is the real challenge.
4 Conclusions and Future Work
In this work, we have proposed a texture analysis framework for characterizing the structural changes in Alzheimer’s Disease (AD). The preliminary results that we show prove that the texture measures are an excellent descriptor of structural changes in different regions of the brain. The most discriminant regions are located in and surrounding the Hippocampus, and the discrimination accuracy obtained at these regions is close to 80%. On the other hand, we have demonstrated that pooling all the texture measures and selecting the most significant achieves higher performance than any other region by itself, which proves that there exist other regions which could play a significant role in neurodegeneration and can be characterized by texture measures. The system using texture measures provides a significant feature reduction and obtains similar and even higher performance that the common baseline Voxels As Features (VAF). In future works, we will extend this texture analysis with other texture features and apply those to Mild Cognitive Impairment (MCI) affected patients, and see whether these measures can be applied to the prediction of MCI conversion to AD and its progression.
References
Alemán, Y., Melie, L., Valdés, P.: Ibaspm: toolbox for automatic parcellation of brain structures. In: 12th Annual Meeting of the Organization for Human Brain Mapping, pp. 11–15, June 2006
Alzheimer’s Association: 2016 Alzheimer’s disease facts and figures. Alzheimer’s Dement. 12(4), 459–509 (2016)
Ashburner, J., Friston, K.J.: Voxel-based morphometry–the methods. Neuroimage 11(6), 805–821 (2000)
Baron, J.C., Chételat, G., Desgranges, B., Perchey, G., Landeau, B., de la Sayette, V., Eustache, F.: In vivo mapping of gray matter loss with voxel-based morphometry in mild Alzheimer’s disease. Neuroimage 14(2), 298–309 (2001)
Dubois, B., Feldman, H.H., Jacova, C., DeKosky, S.T., Barberger-Gateau, P., Cummings, J., Delacourte, A., Galasko, D., Gauthier, S., Jicha, G., et al.: Research criteria for the diagnosis of Alzheimer’s disease: revising the NINCDS-ADRDA criteria. Lancet Neurol. 6(8), 734–746 (2007)
Friston, K., Ashburner, J., Kiebel, S., Nichols, T., Penny, W.: Statistical Parametric Mapping: The Analysis of Functional Brain Images. Academic Press, Cambridge (2007)
Haralick, R., Shanmugam, K., Dinstein, I.: Textural features for image classification. IEEE Trans. Syst. Man Cybern. 3(6), 610–621 (1973)
Khedher, L., Ramírez, J., Górriz, J., Brahim, A., Segovia, F.: Early diagnosis of Alzheimers disease based on partial least squares, principal component analysis and support vector machine using segmented MRI images. Neurocomputing 151, 139–150 (2015)
Kohavi, R.: A study of cross-validation and bootstrap for accuracy estimation and model selection. In: Proceedings of International Joint Conference on AI, pp. 1137–1145 (1995)
Leandrou, S., Petroudi, S., Kyriacou, P.A., Reyes-Aldasoro, C.C., Pattichis, C.S.: An overview of quantitative magnetic resonance imaging analysis studies in the assessment of Alzheimer’s disease. In: Kyriacou, E., Christofides, S., Pattichis, C.S. (eds.) XIV Mediterranean Conference on Medical and Biological Engineering and Computing 2016. IP, vol. 57, pp. 281–286. Springer, Cham (2016). doi:10.1007/978-3-319-32703-7_56
Lerch, J.P., Pruessner, J.C., Zijdenbos, A., Hampel, H., Teipel, S.J., Evans, A.C.: Focal decline of cortical thickness in Alzheimer’s disease identified by computational neuroanatomy. Cereb. Cortex 15(7), 995–1001 (2005)
Malpica, N., Ortuño, J.E., Santos, A.: A multichannel watershed-based algorithm for supervised texture segmentation. Pattern Recogn. Lett. 24(9), 1545–1554 (2003)
Martinez-Murcia, F., Górriz, J., Ramírez, J., Moreno-Caballero, M., Gómez-Río, M., Initiative, P.P.M., et al.: Parametrization of textural patterns in 123i-ioflupane imaging for the automatic detection of Parkinsonism. Med. Phys. 41(1), 012502 (2014)
Martinez-Murcia, F., Górriz, J., Ramírez, J., Ortiz, A., The Alzheimers Disease Neuroimaging Initiative: A spherical brain mapping of MR images for the detection of Alzheimers disease. Curr. Alzheimer Res. 13(5), 575–588 (2016)
Martínez-Murcia, F., Górriz, J., Ramírez, J., Puntonet, C., Salas-González, D.: Computer aided diagnosis tool for Alzheimer’s disease based on Mann-Whitney-Wilcoxon U-test. Expert Syst. Appl. 39(10), 9676–9685 (2012)
Martinez-Murcia, F.J., Ortiz, A., Górriz, J.M., Ramírez, J., Illán, I.A.: A volumetric radial LBP projection of MRI brain images for the diagnosis of Alzheimer’s disease. In: Ferrández Vicente, J.M., Álvarez-Sánchez, J.R., de la Paz López, F., Toledo-Moreo, F.J., Adeli, H. (eds.) IWINAC 2015. LNCS, vol. 9107, pp. 19–28. Springer, Cham (2015). doi:10.1007/978-3-319-18914-7_3
Martínez-Murcia, F.J., Górriz, J., Ramírez, J., Puntonet, C.G., Illán, I.: Functional activity maps based on significance measures and independent component analysis. Comput. Methods Programs Biomed. 111(1), 255–268 (2013)
Martínez-Murcia, F.J., Górriz, J.M., Ramírez, J., Alvarez Illán, I., Salas-González, D., Segovia, F., A.D.N.I.: Projecting MRI brain images for the detection of Alzheimer’s disease. Stud. Health Technol. Inform. 207, 225–233 (2015)
Ojala, T., Pietikäinen, M., Mäenpää, T.: Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 24(7), 971–987 (2002)
Philips, C., Li, D., Raicu, D., Furst, J.: Directional Invariance of Co-occurrence Matrices within the Liver. In: International Conference on Biocomputation, Bioinformatics, and Biomedical Technologies, pp. 29–34 (2008)
Reyes-Aldasoro, C.C., Bhalerao, A.: The Bhattacharyya space for feature selection and its application to texture segmentation. Pattern Recogn. 39(5), 812–826 (2006)
Segovia, F., Górriz, J., Ramírez, J., Salas-Gonzalez, D., Álvarez, I.: Early diagnosis of Alzheimers disease based on partial least squares and support vector machine. Expert Syst. Appl. 40(2), 677–683 (2013)
Stoeckel, J., Ayache, N., Malandain, G., Koulibaly, P.M., Ebmeier, K.P., Darcourt, J.: Automatic classification of SPECT images of Alzheimer’s disease patients and control subjects. In: Barillot, C., Haynor, D.R., Hellier, P. (eds.) MICCAI 2004. LNCS, vol. 3217, pp. 654–662. Springer, Heidelberg (2004). doi:10.1007/978-3-540-30136-3_80
Theodoridis, S., Pikrakis, A., Koutroumbas, K., Cavouras, D.: Introduction to Pattern Recognition: A Matlab Approach. Academic Press, Cambridge (2010)
Towey, D.J., Bain, P.G., Nijran, K.S.: Automatic classification of 123I-FP-CIT (DaTSCAN) SPECT images. Nucl. Med. Commun. 32(8), 699–707 (2011)
Tzourio-Mazoyer, N., Landeau, B., Papathanassiou, D., Crivello, F., Etard, O., Delcroix, N., Mazoyer, B., Joliot, M.: Automated anatomical labeling of activations in SPM using a macroscopic anatomical parcellation of the mni MRI single-subject brain. Neuroimage 15(1), 273–289 (2002)
Vapnik, V.N.: Statistical Learning Theory. Wiley, New York (1998)
Zhang, J., Yu, C., Jiang, G., Liu, W., Tong, L.: 3D texture analysis on MRI images of Alzheimers disease. Brain Imaging Behav. 6(1), 61 (2012)
Acknowledgements
This work was partly supported by the MINECO/ FEDER under the TEC2015-64718-R project and the Consejería de Economía, Innovación, Ciencia y Empleo (Junta de Andalucía, Spain) under the Excellence Project P11-TIC- 7103.
Data collection and sharing for this project was funded by the Alzheimer’s Disease Neuroimaging Initiative (ADNI) (National Institutes of Health Grant U01 AG024904) and DOD ADNI (Department of Defense award number W81XWH-12-2-0012). ADNI is funded by the National Institute on Aging, the National Institute of Biomedical Imaging and Bioengineering, and through generous contributions from the following: AbbVie, Alzheimer’s Association; Alzheimer’s Drug Discovery Foundation; Araclon Biotech; BioClinica, Inc.; Biogen; Bristol-Myers Squibb Company; CereSpir, Inc.; Cogstate; Eisai Inc.; Elan Pharmaceuticals, Inc.; Eli Lilly and Company; EuroImmun; F. Hoffmann-La Roche Ltd and its affiliated company Genentech, Inc.; Fujirebio; GE Healthcare; IXICO Ltd.; Janssen Alzheimer Immunotherapy Research & Development, LLC.; Johnson & Johnson Pharmaceutical Research & Development LLC.; Lumosity; Lundbeck; Merck & Co., Inc.; Meso Scale Diagnostics, LLC.; NeuroRx Research; Neurotrack Technologies; Novartis Pharmaceuticals Corporation; Pfizer Inc.; Piramal Imaging; Servier; Takeda Pharmaceutical Company; and Transition Therapeutics. The Canadian Institutes of Health Research is providing funds to support ADNI clinical sites in Canada. Private sector contributions are facilitated by the Foundation for the National Institutes of Health (www.fnih.org). The grantee organization is the Northern California Institute for Research and Education, and the study is coordinated by the Alzheimers Therapeutic Research Institute at the University of Southern California. ADNI data are disseminated by the Laboratory for Neuro Imaging at the University of Southern California.
Author information
Authors and Affiliations
Consortia
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Martinez-Murcia, F.J. et al. (2017). Evaluating Alzheimer’s Disease Diagnosis Using Texture Analysis. In: Valdés Hernández, M., González-Castro, V. (eds) Medical Image Understanding and Analysis. MIUA 2017. Communications in Computer and Information Science, vol 723. Springer, Cham. https://doi.org/10.1007/978-3-319-60964-5_41
Download citation
DOI: https://doi.org/10.1007/978-3-319-60964-5_41
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-60963-8
Online ISBN: 978-3-319-60964-5
eBook Packages: Computer ScienceComputer Science (R0)