
Abstract
Dermoscopic images are useful tools towards the diagnosis and classification of skin lesions. One of the first steps to automatically study them is the reduction of noise, which includes bubbles caused by the immersion fluid and skin hair. In this work we provide an effective hair removal algorithm for dermoscopic imagery employing soft color morphology operators able to cope with color images. Our hair removal filter is essentially composed of a morphological curvilinear object detector and a morphological-based inpainting algorithm. Our work is aimed at fulfilling two goals. First, to provide a successful yet efficient hair removal algorithm using the soft color morphology operators. Second, to compare it with other state-of-the-art algorithms and exhibit the good results of our approach, which maintains lesion’s features.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Malignant melanoma, or simply melanoma, is the most dangerous form of skin cancer. Although it only represents 4% of all skin cancers, it causes the 80% of deaths related to skin cancer. In Spain, approximately 5000 new patients are diagnosed each year, which is a quantity increasing around 7% yearly [5].
Dermoscopic imagery is a non-invasive and effective tool towards the clinical diagnosis of skin lesions, both for superficial spreading ones but also in the case of vertically growing melanomas [1]. Such images are acquired with a dermatoscope, which is a camera specially designed to capture small regions and to avoid the reflection of light on the skin surface. The former is achieved with appropriate optics, whereas the latter is typically attained with polarized or non-polarized light and an immersion fluid (e.g. alcohols or mineral oil). Computer-aided image analysis technologies can be leveraged to design diagnosis support tools and thus help practitioners. In this way, a variety of techniques have been proposed to remove hair form dermoscopic images. One of such algorithms is Dullrazor [8] that uses top hat transforms and bilinear interpolation to remove hair. Another state-of-the-art algorithm is presented in [11] in which Canny edge detector jointly with coherence transport inpainting are used. In this paper, we present an effective hair removal algorithm employing soft color morphology operators. This novel algorithm is compared with the aforementioned two algorithms exhibiting good results, removing hair effectively while maintaining lesion’s features.
2 Soft Color Morphology
Mathematical morphology has been widely used since its introduction by Serra and Matheron due to their satisfactory trade-off among expressive power and efficiency [10]. Initially designed to deal with binary images, it was promptly extended to grayscale images. Along with the CIELab color space, the soft color morphology operators are designed to be coherent with human color perception and to avoid generating colors whose chroma is different to that of any color already present in the image. Due to its nature, these operators process the image as a whole rather than as a number of independent channels.
Our operators are designed using fuzzy logic operators. In particular, they employ conjunctions [3] and fuzzy implication functions [2]. They also use a structuring element B, which can be represented as a grayscale image. In this work, we always consider that, in the origin B(0), its value is always 1.
We can now formally introduce the basic operators of the Soft Color Morphology. They are the soft color dilation and the soft color erosion:
Definition 1
Let C be a conjunction, let I be a fuzzy implication function, let A be a multivariate image and let B be a structuring element. Then, the soft color dilation of A by B, \(\mathcal {D}_C(A,B)\), is
and the soft color erosion of A by B, \(\mathcal {E}_I(A,B)\), is
The maximum or minimum may not be unique, and so ties are resolved by choosing the candidate with the nearest location (i.e. the x such that the Euclidean distance d(x, y) is minimum), and resolve any further ties with the lexicographical order.
Given these two definitions, we define the closing, opening and black top-hat with the straightforward generalization of the same operators for binary images [10], where the difference has been generalized to the Euclidean distance between colors.
These mathematical morphology operators generalize the ones of the fuzzy mathematical morphology [7]. Besides, these operators preserve the chromatic components of L*a*b*-encoded images, and also preserve colors in any color space when, essentially, the structuring element is a binary image [4].
3 Hair Removal Algorithm
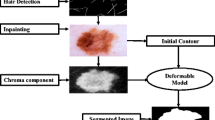
In this section, we introduce the hair removal algorithm and its main steps: a curvilinear object detector for color images and an inpainting algorithm also for color images.
The curvilinear object detector is based on a combination of soft color top-hat transforms. We leverage the appearance of hairs in dermoscopic images by fine-tuning the orientations and size of the structuring elements. Hairs appear as thin, elongated regions with clearly differentiated photometric features than those of its local background, which is non-uniform. More specifically, they are darker than the background, with possible brighter surroundings due to noise in acquisition and to lossy image formats. Besides, their width usually ranges between 4 and 9 pixels and the ratio of hair pixels can range from 0% to almost 40%. The black top-hat, or top-hat by closing, extracts exactly those objects.
The detector \(\mathcal {CD}\), visually depicted in Fig. 1, is defined as:

Workflow of the curvilinear object detector.
where the parameters used are the minimum operator as conjunction \(C(x,y) = \min (x, y)\); and its residuated implication, the Gödel implication \(I = I_\mathbf{GD }\) [2], and \(\alpha \in \{0{}^\circ , 22.5{}^\circ , 45{}^\circ \ldots , 157.5{}^\circ \}\) ranges over different orientations of the structuring element \(B_\alpha \). All of the structuring elements \(B_\alpha \) are bar-like shapes with a Gaussian decayment enclosed in a squared region. We remark that the maximum of the transforms recovers both isolated regions and thin regions, whereas the minimum only recovers isolated areas. We consider structuring elements at 8 different orientations enclosed in \(9 \times 9\) regions.
The inpainting method for color images based on the soft color morphology operators is inspired in the grayscale filter presented in [6]. The inpainting procedure rewrites the pixels that are missing (denoted by the symbol \(\bot \)) as soon as enough information is available, while always maintains pixels whose value is already known. More formally, the iterative inpainting of an image \(A_1\) is defined as the limiting case of the following series:
where \(B_5\) is a \(5\times 5\), flat, rounded structuring element. We also remark that the dilation and erosion from Definition 1 are slightly modified to handle images with missing pixels: they ignore them and output missing if there is possible candidate.
Once the two main building blocks have been introduced, the complete hair removal algorithm is presented. The course of the algorithm, composed by a series of sequential operations, is presented as follows. The image is converted into L*a*b* and is divided by 100. The channel L* is preprocessed with the CLAHE [12], which increases the contrast with a histogram-based equalization. Then, it is used as input for the curvilinear detector. To postprocess it, the curvilinear mask is smoothed with a \(9 \times 9\) median filter, then binarized by a fixed threshold (\(t=0.1\)), and finally enlarged two pixels in each direction. In the L*a*b* image, we replace by \(\bot \) the colors in the locations indicated by the mask. Missing pixels are inpainted, providing the hairless image.
It is designed for middle-sized dermoscopic images (approximately \(600\times 600\) pixels) with different pathologies, like the ones in the \(\text {PH}^2\) dataset [9].
4 Experiments and Conclusions
In Fig. 2 we compare the results of the Dullrazor® algorithm [8], the algorithm by Toossi et al. [11] and the proposed algorithm.

Our algorithm effectively detects and inpaints almost all hair, while hairless images remain almost unchanged, and it maintains the features of the lesion. The shape and size are never affected due to the behaviour of the closing and opening when inpainting. The color is not affected either: colors with new chroma can not appear due to the nature of the soft color morphological operations. The texture of the lesion, on the other hand, is maintained in the majority of situations. In contrast with other procedures that employ smoothing filters or averages, our inpainting procedure does not tend to blur lesions: it recovers uniform regions correctly, and creates smooth but small transitions when inpainting the missing contours of different regions. The method by Toossi et al. leaves a considerable amount of hair and does not respect textures in general. Dullrazor®, on the other side, removes a fair amount of hair. However, it fails at recognizing hair within the lesion, and does not always preserve textures.
References
Argenziano, G., Longo, C., Cameron, A., Cavicchini, S., et al.: Blue-black rule: a simple dermoscopic clue to recognize pigmented nodular melanoma. Br. J. Dermatol. 165(6), 1251–1255 (2011)
Baczyński, M., Jayaram, B.: Fuzzy Implications. Studies in Fuzziness and Soft Computing, vol. 231. Springer, Heidelberg (2008)
Beliakov, G., Pradera, A., Calvo, T.: Aggregation Functions: A Guide for Practitioners, vol. 221. Springer, Heidelberg (2007)
Bibiloni, P., González-Hidalgo, M., Massanet, S.: Soft color morphology. In: Submitted to IEEE International Conference on Fuzzy Systems (FUZZ-IEEE 2017) (2017)
Informe de conclusiones. MELANOMA VISIÓN 360\({}^\circ \): Diálogos entre pacientes y profesionales. Madrid (2015). http://fundacionmasqueideas.org/documentos/. Accessed 20 July 2016
González-Hidalgo, M., Massanet, S., Mir, A., Ruiz-Aguilera, D.: A fuzzy filter for high-density salt and pepper noise removal. In: Bielza, C., Salmerón, A., Alonso-Betanzos, A., Hidalgo, J.I., Martínez, L., Troncoso, A., Corchado, E., Corchado, J.M. (eds.) CAEPIA 2013. LNCS, vol. 8109, pp. 70–79. Springer, Heidelberg (2013). doi:10.1007/978-3-642-40643-0_8
Kerre, E.E., Nachtegael, M.: Fuzzy Techniques in Image Processing. Studies in Fuzziness and Soft Computing, vol. 52. Physica, Heidelberg (2013)
Lee, T., Ng, V., Gallagher, R., Coldman, A., McLean, D.: Dullrazor®: a software approach to hair removal from images. Comput. Biol. Med. 27(6), 533–543 (1997)
Mendonça, T., Ferreira, P.M., Marques, J.S., Marcal, A.R., Rozeira, J.: PH 2 - a dermoscopic image database for research and benchmarking. In: 2013 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp. 5437–5440. IEEE (2013)
Serra, J.: Image Analysis and Mathematical Morphology, vol. 1. Academic Press, Cambridge (1982)
Toossi, M.T.B., Pourreza, H.R., Zare, H., Sigari, M.H., et al.: An effective hair removal algorithm for dermoscopy images. Skin Res. Technol. 19(3), 230–235 (2013)
Zuiderveld, K.: Contrast limited adaptive histogram equalization. In: Graphics GEMS IV, pp. 474–485. Academic Press Professional, Inc. (1994)
Acknowledgments
The Spanish grants TIN 2016-75404-P AEI/FEDER, UE and TIN 2013-42795-P partially supported this work. P. Bibiloni also benefited from the fellowship FPI/1645/2014 of the Conselleria d’Educació, Cultura i Universitats of the Govern de les Illes Balears under an operational program co-financed by the European Social Fund.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Bibiloni, P., González-Hidalgo, M., Massanet, S. (2017). Skin Hair Removal in Dermoscopic Images Using Soft Color Morphology. In: ten Teije, A., Popow, C., Holmes, J., Sacchi, L. (eds) Artificial Intelligence in Medicine. AIME 2017. Lecture Notes in Computer Science(), vol 10259. Springer, Cham. https://doi.org/10.1007/978-3-319-59758-4_37
Download citation
DOI: https://doi.org/10.1007/978-3-319-59758-4_37
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-59757-7
Online ISBN: 978-3-319-59758-4
eBook Packages: Computer ScienceComputer Science (R0)