
Abstract
Automated valuation methods employ diverse methodologies. The appropriateness of the individual model is contingent upon the characteristics of the housing market in question. In circumstances where the housing market is spatially variegated and data is sparse, distinguishing impacts of an environmental event or externality on different spatial segments of the market is challenging. A multi-level model provides one possible approach. Here we apply the model to explore the impact of a natural disaster on the housing market in Istanbul, a city located in a region with relatively frequent seismic activity. The Chapter provides a relatively simple exemplar of the method and its utility. Two levels of influence emerge. We distinguish between the citywide and segmented neighbourhood impact of earthquakes on house prices. Appraisers working in segmented markets where the potential for natural disasters occur might consider the methodological advantages of using multi-level modeling to help isolate both the effects of the risk of damage and also to discern the spatial variations in such effects. Furthermore we contend that there is considerable scope to expand the modelling approach to take account of different levels.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
Strange and mysterious things, though, aren’t they - earthquakes? We take it for granted that the earth beneath our feet is solid and stationary. We even talk about people being ‘down to earth’ or having their feet firmly planted on the ground. But suddenly one day we see that it isn’t true. The earth, the boulders, that are supposed to be solid, all of a sudden turn as mushy as liquid
—Haruki Murakami, After the Quake, from the short story “Thailand”
Automated valuation methods, housing markets and hedonic regression techniques can all appear to be strange and mysterious things, but when combined with the influence of natural disasters, such as earthquakes, their metaphorical ground may be less solid and stationary.
Haruki Murakami’s fictional masterpiece after the quake explores the aftermath of the Kobe earthquake in Japan in 1995. The characters in the collection of six short stories are impacted by the earthquake, but not all directly affected by it. This sets the backdrop for Murakami’s exploration of the enigma of social variation in self-reflection and changing expectations. Whilst the characters appraise their situation, they find themselves differentially affected by the earthquake, and differentially assessing their futures.
The shadows of natural disasters hang over all property markets. But the temporal regularity, scale and spatial impact of their occurrence is not homogenous. Like Murakami’s characters, as predictors of future events, most mass appraisal methods suggests that homebuyers attempt to factor into their decision making the possibility of a natural occurrence and the scale of the impact on values. When the pricing behaviour of individual transactions is amalgamated in areas of natural disasters, appraisers hope that by analyzing the data they can disentangle the bundle of characteristics leading to particular price formations, and use this information to value properties.
Homebuyers, estate agents, lenders and policy makers are all concerned with accurately valuing properties in areas where natural disasters occur (whether infrequently or not). Not least because the locational advantages for urban areas may also correspond to the locus of natural disasters. In Istanbul for example the location of the urban settlement benefits from advantages bringing together two continents and the potential for crossing the Bosphorus which connects the Aegean Sea and the Black Sea. This natural locational advantage also carries a risk of earthquakes as the fault line, the North Atlantic Fault Zone, between the two continents causes regular seismic activity.
Whilst the resources of homebuyer, estate agents, policy makers, lenders and valuers all vary, they are balancing a trade off between accurate valuations of properties in areas of natural disasters and the cost of those valuations. Automated valuation methods offer one solution to this tension. AVM’s methodologically neutrality is contingent upon one of the many forms of regression model utilized and the information entered into the model. The appropriate form of the regression model in each case depends on the characteristics of the housing market being conceptualized and the availability of data.
Automated valuation, using regression models, vary widely in complexity and in their conceptual categories, allowing for extensions of the model. Spatially, some AVMs consider house prices to be smoothed over Cartesian space, whilst others consider dummy variables to be adequate proxies for the distinctions between submarkets. Whilst both of these approaches may relate well to particularly structured stable housing markets, the impact of shocks on the housing market arguably requires a reconceptualization of the fundamental spatial characteristics of market behaviour.
This chapter considers the scope to apply new forms of regression model for an AVM within one set of specific circumstances. We consider the introduction of multi-level modeling as a tool to support automated valuations in markets where an environmental event or external market shock has taken place.
In the following sections we outline the complexity of modeling shocks (in particular natural disasters) on granular housing markets, considering spatially smooth distance-decay and discrete submarket effects. The chapter then outlines existing explanations of the impact on housing markets of a particular natural disaster, namely earthquakes. The context of the Istanbul housing market and its earthquake risk follows on, before an outline of the method used in the multi-level model. The results find that earthquake effects can be identified across the city region, and there is a varied spatial impact at the neighbourhood level too, suggesting that AVMs operating in areas of natural disasters could benefit from a multi-level approach. We conclude with a brief discussion of future extensions of AVM multi-level modeling.
2 Modeling the Impact of Shocks on Property Values
Risk in housing markets emerges for a wide variety of reasons, including as a result of the risk of environmental disasters. Natural disasters occur at different geographical scales, with different levels of predictability about their location and impact (e.g. compare a volcano and a cyclone). The type of disaster also has an unequal spatial impact upon the built environment and upon actor’s perceptions of risk in the housing market. These variations mean that modeling the impact of event shocks on property values can be very spatially complex. In this chapter we focus on the extension of standard hedonic regression models as a basis for a novel, spatially richer modelling framework. This seeks to encapsulate the positive features of hedonic, whilst overcoming some of the weaknesses common in the applied literature.
Des Rosiers and Theriault (2008) outline three reasons for AVM’s use of hedonic regression methods. First, multiple regression analysis uses probability theory to divide the impact of competing influences on house prices. Second, they argue that its calculative nature is objective (see Schulz et al. (2014) for some of the subjective trade offs in constructing a hedonic based AVM) and therefore more likely to produce the market value that fits a testable probability distribution. Third, hedonic approaches reveal the causal dimensions of house pricing, and when combined with GIS can discern the spatial dimensions too. Des Rosiers and Theriault (2008) highlight the conditions necessary for the data to accurately support this threefold rationale, acknowledging that they may not always be reproducible. Whilst we may wish to extend the critique of the detail of these reasons, the perception of hedonic methods to support these reasons does explain it is growing in use by both professionals and the general public.
As discussed extensively earlier in this book, the hedonic techniques undergirding many AVMs have been applied to human and natural phenomenon, as well as the interplay between the two (e.g. parks) and their positive and negative impacts on prices. Environmental variables have been a particularly frequent theme in the hedonic literature (see Ridker and Henning 1968 for an early example). This vast literature covers issues such as the impact of noise pollution, water contamination and the location of hazardous waste sites or powerlines (see Boyle and Kiel 2001). Hedonic models are also frequently utilized in understanding the impact of natural disasters, such as flooding (e.g. Macdonald et al. 1987; Bin et al. 2008), forest fires (e.g. Loomis 2004; Mueller et al. 2009; Stetler et al. 2010) and hurricanes (e.g. Simmons et al. 2002; Hallstrom and Smith 2005). Whilst the precise methodological form varies in many of these papers, the basic proposition encapsulated is that with a hedonic regression it should be possible to discern a discount in property prices that reflects the impact (or risk) of one of these negative external events.
The simple hedonic regression approach assumes that the impact on house prices of an event is constant over time. It views market actors as having the ability and stability to factor this information into their house price calculations consistently over time. In the case of natural disasters, this assumption is only valid if market actors use this information to inform bidding and selling strategies perfectly. It does not easily allow perceptions of the potential of a disaster to vary. Nor does it allow this to feed through into house price patterns.
In the context of this chapter, a key weakness of the most simplistic hedonic models is that they view space as a continuous plain, with the impact and perception of natural disasters equally distributed across the plain. These models have, of course, been extended in a variety of ways to respond to the challenge of spatial variation in attribute values. This includes attempts to model differences in prices that change evenly through Cartesian space by using augmented hedonic methods (e.g. Clapp 2003; Pavlov 2000). These approaches are appealing because they take away the need for the appraiser to possess, or obtain knowledge of spatial boundaries, and simply allow the spatial variance in price to emanate from the data, be smoothed and therefore be predicted quite readily.
The submarket literature offers some pointers for dealing with spatial complexity. Whilst some AVM’s support data driven spatial segmentation, Bourussa et al. (2003) found that AVM’s using existing spatial submarkets (including those defined by appraisers) produced more accurate price predictions than those based on principal component and cluster analysis approaches. Generally, the smaller the size of each group (whether submarkets, ZIP codes, neighbourhoods), the more accurate the house price predictions have been shown to be (Goodman and Thibodeau 2003). The long-standing argument appears to hold that neighbourhood or submarket boundaries should be used, where known, to improving the predictive power of AVMs (see Strazheim 1975; Schnare and Struyk 1976).
This observation has provided a platform for researchers to ask how, if we accept spatial submarkets as a given, should we seek to most effectively accommodate them in a model (Watkins 2012). Leishman et al. (2013) compare the outcomes from four different modelling strategies when applied to data from Perth, Western Australia. They apply a standard market-wide hedonic equation; a system of submarket specific hedonic models; and two different multi-level model specifications to predict house price patterns across space. Their results suggested that the most spatially granular multi-level specification generates the greatest explanatory power and reduces the instance of non-random spatial errors.
In this vein, we also argue that it seems reasonable to suggest that one way to overcome the problem of dealing with spatial differentiation in housing market models, whilst meeting the necessary conditions for AVMs, is to employ multi-level methods. Multi-level models are a variant on standard hedonic methods (Orford 1999; Leishman 2009). Use of multi-level methods is advised when the observations being analysed are clustered and correlated, the causal processes underlying the relationships operate simultaneously at multiple spatial scales and there is value in seeking to separate out the spatial and temporal effects of different attributes (Subramanian 2010). Their use has begun to expand within the quantitative geography field where the technique has been used to examine complex spatial impacts and interactions in a variety of arenas including in the measurement of social well-being and happiness (see Ballas and Tranmer 2008). We discuss the method more fully in Sect. 3 below.
The remainder of the chapter illustrates how this approach might be implemented. It is our view that this approach (at least partly) extends traditional models and is particularly useful in contexts where delineating the differences in the spatial impact of risk is especially desirable.
3 An Applied Case Study—The Impact of Earthquake Risk on Property Values in Istanbul
3.1 Case Study of Istanbul
The empirical analysis in this chapter focuses on Istanbul, the largest city in Turkey and home to almost fifteen per cent of the population. Its formal housing sector is dominated by market dwellings, much of which are located in high density, inner urban neighbourhoods where the stock often dates from the early twentieth century; or, in the case of newer stock, is found planned housing areas established since the start of the century. Many of the latter properties occupy the mid and higher end of the price scale and are promoted to potential sellers in a manner that draws on the growth in popularity of gated and semi-gated communities that benefit from very good links to transport infrastructure, employment centres and excellent public amenities (Alkay 2011). At the lower end of the market, there are significant numbers of unplanned dwellings, estimated by some to be over fifty per cent of the total, located within squatter settlements, known as ‘Gecekondu’ (see Gokmen et al. 2006). These informal parts of the sector are occupied by lower income groups and consist of dwellings in poor physical condition and with limited sales values.
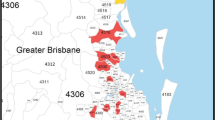
As Keskin (2010) explains, although property values have been moving upwards across the market, there has been evidence of increasing divergence between the top and bottom of the market. Figure 1 illustrates the degree of spatial disaggregation within the market. The submarkets identified on the map comprise neighbourhood that act as close substitutes, even though they are not always spatially contiguous, and according to Keskin represent distinct market segments with their own unique price formation processes and price structure. The highest price neighbourhoods are in submarket 1 while the lowest price subareas are in submarket 5, which also happen to be the neighbourhoods traditionally perceived to be most likely to suffer earthquake damage.

Istanbul’s housing submarkets. Source Keskin (2010)
3.2 Data
The house price and housing attributes data used in our applied modelling work are drawn from the internet listing services of two leading realtors, Turyap and Remax. This dataset includes details of 2175 housing transactions from 2007 and have been combined with socio-economic, neighborhood and locational attributes collected from a survey of households undertaken in 2006 by the Istanbul Greater Municipality (IGM). We have also added data on earthquake risk from the Japanese International Cooperation Agency (JICA) report (JICA 2002). Table 1 summarises the descriptive statistics for all of the variables used in the modelling process.
3.3 Method of Estimation
Some of the house price modelling literature that informs AVM approaches overlooks the hierarchical or clustered structure of the data. This can be a source of errors in these models. Multi-level models starts by recognizing the challenges in analysing hierarchical data structures or variables at different levels. The method models individual-level dependent variables by using combinations of individual-level and group-level independent variables. Multi-level models are also known in the literature as contextual models, hierarchical linear models, hierarchical linear regression, random coefficients models, hierarchical mixed linear models, or Bayesian linear models.
Usually in studies of social phenomena and social data, the hierarchical structure of data consists of lower and upper levels. The lower level consists of individuals or properties which are grouped in higher levels with respect to the context. Due to the fact that multi-level analysis involves individuals that are nested in a contextual level, this method often attempts to examine how the individual level (micro level) outcomes are affected by both the individual level and the group level (macro level or contextual level) variables (Blalock 1984). This statistical method helps to specify effects of contextual subjects on individual-level outcomes. Thus, it becomes possible to display the different relationships between the dependent and independent variables within different contextual groups. These kinds of relationships are referred to as contextual effects and these are the effects that a space has on individuals. On the other hand, compositional effects are the effects that the characteristics of individuals in different geographical levels have.
Multi-level modelling is thus developed from hierarchical approaches that can include both fixed and random effects, and can be modelled at each and every level within the hierarchy. Fixed effects are the “permanent” or “unchanging/constant/fixed” elements of the model and, as such, one estimate is derived for the whole sample. Random effects are the part of the equation that is “allowed to vary” part and where there is potential for different results to occur within the sample (Jones and Bullen 1993).
Clearly, multi-level modelling can be considered a modified version of hedonic price modelling. Hedonic models contain only fixed effects- the intercept and coefficients describe the sample as a whole. Arguably the spatial pattern of house price is not very effectively represented by fixed effects/regression models, given that they assume that the same intercept and slopes characterizes all neighbourhoods or submarkets. An alternative approach to deal with the tendency towards uneven spatial distribution of housing prices is to allow each of the segments to have their own random intercept. In doing this, multi-level models allow us to decompose the residuals and to expose the random intercepts and the hedonic slope parameters unique to each separate geographic unit (Leishman et al. 2013).
In general, a multi-level equation is formulated as:
Here, Yij represents the price of the house i in area j; α, β and μ are the parameters to be estimated, ε is the error term and Xij is a set of explanatory variables which include housing attributes, socio-economic data and earthquake risk of the house i in area j.
4 Model Results and Research Findings
Our multi-level model includes standard property and neighbourhood attributes and a measure of earthquake risk. The results, shown in Table 2, highlight the fixed effects as well as model fit statistics. The coefficients shown in Table 2 are analogous to hedonic coefficients from a regression model. As with standard hedonics, this aspect of the model allows us to isolate the influence of earthquake risk from other price determinants. It also allows the differentiation between market-wide effects (−0.19 % discounts) and random neighbourhoods effects (which can be + where risk is below the market average or − where risk is above the average).
As might be expected the results show that many of the standard variables, including living area of the housing unit, being located at a semi gated, the age of the building, or gated community, income of the household and earthquake risk have a significant impact on prices. The Wald chi-squared test suggests strong explanatory power. The model shows that, on average, we should expect a 0.164 % discount in house price for every 1 % increase in the likelihood that a dwelling might be damaged.
Table 3 provides additional information about the random effects. The likelihood ratio test shows that the random intercepts model offers significant improvement over a standard linear regression model, of course, which includes only fixed effects (Table 3).
This basis multi-level formulation can be used to determine the spatial variations in the impact of key variable. Table 4 summarises the impact of earthquake risk on the five neighbourhoods that had the highest house price levels. It shows that these neighbourhoods with have positive R effect values and that the risk of earthquake is relatively low.
Table 5 shows the impact of earthquake risk on the five lowest price neighbourhoods. This shows that the cheapest neighbourhoods have mainly negative R effect values, implying significant price discounts.
Thus, it is earthquake risk impacts on price in the most pronounced manner in the neighbourhoods where the lowest price properties are found.
5 Conclusion
Modelling house prices across spatially segmented housing markets is a major challenge. It is, however, an important task where the market being analysed is highly spatially differentiated and/or exposure to negative environmental externalities is uneven across the market. The ability to model the likely impacts of house price determinants in a granular way is limited in AVMs that rely on standard hedonic regression methods. Using Istanbul as a case study, we seek to illustrate how a multi-level model can be used for AVM purposes. We seek to illustrate the general robustness of the approach and the way in which it allows us to detect the market wide and neighbourhood specific effects of particular price determinants, in this case the perceived risk of earthquake damage. This approach has been shown in these circumstances to be able to distinguish between the different level impacts and to have high predictive power.
Like other forms of AVM regression, changes in house price caused by perceived risk of earthquake damage is assumed to be internal to the home purchasing decision-making process. This standard assumption, common to the hedonic framework, means that in practice earthquake effects can be observed to have an impact at both the citywide and the neighbourhood level. The effects at neighbourhood level vary widely with clear evidence of discrete spatial impacts on house prices. This finding is significant for all AVM’s in earthquake zones. Importantly it implies that the use of a single variable for earthquake risk, with a constant parameter across the market, will adversely affect the predictive power of the model as a whole and will misrepresent the likely scale of the impact within specific neighbourhoods. Whilst it is foolhardy to suggest that the ground beneath any AVM is unshakeable, this research supports the extension of AVM models by using multi-level methods to separate neighbourhood effects from higher level (urban or regional) effects. Furthermore, multi-level modeling also benefits from being able to cope with fewer numbers of individual observations as long as the number of groups is high enough to analyse the variation between groups at a particular level.
References
Alkay, E. (2011). The residential mobility pattern in the Istanbul Metropolitan Area. Housing Studies, 26(4), 521–539.
Ballas, D., & Tranmer, M. (2008). Happy places or happy people? A multi-level modelling approach to the analysis of happiness and well-being. Mimeo: University of Sheffield.
Blalock, H. M. (1984). Contextual-effects models: Theoretical and methodological issues. Annual Review of Sociology, 10, 353–372.
Bin, O., Brown Kruse, J., & Landry, C. E. (2008). Flood hazards, insurance rates, and amenities: Evidence from the coastal housing market. The Journal of Risk and Insurance, 75(1), 63–82.
Boyle, M., & Kiel, K. (2001). A survey of hedonic studies of the impact of environmental externalities. Journal of Real Estate Literature, 9, 117–144.
Bourassa, S. C., Hoesli, M., & Peng, V. C. (2003). Do housing submarkets really matter? Journal of Housing Economics, 12, 1, 12–28.
Case, B., Colwell, P., Leishman, C., & Watkins, C. (2006). The impact of environmental contamination on condo prices: A hybrid repeat-sale/hedonic approach. Real Estate Economics, 34(1), 77–107.
Clapp, J. M. (2003). A semiparametric method for valuing residential locations: Application to automated valuation. Journal of Real Estate Finance and Economics, 27(3), 303–320.
Des Rosiers, F., & Theriault, M. (2008). Mass appraisal, hedonic price modelling and urban externalities: Understanding property value shaping processes. In T. Kauko, & M. d’Amato (Eds.), Mass appraisal methods, an international perspective for property valuers. UK: RICS Research, Wiley-Blackwell.
Goodman, A., & Thibodeau, T. (2003). Housing market segmentation and hedonic prediction accuracy. Journal of Housing Economics, 12(3), 181–201.
Grigsby, W. (1963). Housing markets and public policy. Uni of Penn Press.
Hallstrom, D. G., & Smith, K. (2005). Market response to hurricanes. Journal of Environmental Economics and Management, 50(3), 541–561.
JICA. (2002). A disaster prevention/mitigation plan for Istanbul. Report to Istanbul Municipal Authotiy, Istanbul. Available at: http://ibb.gov.tr/tr-TR/SubSites/DepremSite/PublishingImages/JICA_ENG.pdf (accessed 20th July 2014)
Jones, K., & Bullen, N. (1993). A multilevel analysis of the variations in domestic property prices—Southern England, 1980–87. Urban Studies, 30(8), 1409–1426.
Keskin, B. (2010). Alternative approaches to modelling housing submarkets: Evidence from Istanbul, Unpublished Ph.D. thesis, Sheffield: University of Sheffield.
Keskin, B., & Watkins, C. (2014). The impact of earthquake risk on property values. London: Royal Institution of Chartered Surveyors.
Lamond, J., Proverbs, D., & Hammond, F. (2010). The impact of flooding on the price of residential property: A transactional analysis of the UK market. Housing Studies, 25(3), 335–356.
Leishman, C. (2009). Spatial change and the structure of urban housing sub-markets. Housing Studies, 24(5), 563–585.
Leishman, C., Costello, G., Rowley, S., & Watkins, C. (2013). The predictive performance of multi-level models of housing submarkets: A comparative analysis. Urban Studies, 50(6), 1201–1230.
Loomis, J. (2004). Do nearby forest fires cause a reduction in residential property values? Journal of Forest Economics, 10(3), 149–197.
MacDonald, D. N., Murdoch, J. C., & White, H. L. (1987). Uncertain Hazards. Insurance, and consumer choice: evidence from housing markets, land economics, 63(4), 361–371.
Malpezzi, S. (2003). Hedonic pricing models: A selective and applied review. In T. O’Sullivan, & K. Gibb (Eds.), Housing Economics and Public Policy. Blackwells.
Mueller, J., Loomis, J., & Gonzalez-Caban, A. (2009). Do repeated wildfires change homebuyers’ demand for homes in high-risk areas? A hedonic analysis of the short and long-term effects of repeated wildfires on house prices in Southern California. Journal of Real Estate Finance and Economics, 38(2), 155–172.
Orford, S. (1999). Valuing the built environment: GIS and house price analysis. Aldershot: Ashgate.
Pavlov, A. D. (2000). Space-varying regression coefficients: A semi-parametric approach applied to real estate markets. Real Estate Economics, 28(2), 249–283.
Pryce, G. (2013). Housing submarkets and the lattice of substitution. Urban Studies, 50(13), 2682–2699.
Ridker, R. G., & Henning, J. A. (1968). The determination of residential property value with special reference to air pollution. Review of Economics and Statistics, 49, 246–257.
Rosen, S. (1974). Hedonic prices and implicit markets: Product differentiation in pure competition. The Journal of Political Economy, 82(1), 34–55.
Schnare, A., & Struyk, R. (1976). Segmentation in urban housing markets. Journal of Urban Economics, 3, 146–166.
Schulz, R., Wersing, M., & Werwatz, A. (2014). Automated valuation modeling: A specification exercise. Journal of Property Research, 31(2), 131–153.
Simmons, K. M., Kruse, J. B., & Smith, D. A. (2002). Valuing mitigation: Real estate response to hurricane loss reduction measures. Southern Economic Journal, 68(3), 660–671.
Straszheim, M. (1975). An econometric analysis of the urban housing market. New York: National Bureau of Economic Research.
Subramanian, S. V. (2010). Multilevel modelling. In M. M. Fischer & A. Getis (Eds.), Handbook of spatial analysis: Software, tools, methods and applications. Berlin: Springer.
Stetler, K. M., Venn, T. J., & Calkin, D. E. (2010). The effects of wildfire and environmental amenities on property values in northwest Montana, USA. Ecological Economics, 69(11), 2233–2243.
Tu, Y. (2003). Segmentation, adjustment and disequilibrium. In T. O’Sullivan, K. Gibb (Eds.), Housing Economics and Public Policy. Blackwells.
Watkins, C. A. (2001). The definition and identification of housing submarkets. Environment and Planning A, 33(12), 2235–2253.
Watkins, C. (2012). Housing submarkets. In S. Smith et al. (Eds.), International encyclopedia of housing and home. North-Holland: Elsevier.
Willis, K. G., & Asgary, A. (1997). The impact of earthquake risk on housing markets: Evidence from tehran real estate agents. Journal of Housing Research, 8(1), 125–136.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this chapter
Cite this chapter
Dunning, R., Keskin, B., Watkins, C. (2017). Using Multi Level Modeling Techniques as an AVM Tool: Isolating the Effects of Earthquake Risk from Other Price Determinants. In: d'Amato, M., Kauko, T. (eds) Advances in Automated Valuation Modeling. Studies in Systems, Decision and Control, vol 86. Springer, Cham. https://doi.org/10.1007/978-3-319-49746-4_13
Download citation
DOI: https://doi.org/10.1007/978-3-319-49746-4_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-49744-0
Online ISBN: 978-3-319-49746-4
eBook Packages: EngineeringEngineering (R0)