
Abstract
Motor activity in physical and psychological stress exposure has been studied almost exclusively with self-assessment questionnaires and from reports that derive from human observer, such as verbal rating and simple descriptive scales. However, these methods are limited in objectively quantifying typical behaviour of stress. We propose to use accelerometer data from smartphones to objectively quantify stress levels. Used data was collected in real-world setting, from 29 employees in two different organisations over 5 weeks. To improve classification performance we propose to use intermediate models. These intermediate models represent the mood state of a person which is used to build the final stress prediction model. In particular, we obtained an accuracy of 78.2 % to classify stress levels.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
OVER the last decades there has been rising concern worldwide about the growth and negative impact of work-related stress. The prevalence of stress-related illnesses such as burnout has increased dramatically in the European Union (EU) [1, 2]. Recent studies show that stress is ranked as a second most common work-related health problem across the members of the EU. In the Fourth European Working Conditions Survey conducted in 2015, 22 % of workers from the EU have reported the impact of work-related stress [2]. Furthermore, a high prevalence of stress has also been reported in USA, where 55 % of employees have reported increased workload having a significant impact on physical and mental health [3]. Recent studies show that individuals with high-stress were accompanied by physical and psycho-social complaints and decreased work-control [4].
To date, current approaches for measuring stress rely mostly on self-reported questionnaires [1]. This presents an issue for effective measurements, due to subjectivity factors. For example, employees might be more predisposed to report information in their favour or in the favour of their organisation, rather than reporting their true health state. To overcome these issues, smartphones are becoming suitable means to carry out these kinds of studies, due to their availability, rich set of embedded sensors and their capacity to be unobtrusive for the subjects [5,6,7,8].
Motor activity-related behaviour (i.e. body hyperactivity, trembling, uncontrollable movement, hand movement) has shown association with perceived stress [9]. In the context of our study, the following research questions are put forth:
-
Is there a relationship between motor activity features that can be automatically extracted from a accelerometer sensor embedded on smart phones and the self-reported stress levels?
-
Is it possible to improve stress detection by incorporating intermediate, hidden, variables related to the subjects’ mood, before building the final model for predicting stress?
The present work tries to answer both these research questions by comparing standard stress measurement questionnaires and motor activity behaviour during phone conversations.
We performed an experimental analysis using real world data. While, we have previously reported on the use of accelerometer data to estimate stress levels [5], this study differs from that work in two important aspects:
-
The use semi-supervised learning to complete the models for subjects with missing data.
-
The induction of intermediate models to predict mood variables, which are incorporated in the final model in order to improve the accuracy of the predictions.
Our results show that using standard supervised models we achieved an accuracy of \(\approx \) 65 %. This measure is increased to \(\approx \) 69 % when using the semi-supervised methods and to \(\approx \) 71 % when using intermediate models. Finally, combining semi-supervised learning and intermediate models we achieve an accuracy of \(\approx \)78.2 %; a notable improvement over the initial score.
The rest of this paper is organized as follows. Section 2 reviews related work on stress detection based on current technology. The study methodology, data acquisition, and feature extraction are presented in Sect. 3. The proposed approach of intermediate models is presented in Sect. 4 and experiments are presented in Sect. 5. Finally, the conclusions of the study are presented in Sect. 6.
2 Related Work
Several methods have tried to infer stress based on physiological signals, such as heart-rate variability, blood pressure, body temperatures and respiration [10, 11]. However, the use of physiological sensors has some limitations:
-
sensors may have a large size to cover many signal types [10],
-
sensors (e.g., skin conductance sensor) limit the movement of the subjects [11]
-
sensors increase the discomfort [12] since they need to be carried all the time.
The miniaturization of wearable sensors has made it possible to include them in smartphones. Recently, there is interest in inferring stress using those sensors, since they are a personal and common accessory among people. A summary of the works aiming at stress detection are described in Table 1. The work in [13] proposed a method for detecting stress based on speech analysis and the variation of speech articulation using smartphones. The authors have reported a predictive accuracy of stress of 81 % and 76 % for indoor and outdoor environments, respectively, using the vocal production of 14 subjects. However, in real-life activities this approach may lead to misinterpretation of speech and therefore of emotion.
In order to infer relationship dynamics of people and behaviour changes in daily activities, smartphones have been suggested as a promising candidate to obtain user’s context. Research work using smartphones for long-term stress monitoring has collected many types of contextual data (e.g., physical activities, social activities and locations) that could help in inferring stress from behaviour changes. In this line, “MoodScope”[14] is a self tracking system to help users manage their mood. The system detects user’s mood from smartphones usage data, such as email messages, calls and SMS logs, application usage, web browsing histories and location changes. The authors reported an initial 66 % accuracy of subjects’ daily mood, improving to 93 % after two months of training.
In another relevant work, Bauer and Lukowicz [15] aimed at recognizing stress from 7 students before and after an exam period. The assumption is that students are likely to be under stress during the exam sessions. They acquired data from smartphones (location, social proximity through Bluetooth, phone calls and SMS logs) reporting an average accuracy of 53 % during the exam session. In [16] the authors monitored 18 subjects for a period of 5 days. In addition to smartphone features they included a wrist sensor. In order to recognize stress levels, the authors applied correlation analysis and reached a 75 % accuracy using machine learning techniques to classify stress moments.
Similarly, Muaremi et al. [17] measured smartphone mobility data (phone-calls, SMS, location and physical activity) and wearable Heart Rate Variability (HRV) sensor data to classify perceived stress. The authors emphasize the importance of recording human voice as a potential source for non-intrusive stress detection. The authors at [16] propose to infer work-relevant stress events using an external hardware (i.e., HRV) and sensor measurements obtained from smartphones. Furthermore, in [18] the authors used context information from the environment, such as weather condition, social proximity obtained by Bluetooth scanning, call logs, SMS logs, and self-reported surveys about personality traits to predict stress events.
As presented in Table 1, recent studies have explored the potential of physiological signals for measuring stress related signs from sensor data (e.g., Galvanic Skin Response (GSR), Electro-Cardiogram (ECG)) and smartphone sensors (e.g., location, audio recording). However, there are several concerns about using physiological sensors, basically due to their obtrusiveness. In contrast, we explore the potential of using a single sensor with the aim of detecting perceived stress levels. We choose to use accelerometer sensor due to their advantages (non-visual and non-auditory) and thus mitigate privacy concerns [20, 21].
2.1 Motor Activity Monitoring
Currently, the clinicians assess motor activity in laboratory settings. Studies measuring level of motor activity in psychological stress have typically used traditional monitoring with paper and pencil diaries, and questionnaires [22].
Monitoring motor activity during sleep may be measured by actigraphs [23] (using piezoelectric accelerometer). However, little is known if data captured from an actigraph could provide motor activity characteristics in perceived stress level in working environments.
Smartphones are a good candidate for monitoring motor activity behaviour patterns in daily activities. Information from smart phones enables easier monitoring and tracking of people than traditional methods, as most people already carry a smartphone so no additional sensors are required. Another benefit of using this technology is that other information (such as phone calls, location, use of social networks) can be obtained and included. In this paper, we collect data from accelerometers during phone calls to infer motor activity changes in working employees.
3 Data Preparation
This section presents how the data was collected and the feature extraction process.
3.1 Data Collection
In this research work, we focus on analysing accelerometer raw data during phone conversation, where we are sure that the subjects are holding their smartphones. This type of measurement has the advantage of their availability and unobtrusiveness. We believe that analysing data collected from accelerometer readings during the phone conversations provide adequate information for classifying the perceived stress that can be also used to show the trajectory of perceived stress (e.g., low-to-high, high-to-low) in working environments.
The second type of data includes subjective information related to subjects’ perceived stress, job-demands and mood states. We developed a questionnaire in a smart phone application to assess psychological variables related to work stress. The questionnaire is clinically validated to capture users perceived stress and mood states of the employees at work. Three times a day the questionnaires appeared automatically (9am -at the beginning of the work, 2pm -around noon, and 5pm -before leaving workplace). The questionnaire was derived from the POMS (Profile of Mood State) scale [24] which has two dimensions related to affect of mood states, including, “Positive Affect” (PA) (e.g., Cheerful, Energetic, Friendly) and “Negative Affect” (NA) (e.g., Tensed, Anxious, Sad, Angry) and the rest measures disengagement from work, where questions were presented in mixed order. Each question has five response alternatives, ranging from 1 (absolutely agree) to 5 (absolutely disagree). The answers were stored on the mobile device and constituted part of the analysis. For the purpose of our analyses, the score distribution has been segmented into three regions, which in our case correspond to three ordinal classes: (“low” or “poor”), when score \({<}\) 3; (“moderate” or “fair”), when score = 3; and (“high” or “sufficient”), when score \({>}\) 3.
For this study, we analysed the information from 29 subjectsFootnote 1 in their work environments, with data collected during their phone conversation and self-reported stress. In total, we obtained 7189 phone calls, however, we have only 5767 labeled instances or 80.22 % useful data of the total phonecalls.
Table 2 shows the number of times that are associated with each stress level (“high”, “moderate”, and “low”). Results show that half of the time the user perceived some level of stress and that during stress-less days the subjects have a higher amount of phone calls.
3.2 Feature Extraction
From the raw accelerometer data a total of 30 features (10\(\times \)3 - for all Minimum, Maximum and Mean) from the frequency domain were extracted (as shown in Table 3). Feature extraction was performed on non-overlapping fixed length windows of 128 samples (25.6 seconds each). We used Fast Fourier Transform (FFT) and discrete Fourier Transform (DFT) to investigate the strength of motor activity signals during phone conversationsFootnote 2. Since we aim at understanding motor activity behaviour around the phone conversation, we keep the following accelerometer segments:
-
One minute before the phone conversation,
-
The reading from the entire duration of the phone call.
-
One minute after the conversation ended.
Figure 1 depicts the data collection, feature extraction (intensity of phone handling during phone conversation by computing features from frequency domain) and prediction process presented in this work.

Proposed approach: data collection, feature extraction and prediction for classifying stress at work of employees.
4 Stress Modelling Using Intermediate Models
In this section we describe the proposed approach that combines intermediate models and semi-supervised learning for estimating stress levels based on smart phones.
4.1 Intermediate Models
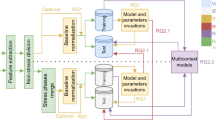
The information provided by the users through the questionnaires is useful, however, it is a tedious task for each user. In this research we propose to predict the mood variables associated to the questionnaires using the data from the smartphone to alleviate the user from this burden. Then, we use the predicted mood variables with the rest of the data from the smartphones to predict the stress levels. We call the models that predict the mood variables from the questionnaire intermediate models as their are used as input for the final predictive model. Although the use of additional variables, such as latent variables, have been previously used in the literature, we are not aware of research that aims at building an intermediate model that can then be used as input for the final model. Figure 2 illustrates the procedure for building the intermediate models. We train a classifier to predict the information from the questionnaires using the features extracted from the smartphone (feature extraction and \(Q'_1\) in the figure, to create a model – intermediate model – that can predict the variables of the questionnaire). We then use the information from the smarphones and the predicted values from the intermediate model (\(q'_1\) in the figure) to create model that can predict the level of stress.
In this study, we used six variables derived from NA and PA (3 per each mood affect) to build 6 intermediate models. We train each classifier separately using each the self-reported questionnaires derived from the ‘Positive Mood Affect (PA)’ and the ‘Negative Mood Affect (NA)’.
In the prediction stage, the intermediate models use the information from the smartphones to predict a weighted set of mood variables based on the accuracy of each model. Then all the data from the smartphones and the mood variables are used as input for the final stress model.

Intermediate Models. Based on the accelerometer data from the smart phones, 30 frequency domain features are extracted. These are used to build the intermediate models for the mood variables, \(Q_1\); and the model for stress, \(S_1\). In the prediction stage both models are combine via a weighted linear combination to predict the stress level.

Semi-Supervised Learning Method (SSL), where L represents labeled instance, U unlabeled instances, and t number of iterations, L = L\(_{t}\) \(\cup \) U\(_{t}\)
4.2 Semi-supervised Learning
In real applications missing labeled instances are a common issue and the standard supervised approaches ignore the unlabeled instances. But this information, even when it is not complete, can be helpful and should not be discarded. Semi-supervised learning (SSL) [25] has been suggested as a method aiming to address this issue. The main objective of semi-supervised learning is to learn from both labeled and unlabeled data, i.e. by exploiting unlabeled samples to improve the learning performance.
For this study we consider one of the most common methods of SSL called Self-Training [25]. This method works by building a classifier using the labeled examples and use it to predict the class of all the unlabeled instances. The predicted classes with high confidence from the classifier are added as new labeled examples. This augmented labeled set is used to build a new classifier and the cycle is repeated until all the unlabeled instances have been incorporated into the training set or until there is no more examples in the unlabeled set with high confidence (see Fig. 3).
5 Experiments
Our experiments have the following objectives:
-
Compare the performance of different classifiers on the data.
-
Assess the effect of intermediate models to enhance the knowledge of perceived stress in employees.
-
Use SSL to address the problem on how to use information from unlabeled data to enhance classification accuracy.
For all the experiments, we used Weka’s [26] classifiers with their default parameters. We build a model for each subject and performed a 10-fold cross validation for all the experiments; we report the global accuracy, precision, recall and f-score values. Table 4 show the results using different classifiers. In the first experiment we compare the performance of the classifiers using a supervised and a semi-supervised learning (SSL) algorithms. In the second experiment we analyse the impact of using the intermediate models, with and without SSL.
In our data set, more than 27.6 % of the phone conversation did not have an associated stress level (the user did not answer the questionnaire). To address this issue, we used the Self-Training Method described above. We followed a simple approach where we divided the data into ten folds, where the training data was used to classify the unlabeled data (as shown in Fig. 3), as threshold for the confidence we used \(\ge \) 80 % for the highest classified value. Then we used all the classified data with the original training set to produce an extended training set. As can be seen from the results adding information from generated from SSL and intermediate models improves the results in terms of accuracy, precision, recall and F-measure for all the classifiers, in some cases as for C4.5 the improvement is nearly 10 %.
By incorporating the intermediate models, a further improvement is obtained in both cases, with and without SSL. As it can be observed in Table 4, the best results are obtained by combining SSL and the intermediate models, and in particular with the random forest classifier.
6 Conclusions
In this paper we presented a study of how to classify the perceived stress of employees from accelerometer data extracted from smart phones during phone conversations. We used real data from employees during 8 working weeks on unconstrained conditions. We extracted several features to analyse the motor activity-related behaviour from different users. To deal with unlabeled data we propose the use of semi-supervised learning techniques. Additionally, we developed a novel approach to incorporate unobserved variables, intermediate models. We experimentally evaluated the impact of using SSL, intermediate models and both of them, using different base classifiers. The proposed approach for creating intermediate models has been shown to increase the prediction of the stress level of the users using the data derived from motor activity; from 61.5 % using the standard supervised methods to \(\ge \)78 % after applying intermediate models and SSL.
A future work we would like to analyse in more depth the models obtained from each person in order to obtain clusters of people who behave similarly; this could help to build prediction models for new users with few data.
Notes
- 1.
One of the subjects had very few phone calls recorded during the trial and was removed from the study.
- 2.
Phone conversations with less than 10 seconds were discarded in our dataset.
References
Näätänen, P., Kiuru, V.: Bergen burnout indicator 15, Edita (2003)
European foundation for the improvement of living and working conditions, Fourth European Working conditions Survey. http://www.eurofound.europa.eu/ewco/surveys/EWCS2005/index.htm
Stress in america, American Psychological Association. http://apa.org/news/press/releases/stress/index.aspx?tab=2
Milczarek, M., Rial-González, E., Schneider, E.: OSH [Occupational safety, health] in figures: stress at work-facts and figures, Office for Official Publications of the European Communities (2009)
Ceja, E., Osmani, V., Mayora, O.: Automatic stress detection in working environments from smartphones’ accelerometer data: A first step. Biomed. Health Inf. IEEE J. 1, 99 (2015)
Ferdous, R., Osmani, V., Marquez, J.B., Mayora, O.: Investigating correlation between verbal interactions, perceived stress. In: 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, Milano (2015)
Hernandez-Leal, P., Maxhuni, A., Sucar, L.E., Osmani, V., Morales, E.F., Mayora, O.: Stress modelling using transfer learning in presence of scarce data. In: Ambient Intelligence for Health, Springer International Publishing, Puerto Varas, Chile, pp. 224–236 (2015)
Osmani, V., Ferdous, R., Mayora, O.: Smartphone app. usage as a predictor of perceived stress levels at workplace. In: 9th International Conference on Pervasive Computing Technologies for Healthcare, IEEE (2015)
Morgan III., C.A., Hazlett, G., Wang, S., Richardson Jr., E.G., Schnurr, P., Southwick, S.M.: Symptoms of dissociation in humans experiencing acute, uncontrollable stress: a prospective investigation. Am. J. Psychiatry
Bakker, J., Pechenizkiy, M., Sidorova, N.: What’s your current stress level? detection of stress patterns from gsr sensor data. In: IEEE 11th International Conference on Data Mining Workshops (ICDMW), pp. 573–580 (2011)
Roh, T., Bong, K., Hong, S., Cho, H., Yoo, H.-J.: Wearable mental-health monitoring platform with independent component analysis, nonlinear chaotic analysis. In: Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, pp. 4541–4544 (2012)
Wijsman, J., Grundlehner, B., Liu, H., Hermens, H., Penders, J.: Towards mental stress detection using wearable physiological sensors. In: Engineering in Medicine and Biology Society, EMBC, Annual International Conference of the IEEE, pp. 1798–1801. IEEE (2011)
Lu, H., Frauendorfer, D., Rabbi, M., Mast, M.S., Chittaranjan, G.T., Campbell, A.T., Gatica-Perez, D., Choudhury, T.: Stresssense: Detecting stress in unconstrained acoustic environments using smartphones. In: Proceedings of the ACM Conference on Ubiquitous Computing, pp. 351–360 (2012)
LiKamWa, R., Liu, Y., Lane, N.D., Zhong, L.: Moodscope: building a mood sensor from smartphone usage patterns. In: Proceeding of the 11th Annual International Conference on Mobile Systems, Applications, and Services, pp. 389–402. ACM (2013)
Bauer, G., Lukowicz, P.: Can smartphones detect stress-related changes in the behaviour of individuals? In: IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), pp. 423–426 (2012)
Sano, A., Picard, R.W.: Stress recognition using wearable sensors, mobile phones. In: Humaine Association Conference on Affective Computing and Intelligent Interaction (ACII), pp. 671–676 (2013)
Muaremi, A., Arnrich, B., Tröster, G.: Towards measuring stress with smartphones and wearable devices during workday and sleep. BioNanoSci. 3(2), 172–183 (2013)
Bogomolov, A., Lepri, B., Ferron, M., Pianesi, F., Pentland, A.S.: Daily stress recognition from mobile phone data, weather conditions, individual traits. In: Proceedings of the ACM International Conference on Multimedia, pp. 477–486. ACM (2014)
Kim, D., Seo, Y., Cho, J., Cho, C.-H.: Detection of subjects with higher self-reporting stress scores using heart rate variability patterns during the day. In: 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS, pp. 682–685. IEEE (2008)
Matic, A., Osmani, V., Mayora-Ibarra, O.: Analysis of social interactions through mobile phones. Mobile Networks Appl. 17(6), 808–819 (2012)
Matic, A., Osmani, V., Mayora, O.: Speech activity detection using accelerometer. In: Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pp. 2112–2115 (2012)
Prasad, M., Wahlqvist, P., Shikiar, R., Shih, Y.-C.T.: A review of self-report instruments measuring health-related work productivity. Pharmacoeconomics 22(4), 225–244 (2004)
Mezick, E.J., Matthews, K.A., Hall, M., Kamarck, T.W., Buysse, D.J., Owens, J.F., Reis, S.E.: Intra-individual variability in sleep duration and fragmentation: associations with stress. Psychoneuroendocrinology 34(9), 1346–1354 (2009)
McNair, D.M., Lorr, M., Droppleman, L.F.: Profile of mood states, Univ (1971)
Zhu, X.: Semi-supervised learning literature survey
Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., Witten, I.H.: The weka data mining software: an update. ACM SIGKDD Explor. Newsl. 11(1), 10–18 (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 ICST Institute for Computer Sciences, Social Informatics and Telecommunications Engineering
About this paper
Cite this paper
Maxhuni, A. et al. (2017). Using Intermediate Models and Knowledge Learning to Improve Stress Prediction. In: Sucar, E., Mayora, O., Munoz de Cote, E. (eds) Applications for Future Internet. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, vol 179. Springer, Cham. https://doi.org/10.1007/978-3-319-49622-1_16
Download citation
DOI: https://doi.org/10.1007/978-3-319-49622-1_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-49621-4
Online ISBN: 978-3-319-49622-1
eBook Packages: Computer ScienceComputer Science (R0)