
Abstract
Despite the clear benefits that nanotechnology can bring to various sectors of industry, there are serious concerns about the potential health risks associated with engineered nanomaterials (ENMs), intensified by the limited understanding of what makes ENMs toxic and how to make them safe. As the use of ENMs for commercial purposes and the number of workers/end-users being exposed to these materials on a daily basis increases, the need for assessing the potential adverse effects of multifarious ENMs in a time- and cost-effective manner becomes more apparent. One strategy to alleviate the problem of testing a large number and variety of ENMs in terms of their toxicological properties is through the development of computational models that decode the relationships between the physicochemical features of ENMs and their toxicity. Such data-driven models can be used for hazard screening, early identification of potentially harmful ENMs and the toxicity-governing physicochemical properties, and accelerating the decision-making process by maximising the use of existing data. Moreover, these models can also support industrial, regulatory and public needs for designing inherently safer ENMs. This chapter is mainly concerned with the investigation of the applicability of (quantitative) structure-activity relationship ((Q)SAR) methods to modelling of ENMs’ toxicity. It summarizes the key components required for successful application of data-driven toxicity prediction techniques to ENMs, the published studies in this field and the current limitations of this approach.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others

Keywords
1 Introduction
There has been much interest recently in assessing and managing the potential effects of ENMs on human health and the environment. There is now a significant amount of studies highlighting that although not all ENMs necessarily have side effects, certain types of ENMs can pose risks to human health and the environment [20, 53, 111] if not properly managed. It has been well reported in literature that a nano-sized form of some materials may exhibit significantly different toxicity despite their chemically identical structure [60, 64]. Although is evidently known that some ENMs exhibit adverse effects, their mode of toxic action and the factors affecting their toxicological responses are still not fully discovered. It is clear that large knowledge gaps still exist in areas that are essential for monitoring and minimizing the risks of potentially toxic ENMs [25, 31].
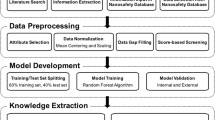
The current toxicity assessment approach primarily relies on animal-based testing that is not only time and cost demanding and but also ethically problematic. Considering the high number of ENMs requiring toxicity screening, the use of alternative approaches such as in silico tests relying on computational modelling methods are needed to predict health risks of a range of ENMs with less cost and time compared to animal testing. There are several computational techniques that have been developed and used in toxicology. The (quantitative) structure–activity relationship ((Q)SAR) analysis is one of the most promising computation approach for toxicity prediction of ENMs since they are capable of quantifying the relationship between relevant properties and biological activity of a certain class of materials. It is a data-driven method that attempts to make use of existing experimental data for in silico prediction of toxicological endpoints. The main assumption behind this approach is that toxicity depends on, and hence can be predicted by, physicochemical properties such as size, shape, surface characteristics and crystal structure. A schematic workflow of the nano-(Q)SAR technique is given in Fig. 5.1.

(Q)SAR modelling of nanomaterial toxicity (Reprinted from Particuology, 21, Ceyda Oksel et al., (Q)SAR modelling of nanomaterial toxicity: A critical review, 1–19., Copyright (2015), with permission from Elsevier)
Although the need for the development of intelligent testing strategies based on in silico methods to assess the toxicity of ENMs has been emphasized by many scientists and regulators [35, 36, 98], scientific investigation of their applications as predictive tools for toxicological evaluation of ENMs has not received much attention. To address this research gap and devote systematic attention to this subject, this chapter is focused on investigating whether the computer-based structure-activity relationship methods are applicable to predict the toxicological effects of ENMs. The ultimate aim here is to contribute to moving the nanotoxicology research forward from individual assessments toward a more integrated hazard screening approach that can predict the toxicity potential of ENMs based on their structural and physical characteristics. The main aim is to give the reader a detailed understanding of the nano-(Q)SAR process, the concepts behind it, the appropriate tools to use, and the remaining knowledge gaps in this area.
2 Toxicity of Nanomaterials
Nanotechnology is a broadly applicable science with considerable potential for breakthroughs in a wide variety of fields. It has impact in almost all branches of engineering, resulting in a rapid increase in the number of ENMs being exploited commercially. However, the distinctive characteristics of ENMs not only make them a material of choice for various applications, but also affect their toxicity potential and present a challenge for the existing regulatory systems.
As numerous natural nano-sized materials have existed in the environment for centuries, and the nature has been filled with several nanofeatures, nanomaterials are not entirely new in many ways. However, unlike naturally occurring nanoparticles (NPs) or incidentally produced nano-sized byproducts, the intentionally designed and manufactured NPs are completely new and capable of exhibiting different biological effects [105]. The study of toxicity of these newly introduced ENMs falls into a new emerging discipline called nanotoxicology. Due to their small size, ENMs have generally been considered to be able to enter and damage living organisms [85].
In recent years, some particular ENMs have been shown to exhibit toxic responses. For example, carbon nanotubes (CNTs) are reported to induce oxidative stress [112] and pulmonary toxicity [115]. Another example of ENMs of significant toxicological concern is nanosilver. Despite initially being perceived to be non-hazardous material, recent studies have provided convincing evidence that nanosilver can exhibit more pronounced toxicity than larger-sized particles of the same substance [5, 32]. For an extensive review of the potential side effects of ENMs, the interested reader can refer to [4, 55, 60, 79, 111].
A toxicological endpoint is the measure of the toxic effect of a substance on human health or the environment, and it determines the harmfulness of a substance. The toxicity of compounds can be evaluated by conducting in vivo, in vitro, and in silico studies. For classical human health hazard assessment through in vivo testing, several toxicological endpoints are relevant, e.g. acute and chronic dermal, oral or inhalative toxicity as well as skin and eye irritation. Although in vitro assays are commonly preferred to in vivo assays as an initial test because of their time and cost effectiveness, there is also a well-recognised need in the nanoscience community to compare and validate in vitro findings with in vivo observations. In (Q)SAR analysis, it is the specific type of activity, such as cell viability or cytotoxicity, that is going to be modelled and predicted. (Q)SAR models can be built and used for the prediction of all toxicological endpoints as long as sufficient toxicity data is provided as input [99]. Ideally, the biological effects of various compounds with different sizes, structures, and complexities under relevant exposure conditions should be tested with standardized test methods for the successful development of nano-(Q)SAR models.
3 Descriptors of ENM Properties
Physicochemical descriptors are experimentally or theoretically derived parameters that are used to correlate the structural parameters with the endpoint of interest through a statistical method. In general, there are two ways of obtaining molecular descriptors representing physical and chemical properties of chemical: experimental measurements and theoretical calculations. Theoretical descriptors can be obtained from different theories and semi-empirical techniques. They provide various structural and compositional information and significant insight into correlations which are assumed to exist between physicochemical properties and biological activity. There are more than 5000 descriptors that have been derived to represent molecular structures but the majority of them are not directly applicable to ENMs. The main problem in using traditional descriptors for nanostructures is their complexity and non-uniformity which make the direct transformation of the nanostructures into a computer-readable form difficult. Experimentally measured parameters such as particle size, size distribution, surface area and surface charge can also be used as descriptors in computational studies. Due to the current limitations in representing nanostructures in a machine readable form, most of the existing nano-(Q)SAR studies use experimental descriptors as an input when developing computational models of ENM toxicity.
There are several issues that are currently of concern to nano-(Q)SAR modellers. The main problem with experimental descriptors is the lack of agreement on how, when and where to characterize ENMs prior to toxicity testing. For theoretical descriptors, the main issue is the appropriate and useful representation of nanostructures enabling computational treatments. Another important issue is the development of novel descriptors for ENMs’ structure. Although traditional QSAR analysis is almost standardized, their application to ENMs is still under development and involves several difficulties, given the complexity of nanostructures. In this section, physicochemical properties that are likely to influence the biological activity of ENMs are briefly explained and their measurement methods are summarised.
3.1 Parameters Influencing the Toxicity of ENMs and their Measurement
The first step in modelling ENM toxicity is identifying toxicity-related properties that can be used as potential determinants of adverse effects of ENMs. Because a complete and exact list of parameters influencing the toxicity of ENMs has not yet been established, detailed material characterization prior to toxicity testing is essential to determine the factors contributing to the biological activities of ENMs and their potential hazards. Although there is still no scientific consensus on the minimum set of relevant nanocharacteristics for toxicological evaluation, some particular physicochemical features are included in the majority of recommendations [95]. The size of ENMs is one of the most important characteristics that affects the properties and behavior of ENMs, and is hence included in the recommendation list of almost all nanotoxicologists. However, as mentioned by Oberdorster et al. [85], the size of the particles is not the only factor that causes changes in the biological activities of materials at the nanoscale. The following characteristics may also be linked to nanotoxicity: size distribution, agglomeration state, shape, crystal structure, chemical composition, surface area, surface chemistry, surface charge, and porosity. Powers et al. [95] investigated the important elements of NM characterization, and expanded the list reported by Oberdorster et al. [85] to include purity, solubility, and hydrophobicity. In a recent review on the minimum set of physicochemical properties required to characterize NMs, Pettitt and Lead [92] suggested that, in addition to the parameters that are most likely to have an effect on NM behavior such as size, surface properties, solubility, and aggregation characteristics, information about the production process and history of ENMs should also be provided to avoid incorrect interpretation of toxicity data. One of the most comprehensive lists of the important physicochemical characteristics for toxicological studies has been provided by the Organization for Economic Cooperation and Development (OECD) Working Group on Manufactured Nanomaterials, the OECD WPMN [88]. The WPMN suggested a list of physicochemical properties potentially needing to be addressed for characterization relevant to (eco)toxicity, and devised a testing programme to investigate this. The physicochemical properties mentioned in this guidance are listed in Table 5.1. The term “composition” in Table 5.1 covers chemical identity and molecular structure, as well as degree of purity, impurities, and additives. Another term in this list that is often broadly defined is the “surface chemistry”. Here, it is meant to identify various modifications of the surface (i.e., coatings) and the composition of the outer layer of the NMs. In OECD’s list, there are also many properties, such as dustiness and n-octanol–water partition coefficient, that have not been specified as prerequisites for NM characterization by other researchers; within the OECD WPMN there is now agreement that the n-octanol-water partition coefficient is not relevant for NMs. Powers et al. [95] took dustiness as an example and argued that such a measurement for dry NM applications should first be standardized, because the presence of well-established analytical techniques for the measurement of intended properties is essential to express the results in comparable terms; dustiness is not an inherent property but depends on the sample tested. For a detailed description of the potential toxicity-related physicochemical properties shown in Table 5.1, please refer to OECD’s guidance on testing ENMs [88].
3.1.1 Particle Size and Size Distribution
The size of ENMs is regarded as one of the most important properties determining the toxicity potential of ENMs. The surface area to volume ratio increases with decreasing particle size. The change in surface-to-volume ratio also affects the surface energy and hence the reactivity of the material. In addition to surface reactivity, the interaction of ENMs with living systems and the uptake and deposition of ENMs within the human body are also affected by particle size [96]. It is generally believed that the risk posed by materials containing nanosized particles increases with decreasing particle size [81]. Indeed, Gurr et al. [45] showed that the oxidative damage induced by TiO2 particles is size-specific: the smaller the particle size, the greater the oxidative damage induced. Similarly, the toxicity of nanosilver is assumed to be dependent on the particle size. Park et al. [90] compared the cytotoxicity, inflammation, genotoxicity, and developmental toxicity induced by different-sized silver ENMs (20, 80, and 113 nm), and found that the smallest nanosilver particles exhibited higher toxicity than larger particles in the assays. More recently, in an interesting study, Xiu et al. [135] concluded that the toxicity of silver NPs are only indirectly associated with morphological features (i.e., these properties influence the release of silver ions which in turn has an effect on the toxicity). All such findings suggest that the size of particles is a possible factor that may directly or indirectly contribute to the toxicity of chemicals. However, in some cases, no relationship between the toxicity of particles and their sizes is observed [64, 70]. There are several techniques that can be used to measure the size of ENMs. Although not a comprehensive list, the most common particle size measurement techniques applicable to ENMs are given in Table 5.2.
The results of different particle size measurement techniques are usually not in agreement because the measurement principles behind each method are different. In general, it is possible to classify the particle size measurement methods applicable to ENMs into three categories: microscopy-based, light scattering-based, and separation techniques [107]. Electron microscopy techniques, which are based on scattered (SEM) or transmitted (TEM) electrons, provide very accurate information and give a clear view of individual and aggregated particles. Therefore, these methods can also be used for polydisperse particle samples. The scanning electron microscopy (SEM) technique provides information about the size, size distribution, particle shape, and morphology, but there is a risk of influencing particle properties during sample drying and contrasting [11]. SEM and TEM give two-dimensional information on the particles. Unlike electron microscopy techniques, a vacuum environment is not required to obtain atomic force microscopy (AFM) images, which allows the measurement of particle sizes under ambient conditions [47].
Dynamic light scattering (DLS) is based on the Brownian motion of suspended particles in solution and gives the hydrodynamic diameter of the particles measured, which is larger than results for dry-measurement diameters. The main advantages of DLS techniques are their simplicity and speed, while their main weaknesses are the high sensitivity to sample concentration and the inability to differentiate between large individual particles and aggregates [81], and furthermore, DLS cannot be successfully applied to polydisperse suspensions of particles as the intensity of the scattered light is proportional to diameter, D, to the power of six, D6, meaning that large particles will overshadow smaller ones. Dynamic centrifugal sedimentation (DCS) and analytical ultracentrifugation use the difference in sedimentation rates of different sized particles to separate a sample. Tantra et al. [120] emphasized that one of the main disadvantages of DCS is the requirement to know the exact density of the particle including coatings and adsorbed analytes on the surface. A dry size measurement method is Brunauer–Emmett–Teller (BET) surface area analysis, which calculates the mean particle diameter from surface area measurement based on the assumption that the particles are nonporous and spherical. Additionally, there are several other size measurement methods, including laser diffraction, mobility analysis, acoustic methods, field-flow fractionation (FFF), and fluorescence correlation spectroscopy (FCS), each of which has its pros and cons. Domingos et al. [26] provided a good example of size measurement by multiple analysis methods including TEM, AFM, DLS, FCS, NP tracking analysis (NPTA), and flow field flow fractionation (FIFFF). They confirmed that the particle size measured by DLS is typically higher than those obtained using the other sizing methods. It was concluded that there is no ideal nanoscale measurement technique that is suitable for all sample types. Various factors, such as the nature of the substance to be measured, the constraints of cost and time, and the type of information required, play a decisive role in the choice of the sizing method. Additionally, the structural properties of ENMs, sample preparation, and polydispersity have significant effects on the results of different ENM size measurement techniques.
There are three important criteria that should be met for accurate measurement of particle size: a well-dispersed system, selection of a representative sample, and appropriate selection of the size measurement method considering the nature of the ENM and its intended use [96]. It should also be kept in mind that some methods require dispersion, such as DLS, NPTA, and DSC. The aggregation/agglomeration of particles in dispersions leads to an increase in the measured particle size, as does the formation of corona, when the hydrodynamic diameter is measured. The results from wet measurements may reflect well the biological situation in nano-toxicity studies, depending on the media, because ENMs will actually not be in a dry form when they are in contact with human cells/organs.
It is our view that the combination of a microscopic technique (e.g., TEM or AFM) and an ensemble technique (e.g., DLS) seems appropriate for monodisperse systems, because this can provide a complete picture of the size characteristics in the dry form and suspension. For polydisperse systems, the DLS technique has serious problems, hence it should be replaced or complemented with an alternative size measurement approach. In summary, it is usually useful to combine a single-particle size measurement technique with an ensemble method to obtain a rich dataset of particle sizes and the size distribution, especially when a priori knowledge on these parameters is unavailable for the test material. The results of seven studies by different researchers are given in Table 5.3, with the aim of comparing different ENM size measurement techniques. It should also be pointed out that, compared with the average value of the particle size, the size distribution provides a more realistic representation of particle size information, which is a critical attribute in nanotoxicology. However, measurement of particle size distributions usually provides a large amount of data (e.g., hundreds of size distribution components), which may cause problems in the (Q)SAR analysis (e.g., increased random correlations). Therefore, it is important to find a reasonable way to represent all components of the size distributions with a few variables that still retain all of the information present in the input data. Wang et al. [132] carried out principal component analysis on size distribution data consisting of a large number of particle size distribution measurements to reduce the number of descriptors to a manageable size. This study is a good example of how to handle large size distribution datasets prior to nano-(Q)SAR analysis. Instead of reporting mean particle size values, researchers should also take into account the variations in the size distribution as a whole, because the ENM samples consist of a range of particle sizes, not only a single type of particles.
3.1.2 Particle Shape
The shape of ENMs is another important feature influencing the biological activities of the particles. The hydrodynamic diameters of spherical and rectangular particles with the same mass, and hence their mobility in solution, vary because of shape effects. Moreover, shape characteristics greatly affect the deposition and absorption kinetics of NPs in a biological environment [81]. The importance of shape in toxicity has been proven for CNTs. Poland et al. [93] showed that long multiwalled CNTs (MWCNTs) are more toxic than short/tangled MWCNTs. The study undertaken by Powers et al. [96] revealed that the antibacterial activity of silver NPs is shape-dependent. In another study, Gratton et al. [41] demonstrated that rod-like (high aspect ratio) NPs are drawn or internalized more efficiently into cells than cylindrical NPs. Although there are several studies investigating and confirming the potential effect of NP shape on toxicity, it is still not possible to draw clear conclusions or define any particular shape inherently “toxic” with current knowledge. Further research is required on NPs with similar composition but different shape to investigate the role of NP shape in toxicity.
There are several nondimensional shape indexes that can be used to quantify the shape characteristics of particles, such as sphericity/circularity, aspect ratio/elongation, convexity, and fractal dimensions. The shape index of NPs is usually determined using microscopic methods such as SEM and TEM, which have the ability to simultaneously determine both particle size and shape. Additionally, the ratio of two particle sizes measured by different techniques, such as DLS and TEM/SEM, can be used as a simple expression of particle shape [56]. Because shape characteristics and the distribution of NPs may vary when they are in contact with organisms, shape measurements should also be made for “as-exposed” as well as “as-received” forms. Wang and Ma [130] defined the shape of a crystal according to the normal distance between each surface of the particle and its geometrical centre. They carried out principal component analysis (PCA) on the shape description dataset for data compression. The calculated surface–centre distances or the resultant principal component values can be directly used as shape indexes of NPs, especially nonspherical NPs, in nano-(Q)SAR. Moreover, these values can also be used as dynamic shape factors to investigate the time and size dependence of shape once this modelling methodology is applied to model the aggregation/agglomeration behaviour of NPs. If aggregation/agglomeration occurs, the normal distances for some faces may disappear with some new distances appearing. If breakage occurs, some new normal distances will be identified to represent the new faces. Such alternative approaches are useful for nano-(Q)SAR applications because they take into account the dynamic nature of NP shape.
3.1.3 Crystal Structure (Crystallinity)
ENMs with the same chemical composition may have different toxicological properties because of their different atomic arrangements and crystal structure. Jiang et al. [62] investigated the effect of crystallinity on NP activity by comparing the ROS generating capacity of TiO2 NPs with similar size but different crystal phases (amorphous, anatase, rutile, and anatase/rutile mixtures). The study found that amorphous samples showed the highest level of ROS activity followed by pure anatase and anatase/rutile mixtures, while pure rutile produced the lowest level of ROS. Nanosilica, which occurs in multiple forms, is another ENM whose toxicity may vary depending on the nature of its crystal structure [82].
A widely used technique to obtain information about crystal phases, purity, crystal structure, crystallite size, lattice constants, and defects of NPs is X-ray diffraction (XRD). XRD is a useful tool to characterize nanostructures because it provides nondestructive evaluation of the structural characteristics without the need for exhaustive sample preparation [28]. Its noncontact and nondestructive features make XRD ideal for in situ measurements [113]. Measurement in a desired atmosphere is allowed in XRD. This makes XRD advantageous for toxicological characterization in which collection of crystal structure data in biologically relevant media becomes an important issue.
Additionally, high-resolution transmission electron microscopy (HR-TEM) and selected-area electron diffraction (SAED) can be used to obtain information about the crystal structure, especially when data acquisition from individual nanocrystals is required. We believe that conventional XRD is preferable over TEM for crystallographic investigation of nanostructures because of the sample-damaging and the user-dependent nature of TEM.
3.1.4 Surface Characteristics
3.1.4.1 Surface Functionalization
Surface chemistry is another factor that needs to be considered for the complete characterization of NPs, because it plays an important role in the surface interactions and aggregation behavior of NPs in liquid media. Therefore, if the surfaces of ENMs are intentionally functionalized, each chemical species and functional groups on the surface should be identified. The influence of surface coating on the toxicity of Ag-NPs has been investigated by many researchers [21, 83, 140]. The results from Nguyen et al. [83] showed that uncoated Ag-NPs are more toxic than coated Ag-NPs. However, the coating is not the only factor that reduces the toxicity of Ag-NPs. Changes in the aggregation state and particle size as a result of surface coating may also be important.
Information about how the ENM surface affects the interactions of NPs in a biological environment can be obtained from different techniques, such as electron spectroscopy (X-ray photoelectron spectroscopy (XPS) and Auger electron spectroscopy (AES)), scanning probe microscopy (AFM and scanning tunneling microscopy (STM)), ion-based methods (secondary ion mass spectrometry and low-energy ion scattering), and other spectroscopic techniques (e.g., IR, NMR, and Raman spectroscopy) [6]. The most important advantage of electron spectroscopy is its high surface sensitivity. XPS is one of the most commonly used techniques for surface analysis [125]. Both XPS and AES can be used to obtain information about the presence, relative surface enrichment, composition, and thickness of coatings.
3.1.4.2 Surface Charge
Surface charge is another important characteristic that may affect the toxicity of ENMs. The biological interactions of ENMs, and hence their biological activities, are highly surface-charge dependent. Park et al. [91] analyzed the effect of surface charge on toxicity using negatively and weakly negatively charged silica-NPs. They found that negatively charged silica-NPs have a higher level of cytotoxicity than weakly negatively charged silica-NPs. In another study, the core of silicon-NPs was covered with different organic monolayers to obtain different surface charges (positive, negative, and neutral) [10]. The study found that positively charged silicon-NPs are more toxic than neutral silicon-NPs, while negatively charged silicon-NPs induced almost no cytotoxicity.
Because it is challenging to directly measure the charge at the surface of particles, zeta potential measurement using dynamic or electrophoretic light scattering is usually used to quantify the surface charge. According to Xu [136], among the three techniques that can be used to determine the zeta potential (electrophoretic light scattering (ELS), and acoustic and electroacoustic methods), ELS is preferred for various applications because of its certainty, sensitivity, and versatility. However, classic ELS cannot successfully determine the zeta potential of turbid samples because the light cannot penetrate the sample. Preferably, the sample should be optically clean and nonturbid for accurate measurements. It was also noted in the same study that the accuracy of zeta potential measurements is greatly affected by environmental conditions, such as pH and ionic strength. The pH-dependence of the zeta potential should also be taken into account because changing the pH of a solution may greatly alter the distribution of surface charge.
The current understanding of the relationship between surface charge and toxicity is severely limited, mainly because of the incapability of existing in situ measurement techniques and the environment-dependence of zeta potential measurements [61]. Because the value of the zeta potential obtained may vary between different techniques and experiments [38], multiple tests should be conducted for the best possible accuracy and the results should be reported together with details on measurement conditions (e.g. pH value and sample concentration).
3.1.5 Aggregation State
Some NPs have the tendency to form large agglomerates both in the dry form and in suspension. If NPs form clusters, they may behave like larger particles because of their increased hydrodynamic size [20]. Because agglomeration could affect important physicochemical features, such as particle size and the size distribution, the biological effects of these changes should be identified to avoid incorrect estimation of the toxic potential of ENMs [61].
The aggregation state is often quantified by measuring the size distribution of existing agglomerates. It can be monitored and quantified by microscopic techniques such as TEM, SEM, and AFM. Additionally, DLS can also be used to investigate NP aggregation. However, characterization of the agglomerate size of NPs in suspensions is very challenging because the degree of aggregation can be influenced by external conditions (e.g., pH, temperature, and humidity). Ideally, in situ instruments that are capable of measuring the size, shape, and number of all agglomerates in the relevant medium are required to characterize the aggregation state. The particle size information used in early nanotoxicological studies usually refers to the primary size of individual NPs and ignores the effect of aggregation. Although accurate characterization of the aggregation state prior to nanotoxicity testing is seen as a prerequisite by several researchers [13, 61, 129], there is still no clear consensus on how to characterize aggregation. However, characterizing the aggregation shape using fractal dimensions, which provide an index of complexity by measuring the space-filling capacity of an object, may be the way forward [109].
3.2 NP-Specific Descriptors
Because some properties of ENMs are different from conventional materials, it is very likely that also the toxicity of ENMs could be different and associated to nanophenomena. Therefore, the development of nanospecific descriptors capable of describing the distinctive properties of NPs is one of the main research requirements in the area of computational nanotoxicology. In this section, the different approaches to develop novel NP-descriptors will be presented.
Glotzer and Solomon [39] proposed an approach to characterize NPs based on microscopic images. They defined eight orthogonal dimensions that can be used as NP-descriptors to compare the structural similarity of different NPs: surface coverage, aspect ratio, faceting, pattern quantization, branching, chemical ordering, shape gradient, and variation in roughness (Fig. 5.2). Although the development of new descriptors based on microscopic images is a promising idea, the numerical expression of these eight dimensions is still an unresolved problem.

Derivation of eight qualitative descriptors based on microscopic images (Reprinted from Nature materials, 6, Glotzer et al., Anisotropy of building blocks and their assembly into complex structures., 557–562., Copyright (2007), with permission from Elsevier)
The idea suggested by Glotzer and Solomon [39] has inspired other researchers to use microscopic images of NPs for the extraction of structural information. Puzyn et al. [97] proposed to quantify each pixel in SEM, TEM, and AFM images using RGB colour codes or gray-scale representation, and then produce a rectangular array of numbers (Fig. 5.3). They also emphasized that these numerical values of image pixels can be used as new descriptors for encoding the structural properties of NPs.

Derivation of structural descriptors based on microscopic images (Reprinted from Small, 5, Puzyn et al., Toward the development of “nano-QSARs”: advances and challenges., 2494–509., Copyright (2009), with permission from John Wiley and Sons)
In another study, Xia et al. [133] developed a multidimensional biological surface adsorption index (BSAI) consisting of five quantitative nanodescriptors: lone-pair electrons, polarity/polarizability, hydrogen-bond donors, hydrogen-bond acceptors, and London dispersion. These five nanodescriptors represent the fundamental forces governing the adsorption process of NPs in a biological environment. In their follow-up study [134], they performed PCA on five-dimensional nanodescriptor datasets to reduce dimensionality, and obtained a two-dimensional representation of the molecular interaction forces in biological systems and hence facilitated characterization of the surface properties of ENMs (Fig. 5.4). After obtaining two-dimensional nanodescriptors via PCA, they managed to classify 16 different ENMs into separate clusters based on their surface adsorption properties.

Derivation of descriptors that represent the fundamental forces governing the adsorption process of NPs (Reprinted by permission from Macmillan Publishers Ltd.: Nat Nano, Xia, et al. An index for characterization of nanomaterials in biological systems. Nat Nano, 5, 671–675, copyright (2010))
Burello and Worth [19] proposed that different types of spectra (e.g., NMR, IR, Raman, and UV–Vis) can be used as nanodescriptors because they contain fingerprint-like information (Fig. 5.5). The first step is spectral measurement followed by conversion of the spectra into a numerical matrix. This data matrix can be seen as spectra-derived descriptors and used for (Q)SAR analysis. It is not entirely a new perspective because spectral information has already been used in a number of studies. The use of IR information for (Q)SAR analysis was shown to be promising by Benigni et al. [9]. They compared the IR spectra with several descriptors commonly used in (Q)SAR studies, and found that IR spectra contain unique information that cannot be obtained from molecular descriptors. Zhou et al. [141] used the spectra of multiwalled NTs for characterization, while Yang et al. [137] attempted to correlate XRD data with photocatalytic performance using the dye decolourization rate. We strongly believe that the use of spectra-derived descriptors in (Q)SAR modelling of ENMs is an interesting approach and deserves further investigation.

Derivation of NP-descriptors based on the spectra of ENMs (Reprinted from Wiley Interdisciplinary Reviews: Nanomedicine and Nanobiotechnology, 3, Burello et al., QSAR modeling of nanomaterials., 298–306., Copyright (2011), with permission from John Wiley and Sons)
The final properties of materials are related not only to the chemical composition and structure of materials but also to the preparation, synthesis, and processing methods. Le et al. [68] suggested that molecular descriptors characterizing physicochemical properties of compounds could be combined with historical descriptors describing the sample preparation and synthesis techniques of materials to develop reliable and predictive models. Although historical descriptors can be useful for modelling traditional materials, their implementation to nano-(Q)SAR models can be very difficult because they probably have no ability to distinguish between ordinary and nanosized particles. The determination of three-dimensional descriptors that are suitable for nanostructures and NP representation is another promising approach and undoubtedly will be put into practice in the near future. In addition, the development of more sophisticated image analysis approaches (e.g., texture analysis-based methods) would facilitate the rapid extraction of morphological information (e.g., particle size, shape, surface area, and aggregation state) from microscopic images of NPs.
4 Nano-(Q)SAR and Modelling Techniques
A (Q)SAR is a mathematical model that attempts to relate the biological activities or properties of a series of chemicals to their physicochemical characteristics in a quantitative manner [99]. Although the first use of (Q)SAR models is attributed to Hansch [50], who brought physical organic chemistry and the study of chemical biological interactions together to propose the first (Q)SAR approach, the relationship between chemical structure and biological activity was reported in several earlier studies ([16, 103]., [89]). Hansch’s (Q)SAR approach has found applications in many disciplines, such as drug design, and chemical and biological science. Moreover, numerous modification of Hansch’s approach to QSAR modelling have been developed by many other researchers [66].
In (Q)SAR models, it is assumed that the observable biological activity is correlated with the structure of compounds, and this correlation can be expressed in a mathematical equation. The presumed relationship between the activity and structure is expressed with the following form of mathematical equation:
where y is the biological activity of the chemical (i.e., toxicity) and f(x i ) is a function of structural properties. A set of well-characterized compounds with known biological effects is required to obtain this mathematical equation. The structural features of compounds with known biological activities are represented by measured or calculated molecular descriptors. Then, a mathematical model relating the measured activity to the descriptor sets is obtained by regression analysis. The last step is evaluation of the reliability of the model and its applicability to other compounds. One of the most important steps, which is often omitted, is to define the model’s boundaries and limitations to demonstrate how well it performs when applied to substances that are not used in building the model.
4.1 Nano-(Q)SAR Research
The papers focusing on the development of nano-(Q)SAR models are given in Table 5.4. Most of the nano-(Q)SAR studies focused on metal oxide (MO) ENMs because of their common commercial use and high production volume. One of the first attempts to show that computational (Q)SAR can give valuable information about nanotoxicity was reported by Liu and Hopfinger [71]. They used molecular dynamic simulations to investigate the effect of CNT insertion on the cellular membrane structure. Four potential toxicity sources were investigated through membrane interaction-(Q)SAR analysis. Although the result of this study was very informative and encouraging, a proven (Q)SAR model was not established because of the absence of experimental data.
Sayes and Ivanov [108] assessed the presence of ENM-induced cell damage based on the release of lactate dehydrogenase (LDH) from cells. Six different physical characteristics were measured for each of the selected MO ENMs (TiO2 and ZnO): primary particle size, size in water and two buffered solutions, concentration, and zeta potential. First, they performed principal component and correlation analysis on the preprocessed dataset to reveal possible correlations between the physical properties and LDH release measurements. Although a strong correlation between some of the physical features were observed, such as particle size and concentration in water, no correlation was found between the measured physical properties and cellular cell damage in the principal component analysis. Their initial intention was to use the same dataset to develop a regression and classification model. However, they were unable to develop a statistically significant regression model using the TiO2 and ZnO dataset. The results of classification analysis were better because they managed to produce a classifier with zero resubstitution error. A clear description of the experimental design, ENM preparation, cell culture conditions, and methodology were given in the paper. The inclusion of such knowledge in toxicological research is very important because it greatly improves the interpretability of collected data and enhances its comparability with other studies. The downside of the study is undoubtedly the small number of ENMs and physical descriptors used. It is unrealistic to build a (Q)SAR model with a few ENMs because it does not allow the splitting of the original datasets into training, validation, and test sets. The number of final descriptors used to develop a (Q)SAR model can be less than six, but it is desirable to have a much larger number of initial descriptors, especially in the absence of specific knowledge regarding the relevance of particular properties to nanotoxicity.
In another study, two different experimental nanotoxicity datasets were used to derive a mathematical relationship between the toxicity of ENMs and their physicochemical properties [33]. The advantage of the data used in this study was the concurrent testing of ENMs under the same conditions. In the first case study, three distinct clusters of ENMs were identified based on their biological activity, and support vector machine (SVM) models with high accuracies were developed. In the second case study, a descriptor quantifying lipophilicity was the most significant predictor of biological activity because it accurately discriminated between ENMs with low and high values of PaCa2 cellular uptake. Overall, it was shown that the (Q)SAR approach can provide useful information for toxicity prediction of new ENMs. The methodology used in this work fulfilled all the principles of the OECD for the validation of (Q)SAR models.
Puzyn et al. [100] were one of the first to derive a mathematical equation based on the dataset of cytotoxicity and molecular descriptors. Initially, a set of 12 structural descriptors were quantum-chemically calculated using the semiempirical PM6 method. Among the pool of descriptors, only one structural descriptor (ΔH Me+) representing the enthalpy of formation of a gaseous cation with the same oxidation state as that in the MO structure was used to establish the following nano-(Q)SAR model:
A set of 17 MO-NPs used by Puzyn et al. [100] can be considered as small from a modelling perspective, but the development of such predictive nano-(Q)SAR models is helpful to encourage new investigations.
Another simple but statistically powerful nano-(Q)SAR model was developed by Epa et al. [29] based on the results of in vitro cell-based assays of ENMs. They used the same dataset as Fourches et al. [33] with minor changes. The difference was that new descriptors encoding the presence or absence of some particular features, such as coating, were added. They managed to build the following nano-(Q)SAR equation based on these dummy variables:
where \( {I}_{{\mathrm{Fe}}_2{\mathrm{O}}_3},{I}_{\mathrm{dextran}} \), and I surface charge stand for indicators (taking values of 1 or 0) for the core material, surface coating, and surface charge, respectively. This was the second quantitative model developed to predict the toxicity of nanostructures. Compared with Eq. (2), this mathematical expression was developed from a more diverse set of data.
Recently, the hypothesis that ENM toxicity is a function of some physicochemical properties was tested by Wang et al. [132]. A set of 18 ENMs including carbon-based materials and MOs were used in the study. Different types of cytotoxicity assays were performed, such as LDH, apoptosis, necrosis, hemolytic, and MTT, and several structural and compositional properties were measured. Initially, they applied PCA to the cytotoxicity data to combine the toxicity values measured at different doses into a single value that describes all the data points on the dose–response curve. It should be mentioned that, because toxicity is highly dose-dependent, the toxicological effects are usually evaluated at multiple concentrations in a series of tests, and the results are represented with a dose–response curve. Figure 5.6 shows examples of the dose–response curves obtained for the 18 ENMs. From this graph, the cell viability is lower in the cells treated with N3 (nanotubes), N14 (zinc oxide), and N6 (aminated beads) than the other ENMs. There are various methods to analyze and compare dose–response curves, such as area under the curve, slope of the curve, threshold values, min/max response, and the benchmark dose approach. In this study, Wang et al. [132] performed PCA to integrate the entire curve, and used the resulting principal components as an overall measure of cumulative response. They concluded that, compared with other approaches, PCA-based representation of the dose–response curves provides more reasonable results when ranking the ENMs according to their hazard potential. Because of the high toxicity level of four particular ENMs (zinc oxide, polystyrene latex amine, Japanese nanotubes, and nickel oxide), nano-(Q)SAR analysis focused on these four ENMs to investigate the potential factors behind their observed toxicity. It was concluded that the physicochemical characteristics leading to the toxicity of ENMs were different, and it was not possible to draw a general conclusion that was valid for all toxic ENMs screened in the study. However, the nano-(Q)SAR method was found to be useful to reveal that some of the measured properties, such as metal content, high aspect ratio, and particle charge, were correlated with the toxicity of different nanosized materials.

Viability results for 18 NMs (Wang et al. [132], reprinted by permission of Taylor & Francis Ltd)
Liu et al. [72] developed a classification-based (Q)SAR model based on multiple toxicity assays, 44 iron oxide core NPs, and 4 simple descriptors (size, zeta potential, and relaxivities). They suggested that existing nano-(Q)SAR models did not take into account the acceptance level of false negative to false positive predictions. Unlike previously constructed nano-(Q)SAR models, they also investigated the decision boundaries of the nano-(Q)SARs subject to different acceptance levels of false negative/false positive predictions.
In another study, Liu et al. [73] attempted to relate the physicochemical properties of MO-NPs to their toxicity by developing a structure–activity relationship. A number of classification nano-(Q)SAR models were developed based on a large toxicity dataset of 24 MO-NPs. A set of 30 molecular descriptors were calculated for each NPs, and only two of them (conduction band energy and ionic index) were identified as important molecular descriptors on which the best performing nano-(Q)SAR model was built. Their conclusion was in a good agreement with the results of Burello and Worth [19], who found that the conduction band energy of oxide NPs is related to their toxicity. Similar findings have also been reported by Zhang et al. [139], who indicated that the oxidative stress induced by MO-NPs could be linked to their conduction and valance band energies.
More recently, Singh and Gupta [116] attempted to build classification and regression nano-(Q)SAR models using ensemble methods such as decision tree forest (DTF) and decision tree boost (DTB). Five different datasets were used to demonstrate and confirm the suitability of these techniques for the (Q)SAR modelling process by comparing the accuracy of the developed nano-(Q)SARs with past studies. It was concluded that the nano-(Q)SAR models constructed had high performance and statistical significance along with superior predictive ability to previous studies.
From our point of view, the common problem in the majority of published (Q)SAR studies is that it is not possible to generalize the results in the absence of explanatory information regarding the underlying reasons for the system behavior, thus making the usability of these studies limited for compounds outside the study. When the results of (Q)SAR analysis are only valid for the tested compounds, (Q)SAR becomes a data analysis tool with no predictive ability. To ensure the reliability of the established nano-(Q)SARs, researchers should also address model uncertainty arising from experimental error and lack of knowledge. Moreover, most of the existing nano-(Q)SAR studies used small datasets to establish a link between nanostructure and toxicity. Although small datasets can be useful to describe or explain the relationship between NP structure and activity, they may not be very useful for predictive purposes.
Table 5.4 summarises the previously reported nano-(Q)SAR studies and compares their methodologies with OECD principles: (1) a defined endpoint, (2) an unambiguous algorithm, (3) the applicability domain, and (4) model validation for stability and predictivity.
4.2 Nano-(Q)SAR Modelling Techniques
In principle, a variety of methods that have proven to be effective in classic (Q)SAR modelling, such as statistical methods, neural networks and decision trees, can be applied to nano-(Q)SAR. In practice, however, their direct use in ENM toxicity modelling has difficulties. The major obstacle originates from the availability of data, because some (Q)SAR algorithms require large datasets that are not currently available for ENMs. Considering the current scarcity of nanotoxicity data, it is reasonable to use modelling tools that can make effective use of smaller datasets. In addition, there is still insufficient knowledge about physicochemical descriptors that can predict the toxicity of ENMs. Therefore, current nano-(Q)SAR studies should focus on identifying toxicity-related physicochemical characteristics as well as predicting potential toxicity values. The ease of use (i.e., the ease of model building and interpretation of the results) is another important consideration, particularly in the nano-(Q)SAR world where the ability to interpret the resulting models is the key to understanding the correlation between different forms of biological activity and descriptors. Overall, the following factors have to be considered when selecting nano-(Q)SAR modelling techniques:
-
Minimum data requirements. Effective use should be made of limited data without relying on the availability of large datasets.
-
Transparency. Models should be transparent (rather than black-box), intuitive, and able to help identify the physicochemical descriptors that are related to the toxicity of ENMs
-
Ease of model construction. The technique should be easy to use and easy to implement.
-
Nonlinearity. The technique should be able to reveal nonlinear relationships/patterns in the dataset.
-
Low overfitting risk. The technique should have low risk of overfitting, which may reduce the generalization of the model.
-
Descriptor selection function. The technique should have the capability of feature selection to exclude redundant descriptors before model building.
-
Ease of interpretation. The technique should be able to produce meaningful and interpretable outcomes and explain how the outcomes are produced.
-
Low modeller dependency. The technique should have low sensitivity to changes in the model parameters.
Below, some (Q)SAR modelling methods are examined, including decision trees, statistical methods, support vector machines, neural networks, multidimensional visualisation, and knowledge-based expert systems. The focus is on discussing their suitability for nano-(Q)SAR modelling, rather than introducing the individual algorithms. Additionally, feature selection and model validation methods are briefly discussed.
4.2.1 Decision Trees (DTs)
Automatic generation of decision trees from data is a powerful machine learning technique that can be used as a classification or regression tool for categorical and numerical predictions of biological activity in (Q)SAR studies [76]. DTs can be constructed with small, large, or noisy datasets, and then used to detect nonlinear relationships. They have a tree-like structure that splits data points into different classes based on decision rules to categorize and model input data. Various DT generation algorithms are available, and can be broadly classified as shown in Fig. 5.7. The most significant advantages of DT methods are their capability to automatically select the input variables (i.e., the physicochemical descriptors that contribute to the observed toxicity) and to remove descriptors that are not related to the endpoint of interest. In a previous study, Buontempo et al. [17] demonstrated the use of a genetic programming-based DT generation technique for in silico toxicity prediction. They developed a DT model containing five descriptors selected from a pool of more than a thousand descriptors that has good predictive performance for both training and test datasets. This “knowledge discovery” capability is no doubt valuable to identify the physicochemical descriptors that contribute to the toxic effects of ENMs. Such knowledge has even more benefits for eliminating or minimizing the risk of ENMs through engineering approaches (i.e., modification of physicochemical properties that influence the toxicological response through the active engineering of ENMs). Another benefit of DT analysis is its capability to avoid the (Q)SAR model being overbiased towards data in dense areas, which is a problem with some other techniques, such as linear regression and neural networks. Small data cases, i.e., data outside the dense data area, can also be modelled as branches of a decision tree. An additional advantage of DTs is the ease of their interpretability and transparency [77]. Investigation of DTs for modelling ENM toxicity requires more research, because, in addition to the abovementioned advantages, there are researchers who have voiced concerns about the generalization ability and predictive power of DTs [8]. DTs (and their extension known as “random forest”) have been investigated for (Q)SAR modelling in a number of studies [2, 3, 49, 76, 119]. Further research on DTs should focus on maximizing their advantages and overcoming their limitations. An interesting example is random decision forest, and several studies have shown its improved generalization ability over DTs [37, 77, 121].

Family tree of proposed inductive learning techniques showing a selection of specific implementations of each type (Reprinted from Particuology, 21, Ceyda Oksel et al., (Q)SAR modelling of nanomaterial toxicity: A critical review, 1–19., Copyright (2015), with permission from Elsevier)
4.2.2 Statistical Methods and Feature Selection
Several statistical methods, such as multiple linear regression (MLR), principal component regression (PCR), and partial least squares (PLS) regression, have been extensively studied in (Q)SAR analysis because of their ease of use and interpretation [138]. PLS is a linear regression method that handles data cases where the number of predictors is greater than the number of compounds. The PLS method works well when there are several noisy and intercorrelated descriptors, and also allows multiple responses to be simultaneously modelled . The usefulness of PLS in (Q)SAR studies, especially when the descriptors are highly correlated and numerous, has been proven by several researchers [23, 27, 30, 43, 75]. However, this method can only be used for the solution of linear regression problems. To overcome this problem, nonlinear versions of the PLS method have been developed based on different algorithms, such as kernel-based PLS [104], neural network PLS [101], and genetic algorithm-based PLS [51]. These extensions allow nonlinear relationships to be modelled in (Q)SAR studies, which is not otherwise possible with the simple PLS technique. Although MLR is one of the most common modelling techniques used to develop regression-based (Q)SAR models, there are three main factors limiting the use of MLR in nanotoxicity modelling: the linearity assumption, i.e., it cannot detect nonlinear causal relationship; the restriction on the ratio of compounds to predictors in the data, i.e., the lowest ratio of the number of ENMs to the number of descriptors should be 5:1; and the dependence of its performance on redundant variables, i.e., the presence of correlated input variables and input variables that are irrelevant to the output may lead to poor model performance [110]. Dimension reduction methods, such as PCA, can be useful for eliminating correlations between input variables (i.e., physicochemical descriptors) without removing information about irrelevant variables that may still affect the model performance. Overall, the main advantage of linear models, such as MLR and PLS, over nonlinear models is their transparency. Some information of the relative importance of the physicochemical descriptors can be directly obtained from a linear model by examining the weights, whereas some nonlinear models, such as neural networks, cannot give such direct information.
The feature selection process is different from the above mentioned dimension reduction technique, i.e., PCA, in that it selects only the inputs that have an effect on the outputs. The input variables that have little or no effect on the outputs are removed during the model building process. Among the various methods for automatic input feature selection, the genetic algorithm (GA) has shown excellent performance. The GA feature selection approach can be applied together with almost all (Q)SAR model building algorithms. The GA starts from a population of possible solutions (called individuals of chromosomes), which can be randomly generated. Each gene in the first generation of solutions consists of randomly selected descriptors. A (Q)SAR model can be built using the randomly selected descriptors in each chromosome. (Q)SAR models built based on the individuals in the initial population of solutions in this first generation are evaluated using a defined fitness function. Based on Darwin’s theory of “survival of the fittest”, individuals undergo operations such as mutation and crossover to generate the population of individuals in the next generation. In summary, a GA algorithm has the following essential steps:
-
1.
Random generation of a set of solutions (the number of solutions can be set by the user) and code into a vector group with fixed length;
-
2.
Generation of a new set of solutions by the method below, or generation of new solutions to substitute individuals in the current population;
-
2.1
Selection of parent individuals based on the value of fitness function;
-
2.2
Crossover to generate one or several subindividuals;
-
2.3
Apply mutation operation to some individuals;
-
2.1
-
3.
Repeat step (2) until one of the stopping criteria is met.
The stopping criteria are reaching the maximum number of generations or time limit, and satisfying the stop criterion for the fitness function. For more detail, please refer to (Reddy et al. [102], Goodarzi et al. [40], Ma and Wang [78]).
4.2.3 Support Vector Machines (SVMs)
There is increasing interest in the use of SVMs, which can handle both regression and classification problems, as an alternative to linear modelling methods such as MLR and PLS in (Q)SAR studies [24, 80]. SVMs can handle many issues that usually affect the performance of other (Q)SAR modelling techniques, such as nonlinear relationships, collinear descriptors, small datasets, and model overfitting [80]. SVMs have good potential for (Q)SAR analysis because of their accuracy and high generalization capability. On the other hand, the main disadvantages of SVMs are the high sensitivity of model performance to the selection of design parameters (e.g., kernel functions) and the complexity of direct interpretation of SVM decisions. SVMs have been used in numerous studies to construct classification [24] and regression [80, 84] based (Q)SAR models. As previously mentioned, GA-based feature selection can be integrated with SVM in (Q)SAR modelling, as shown in near-infrared chemometrics [78].
4.2.4 Artificial Neural Networks (ANNs)
ANNs are algorithms that imitate how the human brain works and computationally simulate human brain activity based on the neural structure of the brain. Although in some cases the poorly understood structure of this technique affects its practical reliability, successful applications of ANNs in the (Q)SAR world [48, 58, 128] keep interest in this method alive. ANNs offer several advantages to (Q)SAR developers, including the ability to deal with the nonlinear nature of structure–activity relationships and large descriptor datasets including unnecessary variables. However, ANNs also have several disadvantages, such as difficulty in interpreting the outcome, selecting the optimum complexity, risk of overfitting, and high sensitivity of the generalization power to changes in parameters and network topology. In some applications, ANN models are treated as a black-box because of their inability to give deep insight into the encoded relationship between the predictors and predicted outcomes [46]. Other studies have suggested that ANN systems should not still be seen as inexplicable models [118] because a number of methodologies facilitating the interpretation of model outcomes have been developed [7, 18, 44]. Furthermore, it should be pointed out that, like other modelling techniques, ANN can be used together with GA-based feature selection algorithms to remove redundant variables during the model building process. In addition, some researchers have investigated the use of the sensitivity analysis method for minimization of the input data dimension and extraction of information about the relative importance of inputs to an output [142].
4.2.5 Multidimensional Visualisation
Multi-dimensional data visualisation is an approach that allows visual exploration of high dimensional data sets in a lower-dimensional display. It significantly contributes to better understanding of the more complex statistical procedures and resulting models in relation to the dataset. It has many important applications and, in particular, can be considered as an important tool to summarise and visually explore the important characteristics of the dataset being analysed. Multidimensional visualisation techniques, such as parallel coordinates [15, 57, 131] and heat maps, are very effective tools for (Q)SAR analysis of toxicity data. They can visually display the causal relationships between ENM physicochemical descriptors and the toxicity endpoints, handle limited datasets, and allow interactive analysis with the aid of interactive functions and multiple colours built in to the software tools. To provide an example, in Fig. 5.8 the data generated by Shaw et al. [114] are scaled, displayed, and coloured using a parallel coordinates graph produced by C Visual Explorer (CVE) tool.

CVE plot of the data collected by Shaw et al. [114] (descriptors: size, relaxivities (R1 and R2), and zeta potential; toxicity endpoints: apoptosis (APO), mitochondrial potential (Mito), reducing equivalents (RED), and ATP content (ATP)). The mean apoptosis data is divided into three categories: low (APO<−1.54), medium (−1.54<APO<−0.74), and high (APO>−0.74), and each category is highlighted in different colors (Reprinted from Particuology, 21, Ceyda Oksel et al., (Q)SAR modelling of nanomaterial toxicity: A critical review, 1–19., Copyright (2015), with permission from Elsevier)
4.2.6 Knowledge-Based Expert Systems
(Q)SAR often refers to data-driven modelling. However, the usefulness of knowledge-based expert systems should not be underestimated, as evidenced by the success of the expert system DEREK of Lhasa Ltd. for toxicity predictions [42]. This expert system draws its knowledge from both literature and databases, and is considered to be one of the most powerful tools for the toxicity predictions of molecules. Considering the gaps and variations in the available ENM toxicity data (i.e., incomplete characterization of physicochemical descriptors and different measures of toxicity), it is our belief that knowledge-based expert systems, ideally with some kind of “text data mining” capability that can continuously capture new knowledge appearing in the literature, might be one of the most effective approaches for nano-(Q)SAR.
4.2.7 Model Validation
Irrespective of the method used to construct the (Q)SAR models, the validity of the outcomes of the predictive models should be evaluated both internally and externally. Internal validation is the process of evaluating the prediction accuracy of (Q)SAR models based on the dataset used in the modelling process. The most common internal validation techniques used in (Q)SAR studies are least squares fit (R 2), chi-squared (χ2), root-mean squared error (RMSE), leave-one-out or leave-many-out cross-validation, bootstrapping, and Y-randomization [127]. The use of external validation techniques in addition to internal validation methods is increasingly being recommended by researchers [126, 127] and authorities [86] for the assessment of (Q)SAR model reliability in the best and most trustworthy way. Moreover, it is always beneficial to use more than one validation metric to quantitatively measure the accuracy of the model prediction.
The definition of the applicability domain of the constructed and statistically validated model is the final, but one of the most important, steps in the (Q)SAR model building process. There are several approaches (e.g., geometry, range, distance, and probability density function based approaches) to define the applicability domain region of statistical models based on different algorithms. For more detailed information about the available approaches for defining the (Q)SAR model applicability domain, refer to the review papers of Jaworska et al. [59] and Sahigara et al. [106].
4.3 Input Data for Nano-(Q)SAR and Its Current Availability
In nano-(Q)SAR models, the importance of high-quality and well-described datasets is even more pronounced because the unique properties of ENMs are mostly associated with particular sizes and conditions [34]. Ideally, the input data required to build a reliable (Q)SAR model should be (1) obtained from a preferably single and standardized protocol, (2) examined in terms of accuracy and suitability for (Q)SAR analysis, and (3) large enough to allow rational division of the data into training and test sets. Because nano-(Q)SAR is a data-based method, the accuracy of the data determines the quality of the final model. Therefore, it is very important to create a comprehensive nanotoxicity database and make it broadly accessible.
In a recent study, Lubinski et al. [74] developed a framework to help modellers evaluate the quality of existing data for modelling (e.g., nano-(Q)SAR) purposes. In the first part of their study, they provided a set of criteria that are mostly related to the source and quantity of the data, experimental procedures, and international standards followed during the characterization process and documentation. In the second part, they assessed the quality of a collection of nanotoxicity data by scoring them according to the proposed criteria. The majority (201 out of 342 data points) of the dataset that was collected and scored was evaluated as useful with restrictions for developing (Q)SAR-like models.
In fact, there is now a great amount of data on nanotoxicity. However, the majority of the available data on ENM toxicity comes from studies focusing on a few ENMs, and hence is not useful for modelling purposes. At this point it should be noted that the data obtained by different research groups is often incomparable because of the differences in experimental procedures (e.g., sample preparation, dispersion protocols, assay types, cell types and exposure doses) and ENMs used (e.g., size, shape and surface modifications). Therefore, the data to be modelled should preferably come from the same study/project until standardized testing procedures and specific types of reference materials are available and accepted. Often, the physicochemical properties measured are not directly related to the toxicity of ENMs because characterization was carried out in the absence of a test medium.
Predefined data formats are necessary to facilitate the storage, maintenance, and exchange of ENM data between different researchers. There are a large number of freely available toxicity databases, most of which are more general in scope and not customized for particular purposes. Commercially available ENM-specific databases are still at the research stage and limited to a few applications. ISA-TAB-NANO introduced by Thomas et al. [123] is a standard NM data sharing format that facilitates the import/export of NM data and enables data exchange between different nanotechnology laboratories and researchers. The ISA-TAB-NANO specification uses four different spreadsheet-based file formats: investigation, study, assay, and material file format.
The OECD WPMN initially launched a database on Research into Safety of Manufactured Nanomaterials in 2009 [87]. However, it does not provide direct access to data because the overall outcomes and outputs section is usually filled in as “publications”. Furthermore, as interest weaned, the systematic updating has been discontinued and the database put on hold.
NANOhub is a database for managing information about ENMs. It currently hosts several projects, but the access to data is usually restricted to only project participants. The experience of collecting data in NANOhub has been captured in OECD harmonised templates (OHTs) to report regulatory studies for some of the physicochemical endpoints for nanomaterials. These additional templates will also be integrated in the International Uniform Chemical Information Database (IUCLID) under REACH for registration. Another data sharing portal that provides access to ENM characterization and in vitro toxicity data is caNanoLab. The main aim of this data repository is to facilitate the sharing of knowledge on nanomedicine.
An alternative approach for collecting nanotoxicity data is to use text mining techniques to develop a customized knowledge repository system. The Nano Health and Environmental Commented Database (NHECD) is a text mining tool that allows automated extraction of information about the effects of ENMs on human health and the environment from scientific papers. However, the current performance of such NM databases using text mining algorithms is not very good because of the nonstandardized recording of ENM information and the difficulties in extracting numerical data from plots (i.e., a large amount of published data in nanotoxicity is available only in the form of plots) and. At this stage, it is important to ensure that all data is recorded in a universally agreed format to facilitate the extraction of ENM information from the literature. The existence of specifications for ENM information sharing is also very important from the viewpoint of (Q)SAR modelling, because the establishment of predictive (Q)SAR models requires close collaboration between different disciplines and research groups. The development of an agreed ontology for ENMs and nanosafety research (i.e., a formal representation of nanostructures, biological properties, experimental model systems, conditions, and protocols) will facilitate not only collection of nanotoxicity data, but also data mining and resource integration efforts.
5 Final Remarks
Despite the clear benefits that nanotechnology can bring to various sectors of industry, there are serious concerns about the potential health risks associated with ENMs, intensified by the limited understanding of what makes ENMs toxic and how to make them safe. As the use of ENMs for commercial purposes and the number of workers/end-users being exposed to these materials on a daily basis increases, the need for assessing the potential adverse effects of multifarious ENMs in a time- and cost-effective manner becomes more apparent. One strategy to alleviate the problem of testing a large number and variety of ENMs in terms of their toxicological properties is through the development of computational models that decode the relationships between the physicochemical features of ENMs and their toxicity. Such data-driven models can be used for hazard screening, early identification of potentially harmful ENMs and the toxicity-governing physicochemical properties, and accelerating the decision-making process by maximising the use of existing data. Moreover, these models can also support industrial, regulatory and public needs for designing inherently safer ENMs. Therefore, the idea of using time- and cost-saving computational approaches such as (Q)SAR in nanotoxicology has gained popularity in recent years and attracted the interest of regulators and researchers aiming at moving from animal-based individual toxicity assessments toward a more integrated hazard screening approach.
(Q)SAR models have been successfully used by engineers, and physical and medicinal chemists to predict hazardous properties of molecules for over 50 years. Although adaptation of the (Q)SAR approach to nanotoxicology has been encouraged by many investigators [19, 98], there are still several barriers that need to be overcome to establish predictive, reliable, and legally acceptable nano-(Q)SAR models. The current toxicity measurement methods used for bulk materials are not always fully adequate to examine ENMs and would, in any case, have to be used with due attention to the material tested. The WPMN launched a series of expert meetings to review the applicability of the OECD test guidelines to ENMs and to identify gaps in availability of test guidelines, resulting in a number of proposals to the OECD Test Guidelines Programme for updating existing guidelines and adding new ones with a view to better address the testing needs of ENMs.
As the available nanotoxicity data is far from ideal for modelling purposes, the choice of nano-(Q)SAR tools used should be made by considering the nature of the existing data (e.g. limited datasets, collinear input data) and desired outcomes (e.g. easily-interpretable models). Previous research on in silico analysis of ENMs toxicity has shown that although computerised (Q)SAR models are useful for modelling nanotoxicity endpoints, they have limited robustness and predictivity, and interpretation of the models they generate can be problematic. The main problem is caused due to the most commonly used (Q)SAR modelling methods working best with large data sets, but are not particularly good at feature selection, and cannot handle collinear input data. Ideally, new computational modelling tools or new ways of using existing tools are required to model the relatively sparse and sometimes lower quality data on the biological effects of ENMs.
Predictive models such as (Q)SAR have great potential to fill in data gaps on nanotoxicity and to be used as a priority-setting method for risk assessment of ENMs. Once all the potential risks are identified by means of toxicity screening methods including in silico models (e.g. (Q)SAR), the next step is the implementation of risk reduction measures for those risks that are outside the range of tolerable limits.While the past studies provided strong evidence that data-driven computational methods can provide useful information for hazard screening and risk assessment of ENMs, much research remains to be done on order to be able to develop optimal and regulatory acceptable nano-(Q)SAR models. Clearly, more comprehensive and high-quality datasets are necessary before obtaining optimal nano-(Q)SAR models. To improve the accuracy of computational models, quality issues associated with experimental data used to develop the model in the first place must be tackled. Moreover, the development of novel descriptors that are able to express the specificity of nano-characteristics would also be of interest. Another problem that complicates the development of predictive models is the heterogeneity of the ENM family. There is a need to generate homogeneous datasets that include specific types or individual classes of ENMs since different types of ENMs are likely to have different mechanisms of toxicity. Despite open questions and uncertainties addressed in this chapter, the results of published nano-(Q)SAR studies have provided quantitative insights leading to toxicity predictions of ENMs. To further prove the usefulness of nano-(Q)SAR approach for ENM toxicity prediction, there is a need for more case studies on high quality datasets associated with a set of ENMs with similar core composition but varying physicochemical properties (e.g. size, shape, surface charge etc.) examined under realistic and identical experimental conditions.
References
Akbari B, Tavandashti MP, Zandrahimi M (2011) Particle size characterization of nanoparticles–a practical approach. Iran J Mater Sci Eng 8:48–56
Andres C, Hutter MC (2006) CNS permeability of drugs predicted by a decision tree. QSAR Combin Sci 25:305–309
Arena VC, Sussman NB, Mazumdar S, Yu S, Macina OT (2004) The utility of structure–activity relationship (SAR) models for prediction and covariate selection in developmental toxicity: comparative analysis of logistic regression and decision tree models. SAR QSAR Environ Res 15:1–18
Arora S, Rajwade JM, Paknikar KM (2012) Nanotoxicology and in vitro studies: the need of the hour. Toxicol Appl Pharmacol 258:151–165
Asare N, Instanes C, Sandberg WJ, Refsnes M, Schwarze P, Kruszewski M, Brunborg G (2012) Cytotoxic and genotoxic effects of silver nanoparticles in testicular cells. Toxicology 291:65–72
Baer DR, Gaspar DJ, Nachimuthu P, Techane SD, Castner DG (2010) Application of surface chemical analysis tools for characterization of nanoparticles. Anal Bioanal Chem 396:983–1002
Baskin I, Ait A, Halberstam N, Palyulin V, Zefirov N (2002) An approach to the interpretation of backpropagation neural network models in QSAR studies. SAR QSAR Environ Res 13:35–41
Bengio Y, Delalleau O, Simard C (2010) Decision trees do not generalize to new variations. Comput Intell 26:449–467
Benigni R, Passerini L, Livingstone DJ, Johnson MA, Giuliani A (1999) Infrared spectra information and their correlation with QSAR descriptors. J Chem Inf Comput Sci 39:558–562
Bhattacharjee S, De Haan LH, Evers NM, Jiang X, Marcelis AT, Zuilhof H, Rietjens IM, Alink GM (2010) Role of surface charge and oxidative stress in cytotoxicity of organic monolayer-coated silicon nanoparticles towards macrophage NR8383 cells. Part Fibre Toxicol 7:25
Bootz A, Vogel V, Schubert D, Kreuter J (2004) Comparison of scanning electron microscopy, dynamic light scattering and analytical ultracentrifugation for the sizing of poly (butyl cyanoacrylate) nanoparticles. Eur J Pharm Biopharm 57:369–375
Borchert H, Shevchenko EV, Robert A, Mekis I, Kornowski A, Grübel G, Weller H (2005) Determination of nanocrystal sizes: a comparison of tem, saxs, and xrd studies of highly monodisperse CoPt3 particles. Langmuir 21:1931–1936
Boverhof DR, David RM (2010) Nanomaterial characterization: considerations and needs for hazard assessment and safety evaluation. Anal Bioanal Chem 396:953–961
Boyd RD, Pichaimuthu SK, Cuenat A (2011) New approach to inter-technique comparisons for nanoparticle size measurements; using atomic force microscopy, nanoparticle tracking analysis and dynamic light scattering. Colloids Surf A Physicochem Eng Asp 387:35–42
Brooks RW, Wilson JG (2011). Method and a system for operating a controllable multi-variable process. US Patent No 7916140
Brown AC, Fraser TR (1868) V.—On the connection between chemical constitution and physiological action. Part. I.—On the physiological action of the salts of the ammonium bases, derived from strychnia, brucia, thebaia, codeia, morphia, and nicotia. Transact Royal Soc Edinburgh 25:151–203
Buontempo FV, Wang XZ, Mwense M, Horan N, Young A, Osborn D (2005) Genetic programming for the induction of decision trees to model ecotoxicity data. J Chem Inf Model 45:904–912
Burden FR, Winkler DA (1999) Robust QSAR models using Bayesian regularized neural networks. J Med Chem 42:3183–3187
Burello E, Worth A (2011) QSAR modeling of nanomaterials. Wiley Interdiscip Rev Nanomed Nanobiotechnol 3:298–306
Buzea C, Pacheco II, Robbie K (2007) Nanomaterials and nanoparticles: sources and toxicity. Biointerphases 2:Mr17–Mr71
Caballero-Díaz E, Pfeiffer C, Kastl L, Rivera-Gil P, Simonet B, Valcárcel M, Jiménez-Lamana J, Laborda F, Parak WJ (2013) The toxicity of silver nanoparticles depends on their uptake by cells and thus on their surface chemistry. Part Part Syst Charact 30(12):1079–1085
Chau YT, Yap CW (2012) Quantitative nanostructure–activity relationship modelling of nanoparticles. RSC Adv 2:8489–8496
Cramer RD, Bunce JD, Patterson DE, Frank IE (1988) Crossvalidation, bootstrapping, and partial least squares compared with multiple regression in conventional QSAR studies. Quant Struct Act Relat 7:18–25
Czermiński R, Yasri A, Hartsough D (2001) Use of support vector machine in pattern classification: application to QSAR studies. Quant Struct Act Relat 20:227–240
Dhawan A, Sharma V (2010) Toxicity assessment of nanomaterials: methods and challenges. Anal Bioanal Chem 398:589–605
Domingos RF, Baalousha MA, Ju-Nam Y, Reid MM, Tufenkji N, Lead JR, Leppard GG, Wilkinson KJ (2009) Characterizing manufactured nanoparticles in the environment: multimethod determination of particle sizes. Environ Sci Technol 43:7277–7284
Dunn W, Wold S, Edlund U, Hellberg S, Gasteiger J (1984) Multivariate structure-activity relationships between data from a battery of biological tests and an ensemble of structure descriptors: the PLS method. Quant Struct Act Relat 3:131–137
Edelstein AS, Cammaratra R (1998) Nanomaterials: synthesis, properties and applications. CRC Press, New York
Epa VC, Burden FR, Tassa C, Weissleder R, Shaw S, Winkler DA (2012) Modeling biological activities of nanoparticles. Nano Lett 12:5808–5812
Eriksson L, Gottfries J, Johansson E, Wold S (2004) Time-resolved QSAR: an approach to PLS modelling of three-way biological data. Chemom Intel Lab Syst 73:73–84
Fadel TR, Steevens JA, Thomas TA, Linkov I (2015) The challenges of nanotechnology risk management. Nanotoday 10:6–10
Foldbjerg R, Dang DA, Autrup H (2011) Cytotoxicity and genotoxicity of silver nanoparticles in the human lung cancer cell line, A549. Arch Toxicol 85:743–750
Fourches D, Pu D, Tassa C, Weissleder R, Shaw SY, Mumper RJ, Tropsha A (2010) Quantitative nanostructure− activity relationship modeling. ACS Nano 4:5703–5712
Gajewicz A, Rasulev B, Dinadayalane TC, Urbaszek P, Puzyn T, Leszczynska D (2012) Advancing risk assessment of engineered nanomaterials: application of computational approaches. Adv Drug Deliv Rev 64(15):1663–1693
Gajewicz AEA (2012) Advancing risk assessment of engineered nanomaterials: application of computational approaches. Adv Drug Deliv Rev 64:1663–1693
Gallegos SA, Burello E, Worth A (2009) Review of computational approaches for predicting the physicochemical and biological properties of nanoparticles [online]. European Commission, Italy
Genuer R, Poggi J-M, Tuleau-Malot C (2010) Variable selection using random forests. Pattern Recogn Lett 31:2225–2236
Glawdel T, Ren C (2008) Zeta potential measurement. Encyclopedia of microfluidics and nanofluidics. Springer, New York
Glotzer SC, Solomon MJ (2007) Anisotropy of building blocks and their assembly into complex structures. Nat Mater 6:557–562
Goodarzi M, Saeys W, Deeb O, Pieters S, Vander Heyden Y (2013) Particle swarm optimization and genetic algorithm as feature selection techniques for the QSAR modeling of imidazo [1, 5-a] pyrido [3, 2-e] pyrazines, inhibitors of phosphodiesterase 10a. Chem Biol Drug Des 82:685–696
Gratton SE, Ropp PA, Pohlhaus PD, Luft JC, Madden VJ, Napier ME, Desimone JM (2008) The effect of particle design on cellular internalization pathways. Proc Natl Acad Sci 105:11613–11618
Greene N, Judson P, Langowski J, Marchant C (1999) Knowledge-based expert systems for toxicity and metabolism prediction: DEREK, StAR and METEOR. SAR QSAR Environ Res 10:299–314
Gu C, Goodarzi M, Yang X, Bian Y, Sun C, Jiang X (2012) Predictive insight into the relationship between ahr binding property and toxicity of polybrominated diphenyl ethers by PLS-derived QSAR. Toxicol Lett 208:269–274
Guha R, Stanton DT, Jurs PC (2005) Interpreting computational neural network quantitative structure-activity relationship models: a detailed interpretation of the weights and biases. J Chem Inf Model 45:1109–1121
Gurr J-R, Wang AS, Chen C-H, Jan K-Y (2005) Ultrafine titanium dioxide particles in the absence of photoactivation can induce oxidative damage to human bronchial epithelial cells. Toxicology 213:66–73
Guyon I, Elisseeff A (2003) An Introduction To Variable And Feature Selection. J Mach Learn Res 3:1157–1182
Gwaze P, Annegarn HJ, Huth J, Helas G (2007) Comparison of particle sizes determined with impactor, AFM and SEM. Atmos Res 86:93–104
Habibi-Yangjeh A, Danandeh-Jenagharad M, Nooshyar M (2006) Application of artificial neural networks for predicting the aqueous acidity of various phenols using QSAR. J Mol Model 12:338–347
Han L, Wang Y, Bryant SH (2008) Developing and validating predictive decision tree models from mining chemical structural fingerprints and high–throughput screening data in PubChem. BMC Bioinf 9:401
Hansch C (1969) Quantitative approach to biochemical structure-activity relationships. Acc Chem Res 2:232–239
Hasegawa K, Miyashita Y, Funatsu K (1997) GA strategy for variable selection in QSAR studies: GA-based PLS analysis of calcium channel antagonists⊥. J Chem Inf Comput Sci 37:306–310
Hassellöv M, Kaegi R (2009) Analysis and characterization of manufactured nanoparticles in aquatic environments. Wiley, London
Holgate ST (2010) Exposure, uptake, distribution and toxicity of nanomaterials in humans. J Biomed Nanotechnol 6:1–19
Hoo CM, Starostin N, West P, Mecartney ML (2008) A comparison of atomic force microscopy (AFM) and dynamic light scattering (DLS) methods to characterize nanoparticle size distributions. J Nanopart Res 10:89–96
Horie M, Fujita K (2011) Toxicity of metal oxides nanoparticles. Adv Mol Toxicol 5:145–178
Hosokawa M, Nogi K, Naito M, Yokoyama T (2007) Nanoparticle technology handbook. Elsevier, Amsterdam
Inselberg A (2009) Parallel coordinates: visual multidimensional geometry and its applications. Springer, New York
Jalali-Heravi M, Asadollahi-Baboli M, Shahbazikhah P (2008) QSAR study of heparanase inhibitors activity using artificial neural networks and Levenberg–Marquardt algorithm. Eur J Med Chem 43:548–556
Jaworska J, Aldenberg T, Nikolova N (2005) Review of methods for assessing the applicability domains of SARS and QSARS. Altern Lab Anim 33:445–459
Jeng HA, Swanson J (2006) Toxicity of metal oxide nanoparticles in mammalian cells. J Environ Sci Health A 41:2699–2711
Jiang J, Oberdörster G, Biswas P (2009) Characterization of size, surface charge, and agglomeration state of nanoparticle dispersions for toxicological studies. J Nanopart Res 11:77–89
Jiang J, Oberdörster G, Elder A, Gelein R, Mercer P, Biswas P (2008) Does nanoparticle activity depend upon size and crystal phase? Nanotoxicology 2:33–42
Kar S, Gajewicz A, Puzyn T, Roy K (2014) Nano-quantitative structure–activity relationship modeling using easily computable and interpretable descriptors for uptake of magnetofluorescent engineered nanoparticles in pancreatic cancer cells. Toxicol In Vitro 28:600–606
Karlsson HL, Gustafsson J, Cronholm P, Möller L (2009) Size-dependent toxicity of metal oxide particles—a comparison between nano-and micrometer size. Toxicol Lett 188:112–118
Kübart SA, Keck CM (2013) Laser diffractometry of nanoparticles: frequent pitfalls & overlooked opportunities. J Pharma Technol Drug Res 2:17
Kubinyi H (2008) QSAR, QSAR: Hansch analysis and related approaches. Wiley, New York
Laidlaw, I. & Steinmetz, M. 2005. Introduction to differential sedimentation. Analytical ultracentrifugation. The Royal Society of Chemistry, Cambridge, pp 270–290.
Le T, Epa VC, Burden FR, Winkler DA (2012) Quantitative structure–property relationship modeling of diverse materials properties. Chem Rev 112:2889–2919
Lee D-H, Cho G, Lim HM, Kim DS, Kim C, Lee S-H (2013) Comparisons of particle size measurement method for colloidal silica. J Ceram Process Res 14:274–278
Lin W, Xu Y, Huang C-C, Ma Y, Shannon KB, Chen D-R, Huang Y-W (2009) Toxicity of nano-and micro-sized ZnO particles in human lung epithelial cells. J Nanopart Res 11:25–39
Liu J, Hopfinger AJ (2008) Identification of possible sources of nanotoxicity from carbon nanotubes inserted into membrane bilayers using membrane interaction quantitative structure − activity relationship analysis. Chem Res Toxicol 21:459–466
Liu R, Rallo R, Weissleder R, Tassa C, Shaw S, Cohen Y (2013a) Nano-SAR development for bioactivity of nanoparticles with considerations of decision boundaries. Small 9(9–10):1842–1852
Liu R, Zhang HY, Ji ZX, Rallo R, Xia T, Chang CH, Nel A, Cohen Y (2013b) Development of structure-activity relationship for metal oxide nanoparticles. Nanoscale 5(12):5644–5653
Lubinski L, Urbaszek P, Gajewicz A, Cronin M, Enoch S, Madden J, Leszczynska D, Leszczynski J, Puzyn T (2013) Evaluation criteria for the quality of published experimental data on nanomaterials and their usefulness for QSAR modelling. SAR QSAR Environ Res 24:995–1008
Luco JM (1999) Prediction of the brain-blood distribution of a large set of drugs from structurally derived descriptors using partial least-squares (PLS) modeling. J Chem Inf Comput Sci 39:396–404
Ma CY, Buontempo FV, Wang XZ (2008) Inductive data mining: automatic generation of decision trees from data for QSAR modelling and process historical data analysis. Comput Aided Chem Eng 25:581–586
Ma CY, Wang XZ (2009) Inductive data mining based on genetic programming: automatic generation of decision trees from data for process historical data analysis. Comput Chem Eng 33:1602–1616
Ma CY, Wang XZ (2011) Simultaneous characterization of multiple properties of solid and liquid phases in crystallization processes using NIR. Particuology 9:589–597
Magrez A, Kasas S, Salicio V, Pasquier N, Seo JW, Celio M, Catsicas S, Schwaller B, Forró L (2006) Cellular toxicity of carbon-based nanomaterials. Nano Lett 6:1121–1125
Mei H, Zhou Y, Liang G, Li Z (2005) Support vector machine applied in QSAR modelling. Chin Sci Bull 50:2291–2296
Monteiro-Riviere NA, Tran CL (2007) Nanotoxicology: characterization, dosing and health effects. CRC Press, Boca Raton
Napierska D, Thomassen L, Lison D, Martens JA, Hoet PH (2010) The nanosilica hazard: another variable entity. Part Fibre Toxicol 7:39
Nguyen KC, Seligy VL, Massarsky A, Moon TW, Rippstein P, Tan J, Tayabali AF (2013). Comparison of toxicity of uncoated and coated silver nanoparticles. J Phys Conf Series. IOP Publishing, 012025
Niu B, Su Q, Yuan X, Lu W, Ding J (2012) QSAR study on 5-lipoxygenase inhibitors based on support vector machine. Med Chem 8:1108–1116
Oberdorster G, Maynard A, Donaldson K, Castranova V, Fitzpatrick J, Ausman K, Carter J, Karn B, Kreyling W, Lai D, Olin S, Monteiro-Riviere N, Warheit D, Yang H, Group, A. R. F. T. I. R. F. R. S. I. N. T. S. W (2005) Principles for characterizing the potential human health effects from exposure to nanomaterials: elements of a screening strategy. Part Fibre Toxicol 2:8
OECD (2007) Guidance document on the validation of (quantitative)structure-activity relationships [(Q)SAR] models. OECD Environment Health and Safety Publications, P.03.03
OECD (2009) OECD database on research into the safety of manufactured nanomaterials. OECD Environment Directorate, Environment, Health and Safety Division, Paris/France
OECD (2010) Guidance manual for the testing of manufactured nanomaterials: OECD’s sponsorship programme. Env/Jm/Mono(2009)20/Rev, Organization for Economic Co-operation and Development, Paris
Overton E (1901) Studien über die narkose zugleich ein Beitrag zur allgemeinen pharmakologie. Gustav Fischer, Jena
Park MV, Neigh AM, Vermeulen JP, De La Fonteyne LJ, Verharen HW, Briedé JJ, Van Loveren H, De Jong WH (2011) The effect of particle size on the cytotoxicity, inflammation, developmental toxicity and genotoxicity of silver nanoparticles. Biomaterials 32:9810–9817
Park Y-H, Bae HC, Jang Y, Jeong SH, Lee HN, Ryu W-I, Yoo MG, Kim Y-R, Kim M-K, Lee JK (2013) Effect of the size and surface charge of silica nanoparticles on cutaneous toxicity. Mol Cell Toxicol 9:67–74
Pettitt ME, Lead JR (2013) Minimum physicochemical characterisation requirements for nanomaterial regulation. Environ Int 52:41–50
Poland CA, Duffin R, Kinloch I, Maynard A, Wallace WA, Seaton A, Stone V, Brown S, Macnee W, Donaldson K (2008) Carbon nanotubes introduced into the abdominal cavity of mice show asbestos-like pathogenicity in a Pilot study. Nat Nanotechnol 3:423–428
Powers KW, Brown SC, Krishna VB, Wasdo SC, Moudgil BM, Roberts SM (2006) Research strategies for safety evaluation of nanomaterials. Part VI. Characterization of Nanoscale Particles for Toxicological Evaluation. Toxicological Sciences, 90(2):296–303
Powers KW, Carpinone PL, Siebein KN (2012) Characterization of nanomaterials for toxicological studies. Nanotoxicity. Springer, New York
Powers KW, Palazuelos M, Moudgil BM, Roberts SM (2007) Characterization of the size, shape, and state of dispersion of nanoparticles for toxicological studies. Nanotoxicology 1:42–51
Puzyn T, Leszczynska D, Leszczynski J (2009) Toward the development of “nano-QSARs”: advances and challenges. Small 5:2494–2509
Puzyn T, Leszczynski J (2012) Towards efficient designing of safe nanomaterials: innovative merge of computational approaches and experimental techniques (no. 25). The Royal Society of Chemistry, London
Puzyn T, Leszczyński J, Cronin M (2010) Recent advances in QSAR studies: methods and applications. Springer, New York
Puzyn T, Rasulev B, Gajewicz A, Hu X, Dasari T, Michalkova A, Hwang H, Toropov A, Leszczynska D, Leszczynski J (2011) Using nano-QSAR to predict the cytotoxicity of metal oxide nanoparticles. Nat Nanotechnol 6:175–178
Qin SJ, Mcavoy TJ (1992) Nonlinear PLS modeling using neural networks. Comput Chem Eng 16:379–391
Reddy AS, Kumar S, Garg R (2010) Hybrid-genetic algorithm based descriptor optimization and QSAR models for predicting the biological activity of Tipranavir analogs for HIV protease inhibition. J Mol Graph Model 28:852–862
Richet C, Seances CR (1893) Comptes Rendus des Seances de la Societe de Biologie et de ses Filiales. Soc Biol Ses Fil 9:775–776
Rosipal R, Trejo LJ (2002) Kernel partial least squares regression in reproducing Kernel Hilbert space. J Mach Learn Res 2:97–123
Sadik OA (2013) Anthropogenic nanoparticles in the environment. Evnviron Sci Process Impacts 15:19–20
Sahigara F, Mansouri K, Ballabio D, Mauri A, Consonni V, Todeschini R (2012) Comparison of different approaches to define the applicability domain of QSAR models. Molecules 17:4791–4810
Savolainen K, Backman U, Brouwer D, Fadeel B, Fernandes T, Kuhlbusch T, Landsiedel R, Lynch I, Pylkkänen L (2013) Nanosafety in Europe 2015–2025: towards safe and sustainable nanomaterials and nanotechnology innovations. Helsinki, Finnish Institute Of Occupational Health
Sayes C, Ivanov I (2010) Comparative study of predictive computational models for nanoparticle-induced cytotoxicity. Risk Anal 30:1723–1734
Schaeublin NM, Braydich-Stolle LK, Maurer EI, Park K, Maccuspie RI, Afrooz AN, Vaia RA, Saleh NB, Hussain SM (2012) Does shape matter? Bioeffects of gold nanomaterials in a human skin cell model. Langmuir 28:3248–3258
Shahlaei M (2013) Descriptor selection methods in quantitative structure–activity relationship studies: a review study. Chem Rev 113:8093–8103
Sharifi S, Behzadi S, Laurent S, Forrest ML, Stroeve P, Mahmoudi M (2012) Toxicity of nanomaterials. Chem Soc Rev 41:2323–2343
Sharma CS, Sarkar S, Periyakaruppan A, Barr J, Wise K, Thomas R, Wilson BL, Ramesn GT (2007) Single-walled carbon nanotubes induces oxidative stress in rat lung epithelial cells. J Nanosci Nanotechnol 7:2466
Sharma R, Bisen D, Shukla U, Sharma B (2012) X-ray diffraction: a powerful method of characterizing nanomaterials. Recent Res Sci Technol 4(8):77–79
Shaw SY, Westly EC, Pittet MJ, Subramanian A, Schreiber SL, Weissleder R (2008) Perturbational profiling of nanomaterial biologic activity. Proc Natl Acad Sci 105:7387–7392
Shvedova AA, Kisin ER, Mercer R, Murray AR, Johnson VJ, Potapovich AI (2005) Unusual inflammatory and fibrogenic pulmonary responses to single walled carbon nanotubes in mice. Am J Physiol Lung Cell Mol Physiol 289(5):L698–L708
Singh KP, Gupta S (2014) Nano-QSAR modeling for predicting biological activity of diverse nanomaterials. RSC Adv 4:13215–13230
Supaka N (2012) Measurement and compare particle size determined by DLS, AFM and SEM. J Microsc Soc Thai 5:38–41
Sussillo D, Barak O (2013) Opening the black box: low-dimensional dynamics in high-dimensional recurrent neural networks. Neural Comput 25:626–649
Sussman N, Arena V, Yu S, Mazumdar S, Thampatty B (2003) Decision tree SAR models for developmental toxicity based on an FDA/TERIS database. SAR QSAR Environ Res 14:83–96
Tantra R, Boyd R, Cackett A, Fry AT, Gohil DD, Goldberg S, Lee JLS, Minelli C, Peck R, Quincey P, Smith S, Snowden J, Spencer S, Tompkins J, Wang J, Yang L (2012) NPL report: final report on the physico-chemical characterisation of prospect engineered nanomaterials
Teixeira AL, Leal JP, Falcao AO (2013) Random forests for feature selection in QSPR models-an application for predicting standard enthalpy of formation of hydrocarbons. J Cheminf 5:1–15
Thiele G, Poston M, Brown R (2010) A case study in sizing nanoparticles [Online]. Micromeritics Instrument Corporation. Available: http://www.micromeritics.com/repository/files/a_case_study_in_sizing_nano_particles.pdf. Accessed Dec 2013
Thomas DG, Gaheen S, Harper SL, Fritts M, Klaessig F, Hahn-Dantona E, Paik D, Pan S, Stafford GA, Freund ET (2013) ISA-TAB-nano: a specification for sharing nanomaterial research data in spreadsheet-based format. BMC Biotechnol 13:2. doi:10.1186/1472-6750-13-2
Tomaszewska E, Soliwoda K, Kadziola K, Tkacz-Szczesna B, Celichowski G, Cichomski M, Szmaja W, Grobelny J (2013) Detection limits of DLS and UV-VIS spectroscopy in characterization of polydisperse nanoparticles colloids. J Nanomater 60–70
Tougaard S (2005) XPS for quantitative analysis of surface nano-structures. Microsc Microanal 11(S02):676–677
Tropsha A (2010) Best practices for QSAR model development, validation, and exploitation. Mol Inf 29:476–488
Veerasamy R, Rajak H, Jain A, Sivadasan S, Varghese CP, Agrawal RK (2011) Validation of QSAR models-strategies and importance. Int J Drug Design Discovery 3:511–519
Ventura C, Latino DA, Martins F (2013) Comparison of multiple linear regressions and neural networks based QSAR models for the design of new antitubercular compounds. Eur J Med Chem 70:831–845
Von Der Kammer F, Ferguson PL, Holden PA, Masion A, Rogers KR, Klaine SJ, Koelmans AA, Horne N, Unrine JM (2012) Analysis of engineered nanomaterials in complex matrices (environment and biota): general considerations and conceptual case studies. Environ Toxicol Chem 31:32–49
Wang XZ, Ma CY (2009) Morphological population balance model in principal component space. AICHE J 55:2370–2381
Wang XZ, Medasani S, Marhoon F, Albazzaz H (2004) Multidimensional visualization of principal component scores for process historical data analysis. Ind Eng Chem Res 43:7036–7048
Wang XZ, Yang Y, Li RF, Mcguinnes C, Adamson J, Megson IL, Donaldson K (2014) Principal component and causal analysis of structural and acute in vitro toxicity data for nanoparticles. Nanotoxicology 8(5):465–476
Xia X-R, Monteiro-Riviere NA, Riviere JE (2010) An index for characterization of nanomaterials in biological systems. Nat Nanotechnol 5:671–675
Xia XR, Monteiro-Riviere NA, Mathur S, Song X, Xiao L, Oldenberg SJ, Fadeel B, Riviere JE (2011) Mapping the surface adsorption forces of nanomaterials in biological systems. ACS Nano 5:9074–9081
Xiu Z-M, Zhang Q-B, Puppala HL, Colvin VL, Alvarez PJ (2012) Negligible particle-specific antibacterial activity of silver nanoparticles. Nano Lett 12:4271–4275
Xu R (2008) Progress in nanoparticles characterization: sizing and zeta potential measurement. Particuology 6:112–115
Yang Y, Guo Y, Hu C, Wang Y, Wang E (2004) Preparation of surface modifications of mesoporous titania with monosubstituted keggin units and their catalytic performance for organochlorine pesticide and dyes under UV irradiation. Appl Catal Gen 273:201–210
Yee LC, Wei YC (2012) Current modeling methods used in QSAR/QSPR. Statistical modelling of molecular descriptors in QSAR/QSPR, pp 1–31
Zhang H, Ji Z, Xia T, Meng H, Low-Kam C, Liu R, Pokhrel S, Lin S, Wang X, Liao Y-P (2012) Use of metal oxide nanoparticle band gap to develop a predictive paradigm for oxidative stress and acute pulmonary inflammation. ACS Nano 6:4349–4368
Zhao C-M, Wang W-X (2012) Importance of surface coatings and soluble silver in silver nanoparticles toxicity to Daphnia magna. Nanotoxicology 6:361–370
Zhou H, Mu Q, Gao N, Liu A, Xing Y, Gao S, Zhang Q, Qu G, Chen Y, Liu G (2008) A nano-combinatorial library strategy for the discovery of nanotubes with reduced protein-binding, cytotoxicity, and immune response. Nano Lett 8:859–865
Zurada JM, Malinowski A, Cloete I (1994) Sensitivity analysis for minimization of input data dimension for feedforward neural network. Circuits and systems. Iscas’94. IEEE international symposium on, pp 447–450
Acknowledgements
The authors would like to acknowledge financial support from EU FP7 (Project: 236215, –Managing Risks of Nanomaterials (MARINA)) and the UK Department for Environment, Food & Rural Affairs (Project: 17857, Development and Evaluation of QSAR Tools for Hazard Assessment and Risk Management of Manufactured Nanoparticles) in support of the EU FP7 project entitled NANoREG: A common European approach to the regulatory testing of nanomaterials (FP7-NMP-2012-LARGE). We are also grateful to Kirsten Rasmussen for her comments and suggestions on an earlier version of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this chapter
Cite this chapter
Oksel, C., Ma, C.Y., Liu, J.J., Wilkins, T., Wang, X.Z. (2017). Literature Review of (Q)SAR Modelling of Nanomaterial Toxicity. In: Tran, L., Bañares, M., Rallo, R. (eds) Modelling the Toxicity of Nanoparticles. Advances in Experimental Medicine and Biology, vol 947. Springer, Cham. https://doi.org/10.1007/978-3-319-47754-1_5
Download citation
DOI: https://doi.org/10.1007/978-3-319-47754-1_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-47752-7
Online ISBN: 978-3-319-47754-1
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)