
Abstract
Excess body weight, commonly categorised as overweight (body mass index, BMI 25.0–29.9 kg/m2) and obesity (BMI ≥30 kg/m2) is an established risk factor for increased incidence of several adult cancers. As body weight is modifiable, there is a potential for cancer prevention. Calculation of attributable risk (here expressed at population attributable fraction, PAF) offers an estimate of the burden of excess cancers attributable to elevated BMI in populations, and thus an approximation of avoidable cases and the opportunity for prevention. Using counterfactual methods, the estimated PAF worldwide attributed to elevated BMI is 3.6 % or nearly half a million new cancer cases in adults (aged 30 years and older after a 10-year lag period). PAFs are higher in women compared with men (5.4 % vs. 1.9 %). Endometrial, post-menopausal breast, and colon cancers account for nearly two-thirds of cancers attributable to elevated BMI. Globally, excess body weight is the third commonest attributable risk factor for cancer (after smoking and infection); in western populations such as the UK, excess weight ranks as second commonest risk factor.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
In this chapter, we discuss the epidemiological background linking obesity and cancer risk, the rationale, methodology and model assumptions underpinning attributable risk estimations, and then summarise recent analyses that estimated the excess burden of cancers attributed to excess weight at a global level. In this manuscript, we use the term ‘obesity’ in a general common sense (as in the title) to denote excess body fatness. In sections on the epidemiology and modelling, we will indicate the specific exposure measure of body fatness. For almost all examples, this is BMI.
1 Epidemiology
Excess body weight, commonly categorised as overweight (BMI 25.0–29.9 kg/m2) and obesity (BMI ≥30 kg/m2), is an established risk factor for increased incidence of several adult cancers [1]. Other anthropometric measures of body fatness, such as waist circumference (WC), are less well studied but are generally associated with increased cancer risk with similar patterns and strengths as those for BMI [2]. The most comprehensive and systematic evaluations of the associations between measures of body fatness and cancer risk have been undertaken through the World Cancer Research Fund (WCRF) continuous update project, which now links excess weight or body fatness to 11 cancers [3]. In 2016, an expert working group of 21 scientists from eight countries gathered under the auspices of the International Agency for Research on Cancer (IARC), to specifically evaluate the preventive effects of avoidance of excess body fatness on cancer risk. This group extended the list of obesity-related cancer, for which sufficient evidence exists, to thirteen malignancies as follows: cancers of the colon and rectum, oesophagus (adenocarcinoma), kidney (renal cell), breast (post-menopausal), endometrium, gastric cardia, liver, gall bladder, pancreas, ovary, thyroid, multiple myeloma and meningioma [2]. For the majority of these cancers, there are plausible (hypothesised) biological mechanisms to explain these links. These candidates are three hormonal (systemic) systems, namely circulating sex hormones; the insulin and the Insulin-like Growth factor system; and circulating adipokines and subclinical systemic inflammation [4]. In addition, the local peri-tumour adipose micro-environment or local ectopic fat is likely to be important [4, 5].
It has become clear over the past five years that, in addition to the common effect modifier such as age and sex, there are other effect modifiers of the above BMI–cancer associations. Two clear examples are smoking status [6] and hormonal replacement therapy [4, 7], and these need to be taken into account in attributable risk modelling. For example, studies show a higher risk of pancreatic cancer due to elevated body weight among never and ex-smokers as compared to current smokers with the same BMI [8]. Meta-analyses generally show inverse associations between BMI and smoking-related cancers such as lung cancer and oesophageal squamous cell carcinoma. When these analyses are stratified by smoking status, null associations were generally observed in the never smoker strata. In the example of HRT use, meta-analyses of prospective studies evaluating the associations between BMI and subsequent risk of post-menopausal breast, endometrial and ovarian cancers stratified by HRT use demonstrate that per incremental increase in 5 kg/m2, and there are increased risks of 18, 90 and 10 %, respectively, in never HRT users. Among ever HRT users, there are no associations between BMI and post-menopausal breast (Pinteraction < 0.001) and ovarian (Pinteraction < 0.001) cancers, and an attenuated association (18 % increase per 5 kg/m2) for endometrial cancer (Pinteraction = 0.003) [4].
2 Why Estimate Attributable Risk
There are broadly four reasons to estimate attributable risk. First, it is an estimate of the burden of a public health problem in a population. Such information is helpful for policy makers planning health strategies and resources. In specific circumstances, this information can be instrumental in bringing about legislative changes. Two examples are told in Table 1—the smoking ban in Ireland [9, 10] and the implementation of the ‘sugar tax’ in the UK [11, 12]. In both examples, the uses of attributable risk estimation were key drivers in the implementations of these legislations.
Second, estimation of attributable risk facilitates ranking of the burden of an ‘exposure’ of interest versus other exposures. This is illustrated later in this review by the recent initiatives by Cancer Research UK, the largest cancer charity organisation in the world, which drew a fresh focus on the link between obesity and cancer, and recognised that this risk factor was the second commonest cause of cancer (in the UK) after smoking, which had been a key preventive focus of the charity for the preceding decades [13].
Third, estimation of attributable risk across many cancer types allows identification of specific ‘hot spots’ and targeting of specific exposure–disease associations. A specific example of this might be the link between excess body weight and endometrial cancer. Here, the (PAF: calculation detailed below) is approximately 50 % [14], and indeed points to some sub-populations of women (e.g. women undergoing bariatric surgery) as potential targets for screening for atypical endometrial hyperplasia, a precursor lesion of endometrial cancer [15].
Finally, in principle (with caveats detailed below), estimation of attributable risk can be used to project future cancer incident trends, (again) important for planning health strategies and resources—for example, future colon cancer incidence in various European countries might be greatly reduced by decreasing BMI level in men; whereas in women, physical activity probably offers a better intervention to curb the future colon cancer problem [16].
3 Estimation of Attributable Risk
Details on the methodologies behind the calculations of PAF have been detailed by the authors previously [7] and are summarised here. The standard approach includes modelling estimates of prevalence of the exposure (Pe) and relative risk (RR) with the simplest formula for such a model described half a century ago by Levin [17] and shown in Table 2. The derived PAF is defined as the proportion of all cases that would not have occurred if the exposure had been absent and is thus relevant in cancer prevention research.
However, there are several limitations of the Levin methods. First, the Levin formula only partially adjusts for confounding and does not allow the inclusion of effect modification into the model. In turn, this results in biased PAF estimates (generally overestimated), as has been extensively described by Flegal et al. [18]. Second is a limitation of specific relevance to the relationship between elevated BMI and disease risk. Specifically, the categorisation of the BMI distribution into normal weight (18.5–24.9 kg/m2), overweight and obesity cause the parameter to become trichotomous or polychotomous. This approach risks double counting the exposure, as individuals who were obese, also had a previous exposure to overweight exposure. Furthermore, using polychotomous categorical distributions to calculate PAF may cause a non-linear result [19] and overestimations of PAFs. There are methods described to overcome some of these limitations, such as those described by Hanley [20].
Against the above limitations, the currently preferred method for the calculation of PAF is the use of counterfactual methods. The contribution of a risk factor to a health measure is estimated by comparing the current or future level of the health measure under alternative hypothetical scenarios including the absence of the exposure. This hypothetical scenario is referred to as counterfactual analysis. The derivation of PAF is shown in Table 2 where RR(x) is the RR of the exposure level x, Pe(x) is the population distribution of exposure, Pne(x) is the counterfactual distribution of the exposure (hypothetical rather than to the actual condition) [21] and m is the maximum exposure level. A key component of this method is to determine the theoretical minimum risk—this is the exposure distribution, here BMI, that would result in the lowest population risk, here of cancer. In the example of smoking, this would be straightforward and would be defined by the never smokers population. In the example of BMI, things are less simple as there are hazards associated with low as well as high BMI, and this needs to be taken into account. Because of these considerations, the WHO has advised a theoretical minimum value of 21–22 kg/m2 for BMI [22]. We have used single values of 22.5 kg/m2 [14] and 22.0 kg/m2 [23], in our respective analyses (detailed below). The difference in the theoretical minimum risk group or reference group is one of the causes of the variations of estimations of cancer risk attributed to excess body weight.
Importantly, counterfactual modelling handles BMI as a continuous distribution and that distribution might take a different form and parameterisation for the whole population and that of the theoretical minimum risk population. This also better captures changes in BMI distributions with time.
4 Model Assumptions Relevant to Obesity-Related Cancers
There are a number of model assumptions that require discussion. Again, these have been detailed elsewhere by the authors [7] and summarised here.
4.1 Assumptions About Causality
A central assumption in all this discussion is that the associations between obesity and increased cancer risk are causally linked. There are a number of authoritative reports from the WCRF [3] and IARC [2] to support this and are covered elsewhere in this Book [24]. One of the present authors has specifically addressed this in a systematic manner [25], evaluating BMI–cancer associations against the nine Bradford-Hill criteria (strength of association; consistency; specificity; temporality; biological gradient; plausibility; coherence; experimental evidence; and analogy) that offers a starting point, and also what have become to be known as the Bristol criteria [26] of appropriate adjustment for key confounding factors; measurement error; assessment of residual confounding; and lack of alternative explanations add a further dimension for assessing the causality of the evidence. The BMI–cancer associations hold up robustly for the majority of these criteria.
4.2 Assumptions About BMI Distributions
The simplest approach to estimate PAF is to use categorical BMI data, yet limitation of such approach needs to be acknowledged and understood. For example, if an increasing mean BMI is modelled over time, the corresponding prevalence based on the commonly used WHO overweight and obese categories will increase. Yet, with further increases in mean BMI, the prevalence of overweight declines as the prevalence of obese continues to increase. Simple formulae to estimate attributable risk, such the Levin formula, are inadequate in this setting. A second approach that is generally quite simple using current statistical tools is the use of a normal BMI distribution. Furthermore, with increasing mean BMI in a population, the BMI distribution changes from a normal to a gamma distribution [27], where the commonly observed skewed distribution of risk factors is converting into a more flat distribution with a growing population being overweight or obesity. These dynamics are best dealt with using the counterfactual modelling analysis.
4.3 Relative Risks
The outputs from the PAF equation—whether using the classical Levin method or contemporary counterfactual modelling—are very sensitive to changes in the RR [14]. Wherever possible, conservative RRs (typically the most adjusted RRs) should be used from overview analyses that have derived RRs and their confidence intervals (CIs) using standardised approaches. Credible intervals for PAFs can be derived using Monte Carlo simulations [23]. The term credible intervals is used here, because of the false reassurance that confidence interval might give. The many underlying assumptions that have to be taken when estimating PAF combined with unavailability of a truly population-based prevalence of the exposure (here obesity) for many low and middle income countries means that cancer burden estimations with CIs is challenging and often impossible.
A note on linearity of relation is worth discussion. In general, PAF is derived as one risk function assuming linearity in the model. Although this model is often justified, we showed that this is not always the case [28]—thus, the risk of endometrial cancer increases exponentially with increasing weight, and risk function should be adjusted for calculating PAR for the higher BMI level, otherwise PAF might be underestimated.
Finally, another assumption in calculating PAF, using the general formulas described earlier, is risk reversibility. For smoking and cancer, risk reversibility has been reported before, i.e. stopping smoking at a young age reduces cancer risk compared to that of non-smokers [29]. Yet, for obesity evidence of reversibility remains limited, mostly because large weight loss is difficult and hard to maintain [30]. Risk reversibility and also accumulation of risk have led to various research avenues assessing the role of ‘obese years’ on cancer risk and also the PAF related to time spent with overweight or obesity [31, 32].
4.4 Assumptions About Lag Periods
For many common epithelial adult malignancies, tumour development is a multi-step process over many years or even decades. It is generally held that the influence of ‘obesity exposure’ on increased cancer risk probably plays out over at least a decade, and perhaps up to four decades with neoplastic processes such as colorectal cancer [33]. In the two published analyses [14, 23] from the authors, detailed below, a lag period of ten years has been assumed for all cancer types. Reasons are twofold, one being the fact that cohort studies for which risk estimates are taken from have on average a follow-up time of 10 years [25]. Secondly, case studies from bariatric surgery patients, with expected decreases in body weight, show a decreased risk of cancer 10 years following the intervention [34]. Nonetheless, the lag period probably varies between different cancers for the same exposure, and currently, this is not integrated into models.
5 Key Papers on the Estimation of Burden of Cancer Attributed to Elevated BMI
Using the above assumptions, the authors have published two analyses evaluating the excess new cancer cases attributed to elevated BMI—the first analysis in 30 European countries [14]; the second, as a global analysis [23]. For the former, PAFs were calculated using European- and gender-specific risk estimates from a published meta-analysis [1] and gender-specific mean BMI estimates from a World Health Organisation Global Infobase. Estimates were calculated for oesophageal adenocarcinoma, thyroid, colon, rectal (only men), renal, gall bladder (only women), pancreatic (only women), post-menopausal breast, endometrial, prostate cancers and malignant melanoma (only men), multiple myeloma, leukaemia, and non-Hodgkin lymphoma. Country-specific numbers of new cancers were derived from GLOBOCAN 2002. A ten-year lag period between risk exposure and cancer incidence was assumed. We used Monte Carlo simulations to derive 95 % CI, recognising that in today’s nomenclature, the term credible intervals are preferred (see above). For 2002, there were 2,171,351 new cancers diagnosed in the 30 countries of Europe. Estimated PAFs were 2.5 % (95 % CI 1.5–3.6 %) in men and 4.1 % (2.3–5.9 %) in women or a total of 70,288 new cases. Sensitivity analyses revealed estimates were most influenced by the assumed shape of the BMI distribution in the population and cancer-specific risk estimates i.e. RR. In a scenario analysis for a 2008 population, the estimated PAFs increased to 3.2 % (2.1–4.3 %) and 8.6 % (5.6–11.5 %), respectively, in men and women. Endometrial, post-menopausal breast and colorectal cancers accounted for 65 % of these cancers.
For the worldwide analysis [23], we derived PAFs using RRs and BMI estimates in adults by age, sex, and country. Again, we assumed a 10-year lag period and calculated PAFs using BMI estimates from 2002 and used GLOBOCAN 2012 data to estimate numbers of new cancers. We selected ten obesity-related cancers, namely oesophageal adenocarcinoma, colon, rectum, pancreas, gall bladder (only women), postmenopausal breast, corpus uteri, ovary, kidney and thyroid cancers. We also calculated the proportion of cancers that were potentially avoidable had populations maintained their mean BMIs recorded in 1982 i.e. 30 years prior to the present day analysis. We did sensitivity analyses to estimate the effects of HRT use and smoking. In total, we estimated that almost a half million or 481,000 new cancers in adults (aged 30 years and older) in 2012 were attributable to high BMI. This was a PAF of 3.6 %. PAFs were greater in women than in men (5.4 % vs. 1.9 %) (Table 3). The burden of attributable cases was higher in countries with very high and high human development indices (HDIs; PAF 5.3 and 4.8 %, respectively) than in those with moderate (1.6 %) and low HDIs (1.0 %). As in our European-based analysis, endometrial, postmenopausal breast and colon cancers accounted for almost two-thirds of cancers attributable to high BMI. As an assessment of the changes in prevalence of excess body weight globally over the past three decades, we found that a quarter (about 118,000) of the cancer cases related to high BMI in 2012 could be attributed (and hence avoidable) had BMI distributions remained as they were in 1982.
As an extension of the worldwide analyses, we published further analyses on the relation between recent trends in BMI and the changing profile of cancer worldwide [35]. By examining seven selected countries, each representing a world region, a pattern of increasing BMI with region and gender-specific diversity was noted: increasing levels of BMI were most pronounced in the Middle East (Saudi Arabia), rather modest in Eastern Asia (India) and generally more rapid in females than in males. This observation translated into a disproportionate distribution of cancer attributable to high levels of BMI, ranging by sex from 4 to 9 % in Saudi Arabia and from 0.2 to 1.2 % in India.
6 The Ranking of Obesity as a Risk Factor
By following principles and assumptions outlined above, it is possible to now start to compare and rank across different risk factors. Table 4 shows that, at a global level, excess body weight is the third commonest attributable risk factor for cancer (after smoking [36] and infection [37]); in western populations such as the UK, excess weight ranks as second commonest risk factor [38]. The exercise that is done in the UK has helped government to prioritise prevention programmes and also increase population awareness on the risk factors for cancer. The UK initiative has also pushed other nations globally to performing similar analyses, for example, in Australia, overweight and obesity are the 4th major cause of cancer following smoking, solar radiation and inadequate diet [39].
7 Future Directions/Integrating Other Obesity-Related Diseases
So far, most of the focus has been on changes in BMI that have already occurred. There are opportunities to predict for changes in the future. Thus, by illustration, CRUK and the UK Health Forum [13] recently reported in Tipping the Scales: Why Preventing Obesity Makes Economic Sense that 72 % of adults in the UK are predicted to be overweight or obese by 2035—including 45 % in the lowest-income quintile. The uplift in obesity is predicted to increase the number of new cancer cases in the next 20 years. It is estimated that if these numbers were reduced by only 1 % every year from the predicted trend, about 64,200 cancer cases could be avoided over the next 20 years [13]. At present, insufficient use is made of existing data to underpin obesity-related interventions and assess their potential impact on the future cancer of cancer
With the growing work on PAF, there is an ongoing movement to estimate future attributable fraction based on current and historical trends of obesity, as well as projects assessing the values of different intervention programmes to reduce future burden of cancer. In such exercise, the assumptions that are generally taken in PAF (as outlined above) are bound to be expanded including assumptions on future occurrence of cancer and also future distributions of BMI. The largest driver of the future cancer burden is the changing population structure: the older the population the higher the number of new cancer cases [40]. Global ageing alone will drive up the total number of cases estimated for 2012 i.e. 14 million by 58 % in 2035 i.e. 24 million [41]. Accordingly, the most important aspect that should be taken into account in future prediction of cancers is incorporation of demographic changes in the analysis. Furthermore, whenever possible, especially when projections are longer than 10–20 years, changes in the disease rate overtime and also other causes of deaths should be taken into account to reduce bias in disease estimate and impact of intervention, if the latter were to be incorporated [42].
In Europe, a previous model, PREVENT [43], has been reconstructed to fit the natural history of cancer and incorporates the previously mentioned aspects of modelling future burden of disease. A study in seven representative countries for each European region has estimated the possible long-term impact of continuous increase in BMI over the next decade against the status quo where BMI remains at its baseline level. The study shows that such increase will cause about 4 % increase in the number of cases in 2040, and if body weight were to decrease to a healthy weight‚ colon cancer might reduce by up to 11 % (in Spanish men) [44]. Such analysis has indeed provided the additional perspective needed in provision of valuable information for researchers and policy makers to quantify the impact of policies targeting BMI (or any other risk factor) on future burden of cancer.
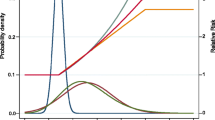
A further dimension is evaluation of the impact on disease (here cancer) where there are two risk factors changing with time, and into the future. This is illustrated in Fig. 1, which might be typical of many western countries—a fall in prevalence of smoking, and a rising in prevalence of obesity. The hypothesis is that currently, smoking is the commonest cause of cancer; but perhaps within the next decade (for example, in women), obesity or more specifically, elevated BMI, might become the commonest cause of cancer.

A schematic representation of future trends in smoking-related versus obesity-related cancers
The proportion of cancer that is avoidable or preventable has been a preoccupation for public health researchers and health makers for many decades. These estimates have started to provide valuable motivations to implement legislative changes. Readers in this field should find the methodologies discussed here, their limitations, and the summarised findings informative.
References
Renehan A, Tyson M, Egger M, Heller RF, Zwahlen M (2008) Body mass index and incidence of cancer: a systematic review and meta-analysis of prospective observational studies. Lancet 371:569–578
Lauby-Secretan B, Scoccianti C, Loomis D, Grosse Y, Bianchini F, Straif K (2016) Body fatness and cancer-viewpoint of the IARC Working Group. N Engl J Med 375:794–798
World Cancer Research Fund. Weight and cancer http://www.wcrf.org/int/cancer-facts-figures/link-between-lifestyle-cancer-risk/weight-cancer. Accessed 8 Aug 2016
Renehan AG, Zwahlen M, Egger M (2015) Adiposity and cancer risk: new mechanistic insights from epidemiology. Nat Rev Cancer 15:484–498
Park J, Morley TS, Kim M, Clegg DJ, Scherer PE (2014) Obesity and cancer–mechanisms underlying tumour progression and recurrence. Nat Rev Endocrinol 10:455–465
Song M, Giovannucci E (2016) Estimating the Influence of obesity on cancer risk: stratification by smoking is critical. J Clin Oncol 34:3237–3239
Renehan AG, Soerjomataram I, Leitzmann MF (2010) Interpreting the epidemiological evidence linking obesity and cancer: a framework for population-attributable risk estimations in Europe. Eur J Cancer 46:2581–2592
Aune D, Greenwood DC, Chan DS, Vieira R, Vieira AR, Navarro Rosenblatt DA et al (2012) Body mass index, abdominal fatness and pancreatic cancer risk: a systematic review and non-linear dose-response meta-analysis of prospective studies. Ann Oncol (Official Journal of the European Society for Medical Oncology/ESMO) 23:843–852
Repace J (2002) Right to life overrides right to smoke. Feb 20. Irish Times
Howell F (2004) Ireland’s workplaces, going smoke free. BMJ 328:847–848
Imamura F, O’Connor L, Ye Z, Mursu J, Hayashino Y, Bhupathiraju SN et al (2015) Consumption of sugar sweetened beverages, artificially sweetened beverages, and fruit juice and incidence of type 2 diabetes: systematic review, meta-analysis, and estimation of population attributable fraction. BMJ 351:h3576
Singh GM, Micha R, Khatibzadeh S, Lim S, Ezzati M, Mozaffarian D et al (2015) Estimated global, regional, and national disease burdens related to sugar-sweetened beverage consumption in 2010. Circulation 132:639–666
Cancer Research UK/UK Health Forum: Tipping the scales: why preventing obesity makes scene https://www.cancerresearchuk.org/sites/default/files/tipping_the_scales_-_cruk_full_report1.pdf2016
Renehan AG, Soerjomataram I, Tyson M, Egger M, Zwahlen M, Coebergh JW et al (2010) Incident cancer burden attributable to excess body mass index in 30 European countries. Int J Cancer 126:692–702
Renehan AG, MacKintosh ML, Crosbie EJ (2016) Obesity and endometrial cancer: unanswered epidemiological questions. BJOG 123:175–178
Menvielle G, Soerjomataram I, de Vries E, Engholm G, Barendregt JJ, Coebergh JW et al (2010) Scenarios of future lung cancer incidence by educational level: modelling study in Denmark. Eur J Cancer 46:2625–2632
Levin ML (1953) The occurrence of lung cancer in man. Acta Unio Int Contra Cancrum 9:531–541
Flegal KM, Graubard BI, Williamson DF (2004) Methods of calculating deaths attributable to obesity. Am J Epidemiol 160:331–338
Barendregt JJ, Veerman JL (2010) Categorical versus continuous risk factors and the calculation of potential impact fractions. J Epidemiol Community Health 64:209–212
Hanley JA (2001) A heuristic approach to the formulas for population attributable fraction. J Epidemiol Community Health 55:508–514
Maldonado G, Greenland S (2002) Estimating causal effects. Int J Epidemiol 31:422–429
James WPT, Jackson-Leach R, Mhurchu AN (2004) Overweight and obesity (high body mass index). In: Ezzati M, Lopez AD, Rodgers A, Murray CJL (eds) Comparative quantification of health risks. World Health Organization, Geneva, pp 497–596
Arnold M, Pandeya N, Byrnes G, Renehan AG, Stevens GA, Ezzati M et al (2015) Global burden of cancer attributable to high body-mass index in 2012: a population-based study. Lancet Oncol 16:36–46
Pischon T, Nimptsch K, Obesity and risk of cancer: an introductory overview [in this Special Issue]. Recent Results Cancer Res (in press)
Renehan AG, Egger M, Zwahlen M (2010) Body mass index and cancer risk: the evidence for causal association. BMC Open J Obes
Lawlor DA, Davey Smith G, Kundu D, Bruckdorfer KR, Ebrahim S (2004) Those confounded vitamins: what can we learn from the differences between observational versus randomised trial evidence? Lancet 363:1724–1727
Sperrin M, Marshall AD, Higgins V, Buchan IE, Renehan AG (2013) Slowing down of adult body mass index trend increases in England: a latent class analysis of cross-sectional surveys (1992–2010). Int J Obes (Lond)
Crosbie EJ, Zwahlen M, Kitchener HC, Egger M, Renehan AG (2010) Body mass index, hormone replacement therapy, and endometrial cancer risk: a meta-analysis. Cancer Epidemiol Biomark Prev 19:3119–3130
Doll R, Peto R, Boreham J, Sutherland I (2004) Mortality in relation to smoking: 50 years’ observations on male British doctors. BMJ 328:1519
Williamson DF, Pamuk E, Thun M, Flanders D, Byers T, Heath C (1999) Prospective study of intentional weight loss and mortality in overweight white men aged 40–64 years. Am J Epidemiol 149:491–503
Arnold M, Freisling H, Stolzenberg-Solomon R, Kee F, O’Doherty MG, Ordonez-Mena JM et al (2016) Overweight duration in older adults and cancer risk: a study of cohorts in Europe and the United States. Eur J Epidemiol 31:893–904
Arnold M, Jiang L, Stefanick ML, Johnson KC, Lane DS, LeBlanc ES et al (2016) Duration of adulthood overweight, obesity, and cancer risk in the Women’s health initiative: a longitudinal study from the United States. PLoS Med 13:e1002081
Meza R, Jeon J, Renehan AG, Luebeck EG (2010) Colorectal cancer incidence trends in the United States and United Kingdom: evidence of right- to left-sided biological gradients with implications for screening. Cancer Res 70:5419–5429
Renehan AG (2009) Bariatric surgery, weight reduction and cancer prevention. Lancet Oncol 10:640–641
Arnold M, Leitzmann M, Freisling H, Bray F, Romieu I, Renehan A et al (2016) Obesity and cancer: an update of the global impact. Cancer Epidemiol 41:8–15
Ezzati M, Henley SJ, Lopez AD, Thun MJ (2005) Role of smoking in global and regional cancer epidemiology: current patterns and data needs. Int J Cancer 116:963–971
de Martel C, Ferlay J, Franceschi S, Vignat J, Bray F, Forman D et al (2012) Global burden of cancers attributable to infections in 2008: a review and synthetic analysis. Lancet Oncol 13:607–615
Parkin DM, Boyd L, Walker LC (2011) The fraction of cancer attributable to lifestyle and environmental factors in the UK in 2010. Br J Cancer 105(Suppl 2):S77–S81
Whiteman DC, Webb PM, Green AC, Neale RE, Fritschi L, Bain CJ et al (2015) Cancers in Australia in 2010 attributable to modifiable factors: summary and conclusions. Aust NZ J Public Health 39:477–484
Bray F, Moller B (2006) Predicting the future burden of cancer. Nat Rev Cancer 6:63–74
Bray F, Jemal A, Grey N, Ferlay J, Forman D (2012) Global cancer transitions according to the human development index (2008–2030): a population-based study. Lancet Oncol 13:790–801
Dyba T, Hakulinen T (2008) Do cancer predictions work? Eur J Cancer 44:448–453
Soerjomataram I, de Vries E, Engholm G, Paludan-Muller G, Bronnum-Hansen H, Storm HH et al (2010) Impact of a smoking and alcohol intervention programme on lung and breast cancer incidence in Denmark: an example of dynamic modelling with prevent. Eur J Cancer 46:2617–2624
de Vries E, Soerjomataram I, Lemmens VE, Coebergh JW, Barendregt JJ, Oenema A et al (2010) Lifestyle changes and reduction of colon cancer incidence in Europe: a scenario study of physical activity promotion and weight reduction. Eur J Cancer 46:2605–2616
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Renehan, A.G., Soerjomataram, I. (2016). Obesity as an Avoidable Cause of Cancer (Attributable Risks). In: Pischon, T., Nimptsch, K. (eds) Obesity and Cancer. Recent Results in Cancer Research, vol 208. Springer, Cham. https://doi.org/10.1007/978-3-319-42542-9_13
Download citation
DOI: https://doi.org/10.1007/978-3-319-42542-9_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-42540-5
Online ISBN: 978-3-319-42542-9
eBook Packages: MedicineMedicine (R0)