
Abstract
Collaborative filtering recommendation currently serves as a key method when it comes to how to rapidly and effectively make proper personalized recommendation for customers. For the sake of above, it becomes a research hot pot in e-commerce system. By analyzing the defects of existing collaborative filtering algorithm, we proposed an improved collaborative filtering algorithm (ICF). In our construction, we firstly establish “users-items” interest degree matrix, and introduce the mechanism of singularity degree to generate the set of similar users, and then optimizes the method of neighbor set generation by recommend importance mechanism. Finally, our experiment proves that ICF has higher performance of accuracy and coverage than other existing algorithms.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Personalized recommendation
- Collaborative filtering
- Interest degree matrix
- Singularity impact degree
- Recommend importance
1 Introduction
By using e-commerce platform, people can enjoy the convenience of shopping without having to go out. However, due to increasing number of deals on e-commerce platform, it is impossible of people to browse all the items in short time using Internet browser. To solve this problem, personalized recommendation system arises at the historic moment. To the best of our knowledge, collaborative filtering(CF) algorithm now has been a hot spot and the most successful algorithm applied in the field of personalized recommendation. In this paper, we present an improved collaborative filtering algorithm - ICF. Innovations of ICF algorithm mainly include three aspects:
-
(i)
ICF establishes the matrix of “user - project” interest degree, instead of traditional data exhibition form in former collaborative filtering algorithm;
-
(ii)
By introducing the mechanism of singularity degree to calculate the similar users set, ICF provides effective improvements in solving two major problems of recommender systems: “cold start” and neighbor misjudgment;
-
(iii)
According to diversity of recommend importance, ICF optimizes the method of neighbor set generation so that recommended results become more reliable.
2 Related Research
Nowadays collaborative filtering algorithm is widely used in different websites, and becomes a vital technique personalized recommendation. In order to rate the unrated items, Badaro et al. [1] propose a new hybrid CF algorithm using one kind of weighted combination matrix based on both user-based collaborative filtering and item-based collaborative filtering. It provides effective improvement in solving the problem of data sparsity in collaborative filtering algorithm. Meanwhile, Ba et al. [2] proposes another improved CF algorithm, which combines the clustering algorithm and SVD algorithm. The algorithm judges an item whether it deserves to be recommended only depending on the recent generated recommendation neighbors.
In order to capture the sequential behaviors of users and items, a recommended system based on CF is proposed in [3]. It helps to find the set of neighbors that are the most influential to given users (items). In the solution of reference [4], item similarity matrix is not only established by nearest neighborhood of each single item, but also by the detection for underlying item neighborhood with propagated neighborhoods. Differently, influences of users and the topology of their social network are considered in [5]. It analyzes relationships among users from their scores on the same item and how influential users impact others. In addition, extension of CF algorithm based on user is realized in [6], which focuses on achieving correlation of interests among different users via exploring potential attributes of users and other data mining techniques. To sum up, [3–6] optimize the neighbor set generation method in further, making the recommended results more reliable. But they fail to make full use of contextual information, which made system facing a performance bottleneck to some extent.
Ying et al. [7] propose a personalized web page recommendation model based on user context and CF. Its improved Collaborative Filtering (CF) algorithm discovers similar users’ interested web page sets of the target user, based on which Collaborative Filtering web Page Set (CFPS) of one user is filtered. Based on user attributes, a new CF recommendation algorithm is proposed in [8]. This algorithm effectively improves the accuracy, quality and user satisfaction of recommendation system in social networks. At meantime, a new method of user-based CF is proposed in [9] based on predictive value padding. It predicts the empty values in user-item matrix by integrating content-based recommendation algorithm and user activity level before calculating user similarity.
Through the above analysis we can conclude that the current collaborative filtering algorithm study focuses on three aspects: sparseness of data, computing similar users set and neighbor set generation. In this paper, we propose an improved collaborative filtering algorithm ICF. On the one hand, ICF uniquely established “users-items” interest degree matrix, on the other, singularity impact degree mechanism is introduced to compute the impact of a single component of user vector on similarity measure from the whole matrix of “users-items” interest degree and to produce weighted influence on similarity measure, which effectively solved the problems of similarity measure in collaborative filtering, including false judgment of neighbors and helplessness for new users or items and so on. What’s more, recommendation importance mechanism is introduced to compute the recommendation importance of a user for an item and filter the result of similarity measure so as to optimize the neighbor set generated by traditional collaborative filtering.
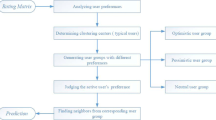
3 Details of Algorithm
The whole thought of ICF is roughly the same as the traditional collaborative filtering algorithm, but in specific implementation details, ICF aims at establishing “users-items” interest degree matrix, introducing the mechanism of singularity degree to generate the similar users set, and optimizing the method of neighbor set generation by recommend importance mechanism. Table 1 lists frequently used notations.
ICF-Building “Users-Items” Interest Degree Matrix.
In order to build “users-items” interest degree matrix, we need to know the interest degree value at some intervals. Usually interest degree values are determined as the specific formula follows:
where m is the number of items that are extracted from the user’s session file.
This paper refers to \( stayDegree_{u,k}^{j} \) so as to display length of access time. The specific formula is as follows:
The calculation of degree of users’ interest in items is as follows:
where \( w_{{u_{t} k}}^{j} \) is an important factor that determines whether \( density_{{u_{t} k}}^{j} \) is able to affect the calculation of interest degree value. The specific calculation method of \( w_{{u_{t} k}}^{j} \) is given as follows:
According to \( I_{{u_{t} k}}^{{segTime_{start\sim end} }} \), we can establish “users - items” interest degree matrix. As shown in Fig. 1 (\( ID_{{u_{t} ,k}} \) is on behalf of \( I_{{u_{t} k}}^{{segTime_{start\sim end} }} \)):

“Users - Items” interest degree matrix
ICF- Similar User Set Calculation.
Definition 3.1 singularity impact degree factor: the factor expresses the impact from the individual. The specific quantitative process of the singularity impact degree factor is as follows (this paper divides user`s interest into three levels: positive interest, medium interest and negative interest):
Based on MSD [10] similarity calculation method, we take the product of singularity impact degree factor of different users as the weight value. Combinations are shown in the following Table 2:
From the above table we can get the formula of the similarity calculation method based on the singularity impact degree is as follows:
The advantages of the similarity calculation method based on singularity impact degree are as follows:
-
(1)
It is realized on the basis of MSD similarity calculation method, so it has the ability to solve the problem of “cold start” like MSD.
-
(2)
Interest degree division is more flexible due to its scalability, which is free from fixed hierarchy number.
-
(3)
Focusing on the partial in the view of the whole, which means we take into account the effect of the individual components, in process of similarity calculation, based on overall distribution characteristics investigated from whole level of interest in an item to measure the similarity among the users.
ICF- Neighbor Set Generation.
Definition 3.2 recommended Importance of an item: it refers to a function that the item can be recommended by the system, and the calculation formula is as follows:
if \( L_{k} \ne \emptyset \), \( RI_{k}^{item} \in [0,1] \); if \( L_{k} = \emptyset \), \( RI_{k}^{item} \) has no solution.
Definition 3.3 recommended Importance of a user: it refers to a function that the user makes the system give priority to his recommendation, and its calculation formula is as follows:

where \( F_{1} = \frac{{\# M_{{u_{t} }} + \# N_{{u_{t} }} }}{\# Item} \) represents the proportion of items that have a degree of interest, \( F_{2} = 1 - \frac{{\# M_{{u_{t} }} }}{{\# M_{{u_{t} }} + \# N_{{u_{t} }} }} \) represents the proportion of positive interest degree items in items that have a degree of interest. If \( M_{{u_{t} }} \ne \emptyset \) or \( N_{{u_{t} }} \ne \emptyset \), \( RI_{{u_{t} }}^{user} \in [0,1] \); if \( M_{{u_{t} }} \ne \emptyset \) and \( N_{{u_{t} }} \ne \emptyset \), \( RI_{{u_{t} }}^{user} \) has no solution.
Definition 3.4 recommendation importance of a user for an item: it refers to a function of the user makes the system recommend an item, and its calculation formula is as follows:

, where \( \mu = \sum\limits_{{itemN \in Q_{k}^{'} }} {sim(k,itemN)} \).
Using the similarity calculation method based on the singularity impact degree, we sort \( MSD^{SI} \) by the order from big to small. So we can get L users who are the most similar to the target user \( u_{t} \): \( simU_{{u_{t} }} (u_{{SI_{1} }} ,u_{{SI_{2} }} , \cdots ,u_{{SI_{L} }} ) \). Then we respectively measure diversity between L users and the target user \( u_{t} \) in recommendation importance of a user for an item. The less diversity between a certain user and target user \( u_{t} \), the more similar ability in recommend an item such as preferences in behavior patterns, and interest. The calculation method of diversity in recommendation importance of a user for an item between the user and the target user \( u_{t} \) is as follows:
We assume that the vector of target user’s recommended importance of m items is as follows: \( RI_{{u_{t} }}^{user\_item} (RI_{{u_{t} ,1}} ,RI_{{u_{t} ,2}} , \cdots ,RI_{{u_{t} ,k}} \cdots ,RI_{{u_{t} ,m}} ) \).The vector represents recommended importance of m items of the user \( u_{{SI_{i} }} (i = 1,2, \cdots ,L) \) in the target user’s similar user set \( simU_{{u_{t} }} \left( { \ne \emptyset } \right) \) is as follows: \( RI_{{u_{{SI_{i} }} }}^{user\_item} (RI_{{u_{{SI_{i} }} ,1}} ,RI_{{u_{{SI_{i} }} ,2}} , \cdots ,RI_{{u_{{SI_{i} }} ,k}} \cdots ,RI_{{u_{{SI_{i} }} ,m}} ) \).The difference between the target user \( u_{t} \) and the similar user \( u_{{SI_{i} }} \) in factors of recommended importance of items is as follows:

where \( RID\,\, = \,\{ K \in Item\,\,|\,\,RI_{{u_{t} ,k}} \ne \bullet \cap RI_{{u_{{SI_{i} }} ,k}} \ne \bullet \} \), \( \# RID \) represents the total element number of the set \( RID \). Obviously, the smaller value of \( RI_{{u_{t} ,u_{{SI_{i} }} }}^{dif} \), the smaller difference between the target user \( u_{t} \) and the similar user \( u_{{SI_{i} }} \) in recommended importance of items. So \( u_{{SI_{i} }} \) may become one of the candidates of the optimal neighbor set of \( u_{t} \), which is close to \( u_{t} \).
We calculate the difference between each user in \( simU_{{u_{t} }} \) with the target user \( u_{t} \) in factors of recommended importance of m items according to the following formula. The user in \( simU_{{u_{t} }} \) is sorted by the order from big to small according to the \( RI_{{u_{t} ,u_{{SI_{i} }} }}^{dif} \) value. We select the former KN (\( 0 \le KN \le L \)) users to form target user’s best neighbor set: \( OPN = \{ u_{{opn_{i} }} \in simU_{{u_{t} }} \,|\,\,i = 1,2, \cdots ,KN\} \). Namely, \( (simU_{{u_{t} }} \ne \emptyset \cap OPN \ne \emptyset ) \cap (\forall u_{{any_{i} }} \in OPN) \cap (\forall u_{{any_{j} }} \in simU_{{u_{t} }} \cap u_{{any_{j} }} \notin OPN) \cap (RI_{{u_{t} ,u_{{any_{i} }} }}^{dif} \ne \bullet \cap RI_{{u_{t} ,u_{{any_{j} }} }}^{dif} \ne \bullet ) \Rightarrow RI_{{u_{t} ,u_{{any_{i} }} }}^{dif} \le RI_{{u_{t} ,u_{{any_{j} }} }}^{dif} \).
In the “users-items” interest degree matrix, based on the target user’s optimal neighbor set OPN, we predict the target user’s item interest degree value that has no value of it. The prediction uses the method of modified weighted prediction, the formula is as follows:

, where \( \overline{{ID_{{u_{t} }} }} \) is the average interest degree value of the target user’s interest in an item; \( \overline{{ID_{knu} }} \) is the average interest degree value of the optimal neighbor user \( knu \) of the target user \( u_{t} \) interested in the item: \( \mu_{{u_{t} ,k}} = \frac{1}{{\sum\limits_{knu \in OPN} {sim(u_{t} ,knu)} }} \).
According to the above prediction of target user’s item interest degree value, we can use TOP-N way to push \( P_{{u_{t} ,k}}^{ID} \) in the top N (from big to small) corresponding to the item set \( Item\text{Re} c \) to target user \( u_{t} \).
We define the target user’s item set with no interest degree value is as follows: \( I{\text{tem}}L = \{ iteml \in Item\,\,|\,\,ID_{{u_{t} ,iteml}} = \bullet \} \), \( 0 \le \# I{\text{tem}}L \le m \). Where \( \# I{\text{tem}}L \) represents the total element number of \( I{\text{tem}}L \), so \( Item\text{Re} c = \{ itemR_{i} \in ItemL\;|\;i = 1,2, \cdots ,N \cap 0 \le N \le \# ItemL\} \). Namely, \( (\forall item_{{any_{i} }} \in Item\text{Re} c) \cap (\forall item_{{any_{j} }} \in ItemL \cap item_{{any_{j} }} \notin Item\text{Re} c) \cap \,(P_{{u_{t} ,item_{{any_{i} }} }}^{ID} \ne \bullet \cap P_{{u_{t} ,item_{{any_{j} }} }}^{ID} \ne \bullet ) \Rightarrow P_{{u_{t} ,item_{{any_{i} }} }}^{ID} \ge P_{{u_{t} ,item_{{any_{j} }} }}^{ID} \). And we stipulate \( Item\text{Re} c \) is the ordered set, so \( P_{{u_{t} ,item\text{Re}_{i} }}^{ID} \ge P_{{u_{t} ,item\text{Re}_{i + 1} }}^{ID} \) Where item \( item\text{Re}_{i} \in Item\text{Re} c \), \( i = 1,2,3, \cdots ,N - 1 \).
4 Experiments and Results
Experimental Data and Log Preprocessing.
We extracted log of 15 days from June 6th, 2015 to June 20th, 2015 in server of official website of Nanjing University of Posts and Telecommunications as our experimental data. In order to establish the “user-item” interest degree matrix, we did a survey on which items users browse, the number of access of items, dwell time and other essential information. We extracted 75 % of the users in the user set, while extracting 80 % of the items in the project set as training set, and the rest were used as test set. Finally we compared ICF, in terms of mean absolute error (MAE) and coverage, based on [1, 5] at the same running environment.
Before the user session identification, we performed data cleaning on the log, and Fig. 2 is the change chart of user request number in the process of data cleaning. As can be seen from Fig. 2, after data cleaning, the number of user requests has decreased from 6277820 to 268220. Figure 3 is the change chart of user number in the user identification process. As can be seen from Fig. 3, after user identification, the number of user has increased from 6277820 to 268220.

Data cleaning.

User identification.
After user identification, we used the time window model to identify sessions on the log. We chose 25.5 min as a measure of the session timeout threshold, and identified 53110 users’ sessions. After the above steps of log preprocessing, we can obtain that the number of user request log entries is 268220, the number of users is 47440 and the number of sessions is 53110. On this basis, we constructed the “user – project” interest matrix with the information of items users browse, the number of access of items, dwell time and other essential information.
Experimental Results and Analysis.
According to the “user-item” interest degree matrix, we compared ICF, in terms of mean absolute error (MAE) and coverage, with traditional collaborative filtering algorithm and other improved collaborative filtering algorithm based on [1, 5] at the same running environment (In the following figure, K represents the size of the neighbor user set).
As is shown in Fig. 4: The value of MAE with ICF is always less than others no matter what values K takes. It is apparent to see that recommendation results became more accurate. As is shown in Fig. 5: Coverage of ICF is always higher than others no matter what value K takes. Viewing the above, ICF has better coverage, and shows better personalized recommendation.

MAE. (Color figure online)

Coverage. (Color figure online)
5 Conclusions
In this paper, we propose an improved collaborative filtering algorithm ICF. In this paper, we propose an improved collaborative filtering algorithm ICF. In our construction, improvement can be accounted for by following three aspects: data representation, calculation of similarity degree and generation of neighbor set. Finally, we verify its high accuracy and coverage by experiments compared with existing algorithms.
References
Badaro, G., Hajj, H., El-Hajj, W., et al.: A hybrid approach with collaborative filtering for recommender systems. In: 2013 9th International Conference on Wireless Communications and Mobile Computing Conference (IWCMC), pp. 349–354 (2013)
Ba, Q., Li, X., Bai, Z.: Clustering collaborative filtering recommendation system based on SVD algorithm. In: 2013 4th International Conference on Software Engineering and Service Science (ICSESS), pp. 963–967 (2013)
Sun, G.F., Wu, L., Liu, Q.: Recommendations based on collaborative filtering by exploiting sequential behaviors. J. Softw. 24(11), 2721–2733 (2013)
Ji, H., Chen, X., He, M., et al.: Improved recommendation system via propagated neighborhoods based collaborative filtering. In: 2014 International Conference on Service Operations and Logistics, and Informatics (SOLI), pp. 119–122 (2014)
Yao, Z., Feng, J., Chen, X.: Collaborative filtering recommendation algorithms research based on influence and complex network. In: 2014 11th International Conference on Service Systems and Service Management (ICSSSM), pp. 1–6 (2014)
Chang, N., Terano, T.: Improving the performance of user-based collaborative filtering by mining latent attributes of neighborhood. In: 2014 International Conference on Mathematics and Computers in Sciences and in Industry (MCSI), pp. 272–276 (2014)
Ying, Z., Zhou, Z., Han, F., et al.: Research on personalized web page recommendation algorithm based on user context and collaborative filtering. In: 2013 4th International Conference on Software Engineering and Service Science (ICSESS), pp. 220–224 (2013)
Huigui, R., Shengxu, H., Chunhua, H.: User similarity-based collaborative filtering recommendation algorithm. J. Commun. 2, 16–24 (2014)
Fan, J., Pan, W., Jiang, L.: An improved collaborative filtering algorithm combining content-based algorithm and user activity. In: 2014 International Conference on Big Data and Smart Computing (BIGCOMP). IEEE Computer Society, pp. 88–91 (2014)
Acknowledgments
This work is supported by the National Natural Science Foundation of China (60973140, 61170276, 61373135), The research project of Jiangsu Province (BY2013011), The Jiangsu provincial science and technology enterprises innovation fund project (BC2013027), the High-level Personnel Project Funding of Jiangsu Province Six Talents Peak and Jiangsu Province Blue Engineering Project. The major project of Jiangsu Province University Natural Science (12KJA520003).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Li, X., Zhang, X., Sun, Z. (2016). Improved Collaborative Filtering Algorithm (ICF). In: Huang, DS., Han, K., Hussain, A. (eds) Intelligent Computing Methodologies. ICIC 2016. Lecture Notes in Computer Science(), vol 9773. Springer, Cham. https://doi.org/10.1007/978-3-319-42297-8_55
Download citation
DOI: https://doi.org/10.1007/978-3-319-42297-8_55
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-42296-1
Online ISBN: 978-3-319-42297-8
eBook Packages: Computer ScienceComputer Science (R0)