
Abstract
The work is about the discount rate subject-matter and the research of its dependence on defined factors. The first part of the work focuses on presenting the variability of assessed discount rates (measured by WACC) for chosen enterprises of IT sector. In this part, the factors which can influence the discount rate are also shown. In the next part, the econometric models constructed by IBM SPSS computer program are presented. The models describe the linear dependence between dependent variable and independent variables. The last part is a statistic verification of constructed models, which bases on this part was the agreement with Gauss-Markov assumptions. The statistic verification scheme of econometric models was conducted (according to the literature) in the following steps: matching models to empirical data, the relevance of regression coefficients, checking the attributes of random elements which is the examining of the normality, homoscedasticity and the autocorrelation of any order.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
To develop and maximize its value, an enterprise should invest in fixed assets. Investing in the fixed assets is connected with long-term enterprise functioning, with the object of generating profits during the long time in the future. Considering both time preferences and opportunity costs, which means showing the potential profits of capital investment in alternative investments, is a great importance of the discount rate. The discount rate, used i.a. to assess investment profitability, is presented as the cost of capital. The most common definition of the capital cost is to determine it as the return rate of invested capital which is most expected by the investors [1–3]. The way of set the discount rate is conditioned by the structure of invested capital, which can comes from own sources, foreign sources or both sources at the same time. In the reference books concerning the methods of investment profitability, the constant discount rate is assumed [4]. The constant discount rate in the whole period of investment realization is too simplificated and do not reflect the real money value loss in time. Some authors propose to use different discount rate for each year [5], but it is still not enough.
Investments realized by an enterprise are made with some uncertainty regarding future conditions. The risk is a core element because the success of the investment is counted by the entrepreneur. The risk scale increases when the investment time horizon increases. In relation to risk definition, which means it is possible that non-planned situation appears [6, 7]. In that case, the possibility of changing the discount rate should be taken into account. Many factors can influence the discount rate e.g. Monetary policy of central bank, fiscal policy (loans and investments interest, debentures and treasury bills interest), inflation, capital structure, exchange rate, gross domestic product value [8, 9] and it is hard to expect them to be constant during the whole period of investment realization. It is a proof that the discount rate should vary. That is why, both the factors identification and analyzes, that can influence the discount rate, are so crucial.
2 Data Collection
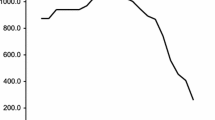
The discount rate was estimated (for every day of quotation, during the analyzed period, which equals 2.508 observations) for each enterprise. It was measured as the weighted average capital cost. The estimated discount rate for analyzed enterprises is presented in Figs. 1 and 2.

WACC-measured discount rate—part 1. (source own elaboration)

WACC-measured discount rate—part 2 (source own elaboration)
Figures 1 and 2 present the modeling of the discount rate in the analyzed period. The capital cost estimation of examined enterprises, which was calculated for any day of analyzed period, confirmed the rightness of use the variable discount rate. So, it was valid to show and analyze factors, which could influence the discount rates variability for each analyzed enterprise of IT sector.
The aim of the model test was to determine the character and kind of causal relationships between the examined variable (the discount rate) and the explanatory variable. Empirical studies were realized with an example of IT sector enterprises, which were publicly traded on Polish Stock Exchange between 2004 and 2013. Enterprises were chosen on the basis of companies which belong to the stock market index called WIG-INFO (Warsaw Stock Exchange—Information Technology), according to the situation on the 21st August 2014. The set criteria was realized by Assecopol, Calatrava, CdProjekt, Comarch, Elzab, McLogic, Simple, Sygnity, Talex, Wasko.
In the analyzed financial reports, every company shows the risk factors which threaten them or influence their activity. The most often mentioned factors were chosen among many unfavorable determinants that had been mentioned. The factors in the research were determined as “the independent variable”. The independent variables are the following:
-
Unemployment rate (x1),
-
Inflation rate (Consumer Price Index—CPI, x2)
-
Euro exchange rate (x3)
-
Dollar exchange rate (x4)
-
Budgetary deficit (x5)
-
WIBOR 3M (x6)
-
GDP index (x7)
-
Economy investment rate (x8)
-
Power price—weighted arithmetic mean by twenty-four hours volume (x9)
-
Fuel price—average price of diesel fuel from the petrol station for a given day (x10)
Most data connected with the independent variables were collected on the basis of information from Polish Central Statistical Office website. However, power prices came from Polish Power Exchange website. Euro and Dollar exchange rates were generated by Excel Pack computer program (which related to data from National Bank of Poland). Econometric modeling was conducted by IBM SPSS computer program.
3 Econometric Models
The aim of the research was both checking if the assessed discount rate for each enterprise is a linear function of examined factors and statistic verification of dependents. The results of the program report will be presented for the chosen enterprisesFootnote 1 while explanations and conclusions will be discussed for all analyzed enterprises (together with summary results in the summary table).
First, the econometric models, based on linear regression, were built using forward selection method. The forward selection method was chosen considering sequential procedure of variables selection. The variables are entered sequentially into the model.
The critical point in this case is the sequence of variables entered into the model. The sequence concerns the strongest correlation with a dependent variable. Several models were obtained with the function of linear regression using forward selection method. A model, which is characterized with the highest coefficient of determination (R2) was chosen of the several models. The coincidence condition was examined in the models chosen in such way. When there had been no coincidence, a model was formed again excluding the variable for which the coincidence conclusion had not been realized. Equations (the ultimate ones, after coincidence check) of particular regression models for each WACC (for a given enterprise) were constructed on the basis of results. The results had been generated by a computer program and determined coefficients had been generated for every variable. Table 1 presents the chosen model with coefficients for a model of Comarch enterprise.
On the basis of the Table 1, analytical regression form for WACCComarch presents as followingFootnote 2:
The presented model should be interpreted in the way: if the independent variable xi increases by 1 unit,Footnote 3 the dependent variable changes by the value of coefficient xi. The mark near the variable coefficient xi informs about the way of the changes. On the other hand the constant informs about the distance between the regression line and the middle of coordinate system. The econometric model for Comarch enterprise concerns the discount rate dependence on 8 factors. In the enterprise model, the following variables were deleted: unemployment rate (x1) and economy investment rate (x8). Models for WACC rate of other enterprises are presented in Table 2.
The proposed models differ in relations to the amount of variables, which entered into the model. CDProject is characterized by the smallest amount of variables. There is only one model, where the dependence between WACC and variables considers all analyzed factors. The interpretation of individual regression models is the same as in case of Comarch model. The variables which were excluded the most often are: budgetary deficit and economy investment rate. The only variable which was entered into the models is Wibor3m return rate.
4 Econometric Models Verification
The received econometric models were verified both at the point of Gauss-Markov assumptions and according to proposed stages [10 p. 11]:
-
The relations between a dependent variable and independent variables is linear
-
The value of independent variables are determined (are not random)—the dependent variable randomization comes out of the randomization of the random element
-
Random elements for particular values of independent variables have got normal distribution (or extremely close to the normal one) with expected value equals 0 and a variance.
-
Random elements are not correlated.
4.1 Matching a Model to Empirical Data
First, a relation between independent variables and the dependent variable had been studied. The relation is determined by coefficient R. For most models, coefficient R (also called multiple R) equals over 0.9 which proofs the strong dependence between independent variables and the dependent variable. The dependence is weaker for CDProject only.
Then, it was checked if a model would match to empirical data. It was studied with coefficient R2. The coefficient of determination is used to determine which part of the total dependent variable Y is explained by linear regression, in relation to independent variables. In other words, the value of R2 informs what percentage of studied feature variability (the discount rate) is explained by a model. The coefficient value for analyzed feature—the discount rate, for each enterprise is presented in Table 3.
Interpreting the obtained results—for example, for Elzab enterprise—the model explains 90.6 % of studied feature variability which is the discount rate for the enterprise. The accepted value for the coefficient usually equals about 0.6 [10 p. 14]. In case of both analyzed enterprises and proposed models, there is only one model which does not meet the condition. This is the model connected with CDProject. For the enterprise, the coefficient of determination value equaled 0.460. It means that the proposed model explains only 46 % of the discount rate variability for the enterprise.
4.2 The Significance of Regression Coefficients Equation
In the next step, it was checked if there is a linear dependence between the dependent variable and whichever independent variables of the model. To do this, the significance test of regression coefficients equation using F-distribution, also called the Fisher-Snedecor’s distribution, was conducted.
I have made a null hypothesis that the discount rate does not depend on at least one of mentioned coefficients. There is an alternative hypothesis that at least one of the coefficients determine the dependence and I verify it with distribution when the null hypothesis is true, it has got F-distribution.
For each model, the significance level of F-distribution equals 0.000 and it is lower than the accepted significance level α = 0.05, so I reject H0 for each model. The conclusion of the conducted test is the fact that is should be regarded that there is the linear dependence between WACC variable and at least one of the variables considered in the model. The verification can be also done by comparing empirical value of F-distribution with critical value of established significance level. When F > Fα, the alternative hypothesis is accepted. For instance, the critical value of 0.05 significance level for Talex equals 1.9421, when there are 8 degrees of numerator freedom and 24994 degrees of denominator freedom. Because there is the dependence F > Fα ie.1955.276 > 1.9421, the alternative hypothesis was accepted. Both the comparison of F-distribution value and the level of its significance for all enterprises are presented in the Table 4.
4.3 The Significance of Particular Regression Coefficients
The econometric model is correct because there is a significant dependence between all independent variables and a dependent variable.
I have made a null hypothesis that the coefficients are non-significant oppose to the alternative hypothesis when the coefficients are significant. I verify it on the basis of statistics which means that the null hypotheses are Student’s t-distribution.
The verification of the made hypotheses can be considered by comparing empirical value of Student t-distribution with a critical value—\( \left| t \right| \le t_{\alpha } \)—when there is no reason to reject H0 (it means that the variable is non-significant). In other case we accept the hypothesis H1, so we have the bases to accept that there is the linear dependence between the dependent variable and all variables included in the model,Footnote 4
In Table 5 the empirical values of Student’s t-distribution for each factor and the levels of their significance for chosen enterprises are presented.
Interpreting the results e.g. of Simple enterprise: the empirical values of Student’s t-distribution for all variables, with the absolute value, are greater than the critical value, with the accepted level of significance (0.05) which is 1.96. That is why, the alternative hypothesis was accepted. The dependence was realized for all studied factors, so I have the bases to accept that there is the linear dependence between the dependent variable (WACC) and all independent variables included in the model. Analyzing all examined enterprises of IT sector, the linear dependence between the discount rate and all factors included in particular models was confirmed.
4.4 Random Elements Features
Then, random elements features were examined. It is needed to meet the features to assure the efficiency of coefficients estimators (Gauss-Markov assumption). To do this, firstly, the normality of random features.
4.4.1 Normality
Considering the huge test (ed. 2508 observations), the hypothesis of random features normality was verified by Kolmogorov-Smirnov test. The Table 6 includes the exemplary report generated by SPSS computer program for Assecopol enterprise.
I have made a null hypothesis that the random elements have got N(0, S Footnote 5 ɛ ) distribution.
In the case of the discount rate model for Assecopol, the empirical value of Kolmogorov-Smirnov statistics (K-S) equals 0.054. The critical value of accepted significance level 0.05 equals 1.358.Footnote 6 The K-S statistics value is lower than the critical value so there are no bases to reject the hypothesis concerned the normality of random elements distribution. The value of K-S statistics for all enterprises is presented in Table 7.
The normality of random elements, when the level of significance equals 0.05, was not confirmed for CDProject only. However, when we assumed that the level of significance equals 0.001, for which the critical value equals 1.627, the normality of significance elements happens. When the level of significance was changed for all analyzed models, the value of Kolmogorov-Smirnov statistics was lower than the critical value of accepted significance level. So, concerning all the cases, there are no bases to reject the hypothesis that the random elements have normal distribution.
4.4.2 Homoscedasticity
Equality of variance of random element was checked by Spearman’s rank correlation test. Using the test, it was checked if the variance of random elements increased (decreased) when the time passed.
I have made a null hypothesis about homoscedasticity of model random elements oppose to the alternative hypothesis. The alternative hypothesis reads about heteroscedasticity of the elements. If the H0 hypothesis is true, the statistics r has got asymptotically normal distribution \( N\left( {0,\frac{1}{{\sqrt {n - 1} }}} \right) \) (in practice, for a test n > 10). For the empirically set statistics value, there is \( \left| {r\sqrt {n - 1} } \right| < u_{\alpha } \) and there is no reason to reject H0 hypothesis about random elements homoscedasticity. The value of r statistics with the value \( \left| {r\sqrt {n - 1} } \right| \) for enterprises was presented in Table 8.
For the significance level 0.05 the critical value is 1.96 (according to normal distribution). In Table 8, there were bold enterprises for which the alternative hypothesis was accepted, which means for the models the random elements variance is not constant. For other models, the condition was met of homoscedasticity existence. When the significance level equals 0.001 (for which the critical value equals 3.2905), the homoscedasticity condition are not met for CDProject enterprise. To sum up, the level of significance equals 0.05, it should be assumed that the constructed models for the following enterprises: CDProject, McLogic and Simple, are not correct. At this stage, it can be claimed that the linear dependence between assessed discount rate for CD Project and the variables (which, according to the proposed model, should determine WACCCDProjekt linear dependence) cannot be proved. The model incorrectness for CDProject suggested also the low level of rate R2.
4.4.3 Autocorrelation of Any Order
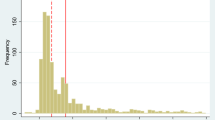
Autocorrelation is the random elements correlation which is not eligible. The verification test for autocorrelation was done by Gretl computer program. The inference based on graphic base of correlogram presentation (Fig. 3).

Autocorrelations function (ACF) for WACCwasko
Vertical poles in the presented correlogram chart are the autocorrelation coefficient for next delays in the determined range of delays. Because the observations 10-order with maximum delay does not exist in the standard mistake range, and even significantly cross the values, it should be found, that the autocorrelation happens. Autocorrelation function has not got the fast loss tendency (convergence to zero) together with the delay increase, so it should be found that the process is unsteady.
4.4.4 Summary
The constructed models do not meet all Gauss-Markov assumptions, especially the lack of autocorrelation. That is why; the proposed models cannot be used to build forecasts for a variable WACC. When the autocorrelation happens, the efficiency of estimators decrease and the lower efficiency of obtained results is a consequence. The causes of autocorrelation happening between the independent variables can be, first of all, read into inappropriate selection and method of the model construction (e.g. data can be characterized by periodicity and it could not be considered in modeling). The autocorrelation can also result from the nature of studied phenomenon—the existence of processes inertial and economic cases (which means, the effects of processes and economic cases are noticeable in the long period of time). The autocorrelation confirmed in the research can also prove that the past cases influenced the decision-making process (e.g. monetary policy, decisions concerned pricing, interest rates, and exchange rates) and autocorrelation existence implies that in the model, there is a need to consider the variables delayed in time. The attempt to eliminate autocorrelation was not finished successfully. In the presented research, as well in the case of financial series analysis, the better solution can be the use of ARMI or ARCH models. The financial markets specificity characterizes by relative freedom of decision-making and forecasting. It influences negatively the possibility to identify a trend and seasonal or periodical oscillations in the time series. It can limit the possibility of identification the dependence between financial series. However, the presented verification of models, constructed by SPSS statistic pack, allows determining that there is dependence between the dependent variable and independent variables.
Notes
- 1.
The number and the size of the report generated by SPSS computer program allows to put full reports and results of conducted analysis. That is why, the summary data or parts of the tables generated in the report are mostly presented.
- 2.
The sequence of independent variables in the models is connected with the accepted forward selection method.
- 3.
A unit e.g.: for exchange rates—PLN, budgetary deficit—bn PLN, Wibor3m—interest rate etc.
- 4.
According to the Student’s t-distribution tables, if the level of significance equals 0.05, the critical value equals 1.96. If the level of significance equals 0.1, the critical value equals 1.64 (for a huge test—when the degrees of freedom are over 500).
- 5.
It is the standard estimation mistake, which can be read in the SPSS computer program report in the table called “Model—summary”. Considering that the hypothesis is made for all models at the same time, the value of standard mistake was not entered because for different models, different values are accepted.
- 6.
According to the tables of Kolmogorov-Smirnov limiting distribution.
References
Duliniec, A.: Finansowanie przedsiębiorstwa, Strategie i instrumenty. Polskie Wydawnictwo Ekonomiczne, Warszawa (2011)
Pęksyk, M., Chmielewski, M., Śledzik, K.: Koszt kapitału a kryzys finansowy—przykład USA. In: Zarzecki, D. (ed.) Finanse, Rynki finansowe, ubezpieczenia nr 25—Zeszyty Naukowe Uniwersytetu Szczecińskiego nr 586, pp. 377–387, Szczecin (2010)
Blanke-Ławniczak, K., Bartkiewicz, P., Szczepański, M.: Zarządzanie finansami przedsiębiorstw. Podstawy teoretyczne, przykłady, zadania. Wydawnictwo Politechniki Poznańskiej, Poznań (2007)
Wrzosek, S. (ed.): Ocena efektywności inwestycji. Wydawnictwo Uniwersytetu Ekonomicznego we Wrocławiu, Wrocław (2008)
Wilimowska, Z., Wilimowski, M.: Sztuka zarządzania Finansami część 2, Bydgoszcz (2001)
Sierpińska, M., Jachna, T.: Ocena przedsiębiorstwa według standardów światowych. Wydawnictwo Naukowe PWN, Warszawa (2005)
Wilimowska, Z.: Ryzyko inwestowania. In: Ekonomika i Organizacja Przedsiębiorstwa nr 7/98, pp. 5–7
Brealey, R.A., Myers, S.: Podstawy finansów przedsiębiorstw tom 1. Wydawnictwo Naukowe PWN, Warszawa (1999)
Siudak, M.: Zarządzanie finansami przedsiębiorstwa. Oficyna Politechniki Warszawskiej, Warszawa (1999)
Gładysz, B., Mercik, J.: Modelowanie ekonometryczne, Studium przypadku. Wydanie II. Oficyna Wydawnicza Politechniki Wrocławskiej, Wrocław (2007)
Acknowledgements
The research presented in this paper was partially supported by the Polish Ministry of Science and Higher Education.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Gwóźdź, K. (2016). The Analyses of Factors Which Influence the Discount Rate—with an Example of IT Sector. In: Wilimowska, Z., Borzemski, L., Grzech, A., Świątek, J. (eds) Information Systems Architecture and Technology: Proceedings of 36th International Conference on Information Systems Architecture and Technology – ISAT 2015 – Part IV. Advances in Intelligent Systems and Computing, vol 432. Springer, Cham. https://doi.org/10.1007/978-3-319-28567-2_2
Download citation
DOI: https://doi.org/10.1007/978-3-319-28567-2_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-28565-8
Online ISBN: 978-3-319-28567-2
eBook Packages: EngineeringEngineering (R0)