
Abstract
An equivalent transfer function representation (TFR) is introduced to study the state-feedback/observer (SFO) topologies of control systems. This approach is used to explain why an observer can radically reduce even large model errors. Then the same principle is combined with Youla-parametrization (YP) introducing a new class of regulators
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction, the State Feedback (SF)
It is a well known methodology to use the state variable representations (SVR) of linear time invariant (LTI) single input - single output (SISO) systems [1]. The SVR proved to be excellent tool to implement both LQR (Linear system - Quadratic criterion - Regulator) control and pole placement design. The practical applicability required to introduce the observers, which make this methodology widely applied even for large scale and higher dimension plants [3]. Thousands of theoretical considerations mostly concentrate on the irregularities and special structures in the SVR appearing and much less publications deal with the model error properties of these systems.
It is possible to find a proper new way to discuss and investigate the the special properties and limitations of the classical state-feedback (SF), state-feedback/observer (SFO) topologies if someone replaces the SVR by their transfer function representations (TFR) [2].
Consider a SISO continuous time (t) LTI dynamic plant described by the SVR
Here P is the TFR of the open-loop system with the numerator and denominator polynomials
If we want to express the operation of the SF by equivalent scheme using TFR forms, Fig. 1 can be used, where the feedback regulator R f = K k is obtained from the basic equation (complementary sensitivity function, CSF) of the closed-loop

Equivalent schemes of SF using TFR forms
where k r is obtained by requiring that the static gain of T ry should be equal to one. The calibrating factor k r is necessary because the closed-loop using SF is not an integrating one. Equation (4) clearly shows, that the open-loop zeros remain unchanged and the closed-loop poles will be the required ones. The solution formally makes the characteristic polynomial of the closed-loop equal to the desired polynomial ("placed poles")
Here it is obtained that
which corresponds to the state feedback vector in the classical SVR.
2 Observer-Based State-Feedback with Equivalent TFR Forms
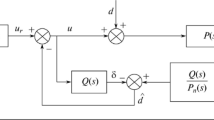
The practical applicability of the SF theory was introduced by the development of the observers capable to calculate the unmeasured state variables. The most general SF/Observer (SFO) topology discussed above can also be given using equivalent TFR forms of SF and is shown in Fig. 2.

Equivalent topology of the general basic SFO scheme using TFR forms
The usual classical design goal for the observer is to determine the observer feedback so that its feedback closed-loop system has the characteristic polynomial
The TFR K l (s) = L(s)/B(s) in Fig. 2 corresponds to the observer feedback vector in the classical SVR.
The pole-placement design goals for the SF and observer dynamics require
After some long, but straightforward block manipulations the equivalent SFO scheme can be transformed into another unity feedback closed-loop form given in Fig. 3.

Reduced equivalent topology of the general basic SFO scheme
It is interesting to observe that the transfer function of the closed-loop in Fig. 3 has a very special structure
It is formally two simpler closed-loops cascaded, which dynamically completely corresponds to the characteristic equation: R(s) = 0 and Q(s) = 0. The overall transfer function of the SFO system is
3 Model Error Properties
The above widely applied methodology has a common problem, that in all regulator and observer equations the true process P is used instead of the estimated model \( \hat{P} \) of the process. The equivalent TFR form of the SF using the model of the process is shown in Fig. 4.

The model based SF scheme and error
The parallel scheme in Fig. 4 is used to compute the model error. Using (4) the \( {\hat{T}}_{\mathrm{ry}} \) model-based version of T ry is
and its relative uncertainty
which shows that ℓ T = 0 for ℓ A = 0. Introducing the additive \( \varDelta = P-\hat{P} \) and relative plant model error
the modeling error ε k in Fig. 4 can be expressed as
The SFO scheme is widely applied in the practice with model-based SVR, so it is interesting how the model-based scheme in Fig. 5 influences the original modeling error ε k .

Model based SFO scheme with TFR forms
After some long but straightforward computations
is obtained. Equation (15) clearly shows the influence of the SFO scheme, because it decreases the modeling error ε k by (\( 1+{K}_l\hat{P} \)). Selecting fast observer poles, one can reach quite small "virtual" modeling error ε l in the major frequency domains of the tracking task.
Besides the radical model error attenuating behavior of the model-based SFO scheme, unfortunately it has a very important drawback, the nice cascade (9) structure changes to
which form is not factorable except for the exact model matching case, when ℓ → 0. On the basis of Fig. 5 and (16) it is easy to see that the poles of the observer feedback loop remain unchanged using the placement design equation forms model-based SFO (8), thus the only solution is to use the available model of the process, in this case \( \hat{A} \), i.e.,
for the pole placing equations.
Because this design ensures the required poles only for small ℓ (see (16)), a serious robust stability investigation is required first. Next it is important to investigate where the actual pole is located for non zero ℓ, so how big the performance loss is coming from the model based SFR. These steps are usually neglected in most of the published papers, books and applications.
4 Introducing the Observer Based Y oula-Regulator
For open-loop stable processes the all realizable stabilizing (ARS) model based regulator \( \hat{C} \) is the Y oula -parametrized one:
where the "parameter" Q ranges over all proper (Q(ω = ∞) is finite), stable transfer functions [5], [6], see Fig. 6a.

The equivalent IMC structure of an ARS regulator
It is important to know that the Y-parametrized closed-loop with the ARS regulator is equivalent to the well-known form of the so-called I nternal M odel C ontrol (IMC) principle [6] based structure shown in Fig. 6b.
Q is anyway the transfer function from r to u and the CSF of the whole closed-loop for \( \hat{P}= P \), when ℓ → 0
is linear (and hence convex) in Q.
It is interesting to compute the relative error ℓ T of \( {\hat{T}}_{\mathrm{ry}} \)
The equivalent IMC structure performs the feedback from the model error ε Q . Similarly to the SFO scheme it is possible to construct an internal closed-loop, which virtually reduces the model error to
and performs the feedback from ε l (see Fig. 7), where \( {\hat{L}}_l \) is the internal loop transfer function. In this case the resulting closed-loop will change to the scheme shown in Fig. 8.

The observer-based IMC structure

Equivalent closed-loop for the observer-based IMC structure
This means that the introduction of the observer feedback changes the Y oula -parametrized regulator to
The form of \( {\hat{C}}^{\prime } \) shows that the regulator virtually controls a fictitious plant \( {\hat{P}}^{\prime } \) which is also demonstrated in Fig. 8. Here the fictitious plant is
The closed-loop transfer function is now
The relative error ℓ ′T of \( {\hat{T}}_{\mathrm{ry}}^{\prime } \) becomes
which is smaller than ℓ T. The reduction is by \( \hat{H}=1 / \left(1+{\hat{L}}_l\right) \).
5 An Observer Based PID-Regulator
The ideal form of a Youla-regulator based on reference model design [4], [5] is
when the inverse of the process is realizable and stable. Here the operation of R n can be considered a reference model (desired system dynamics). It is generally required that the reference model has to be strictly proper with unit static gain, i.e., R n(ω = 0) = 1.
For a simple, but robust PID regulator design method assume that the process can be well approximated by its two major time constants, i.e.,
According to (26) the ideal Youla-regulator is
Let the reference model R n be of first order
which means that the first term of the regulator is an integrator
whose integrating time is equal to the time constant of the reference model. Thus the resulting regulator corresponds to the design principle, i.e., it is an ideal PID regulator
with
The Youla-parameter Q in the ideal regulator is
It is not necessary, but desirable to ensure the realizability, i.e., to use
where T can be considered the time constant of the derivative action (0.1 T D ≤ T ≤ 0.5 T D). The regulator \( {\hat{C}}^{\prime } \) and the feedback term \( \hat{H} \) must be always realizable. In the practice the PID regulator and the Youla-parameter is always model-based, so
The sheme of the observer based PID regulator is shown in Fig. 9, where a simple PI regulator
is applied in the observer-loop. Here T l must be in the range of T, i.e., considerably smaller than T 1 and T 2.

An observer based PID regulator
Note that the frequency characteristic of \( \hat{H} \) cannot be easily designed to reach a proper error suppression. For example, it is almost impossible to design a good realizable high cut filter in this architecture. The high frequency domain is always more interesting to speed up a control loop, so the target of the future research is how to select \( {\hat{K}}_l \) for the desired shape of \( \hat{H} \).
6 Simulation Examples
The simulation experiments were performed in using the observer based PID scheme shown in Fig. 9.
Example 1
The process parameters are: T 1 = 20, T 2 = 10 and A = 1. The model parameters are: \( {\hat{T}}_1=25 \), \( {\hat{T}}_2=12 \) and \( \hat{A}=1.2 \). The purpose of the regulation is to speed up the basic step response by 4, i.e., T n = 5 is selected in the first order R n . In the observer loop a simple proportional regulator \( {\hat{K}}_l=0.01 \) is applied. The ideal form of Q (33) was used. Figure 10 shows some step responses in the operation of the observer based PID regulator.

Step responses using the observer based PID regulator
It is easy to see that the \( {\hat{T}}_{\mathrm{ry}}^{\prime } \) very well approximates R n in the high frequencies (for small time values) in spite of the very bad model \( \hat{P} \).
Example 2
The process parameters and the selected first order R n are the same as in the previous example. The model parameters are: \( {\hat{T}}_1=30 \), \( {\hat{T}}_2=20 \) and \( \hat{A}=0.5 \). In the observer loop a PI regulator (37) is applied with A l = 0.001 and T l = 2. The ideal form of Q (33) was used. Figure 11 shows some step responses in the operation of the observer based PID regulator.

Step responses using the observer based PID regulator
It is easy to see that the \( {\hat{T}}_{\mathrm{ry}}^{\prime } \) well approximates R n in the high frequencies (for small time values) in spite of the very bad model.
7 Conclusions
The TFR of the classical methods are introduced to get a simple and useful tool to analyze and explain further behaviors, which are difficult to obtain using SVR. Using TFR it was shown, if the SVR used in the SFO scheme is model-based then the original (without observer) model error decreases by the sensitivity function of the observer feedback loop. This model error reducing capability gives the theoretical background of the success of practical model-based SFO applications.
Finally the SFO method was applied for the classical IMC structure, opening a new class of methods for open-loop stable processes. This new method combines the classical Youla-parametrization based regulators with the SFO scheme. Using this new approach an observer based PID regulator was also introduced. This regulator works well even in case of large model errors as some simulations showed.
References
Åström K.J. (2002). Control System Design Lecture Notes, U of California, Santa Barbara.
Bányász, Cs. and L. Keviczky (2004). State-feedback solutions via transfer function representations, J. Systems Science, 30, 2, pp. 21-34.
Kailath T. (1980). Linear Systems, Prentice Hall.
Keviczky L. (1995). Combined identification and control: another way. (Invited plenary paper.) 5th IFAC Symp. on Adaptive Control and Signal Processing, ACASP'95, Budapest, H, pp. 13-30.
Keviczky L. and Cs. Bányász (2001). Iterative identification and control design using K-B parametrization, In: Control of Complex Systems, Eds: K.J. Åström, P. Albertos, M. Blanke, A. Isidori, W. Schaufelberger and R. Sanz, Springer, pp. 101-121.
Maciejowski J.M. (1989). Multivariable Feedback Design, Addison Wesley.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Additional information
This work was supported in part by the MTA-BME Control Engineering Research Group of the HAS, at the Budapest University of Technology and Economics and by the project TAMOP 4.2.2.A-11/1/KONV-2012-2012, at the Széchenyi University of Győr.
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Keviczky, L., Bányász, C. (2015). Generalization of the Observer Principle for YOULA-Parametrized Regulators. In: Selvaraj, H., Zydek, D., Chmaj, G. (eds) Progress in Systems Engineering. Advances in Intelligent Systems and Computing, vol 366. Springer, Cham. https://doi.org/10.1007/978-3-319-08422-0_6
Download citation
DOI: https://doi.org/10.1007/978-3-319-08422-0_6
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-08421-3
Online ISBN: 978-3-319-08422-0
eBook Packages: EngineeringEngineering (R0)