
Abstract
The reduced order model (ROM) is one of the methods for quickly monitoring the response results when operating conditions change in complex systems. In the conventional method, human and numerical costs are incurred in pre-treatment, interpretation, post-processing to monitor the results of a response under a specific operating condition using numerical analysis. A simplified model is developed that faithfully reproduces higher-order models while lowering the degree of freedom (DOF) of complex systems. Training data should be collected for ROM configuration to predict the performance of the compressor. After setting the operating conditions inside and outside the actual operating area of the compressor as the analysis conditions of the 3D Fluid–Structure Interaction simulation results are collected as training data. The ROM for predicting the performance of the compressor is generated based on the training data. Although a large amount of data is required for high accuracy ROM generation, simulation can only obtain a small amount of training data with a long analysis time. Artificial Neural Network Method complements small amounts of training data by extending to large amounts of data. This paper is a study to establish a methodology for making ROM for predicting the performance of reciprocating compressor. The accuracy of the ROM is verified by comparing it with the experimental data.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
General numerical analysis methods for performance analysis of compressors can be divided into 1D, a low-dimensional analysis, and 3D, a high-dimensional analysis. 1D analysis takes less time to analyze, but due to dimensional limitations, it is limited to accurately simulate the fluid characteristics inside the compressor, while 3D analysis uses high-order equations, so it can simulate the internal behavior of the compressor close to natural phenomena, but it takes a long time to interpretation. There are difficulties in selecting the analysis model because there are advantages and disadvantages of each analysis model. To solve this problem, a solution is proposed to generate the reduced order model (ROM) based on high-accuracy 3D analysis results and connect the 1D analysis model with the ROM. As a result, the long analysis time, which is a disadvantage of the 3D analysis model, is shortened, and the low accuracy, which is a disadvantage of the 1D analysis model, is increased.
Lucia et al. [1] discussed the development of reduced order modeling techniques and their applicability in computational physics, especially in the multi-disciplinary field of computational aeroelasticity. Nayfeh et al. [2] presented the reduced order models for microbeams and rectangular and circular microplates. They validated these models by comparing their results with theoretical and experimental results. Yi-dong et al. [3] proposed a strategy to develop the reduced order model based on CFD results. The results showed the benefits of using ROM methodology for process simulation and optimization. Stabile et al. [4] compared and tested the accuracy of two different pressure stabilization strategies for POD-Galerkin ROMs based on a finite volume approximation. The ROMs are used to approximate the parametrised unsteady Navier–Stokes equations for moderate Reynolds numbers.
In many previous studies, researchers did not discuss about the use of ROM when predicting the performance of reciprocating compressors. It is necessary to use the ROM because the ROM can reduce the shortcomings of numerical analysis methods. The objective of this study is to establish a methodology for development of reduced order model for performance prediction of reciprocating compressors.
2 Training Data
2.1 3D FSI Data
The training data required for reduce order model (ROM) configuration to predict the performance of the compressor is collected. After setting the operating conditions inside and outside the actual operating conditions of the compressor as the analysis conditions of the 3D analysis simulation, the analysis result, 3D Fluid–Structure Interaction (FSI) Data, is collected as training data.
2.2 Input and Output Parameter
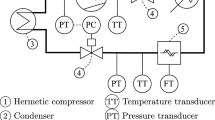
The input parameters of training data include six parameters, and the output parameters of training data include nine parameters. The input parameters and output parameters are shown in Fig. 1. The case of training data is determined according to the combination of the input parameters. In this study, RT has four conditions, RPS has four conditions, and the combination of \({T}_{e}\), \({T}_{c}\), \({P}_{s}\), \({P}_{d}\) has five conditions. So, the training data has 80 conditions. The meanings, ranges, and the number of conditions of input parameters are displayed in Table 1.

Input and output parameters of training data
2.3 Reliability Verification of Training Data
Two methods are used to verify the reliability of training data. One is to compare mass flow rate with the experimental results under seven conditions, and the other is to compare discharge average temperature with the experimental results under four conditions. Table 2 shows the error rate of mass flow rate under seven conditions, and Table 3 shows the error rate of discharge average temperature under four conditions. The reliability of training data is verified because the error rate is < 10% under all eleven conditions. To verify the reliability of the training data, the additional data is generated. The additional data is used for data extending and ROM generation.
3 Data Extending
3.1 ANN Method
The artificial neural network (ANN) method is chosen to extend a small amount of training data. This is because the ANN method is a specialized method for predicting figures by inputting figures. The ANN model receives input parameters from the input layer, multiplies by weights, and adds them all, and predicts output parameters from output layer through hidden layers containing activation function.
Figure 2 represents an example of ANN model and the process of obtaining the output value. In Eq. (1), \({y}_{k}^{l-1}\) is the output value of the previous layer and the input value of the current layer. \({a}_{k}^{l-1}\) is multiplied by the weight \({\omega }_{jk}^{l}\), and bias \({b}_{j}^{l}\) is added to the sum of the weight products. After that, the output value \({y}_{j}^{l}\) is obtained after passing the activation function \(f\) [5].

Structure of artificial neural network
In this study, the ANN model consists of one input layer, one output layer, and four hidden layers. The input layer has six nodes, the output layer has nine nodes, and each hidden layer has fifty nodes. The function tanh and sigmoid are selected as the activation functions. The error is calculated through the root mean square error (RMSE) of Eq. (2). ANN method proceeds in the direction in which the value of RMSE is minimized, and the value of the weight and bias of ANN model is optimized as the error is minimized.
3.2 Data Extending Method Using ANN Method
The reduced order model (ROM) is generated based on the training data. Although a large amount of data is required for high-accuracy ROM, 3D FSI simulation can only obtain a small amount of training data due to its long interpretation time. It complements a small amount of training data by expanding a small amount of training data to a large amount of data through ANN model.
Figure 3 shows the flow chart for ANN model development and data expansion. Training data is trained on ANN model. When new input parameters are entered into the developed ANN model, the output parameters are predicted. The prediction results are obtained as extended data [6]. The range of the new input parameters cannot be outside the range of the training data used for ANN model development. This is because ANN model cannot accurately predict data from untrained areas. A small amount of training data is supplemented by using data expansion by ANN model, and extended data is applied when ROM is generated.

Flow chart of data extending
4 Reduced Order Model
4.1 Concept of Reduced Order Model
The reduced order model (ROM) is one of the methods for quickly monitoring the corresponding response results when operating conditions change in the complex system. In the numerical analysis, human and numerical costs are incurred in pre-treatment, interpretation, post-processing to monitor the response results under specific operating conditions. To address the shortcomings of numerical analysis in the development and monitoring of complex systems, simplified model is developed that faithfully reproduces high-dimensional analysis model while lowering the degree of freedom (DOF) of the complex systems.
4.2 Development of Reduced Order Model
Figure 4 shows the process of generating ROM in the ANSYS Workbench. The ANSYS Workbench supports the generation of ROM that can analyze the system in short simulation time. In the ANSYS Workbench, training data and extended data are entered to generate ROM. The ANSYS Workbench provides a variety of response surface type. There is a difference in the accuracy and calculation time of the ROM according to the response surface type. There are many methods for verifying the accuracy of ROM, but in this study, the accuracy is verified by comparing the cooling capacity of the experimental results with the cooling capacity predicted by ROM. The ROM is converted into Functional Mock-up Unit (FMU). The reason for converting to FMU is that ROM is implemented within the Ansys Workbench, but ROM cannot be directly linked to the 1D analysis model. The function that enables this connection is to convert ROM into FMU. By connecting FMU to the 1D analysis model, the 1D analysis model can apply 3D analysis results with high accuracy without long analysis time [7].

Flow chart of generating ROM
4.3 Response Surface Type
Genetic Aggregation. Genetic Aggregation is method that optimizes predictions for input values using genetic algorithm. Equation (3) represents the mathematical model of Genetic Aggregation.
\({\widehat{y}}_{ens}\) is the prediction of the ensemble, \({\widehat{y}}_{i}\) is the prediction of the ith response surface, \({N}_{M}\) is the number of met models used and \({N}_{M}>1\), \({w}_{i}\) is the weight factor of the \({i}^{th}\) response surface. The weight factors satisfy: \(\sum_{i=1}^{{N}_{M}}{w}_{i}=1\) and \({w}_{i}\ge 0\), \(1\le i\le {N}_{M}\). The weight factors are optimized through the genetic algorithm [8].
Non-parametric Regression. The mathematical model of Non-parametric Regression is represented as Eq. (4). The function \(f\) is a fitting equation for output values. By adding and subtracting the margin of tolerance \(\varepsilon\) to the function \(f\), all output values are included within the range of predicted values. Figure 5 shows the behavioral pattern of Non-parametric Regression.

Behavioral pattern of response surface
Kriging. Kriging is method that represents predicted values for input values by adding a term of deviation to a quadratic polynomial function as shown in Eq. (5). The function \(f\) represents the general behavior of the model as a quadratic polynomial function, and the function \(z\) represents the local behavior of the model as a term of deviation. The term of deviation can be obtained by solving the covariance equation [9]. Figure 5 shows the behavioral pattern of Kriging.
Standard Response Surface. Standard Response Surface is very similar to Kriging. Standard Response Surface is expressed only as a quadratic polynomial function without a term of deviation as shown in Eq. (6).
5 Results and Discussion
5.1 Results of ANN
Figure 6 shows the training results of the ANN model for nine output parameters. The x-axis is the output parameter of the training data, and the y-axis is the result calculated by the trained ANN model. The points line up on the graphs because the output parameters of the training data and the calculated results match. However, among the nine output parameters, a large error occurred at the maximum torque. The reason is that the input parameter of the result of the large error is an extreme condition in which it is difficult to form a normal refrigeration cycle.

Training results of ANN model
5.2 Reliability Verification of Extended Data
After learning the training data, entering new input parameters into the trained ANN model yields predictive results considering nonlinearity. Among these predictive results, results that are outside the margin of error are excluded. In this study, the margin of error is 10%. The new input parameters input to the trained ANN model are the input parameters of the experimental conditions. The trained ANN model predicts the output parameters under the corresponding experimental conditions. There are two reasons for entering the experimental conditions into the new input parameters. First, the experimental conditions are within the range of the training data used for ANN model development. Second, the accuracy of the predicted data can be verified by comparing the cooling capacity of the experimental results with the cooling capacity of the predicted data.
Figure 7 is a graph showing the cooling capacity of predicted data. The x-axis is the cooling capacity of the experimental results, and the y-axis is the cooling capacity predicted by the trained ANN model. Since there are 100 experimental conditions, ANN model predicts 100 data. Of the 100 data, 93 data are selected as extended data. The reason is that 93 data are within 10% of the error rate, and the remaining seven data exceed 10% of the error rate.

Cooling capacity predicted by ANN method
5.3 Accuracy of Reduced Order Model
The method for verifying the accuracy of ROM is to compare the number of cases with an error rate of < 10% by comparing the cooling capacity of the experimental results with the cooling capacity predicted by ROM. The ROM Accuracy represents the number of cases with an error rate of < 10%. Since the experimental conditions are 100 cases, the ROM Accuracy is expressed as an integer from 0 to 100.
Another method to verify the accuracy of ROM is to compare the average error rate and the maximum error rate for 100 cases. The inclusion of extended data in the ROM reduces the average error rate from 4.656% to 4.318% and the maximum error rate from 11.77% to 9.777%. As the error rate is <10% for all 100 cases, the ROM Accuracy is 100. Figure 8 shows the error rate according to the amount of data.

Accuracy of reduced order model according to the amount of data
Table 4 shows the accuracy of the ROM according to the response surface type. Genetic Aggregation shows the highest accuracy when comparing the accuracy of the ROM according to the response surface type. The ROM Accuracy is 100, the average error rate is 4.318%, and the maximum error rate is 9.777%.
6 Conclusions
In this study, the reduced order model (ROM) was generated to predict the performance of reciprocating compressors and the methodology for development of ROM was established. The ROM can be developed in the following process.
-
The 3D Fluid-Structure Interaction (FSI) Data is collected as training data.
-
The train data is extended by ANN method.
-
In the ANSYS Workbench program, the training data and extended data are entered to generate ROM.
-
The ROM is converted into Functional Mock-up Unit (FMU).
-
The accuracy of the ROM is verified through comparison with the experimental results.
Accuracy results show best performance when extended data is applied to the ROM and when response surface type is Genetic Aggregation.
References
D.J. Lucia, P.S. Beran, W.A. Silva, Reduced-order modelling: new approaches for computational physics. Prog. Aerosp. Sci. 40, 51–117 (2004)
A.H. Nayfeh, M.I. Younis, E.M. Abdel-Rahman, Reduced-order models for MEMS applications. Nonlinear Dyn. 41, 211–236 (2005)
Y.-D. Lang, A. Malacina, L.T. Biegler, S. Munteanu, J.I. Madsen, S.E. Zitney, Reduced order model based on principal component analysis for process simulation and optimization. Energy Fuels 23, 1695–1706 (2009)
G. Stabile, G. Rozza, Finite volume POD-Galerkin stabilised reduced order methods for the parametrised incompressible Navier-Stokes equations. Comput. Fluids 173, 273–284 (2018)
Y. Park, M. Choi, K. Kim, X. Li, C. Jung, S. Na, G. Choi, Prediction of operating characteristics for industrial gas turbine combustor using an optimized artificial neural network. Energy 213, 118769 (2020)
Q.Q. Sun, H.C. Zhang, Z.J. Sun, Y. Xia, Ridge regression and artificial neural network to predict the thermodynamic properties of alkali metal Rankine cycles for space nuclear power. Energy Conv. Management 273, 116385 (2022)
Han Suk Kim, Design techniques for heat sink thermal analysis using a reduced order model (ROM). Korean Institute Power Electron. 25(4), 44–49 (2020)
J. Xiangjie, Z. Cai, W. Chong, Response surface optimization of machine tool column based on ansys workbench. Acad. J. Manuf. Eng. 18(2), 162–170 (2020)
B.C. Song, I.K. Bang, D.S. Han, G.J. Han, K.H. Lee, Structural design of a container crane part-jaw, using metamodels. J. Korean Soc. Manuf. Process Eng. 7(3), 17–24 (2008)
Acknowledgements
This work was supported by the Korea Institute of Energy Technology Evaluation and Planning (KETEP) and the Ministry of Trade, Industry and Energy (MOTIE) of the Republic of Korea (No. 2022730000005B) and This work was supported by Korea Institute of Energy Technology Evaluation and Planning (KETEP) grant funded by the Korea government (MOTIE) (20214000000140, Graduate School of Convergence for Clean Energy Integrated Power Generation).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Jeong, H. et al. (2024). Development of Reduced Order Model for Performance Prediction of Reciprocating Compressor. In: Read, M., Rane, S., Ivkovic-Kihic, I., Kovacevic, A. (eds) 13th International Conference on Compressors and Their Systems. ICCS 2023. Springer Proceedings in Energy. Springer, Cham. https://doi.org/10.1007/978-3-031-42663-6_32
Download citation
DOI: https://doi.org/10.1007/978-3-031-42663-6_32
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-42662-9
Online ISBN: 978-3-031-42663-6
eBook Packages: EngineeringEngineering (R0)