
Abstract
This is the companion paper for the ICPR 2022 Paper “Deep Saliency Map Generators for Multispectral Video Classification”, that investigates the applicability of three saliency map generators on multispectral video input data. In addition to implementation details of modifications for the investigated methods and the used neural network implementations, the influence of the parameters and a more detailed insight in the training and evaluation process is given.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Providing the source code not only gives a better understanding of the statements, it also helps to verify the outcomes of the examined experiments. Nonetheless, even the best-documented source code can still leave questions unanswered, such as how a specific parameterization changes the results or why a selected metric was chosen. In the following, a more detailed view on the examined saliency map generators (Sect. 2) of the addressed Paper [1] is given. In addition, the influence of the methods’ parameters regarding the deletion and insertion metric is shown. Afterwards, the used network implementations are described (Sect. 3). The last section covers the evaluation with the used metrics (Sect. 4).
Our source code can be found at GitHubFootnote 1 and requires Python 3.9, PyTorch 1.8.2 LTS, and torchvision 0.9.
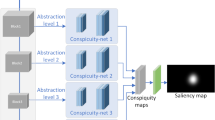
2 Deep Saliency Map Generators
The three investigated methods are Grad-CAM [4], Randomized Input Sampling for Explanation (RISE) [3] and the similarity difference and uniqueness method (SIDU) [2]. Since they are usually applied to ordinary images, some adjustments have been made, that are explained in the following. For Table 1 and Table 2, \(\uparrow \) (\(\downarrow \)) indicates, that a higher (lower) value is better.
2.1 Grad-CAM
While Grad-CAM not only outperforms its competitors, it is also the simplest to implement. Grad-CAM generates a saliency map by calculating a weighted sum of the forward features of the last convolutional layer. The weights are determined by the gradient of the target class. Grad-CAM requires a forward and backward pass of the input through the network. We therefore register a forward and backward hook at the target layer of our model, to extract the forward features
 and the gradient
and the gradient
 for the score \(y^c\) of the target class c. Here, k equals the number of forward feature maps, generated by the network. The gradient is summed to obtain the neuron importance weights
for the score \(y^c\) of the target class c. Here, k equals the number of forward feature maps, generated by the network. The gradient is summed to obtain the neuron importance weights

as described by [4]. The forward features are multiplied with the neuron importance weights and activated via ReLU. The final saliency map
is given by the upscaled weighted sum of the features. Since 3D ResNet generates three-dimensional forward features, the temporal dimension must also be taken into account in Eq. 1. Additionally, the bilinear interpolation in Eq. 2 changes to a trilinear interpolation.
2.2 RISE
RISE is a Monte Carlo approach that masks the input and calculates a weighted sum of the masks according to the output of the masked input to retrieve a saliency map. For RISE, we largely stick to the official implementationFootnote 2: First, \(n=1000\) random binary grids of size \(\boldsymbol{s}=2\times 8\times 8\) are sampled in such a way, that the value of a tile of the grid equals one with a probability of \(p=0.1\). Each grid is either bilinear or trilinear, upscaled to a slightly larger size than the input. The resulting grids are randomly cropped to match the input size. After this, the input data is multiplied elementwise with these masks and propagated through the network. The resulting network output \(\boldsymbol{P}\) is then used as a weighting term in the calculation of the final saliency map:

As it can be seen in Table 1, the usage of more masks lead to slightly better Deletion and Insertion scores, but comes at the cost of a significant higher computation time. Furthermore, the temporal mask resolution with \(\boldsymbol{s}=2\times \ 8\times 8\) leads in almost all cases to the best or tied to the best scores. The increased probability of \(p=0.25\) for a grid tile to be nonzero, has also a positive influence and leads to slightly better scores.
2.3 SIDU
SIDU uses the features of the last convolutional layer to mask the input data, propagates the masked input through the network and calculates the similarity differences and a uniqueness scores of the output to finally generate a saliency map. As for RISE, we also stick largely to the official implementation of SIDUFootnote 3. To extract the forward features, we register a forward hook at the target layer of the used model and perform a forward propagation. The network output \(\tilde{\boldsymbol{P}}\) and the forward features
 are recorded. The masks
are recorded. The masks

are the result of the binarization of the forward features with a threshold (\(\tau = 0.5\)), followed by a bilinear or trilinear upscaling. Similar to RISE, the masks are elementwise multiplied with the input data and propagated through the network. The resulting network output \(\boldsymbol{P}\) is used in the calculation of the similarity difference sd and uniqueness u scores. The resulting saliency map

is the product of those two scores and the corresponding masks.
Table 2 shows the influence of \(\tau \) on the Deletion and Insertion scores. For \(\tau \ge 0\), the Deletion and Insertion scores are quite similar.
3 Networks
The investigated network families are 3D-ResNets and the Persistent Appearance Networks (PAN). Since the Multispectral Action Dataset is comparably small, we used the 3D-ResNet 18 provided by torchvision and the official PAN-Lite network implementationFootnote 4.
3.1 3D-ResNet
The target layer for the forward feature extraction of Grad-CAM and RISE, when used with 3D-ResNets, is the output of the last convolutional layer right before the pooling layer. The upscaling for all three investigated methods is trilinear.
3.2 Persistent Appearance Network
Since we use PAN with a ResNet 50 backbone, the forward features are also extracted at the last convolutional layer right before the pooling layer. The upscaling, however, is bilinear for Grad-CAM and SIDU and trilinear for RISE. The trilinear upscaling provides a more temporally stable mask.
4 Evaluation
The experiments are evaluated with the Deletion and Insertion metric on sequences of the Multispectral Action Dataset. The fixed train and test split can be found in the git repository, while the dataset can be freely requested.


4.1 Deletion Metric
Given a saliency map
 and an input sequence
and an input sequence
 , the Deletion metric (see Algorithm 1) first sorts the indices of the entries of
, the Deletion metric (see Algorithm 1) first sorts the indices of the entries of
 in descending order, according to their values. Afterwards, the sorted indices are separated in n coherent parts and the values of
in descending order, according to their values. Afterwards, the sorted indices are separated in n coherent parts and the values of
 are successively replaced with a fixed value \(v=0\), according to the partition order. After each part, the classifier f computes the class probability for the target class t of the modified input. The class probability after the ith part is recorded in \(\boldsymbol{p}_i\). Finally, the area under the curve of the entries of \(\boldsymbol{p}\) and the linear spaced values from 0 to 1 in n steps is returned.
are successively replaced with a fixed value \(v=0\), according to the partition order. After each part, the classifier f computes the class probability for the target class t of the modified input. The class probability after the ith part is recorded in \(\boldsymbol{p}_i\). Finally, the area under the curve of the entries of \(\boldsymbol{p}\) and the linear spaced values from 0 to 1 in n steps is returned.
4.2 Insertion Metric
Similar to the Deletion metric, the Insertion metric (see Algorithm 2) successively unblurs a blurred version
 of the input data
of the input data
 , according to the importance score of the given saliency map
, according to the importance score of the given saliency map
 .
.
5 Conclusion
This paper shows the impact of different parameter choices for already existing methods, namely Grad-CAM, RISE and SIDU, when applied not to ordinary images but rather video input data in the visual and long-wave infrared spectrum. To quantify the results, the Deletion and Insertion metric are used. While for RISE, a higher number of generated masks seems to improve the scores, a higher temporal mask resolution seems to be counterproductive. The probability parameter used by RISE seems not to have a big impact. For SIDU, the default value for the threshold \(\tau =0.5\) results in most cases in the best or close to the best scores.
References
Bayer, J., Munch, D., Arens, M.: Deep Saliency Map Generators for Multispectral Video Classification. In: 2022 26th International Conference on Pattern Recognition (ICPR), pp. 3757–3764. IEEE (8 2022). https://doi.org/10.1109/ICPR56361.2022.9955639. https://ieeexplore.ieee.org/document/9955639/
Muddamsetty, S.M., Mohammad, N.S.J., Moeslund, T.B.: SIDU: Similarity Difference And Uniqueness Method for Explainable AI. In: 2020 IEEE International Conference on Image Processing (ICIP), pp. 3269–3273. IEEE (10 2020). https://ieeexplore.ieee.org/document/9190952/
Petsiuk, V., Das, A., Saenko, K.: RISE: Randomized input sampling for explanation of black-box models. In: British Machine Vision Conference (BMVC) (2018)
Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-CAM: visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vision 128(2), 336–359 (2019). https://doi.org/10.1007/s11263-019-01228-7
Acknowledgements
This work was developed in Fraunhofer Cluster of Excellence “Cognitive Internet Technologies”.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Bayer, J., Münch, D., Arens, M. (2023). Companion Paper: Deep Saliency Map Generators for Multispectral Video Classification. In: Kerautret, B., Colom, M., Krähenbühl, A., Lopresti, D., Monasse, P., Perret, B. (eds) Reproducible Research in Pattern Recognition. RRPR 2022. Lecture Notes in Computer Science, vol 14068. Springer, Cham. https://doi.org/10.1007/978-3-031-40773-4_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-40773-4_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-40772-7
Online ISBN: 978-3-031-40773-4
eBook Packages: Computer ScienceComputer Science (R0)
