
Abstract
The amount of data generated by the human race worldwide is increasing at an exponential rate every day. Therefore, data classification has become a necessity, and many researchers are focusing on evaluating automatic language processing techniques and improving text classification methods.
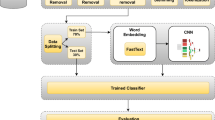
Recently, deep learning models have achieved state-of-the-art results in many areas, including a wide variety of NLP applications. In fact, deep learning has the potential to handle and analyze massive data in both supervised and unsupervised modes and in real time. This paper briefly introduces different feature extraction and classification algorithms and analyzes and compares the different textual representations on the performance of various text classification algorithms. The results show that distributed word representations such as word2vec and Glove outperform other feature extraction methods such as BOW. More importantly, contextual embedding, such as BERT, can achieve good performance compared to traditional word embedding and compared to other classification methods.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


References
Bengio, Y., Ducharme, J., Vincent, P., Janvin, C.A.: Neural probabilistic language model (2003)
Mnih, A., Hinton, G.: Three new graphical models for statistical language modeling. In ICML 2007: Proceedings of the 24th international conference on Machine learning, pp. 641–648. ACM (2007)
Collobert, R., Weston, J.: A unified architecture for natural language processing: Deep neural networks with multitask learning. In: International Conference on Machine Learning, ICML, pp. 160–167 (2008)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: pretraining of deep bidirectional transformers for language understanding. In: NAACL 2019 (2019). https://doi.org/10.18653/v1/N19-1423
Karim, A., Loqman, C., Hami, Y., Boumhidi, J.: Max stable set problem to found the initial centroids in clustering problem. Indon. J. Electr. Eng. Comput. Sci. 25(1), 569–579 (2022)
Karim, A., Loqman, C., Boumhidi, J.: Determining the number of clusters using neural network and max stable set problem. Procedia Comput. Sci. 127, 16–25 (2018)
Naili, M., Chaibi, A.H., Ghezala, H.H.B.: Comparative study of word embedding methods in topic segmentation. Procedia Comput. Sci. 112, 340–349 (2017)
Jiang, M., et al.: Text classification based on deep belief network and softmax regression. Neural Comput. Appl. 29(1), 61–70 (2016). https://doi.org/10.1007/s00521-016-2401-x
Kowsari, K., Heidarysafa, M., Brown, D.E., Meimandi, K.J., Barnes, L.E.: RMDL: random multimodel deep learning for classification. In: Proceedings of the 2018 International Conference on Information System and Data Mining, Lakeland, FL, USA, 9–11 April 2018 (2018). https://doi.org/10.1145/3206098.3206111
Kowsari, K., Brown, D.E., Heidarysafa, M., Jafari Meimandi, K., Gerber, M.S., Barnes, L.E.: HDLTex: hierarchical deep learning for text classification. machine learning and applications (ICMLA). In: Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017 (2017)
Yang, Z., Yang, D., Dyer, C., He, X., Smola, A.J., Hovy, E.H.: Hierarchical attention networks for document classification. In Proceedings of the HLT-NAACL, San Diego, CA, USA, 12–17 June 2016, pp. 1480–1489 (2016)
Zhang, X., Zhao, J., LeCun, Y.: Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 28, 649–657 (2015)
Levy, O., Goldberg, Y., Dagan, I.: Improving distributional similarity with lessons learned from word embeddings. Trans. Assoc. Comput. Linguist. 3, 211–225 (2015)
Pennington, J., Socher, R., Manning, C.: Glove: global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics (2014)
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representations in vector space (2013). http://arxiv.org/abs/1301.3781
Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Advances in Neural Information Processing Systems Conference (NIPS 2013), pp. 3111–3119 (2013)
Ye, Z., Byron, C.W.: A sensitivity analysis of (and practitioners’ guide to) convolutional neural networks for sentence classification. In: IJCNLP (2015). arXiv preprint arXiv:1510.03820
Lang, K.: Newsweeder: learning to filter netnews. In: Proceedings of the Twelfth International Conference on Machine Learning, pp. 331–339 (1995)
Acknowledgments
This work was supported by the Ministry of Higher Education, Scientific Research and Innovation, the Digital Development Agency (DDA) and the CNRST of Morocco [Alkhawarizmi/2020/36].
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Karim, A., Hami, Y., Loqman, C., Boumhidi, J. (2023). Case Studies of Several Popular Text Classification Methods. In: Motahhir, S., Bossoufi, B. (eds) Digital Technologies and Applications. ICDTA 2023. Lecture Notes in Networks and Systems, vol 668. Springer, Cham. https://doi.org/10.1007/978-3-031-29857-8_56
Download citation
DOI: https://doi.org/10.1007/978-3-031-29857-8_56
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-29856-1
Online ISBN: 978-3-031-29857-8
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)