
Abstract
In recent years, with the great success of deep learning, deep networks-based hashing has become a leading approach for image retrieval. Most existing deep hashing methods extract the semantic representations only from the last layer, resulting in structure information being ignored which contains additional semantic details that are useful for hash learning. To enhance the image retrieval accuracy by exploring the semantic information and the structure information (local information), We propose a new method of deep hashing called Deep Multi-Scale Hashing (DMSH). This is achieved, firstly, by extracting multiscale features from multiple convolutional layers. Secondly, the features extracted from the convolutional layers are fused to generate more robust representations for efficient image retrieval. The experiments on the CIFAR10 and NUS-WIDE datasets show the superiority of our method.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The rapid advances in the internet and communication have resulted in images’ massive overloading to the internet [22, 40, 41], making it extremely difficult to retrieve large-scale data accurately and effectively, representing a practical research problem. The hash-based image retrieval technique [36] has attracted increasing attention to guarantee retrieval quality and computation efficiency. The hashing methods perform to map images into compact binary codes to take advantage of binary codes’ superior computational and storage capabilities.
Existing hashing techniques can be divided into groups that are data-dependent and Data-independent. Data-independent approaches, representing locally-sensitive hashing (LSH) [11], are used in random projections as the hash functions to learn binary codes. However, these methods do have some limitations. The data-independent methods do not use auxiliary information, which makes them suffer in terms of poor image retrieval accuracy. Furthermore, They require long codes that cost plenty of storage [1, 11, 15]. To address this problem, data-driven methods exploit training information to create hash functions, obtaining shorter binary codes with better performance. Moreover, they can be categorized-into unsupervised hashing methods [12, 13, 25, 29] and supervised hashing methods [7, 9, 20, 23, 24, 33, 34].
On the other hand, deep hashing techniques [4, 10, 21, 42] have been proposed after the great success of deep neural networks on many computer vision tasks. Compared with traditional hashing approaches, deep hashing techniques exhibit advan- tages in extracting high-level semantic features and producing binary codes into an end-to-end framework. However, many recent works on deep hashing methods [14, 17, 31] used the penultimate layer features in fully connected layers as the global image descriptor. However, they are undesirable image features because the high-level features exhibit global details but lack local characteristics.
To address the above problems, in this paper, we propose a new deep hashing method called Deep Multi-Scale Hashing (DMSH), which use FPN in deep hashing—using FPN. Extracting the multi-level semantic and visual information from the input image is facilitated. To be more specific, An FPN builds a pathway of bottom-up and the top-down features with links between the features the network produces at different scales. The hash codes are then learned from these feature scales and fuse to obtain the final ones. Moreover, the network employs various hashing results depending on different scale features. Consequently, the network would improve retrieval recall while preventing precision degradation. The main contributions of the work, in brief, are as follows:
-
1.
A Deep Multi-Scale Hashing (DMSH) learns hash codes from various feature scales and fuses them to generate the final binary codes. As a result, the network will be able to retrieve better.
-
2.
A new deep hashing method is proposed that conducts joint optimization of feature representation learning and binary codes learning in a deep, unified framework.
-
3.
Experimentation based on two large-scale data-sets show that DMSH provides state-of-the-art performance in real applications.
2 Proposed Method
2.1 Problem Definition
Let \( X=\left\{ x_{i} \right\} ^{N}_{i=1}\in \mathbb {R} ^{ d \times N} \) denote the training dataset with N image samples, where \( Y=\left\{ y_{i} \right\} ^{N}_{i=1}\in \mathbb {R} ^{ K \times N} \) represents the ground truth labels of the \( x_{i} \), K is the number of classes. Let’s say that the pairwise labels for training images are represented by the matrix \(S = \left\{ s_{ij} \right\} \), where \(s_{ij} = 0\) represents no semantic similarity between samples \(x_{i}\) and \(x_{j}\) and \(s_{ij} = 1\) represents semantic similarity. The objective of deep hashing methods with pairwise labels is to Learning a nonlinear hash function \(f:x \mapsto B\in \left\{ -1,1 \right\} ^{L}\), which can the ability to convert each input data xi into binary codes \(b_{i}\in \left\{ -1,1 \right\} ^{L}\), L is the Hash code length.
2.2 Model Architecture
Lin [26] suggested that a feature pyramid network was applied to improve object detection in RetinaNet [27]. FPN aids the network in learning more effectively and detecting objects at various scales present in the image. Some previous methods worked by providing input to the network, such as an image pyramid. While doing this does enhance the feature extraction procedure, it also lengthens processing time and is less effective.
FPN solved this issue by creating the bottom-up and top-down connection of entities and merging them with network entities created at different levels via a lateral connection.
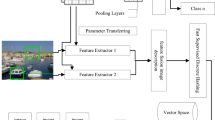
Figure 1 displays the architecture of our proposed method (DMSH). We used VGG-19 as the backbone network. The FPN we used is similar to the original FPN [26], with the difference that, in light of the authors’ expertise, we employed concatenation layers rather than adding layers within the feature pyramid. FPN extracts four final features, each presenting the input image’s features at various scales. The features obtained are fused using a convolutional (Conv1\(\,\times \,\)1) layer to get a merged feature and then apply dropout layers, followed by the first hash layers.
At the end of the design, we assembled the five hash layers. We then connected the latter to the final hash layer, and finally, we connected the final hash layer to the classification layer (the number of neurons in the classification layer is equal to the number of categories of the dataset). With this procedure, the network uses various hash results based on different features scale. The network will be able to retrieve images more effectively.

The architecture of our proposed method: Deep Multi-Scale Hashing (DMSH).
2.3 Objective Function
Pairwise Similarity Loss. We carry out our deep hashing method by maintaining the greatest similarity between each pair of images in the Hamming space. The inner product is used to calculate the pairwise similarity. For two binary codes, \(b_{i}\) and \(b_{j}\), the inner product is written as follows: \(dist_{H}\left( b_{i}, b_{j} \right) = \frac{1}{2}b_{i}^{T}b_{j}\)
Given that all binary codes of points are \(B = \left\{ b_{i} \right\} ^{N}_{i=1}\), we can write the likelihood of pairwise labels \(S = \left\{ s_{ij} \right\} \) as follows:
where \( \sigma (w_{ij}) = \frac{1 }{1+e^{-w_{ij}}} \), and \( w_{ij} = \frac{1}{2} b_{i}^{T}b_{j} \)
According to the equation above, we may deduce that the greater the inner product \(\langle b_{i},b_{j}\rangle \) corresponds to a smaller equivalent \(dist_{H}\left( b_{i}, b_{j} \right) \) and a larger \(p\left( 1|b_{i},b_{j} \right) \).
This indicates that when \(s_{ij}=1\), the hash codes \(b_{i}\) and \(b_{j}\) are regarded as similar, and vice versa.
We may get the following optimization problem by considering the negative log-likelihood of the pairwise labels in S:
The above optimization problem makes the distance between two similar points as small as possible, precisely what pairwise similarity-based hashing approaches aim to achieve.
Pairwise Quantization Loss. In real-world applications, discrete hash codes (binary codes) measure similarity. Optimizing discrete hash coding (binary) in CNN is difficult, however. Therefore, gradient disappearance through the back-propagation stage is avoided using the continuous hash coding version.
Discrete hash codes are utilized in real-world applications to determine similarity. However, discrete hash coding in CNN is challenging to optimize. Therefore, continuous hash coding prevents gradient disappearance during the back-propagation phase. Where the hash layer output is \(u_{i}\) and \(b_{i} = {{\,\textrm{sgn}\,}}\left( u_{i} \right) \). Hence, quantization loss has been introduced to reduce the gap between discrete and continuous hash codes. An objective function is defined as
Q is the mini-batches.
Classification Loss. We apply the classification loss (the cross-entropy loss) to identify the classes to obtain robust multiscale features. The classification loss function can be expressed as follows:
where \(y_{i,k}\) is the label, \(p_{i,k}\) is the output of the \(i-th\) training sample, which corresponds to the \(k-th\) class.
In conclusion, quantization loss, pairwise similarity loss, and classification loss can be combined to produce the overall loss function:
3 Experiments
3.1 Datasets
The CIFAR-10 [19] contains 60,000 images of 10 different categories, and each image is 32\(\times \)32 in size. Following [2], we sampled 100 images per category as a query set (a total of 1000) and the remaining images as a database. Additionally, 500 images per category are selected (a total of 5000) from the retrieval database as a training set.
NUS-WIDE. [8] is a multi-label data set containing approximately 270,000 images collected from Flickr consisting of 81 ground-truth concepts. We randomly sampled 2100 images from the 21 most frequent classes as the query set, while the rest as a database, and selected 10,000 images from the retrieval database as a training set.
3.2 Experimental Settings
Our DMSH implementation utilizes PyTorch. We use a convolutional network called VGG-19, pre-trained on ImageNet [30]. In all training, we use the Adam [18] algorithm. For the hyperparameters of the objective function, the beta to 0.1 and the alpha is set to 0.01.
3.3 Evaluation Metrics
We use four evaluation metrics to measure the retrieval performance of different hashing methods: Mean Average Precision (MAP), Precision-Recall curves, precision curves w.r.t, and Precision curve within Hamming radius 2. Five unsupervised approaches are included in our comparison of the proposed DMSH, i.e., SGH [16], LSH [11], SH [38], ITQ [13], PCAH [37], and two supervised approaches, i.e., KSH [28], SDH [32], and eight deep hashing approaches, i.e., DPH [3], CNNH [39], DNNH [21], DCH [5], DHN [42], HashNet [6], LRH [2], DHDW [35].
3.4 Results
Tables 2 and 3 displays the MAP results for all methods on the CIFAR-10 and NUS-WIDE data sets with different code lengths. The results in the table demonstrate how well the proposed DMSH method performs compared to all other techniques. In particular, on the datasets CIFAR-10 and NUS-WIDE, DMSH delivers absolute gains in average mAP of 49.4% and 24.44%, respectively, above SDH, the top shallow hashing technique. However, we can observe that deep hashing performs better than classical hashing techniques, mainly because it can produce more reliable representations of features. For deep hashing methods, On CIFAR-10 and NUS-WIDE, respectively, the average mAP of our suggested DMSH approach increased by 11.5% and 8.3% per cent compared to the second-best hashing method LRH.
Precision curves represent the retrieval performance in Figs. 2a and 3a (P@H = 2). The proposed DMSH performs noticeably better than alternative approaches. According to the precision curves, the proposed DMSH approach still has the highest precision rate when the code length rises.
We further highlight the effectiveness of our method in Figs. 2b, 3b, 2c and 3c, where we compare our method’s precision concerning top returned samples and Precision-Recall with other techniques. Figures 2c and 3c show that, for return sample counts between 100 and 1000, the suggested DMSH approach provides the highest precision with 48 bits. Based on Figs. 2a and 3b, it can be shown that our DMSH delivers significantly high precision at a low recall level, which is necessary for precision-first retrieval and is frequently utilized in real-world systems. In summary, our technique, DMSH, outperforms the compared techniques.

The comparison results on the CIFAR-10 dataset under three evaluation metrics.

The comparison results on the NUS-WIDE dataset under three evaluation metrics.

Top 20 retrieved results from CIFAR-10 dataset by DMSH with 48-bit hash codes. The first column shows the query images, the retrieval results of DMSH are shown at other columns.
4 Conclusions
In this paper, we developed an end-to-end Deep Multi-Scale Hashing (DMSH) for large-scale image retrieval, Which generates robust hash codes by optimizing the semantic loss, similarity loss, and quantization loss. In addition, the network employs different hashing results depending on various scale features. As a result, the network would improve retrieval recall while preventing precision degradation. The experimental results on two image retrieval data sets demonstrated that our method outperforms other state-of-the-art hashing methods. The suggested model can provide robust representative features due to its scalable structure, which allows for use in many additional computer vision tasks.
References
Andoni, A., Indyk, P.: Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Commun. ACM 51(1), 117–122 (2008)
Bai, J., et al.: Loopy residual hashing: filling the quantization gap for image retrieval. IEEE Trans. Multimedia 22(1), 215–228 (2019)
Bai, J., et al.: Deep progressive hashing for image retrieval. IEEE Trans. Multimedia 21(12), 3178–3193 (2019)
Cakir, F., He, K., Bargal, S.A., Sclaroff, S.: Hashing with mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 41(10), 2424–2437 (2019)
Cao, Y., Long, M., Liu, B., Wang, J.: Deep cauchy hashing for hamming space retrieval. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1229–1237 (2018)
Cao, Z., Long, M., Wang, J., Yu, P.S.: Hashnet: deep learning to hash by continuation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 5608–5617 (2017)
Chen, Z., Zhou, J.: Collaborative multiview hashing. Pattern Recogn. 75, 149–160 (2018)
Chua, T.S., Tang, J., Hong, R., Li, H., Luo, Z., Zheng, Y.: Nus-wide: a real-world web image database from national university of Singapore. In: Proceedings of the ACM International Conference on Image and Video Retrieval, pp. 1–9 (2009)
Cui, Y., Jiang, J., Lai, Z., Hu, Z., Wong, W.: Supervised discrete discriminant hashing for image retrieval. Pattern Recogn. 78, 79–90 (2018)
Erin Liong, V., Lu, J., Wang, G., Moulin, P., Zhou, J.: Deep hashing for compact binary codes learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2475–2483 (2015)
Gionis, A., Indyk, P., Motwani, R., et al.: Similarity search in high dimensions via hashing. In: Vldb, vol. 99, pp. 518–529 (1999)
Gong, Y., Kumar, S., Rowley, H.A., Lazebnik, S.: Learning binary codes for high-dimensional data using bilinear projections. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 484–491 (2013)
Gong, Y., Lazebnik, S., Gordo, A., Perronnin, F.: Iterative quantization: a procrustean approach to learning binary codes for large-scale image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 35(12), 2916–2929 (2012)
Gordo, A., Almazán, J., Revaud, J., Larlus, D.: Deep image retrieval: learning global representations for image search. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9910, pp. 241–257. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46466-4_15
Indyk, P., Motwani, R.: Approximate nearest neighbors: towards removing the curse of dimensionality. In: Proceedings of the 30th Annual ACM Symposium on Theory of Computing, pp. 604–613 (1998)
Jiang, Q.Y., Li, W.J.: Scalable graph hashing with feature transformation. In: 24th International Joint Conference on Artificial Intelligence (2015)
Jiang, Q.Y., Li, W.J.: Asymmetric deep supervised hashing. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 32 (2018)
Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
Kulis, B., Darrell, T.: Learning to hash with binary reconstructive embeddings. In: Advances in Neural Information Processing Systems, vol. 22 (2009)
Lai, H., Pan, Y., Liu, Y., Yan, S.: Simultaneous feature learning and hash coding with deep neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3270–3278 (2015)
Li, S., Chen, Z., Li, X., Lu, J., Zhou, J.: Unsupervised variational video hashing with 1d-cnn-lstm networks. IEEE Trans. Multimedia 22(6), 1542–1554 (2019)
Lin, G., Shen, C., Shi, Q., Van den Hengel, A., Suter, D.: Fast supervised hashing with decision trees for high-dimensional data. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1963–1970 (2014)
Lin, G., Shen, C., Suter, D., Van Den Hengel, A.: A general two-step approach to learning-based hashing. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2552–2559 (2013)
Lin, G., Shen, C., Wu, J.: Optimizing ranking measures for compact binary code learning. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8691, pp. 613–627. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10578-9_40
Lin, T.Y., Dollár, P., Girshick, R., He, K., Hariharan, B., Belongie, S.: Feature pyramid networks for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 2117–2125 (2017)
Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 2980–2988 (2017)
Liu, W., Wang, J., Ji, R., Jiang, Y.G., Chang, S.F.: Supervised hashing with kernels. In: 2012 IEEE Conference on Computer Vision and Pattern Recognition, pp. 2074–2081. IEEE (2012)
Liu, W., Wang, J., Mu, Y., Kumar, S., Chang, S.F.: Compact hyperplane hashing with bilinear functions. arXiv preprint arXiv:1206.4618 (2012)
Russakovsky, O., et al.: Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 115(3), 211–252 (2015)
Shen, F., Gao, X., Liu, L., Yang, Y., Shen, H.T.: Deep asymmetric pairwise hashing. In: Proceedings of the 25th ACM International Conference on Multimedia, pp. 1522–1530 (2017)
Shen, F., Shen, C., Liu, W., Tao Shen, H.: Supervised discrete hashing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 37–45 (2015)
Song, J., Gao, L., Liu, L., Zhu, X., Sebe, N.: Quantization-based hashing: a general framework for scalable image and video retrieval. Pattern Recogn. 75, 175–187 (2018)
Strecha, C., Bronstein, A., Bronstein, M., Fua, P.: Ldahash: Improved matching with smaller descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 34(1), 66–78 (2011)
Sun, Y., Yu, S.: Deep supervised hashing with dynamic weighting scheme. In: 2020 5th IEEE International Conference on Big Data Analytics (ICBDA), pp. 57–62. IEEE (2020)
Wang, J., Zhang, T., Sebe, N., Shen, H.T., et al.: A survey on learning to hash. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 769–790 (2017)
Wang, J., Kumar, S., Chang, S.F.: Semi-supervised hashing for large-scale search. IEEE Trans. Pattern Anal. Mach. Intell. 34(12), 2393–2406 (2012)
Weiss, Y., Torralba, A., Fergus, R.: Spectral hashing. In: Advances in Neural Information Processing Systems, vol. 21 (2008)
Xia, R., Pan, Y., Lai, H., Liu, C., Yan, S.: Supervised hashing for image retrieval via image representation learning. In: 28th AAAI Conference on Artificial Intelligence (2014)
Yan, C., Li, Z., Zhang, Y., Liu, Y., Ji, X., Zhang, Y.: Depth image denoising using nuclear norm and learning graph model. ACM Trans. Multimedia Comput. Commun. Appl. (TOMM) 16(4), 1–17 (2020)
Yan, C., Shao, B., Zhao, H., Ning, R., Zhang, Y., Xu, F.: 3d room layout estimation from a single RGB image. IEEE Trans. Multimedia 22(11), 3014–3024 (2020)
Zhu, H., Long, M., Wang, J., Cao, Y.: Deep hashing network for efficient similarity retrieval. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30 (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Redaoui, A., Belloulata, K., Belalia, A. (2023). Deep Multi-Scale Hashing for Image Retrieval (DMSH). In: Salem, M., Merelo, J.J., Siarry, P., Bachir Bouiadjra, R., Debakla, M., Debbat, F. (eds) Artificial Intelligence: Theories and Applications. ICAITA 2022. Communications in Computer and Information Science, vol 1769. Springer, Cham. https://doi.org/10.1007/978-3-031-28540-0_4
Download citation
DOI: https://doi.org/10.1007/978-3-031-28540-0_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-28539-4
Online ISBN: 978-3-031-28540-0
eBook Packages: Computer ScienceComputer Science (R0)