
Abstract
In video action segmentation scenarios, intelligent models require sufficient training data. However, the significant expense of human annotation for action segmentation makes this method prohibitively expensive, and only very limited training videos can be accessible. Further, large Spatio-temporal variations exist in training and test data. Therefore, it is critical to have effective representations with few training videos and efficiently utilize unlabeled test videos. To this end, we firstly present a brand new Contrastive Temporal Domain Adaptation (CTDA) framework for action segmentation. Specifically, in the self-supervised learning module, two auxiliary tasks have been defined for binary and sequential domain prediction. They are then addressed by the combination of domain adaptation and contrastive learning. Further, a multi-stage architecture is devised to acquire the comprehensive results of action segmentation. Thorough experimental evaluation shows that the CTDA framework achieved the highest action segmentation performance.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Deep learning has been essential to enhance the great performance for action recognition, particularly for shorter videos containing only a single action label. However, it is still a challenge on long untrimmed videos with many action segments, i.e., it is challenging for the model to correctly predict each frame’s action from a long video with fine-grained class labels. Many researchers pay attention to temporal convolutional networks (TCN) [15] in action segmentation. Nevertheless, it is still hard to train effectively with the limited amount of data for better performance on public datasets due to the high-cost human annotation of each frame from a long video. Therefore, it is crucial in action segmentation to exploit unlabeled data effectively for model training without additional large-scale manual annotated data.

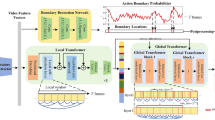
The overview of Contrastive Temporal Domain Adaptation (CTDA) for video action segmentation with three modules: self-supervised learning (SSL), feature extraction, and action prediction. In the SSL module, domain adaptation and contrastive learning are performed together from the source and target domains. In the feature extraction module, one prediction generation stage and several refinement stages are included for better representation.
Apart from training with limited annotated data, another challenge of action segmentation lies in that significant Spatio-temporal variations exist in training and test data. More specifically, Spatio-temporal variation refers to the same action which is executed by different subjects with different styles. It can be regarded as one of the domain adaptation problems [24]. The source domain is the videos with annotated labels while the target domain is the unlabeled videos. As a result, it is essential for us to minimize the discrepancy and enhance the generalization performance of an action segmentation model.
This paper proposes a new Contrastive Temporal Domain Adaptation (CTDA) framework in action segmentation with limited training/source videos. We are mainly inspired by the latest closely-related method SSTDA [3]. Specifically, we embed the most recent contrastive learning approaches in the following auxiliary domain prediction tasks. Concretely, binary domain prediction refers to the model performing one of the two auxiliary tasks to predict each frame’s domain (source domain or target domain), embedding frame-level features with local temporal dynamics. In contrast, sequential domain prediction is the other auxiliary task that the model predicts the domain of video segments and performs sequential domain prediction using video-level features in which global temporal dynamics from untrimmed videos are embedded. Besides the two auxiliary tasks from self-supervised learning, we also induce contrastive learning into our model to obtain the stronger feature representation. Specifically, for contrastive learning, the negative pair is defined as the two video frames/segments from the different domains, while the opposite is the positive pair. The model constructed by contrastive learning ensures that the videos of the same domain are forced to be closer in the same latent space, while the videos from different domains are pushed far away. Thus, contrastive learning enhances the prediction ability of the two auxiliary tasks without any annotations. Furthermore, we devise a multi-stage architecture to obtain the final results of action segmentation better. There are two improvements: (a) the predication generation stage has a dual dilated layer to combine larger and smaller receptive fields; (b) it is followed by embedding efficient channel attention to increase the information interaction with channels.
In Fig. 1, we illustrate the CTDA framework with three various modules: (1) self-supervised learning (SSL) module, (2) feature extraction module, and (3) action prediction module. To be more specific, the data that has labels is the source domain in the SSL module, while the other data is the target domain. Then, domain adaptation and contrastive learning are performed together. In the feature extraction module, one prediction generation stage and several refinement stages are included. In the action prediction module, it outputs the predicted action for each frame of a long video. So, we design a diverse combination of the latest domain adaptation and contrastive learning approaches to reduce the domain discrepancy (i.e., Spatio-temporal variations) and find that contrastive learning combined with domain adaptation can improve the video action segmentation effect.
Therefore, this paper has made three major contributions:
(1) We are the first to propose a novel contrastive temporal domain adaptation (CTDA) approach to video action segmentation. Different from the closely-related method SSTDA [3], we apply the latest contrastive learning approaches to two auxiliary tasks within the domain adaptation framework.
(2) The proposed CTDA brings boost to the predication generation stage with a dual dilated layer to combine larger and smaller receptive fields in multi-stage architecture, followed by embedding efficient channel attention to increase the information interaction with channels for action segmentation.
(3) Extensive experimental results illustrate that CTDA not only achieves the best results on two public benchmarks but also achieves comparable performance even with less training data.

Network for proposed Contrastive Temporal Domain Adaptation (CTDA) framework for action segmentation. Two auxiliary tasks (i.e., binary and sequential domain prediction) are performed by domain adaptation and contrastive learning together within the self-supervised learning paradigm. We improve the predication generation stage with a dual dilated layer, followed by embedding efficient channel attention.
2 Related Work
Domain Adaptation. DA is defined as a representative transfer learning approach in that both the source and the target tasks are identical but without the same data distribution. Moreover, the data in the source domain are labeled, whereas the data in the target are not. RTN [20] uses residual structure to learn the difference classifiers. JAN [21] proposes a JMMD to make the joint distribution’s features closer. MADA [25] states that the alignment of semantic information can make the feature space better aligned. Within this work, we investigate various domain adaptation approaches to learn information from unlabeled target videos with the same contrastive learning approaches in the CTDA framework.
Contrastive Learning. The concept of contrastive learning is a new approach to self-supervised learning that has emerged as a result of recent research. SimCLRv2 [4] is the improved version to explore larger ResNet models and increase the non-linear network’s capacity. Momentum Contrast (MoCo) [13] builds a dynamic dictionary, and MoCov2 [5] applies an MLP-based projection head to obtain better representations. SimSiam [6] maximizes the similarity to learn meaningful representations. BYOL [12] proposes two networks to interact and learn from each other without negative pairs. Therefore, we evaluate self-supervised learning with different latest contrastive learning approaches based on the same domain adaptation approaches in the CTDA framework.
Action Segmentation. Long-term dependencies is important to video action segmentation for high-level video understanding. The temporal convolutional network (TCN) [15] is firstly proposed for action segmentation with an encoder-decoder architecture. MS-TCN [7] designs multi-stage TCNs, and MS-TCN++ [19] further introduces a dual dilated layer to decouple the different phases. Very recently, self-supervised learning with domain adaptation (SSTDA) [3] has been introduced for DA problems. This paper combines contrastive temporal domain adaptation in the self-supervised learning to embed the latest contrastive learning approaches in the auxiliary tasks to reduce the Spatio-temporal discrepancy further for action segmentation.
3 Methodology
3.1 Framework Overview
Action segmentation is high-level video understanding, which depends on large amount of labeled videos with high-cost annotation. We redefine the self-supervised learning module for better representation and to distinguish the difference in similar activities. Therefore, we propose a novel Contrastive Temporal Domain Adaptation (CTDA) framework that integrates domain adaptation and contrastive learning together for both of the auxiliary tasks.
In Fig. 2, we show the proposed CTDA framework in detail. We select SSTDA [3] as the backbone, because it integrates domain adaptation within MS-TCN for the first time and achieves better performance. Furthermore, we improve the predication generation stage with a dual dilated layer to combine larger and smaller receptive fields more effectively, followed by embedding efficient channel attention, which can not only avoid the reduction of feature dimension, but also increase the information interaction with channels. Based on the above improvements, the CTDA has obtained better metrics and achieved relatively comparable results with fewer training videos.
3.2 Self-supervised Learning Module
This paper further combines contrastive learning with SSTDA [3] to enhance the SSL module, then embed the latest contrastive learning approaches in binary and sequential domain predictions. Therefore, domain adaptation and contrastive learning are performed together in both auxiliary tasks’ predictions.
In self-supervised learning modules, we split videos into two approaches and carried out the pipeline of two branches simultaneously. The first approach is video frame, and the first auxiliary task in self-supervised learning is binary prediction to determine whether they are source or target. The second is the video segment, and the second auxiliary task for sequential domain prediction is to predict the correct combination of the segments. To sum up, we have embedded contrastive learning in the corresponding positions of the two auxiliary tasks of domain adaptation (local and global) while predicting the two auxiliary tasks jointly completed by domain adaptation approaches and contrastive learning approaches. Therefore, contrastive learning in the CTDA framework improves the performance of the SSL module.
3.3 Feature Extraction Module
We refer to SSTDA-based code [3] and improve the prediction generation stage with a dual dilated layer, followed by efficient channel attention, which can not only avoid the reduction of feature dimension but also increase the information interaction with channels.
Prediction Generation Stage. We follow the architecture of SSTDA [3], and make two improvements: (1) combination with a designed-well dual dilated layer to obtain the various reception views and (2) embedding efficient channel attention (ECA) for feature interaction between channels. The prediction generation stage is described in Fig. 3(a). Specifically, in Net1, there is only one convolution with dilated factor \(2^l\) in SSTDA, and we introduce a dual dilated layer (DDL) for optimization. The dilated factor is set as \(2^l\) and \(2^{L-l}\) at each layer l, and L represents the layer’s quantity. To increase the information interaction between channels, we embed efficient channel attention shown in Fig. 4.
Refinement Stage. The latest research shows that a DDL combines different larger and smaller reception views only in the prediction generation stage [19] to achieve better performance. In Fig. 3(b), we follow the design of SSTDA [3] without changes in the refinement stage, and it is a simplified version of the prediction generation stage, where DDL is replaced by a dilated factor \(2^l\), and other processes remain unchanged.

An illustration of prediction generation stage and refinement stages.

An illustration of efficient channel attention (ECA).
3.4 Implementation Details
In this paper, we refer to SSTDA-based code [3] in PyTorch [23] for improvement. Following the official implementation, we use the same four-stage architecture. Please see Fig. 2 for more details.
4 Experiments
4.1 Datasets and Evaluation Metrics
Datasets. This paper selects two challenging action segmentation datasets: GTEA [8] and 50Salads [30]. The standard splits of training sets and validation sets with different people to perform the same actions may trigger a series of domain shift-related problems. In this case, we followed the strategy first proposed in [3].
The GTEA dataset covers seven different kinds of behaviors that occur daily in a kitchen (e.g., making cheese sandwiches and tea) with four different human subjects from a dynamic view so that it contains 28 egocentric videos from the camera with the actor’s head in total. The 50Salads dataset consists of 50 videos that fall into 17 different activity categories related to the preparation of salads in the kitchen (e.g., cut tomato), which are performed by 25 human subjects to prepare two different salads.
In this paper, we follow the previous works to pre-extract I3D feature sequences for the videos of both datasets, which are trained on kinetics dataset [1] followed by taking the features to the input of our framework.
Evaluation Metrics. To better evaluate the performance, we select the same three widely evaluation metrics mentioned in [15], there are frame-wise Accuracy, segmental edit distance (Edit) and segmental F1 score, respectively.
4.2 Experimental Results
Comparison to State-of-the-Art. This paper evaluates CTDA framework on challenging action segmentation datasets: GTEA [8] and 50Salads [30]. As seen in Table 1, we summarize the metrics in detail, and the CTDA framework achieves the highest performance on the two datasets.
For 50salads, a relatively small dataset, the CTDA framework achieves significant improvement. Compared with SSTDA [3], the F1 score {10,25,50} is 85.5, 84.2, 76.9, respectively. Overall, it increases by 3 points on average. As for the other two metrics, edit distance and frame-wise accuracy, the former is relatively more important, which can be penalized for over-segmentation errors. The value of edit distance also obviously improves the 3 points. Besides, the frame-wise accuracy raises from 83.2 to 84.5. Therefore, we can clearly see when using the full training data, our CTDA framework improves on average by 3 points in F1 scores and segmental edit distance in SSTDA, 5 points in MS-TCN++, and 10 points in MS-TCN, respectively.
For another small dataset, GTEA, our CTDA framework also achieves a slight improvement, but not as much as 50Salads, probably mainly because of the relatively simple dataset and activities. From Table 1, we can see CTDA framework has achieved a slight increase in F1 score and segmental edit distance compared to other approaches with similar frame-wise accuracy, which indicates that we have further reduced the impact of over-segmentation to better video action segmentation.
Performance with Less Training Data. Based on the performance in Table 1, our CTDA framework achieves the improvement with unlabeled target videos, followed by training with fewer labeled frames in this section. The process follows the SSTDA setup [3]. In Table 2, we record in detail to train with fewer instances of labeled training data, which related to the different percentages of labeled training data (m%) with four different latest contrastive learning approaches (MoCov2 [5], SimCLRv2 [4], SimSiam [6] and BYOL [12]). We train with less labeled training data from 95% to 65% at a rate of 10% each time for 50Salads, and the lower limit is set at 60%.
To facilitate the analysis, we choose BYOL embedded in the CTDA framework. Compared to the SSTDA [3] and MS-TCN [7], we only use 60% of the data for training, and the model can still achieve better performance that F1@{10,25,50} is 78.8, 76.4, 67.5, segmental edit distance is 70.5, and Frame-wise accuracy is 81.3, which exceeds the SSTDA performance with 65% training data and the best results of MS-TCN with 100% training data. When we use 75% of the data for training, our performance can exceed MS-TCN++ with 100% training data in all metrics. When we use 85% training data, it can also exceed SSTDA with 100% training data. In general, CTDA framework only needs 85% training data to obtain the best performance on 50Salads. Table 2 records other latest contrastive learning approaches embedded in the CDTA framework.

Qualitative effects on various temporal action segmentation approaches with color-coding the obtained action segments for the best view. (a) On the activity Make salad by Subject 04 from the 50Salads dataset. (b) On the activity Make coffee from the GTEA dataset.
4.3 Ablation Study
Different Contrastive Learning Approaches. We conduct a extensive experiments on 4 contrastive learning approaches (MoCov2 [5], SimCLRv2 [4], SimSiam [6] and BYOL [12]), and embed them followed by the Binary Classifier to predict a frame to source or target (local mode), and embed them followed by the segment classifier to predict a segment sequence (global mode), and combination both of them (both mode). In Table 3, we record the comparison of different contrastive learning on 50Salads. We can demonstrate that (1) when the local contrastive learning mode is used, the average performance is higher than that of the non-contrastive learning mode, and (2) the average performance with both contrastive learning modes is higher than that of the local contrastive learning mode. (3) As a result, the two auxiliary tasks are performed by domain adaptation and contrastive learning together, which can maximize the best effect of self-supervised learning, not for one auxiliary task to binary domain prediction.
Different Domain Adaptation Approaches. We perform an ablation study on different domain adaption approaches to demonstrate which can learn information from unlabeled target videos better with the same contrastive learning approach in our CTDA framework. We take the same contrastive learning approach BYOL [12] as an example. Please see Table 4 for more detail. We can see that the CTDA framework combines with SSTDA, whose performance is significantly higher than other domain adaptation approaches. The results demonstrate that SSTDA performs better than other DA strategies with contrastive learning because it aligns temporal dynamics better within our CTDA framework.
Different Embedded Components of the Framework. We further conducted two experiments on various embedded components of the CTDA framework to demonstrate the effectiveness of the dual dilated layer (DDL) and efficient channel attention (ECA). Table 5 shows the impact of DDL on the CTDA framework, and Table 6 shows the effects of ECA. Comparing Table 5 and Table 6, we can conclude that both DDL and ECA have had a positive effect on improving outcomes, and DDL is even more critical.
4.4 Quantitative Effects
We represent the qualitative segmentation effect for the best view of two datasets in Fig. 5. (a) is the activity Make salad by Subject 04 on 50Salads, and (b) is the activity Make coffee on GTEA. We choose Fig. 5(b) for further detailed analysis. It is the activity Make coffee, including a series of actions (e.g. take, open, scoop, pour, close, put, stir and background). Each action segmentation approach in Fig. 5 correctly predicts action categories and duration segments, and improves the sequence accuracy. For example, at the beginning of Fig. 5(b), the CTDA framework predicts the action time boundary of scoop and pour relatively more accurately and then predicts the time boundary of take and pour better, which adapts to the target domain more effectively. Therefore, the CTDA framework reduces the prediction error relatively and achieves better action segmentation performance.
5 Conclusions
This paper proposes a novel self-supervised Contrastive Temporal Domain Adaptation (CTDA) framework for efficiently utilizing unlabeled target videos with limited training videos. We are the first to combine contrastive learning and temporal domain adaptation for action segmentation. Furthermore, a multi-stage architecture is also devised to obtain the final results of action segmentation. Extensive experiments on two action segmentation benchmarks demonstrate that CTDA achieves the best results. In our upcoming work, we will further enhance the prediction of action segments to overcome the challenge that estimating time boundaries excessively deviates from the ground truth by embedding an additional module to refine the segment time boundary information.
References
Carreira, J., Zisserman, A.: Quo vadis, action recognition? A new model and the kinetics dataset. In: CVPR, pp. 6299–6308 (2017)
Chen, M.H., Li, B., Bao, Y., AlRegib, G.: Action segmentation with mixed temporal domain adaptation. In: WACV, pp. 605–614 (2020)
Chen, M.H., Li, B., Bao, Y., AlRegib, G., Kira, Z.: Action segmentation with joint self-supervised temporal domain adaptation. In: CVPR, pp. 9454–9463 (2020)
Chen, T., Kornblith, S., Swersky, K., et al.: Big self-supervised models are strong semi-supervised learners. In: NIPS, vol. 33, pp. 22276–22288 (2020)
Chen, X., Fan, H., Girshick, R., et al.: Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297 (2020)
Chen, X., He, K.: Exploring simple Siamese representation learning. In: CVPR, pp. 15750–15758 (2021)
Farha, Y.A., Gall, J.: MS-TCN: multi-stage temporal convolutional network for action segmentation. In: CVPR, pp. 3575–3584 (2019)
Fathi, A., Ren, X., Rehg, J.M.: Learning to recognize objects in egocentric activities. In: CVPR, pp. 3281–3288. IEEE (2011)
Gammulle, H., Denman, S., Sridharan, S., Fookes, C.: Fine-grained action segmentation using the semi-supervised action GAN. Pattern Recogn. 98, 107039 (2020)
Ganin, Y., et al.: Domain-adversarial training of neural networks. J. Mach. Learn. Res. 17(1), 2030–2096 (2016)
Gao, S.H., Han, Q., Li, Z.Y., Peng, P., Wang, L., Cheng, M.M.: Global2Local: efficient structure search for video action segmentation. In: CVPR, pp. 16805–16814 (2021)
Grill, J.B., et al.: Bootstrap your own latent-a new approach to self-supervised learning. NIPS 33, 21271–21284 (2020)
He, K., Fan, H., Wu, Y., et al.: Momentum contrast for unsupervised visual representation learning. In: CVPR, pp. 9726–9735 (2020). https://doi.org/10.1109/CVPR42600.2020.00975
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR, pp. 770–778 (2016)
Lea, C., Flynn, M.D., Vidal, R., Reiter, A., Hager, G.D.: Temporal convolutional networks for action segmentation and detection. In: CVPR, pp. 156–165 (2017)
Lea, C., Reiter, A., Vidal, R., Hager, G.D.: Segmental spatiotemporal CNNs for fine-grained action segmentation. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9907, pp. 36–52. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_3
Lee, C.Y., Batra, T., Baig, M.H., Ulbricht, D.: Sliced Wasserstein discrepancy for unsupervised domain adaptation. In: CVPR, pp. 10285–10295 (2019)
Lei, P., Todorovic, S.: Temporal deformable residual networks for action segmentation in videos. In: CVPR, pp. 6742–6751 (2018)
Li, S.J., AbuFarha, Y., Liu, Y., Cheng, M.M., Gall, J.: MS-TCN++: multi-stage temporal convolutional network for action segmentation. TPAMI (2020)
Long, M., Wang, J., Jordan, M.I.: Unsupervised domain adaptation with residual transfer networks. In: NIPS (2016)
Long, M., Zhu, H., Wang, J., Jordan, M.I.: Deep transfer learning with joint adaptation networks. In: ICML, pp. 2208–2217. PMLR (2017)
Mac, K.N.C., Joshi, D., Yeh, R.A., Xiong, J., Feris, R.S., Do, M.N.: Learning motion in feature space: locally-consistent deformable convolution networks for fine-grained action detection. In: ICCV, pp. 6282–6291 (2019)
Paszke, A., et al.: PyTorch: an imperative style, high-performance deep learning library. NIPS 32, 8026–8037 (2019)
Patel, V.M., Gopalan, R., Li, R., Chellappa, R.: Visual domain adaptation: a survey of recent advances. IEEE Signal Process. Mag. 32(3), 53–69 (2015)
Pei, Z., Cao, Z., Long, M., Wang, J.: Multi-adversarial domain adaptation. In: AAAI (2018)
Richard, A., Gall, J.: Temporal action detection using a statistical language model. In: CVPR, pp. 3131–3140 (2016)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Saito, K., Watanabe, K., Ushiku, Y., Harada, T.: Maximum classifier discrepancy for unsupervised domain adaptation. In: CVPR, pp. 3723–3732 (2018)
Singh, B., Marks, T.K., Jones, M., Tuzel, O., Shao, M.: A multi-stream bi-directional recurrent neural network for fine-grained action detection. In: CVPR, pp. 1961–1970 (2016)
Stein, S., McKenna, S.J.: Combining embedded accelerometers with computer vision for recognizing food preparation activities. In: UbiComp, pp. 729–738 (2013)
Wang, D., Hu, D., Li, X., Dou, D.: Temporal relational modeling with self-supervision for action segmentation (2021)
Wang, Z., Gao, Z., Wang, L., Li, Z., Wu, G.: Boundary-aware cascade networks for temporal action segmentation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12370, pp. 34–51. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58595-2_3
Xie, S., Zheng, Z., Chen, L., Chen, C.: Learning semantic representations for unsupervised domain adaptation. In: ICML, pp. 5423–5432. PMLR (2018)
Xu, D., Xiao, J., Zhao, Z., Shao, J., Xie, D., Zhuang, Y.: Self-supervised spatiotemporal learning via video clip order prediction. In: CVPR, pp. 10334–10343 (2019)
Acknowledgements
This work was supported in part by National Natural Science Foundation of China (61976220 and 61832017), Beijing Outstanding Young Scientist Program (BJJWZYJH012019100020098), and the Research Seed Funds of School of Interdisciplinary Studies, Renmin University of China.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Han, H., Lu, Z., Wen, JR. (2023). CTDA: Contrastive Temporal Domain Adaptation for Action Segmentation. In: Dang-Nguyen, DT., et al. MultiMedia Modeling. MMM 2023. Lecture Notes in Computer Science, vol 13834. Springer, Cham. https://doi.org/10.1007/978-3-031-27818-1_46
Download citation
DOI: https://doi.org/10.1007/978-3-031-27818-1_46
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-27817-4
Online ISBN: 978-3-031-27818-1
eBook Packages: Computer ScienceComputer Science (R0)