
Abstract
The inevitable environmental and technical limitations of image capturing has as a consequence that many images are frequently taken in inadequate and unbalanced lighting conditions. Low-light image enhancement has been very popular for improving the visual quality of image representations, while low-light images often require advanced techniques to improve the perception of information for a human viewer. One of the main objectives in increasing the lighting conditions is to retain patterns, texture, and style with minimal deviations from the considered image. To this direction, we propose a low-light image enhancement method with Haar wavelet-based pooling to preserve texture regions and increase their quality. The presented framework is based on the U-Net architecture to retain spatial information, with a multi-layer feature aggregation (MFA) method. The method obtains the details from the low-level layers in the stylization processing. The encoder is based on dense blocks, while the decoder is the reverse of the encoder, and extracts features that reconstruct the image. Experimental results show that the combination of the U-Net architecture with dense blocks and the wavelet-based pooling mechanism comprises an efficient approach in low-light image enhancement applications. Qualitative and quantitative evaluation demonstrates that the proposed framework reaches state-of-the-art accuracy but with less resources than LeGAN.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
In the digital era, a plethora of photos are acquired daily, while only a fraction is captured in optimal lighting conditions. Image acquisition in low-lighting conditions is challenging to be improved when low brightness, low contrast, a narrow gray range, color distortion and severe noise exists, and no other sensor is involved as for example multiple cameras of different specifications. Image enhancement has significantly been improved over the last years with the popularity of neural network architectures that have outperformed traditional image enhancement techniques. The main challenge in low-light image enhancement is to maximize the information involved from the input image on the available patterns and extract the colour information that is hidden behind the low values of luminance. This challenge has been tackled using the traditional approaches of histogram equalization [17] and Retinex theory [21] while neural network approaches either involve Generative Adversarial Networks or Convolutional Neural Networks architectures [14].
Although a wide range of solutions have already been applied in image enhancement, none of them has yet considered photorealistic style transfer. Targeting in improving the quality of under-exposed images, photorealistic style transfer requires as input, one under-exposed image that has been captured in low-lighting conditions, along with an image of normal lighting conditions. The proposed approach is trained using a collection of style images that all have optimal lighting conditions, which are then transferred to the given under-exposed images through an enhancer module.
However, texture, brightness, contrast and color-like information need to be effectively reconstructed in the generated enhanced image, but it has been reported that Haar wavelet-based pooling is superior to max-pooling for generating an image with minimal information loss and noise amplification [37]. Wavelet unpooling recovers the original signal by performing a component-wise transposed-convolution, while max-pooling does not have its exact inverse. Max-pooling that the encoder-decoder structured networks used in the WCT [22] and PhotoWCT [23] are not able to restore the signal and they need to perform a series of post-processing steps for the remaining artifacts. The multi-layer feature aggregation mechanism is adopted as it is presented in [25], but with a Haar wavelet-based transformation to support the Adaptive Instance Normalization for image enhancement in low-lighting conditions.
In this work, we propose an novel framework for image enhancement on low-light conditions. A modified U-Net based architecture is designed that involves dense blocks, which contain dense, convolutional, and wavelet pooling layers to better preserve texture regions in image enhancement. The framework requires as input low-light and normal-light images, where encoding is using low frequency (LL) components and unpooling is performed with high frequency components (LH, HL, HH), which leads to better image enhancement. Our method achieves state-of-the-art results but with less computational resources, both in training and testing phases.
The remainder of the paper is structured as follows. Section 2 provides an overview of state of the art in image enhancement while Sect. 3 presents the proposed framework analysing and providing details for any of its aspect. Section 4 provides experiments that demonstrate the effectiveness of the proposed approach, and finally Sect. 5 concludes this work.
2 Related Work
Image enhancement has been initially relied on the statistical method of histogram equalization [4]. Histogram equalization enhances the images through the expansion of their dynamic range either at a global [12] or a local level [17]. In particular, the method [19], which is based on histogram equalization, enhances the image contrast by expanding the pixel intensity distribution range. Other works propose the use of double histogram equalization for image enhancement [2]. The statistical properties of adjacent pixels and large gray-level differences have been utilized by Lee et al. [17] to adjust brightness at local levels. Histogram equalization methods produces visually accepted images with less resources but with many distortion as local pixel correlations are not considered.
Since this type of methods lack physical explanation, several image enhancement methods have been proposed based on Retinex theory. Retinex based methods for image enhancement have estimated illumination and reflectance with more details through the designed weighted variation model [6]. In [10] the authors have estimated a coarse illumination map, by computing the maximum intensity of each RGB pixel channel, and then they refine the coarse illumination map using a structure prior. Another Retinex model has been proposed Li et al. [21] that takes into consideration the noise in the estimation of the illumination map through solving the optimization problem of generating a high-contrast image with proper tonal rendition and luminance in every region. Furthermore, an adaptive multi-scale Retinex method for image enhancement has been proposed in [16] where each single-scale Retinex output image is weighted and it is adaptively estimated, based on both the input content image to generate an enhanced image with a natural impression and appropriate tone reproduction in each area of the image. Additional works have combined the camera response with the traditional Retinex model to obtain an image enhancement framework [27]. Contrary to the methods that change the distribution of image histogram or that rely on potentially inaccurate physical models, Retinex theory has been revisited in the work of [36]. The authors proposed Retinex-Net, that uses a neural network to decompose the input images into reflectance and illumination, and in an additional layer an encoder-decoder network is used to adjust the illumination. Contrary to the combination of Retinex based methods with neural networks for image enhancement, these methods may generate blurry artifacts that reduce the quality of the generated image.
In the deep learning era, several approaches have been introduced for image enhancement. In [24], the authors apply the LLNet on the low-light image enhancement problem, proposing the stacked sparse denoising of a self-encoder, based on the training of synthetic data to enhance and denoise the low-light noisy input image. A flow-based low-light enhancement method has been proposed in [34] to learn the local pixel correlations and the global image properties by determining the correct conditional distribution of the enhanced images. In [29] the authors have proposed MSRNet, that is able to learn the end-to-end mapping from low-light images directly to the normal light images with an optimization problem. In [8] the authors introduce a neural network architecture that performs image enhancement with two layers; a data-driven layer that enables slicing into the bilateral grid, and a multiplicative operation for affine transformation to compute a bilateral grid and by predicting local affine color transformations. In addition, the work of [13] proposes the use of a translation function to learn with a residual convolutional neural network training, aiming to improve both color rendition and image sharpness. The neural network includes a composite perceptual error function that combines content, color and texture losses. A convolutional neural network has also been proposed in [32], where the authors introduce an illumination layer in their end-to-end neural network for under-exposed image enhancement, with the estimation of an image-to-illumination mapping for modeling multiple lighting conditions. The work of [20] has proposed a trainable CNN for weak illumination image enhancement, called LightenNet, which learns to predict the relationship between illuminated image and the corresponding illumination map. A feature spatial pyramid model has been proposed in [30] with a low-light enhancement network, in which the image is decomposed into a reflection and an illumination image and then are fused to obtain the enhanced image. A GLobal illumination-Aware and Detail-preserving Network (GLADNet) has been proposed in [33]. The architecture of the proposed network is split into two stages. For the global illumination prediction, the image is first downsampled to a fixed size and passes through an encoder-decoder network. The second step is a reconstruction stage, which helps to recover the detail that has been lost in the rescaling procedure. Motivated by the good performance of neural networks, but at a higher computational cost, generative adversarial networks combine two neural networks and have also been involved in image enhancement.
The flourishing of GANs has led to several image enhancement solutions aiming to eliminate paired data for training. In [5] the authors introduce EnhanceGAN, which is an adversarial learning model for image enhancement, where they highlight the effectiveness of a piecewise color enhancement module that is trained with weak supervision and extend the proposed framework to learning a deep filtering-based aesthetic enhancer. Moreover, the unpaired learning method for image enhancement of [3] is based on the framework of two-way generative adversarial networks, with similar structure to CycleGAN, but with significant modifications, as the augmentation of the U-Net with global features, the improvement of Wasserstein GAN with an adaptive weighting scheme, and an individual batch normalization layer for generators in two-way GANs. In addition, Zero-DCE [9] takes a low-light image as input and produces high-order tonal curves as its output, which are then used for pixel-wise adjustment on the input range of to obtain the enhanced image. Furthermore, in [7] the authors present an unsupervised low-light image enhancement method named Le-GAN, which includes an illumination-aware attention module and an identity invariant loss. In a similar alternative, the work of [18] proposes an unsupervised learning approach for single low-light image enhancement using the bright channel prior (BCP), where the definition of loss function is based on the pseudo ground-truth generated using the bright channel prior. Saturation loss and self-attention map for preserving image details and naturalness are combined to obtain the enhanced result. Finally, EnlightenGAN [14] is an unsupervised GAN-based model on the low-light image enhancement, that utilizes a one-way GAN and a global-local discriminator structure. Although these methods enhance the holistic brightness of the input, they result to the generation of over-exposed regions.
In contrast, the proposed approach adopts a modified U-Net based architecture with dense blocks and wavelet pooling layers. The low frequency (LL) component is involved in encoding while decoding utilizes the high frequency components (LH, HL, HH) of the input image. Consequently, the proposed approach is able to preserve the structure and texture information through this wavelet pooling transformation.
3 Methodology
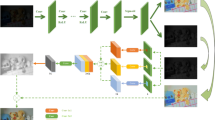
To achieve photorealism, a model is expected to recover the structural information of a given image, while it enhances the image’s luminance effectively. To address this issue, the proposed U-Net-based network is combined with wavelet transformations and Adaptive Instance Normalization (AdaIN), as it is illustrated in Fig. 1. More specifically, the image recovery is addressed by employing wavelet pooling and unpooling, in parallel preserving the information of the content to the transfer network. The frameworks uses as input low-light images along with normal-light images to generate the enhanced images. Afterwards, dense blocks are used to enhance the quality of feature transferring and skip connections in the transferring process. Intending to a natural stylization effect, the enhanced features are inserted into the image reconstruction process, along with the connected features of different levels from the encoding process.
3.1 Network Architecture
Following a U-Net alteration, the proposed network is comprised by the following three sub-components: encoder, enhancer and decoder. The encoder and decoder formulate the symmetric structure of a U-Net, as it has been originally introduced by Ronneberger et al. [28], aiming to preserve the structural integrity of an image. The encoder includes convolutional and pooling layers that also involve a downsampling mechanism, while the decoder has a corresponding upsampling mechanism. The U-Net architecture has been designed with a skip connection between encoder and decoder modules. On top of the existing skip connections, the Photorealistic Style Transfer Network called UMFA [25] includes also multi-layer feature aggregation (MFA) and AdaIN blocks [11], in a module which is called enhancer. The enhancer module and the encoder both include a Haar wavelet-based pooling layer, replacing the traditional max-pooling layer in order to capture smooth surface and texture information. In Fig. 1, the red and blue solid lines represent the features of the normal-light and low-light images, respectively, while the Haar wavelet-based pooling is in the dense blocks of the encoder and the AdaIN block of the enhancer module.

Proposed image enhancement framework based on U-Net architecture and wavepooling layers. (Color figure online)
Encoder: The encoder of the proposed framework is illustrated in the green box of Fig. 1 and it has convolutional layers and downsampling dense blocks. Downsampling dense blocks contain a Haar wavelet-based pooling layer, a dense block and two convolutional layers. A dense block is created by three densely connected convolutional layers. The Haar wavelet transformations of the pooling layer implements downsampling operations to halve the feature size, keeping the dimensions identical to a max pooling layer. The encoder allows to keep multi-scale image information and to process high-resolution images.
Decoder: The decoder, which is illustrated in the yellow box of Fig. 1, mirrors the encoder structure, with four upsampling blocks to formulate a U-Net structure along with the aforementioned encoder. Each block consists of an upsampling layer, three convolutional layers and a concatenation operation that receives the corresponding encoder feature coming from the enhancer module.
Enhancer: In the purple box of Fig. 1 the structure of the enhancer module is depicted. This module passes multi-scale features from the encoder to the decoder. Feature aggregation allows the network to incorporate spatial information from various scales and keep the detailed information of the input image. Features are inserted from the previous layer to the next one for all pairs of layers of the encoder, then they are transformed using AdaIN to enhance the input image. The pooling layer is again based on Haar wavelet transformation, briefly described as follows.
Haar wavelet pooling has four kernels, \(\{LL^T, LH^T, HL^T, HH^T\}\), where the low (L) and high (H) pass filters are:
The output of each kernel is denoted as LL, LH, HL, and HH, respectively, representing each one of the four channels that are generated from the Haar wavelet-based pooling. The low-pass filter LL contains smooth surface and texture, while the high-pass filters (LH, HL, HH) extract edge-like information of different directions (i.e. vertical, horizontal, and diagonal). Every max-pooling of UMFA method [25] is replaced with the wavelet pooling. Motivated by [37], the max-pooling layers are replaced with wavelet pooling, the low frequency component (LL) is passed to the next encoding layer. The high frequency components (LH, HL, HH) are skipped to the decoder directly. Using the wavelet pooling the original signal can be exactly reconstructed by wavelet unpooling operation. Wavelet unpooling fully recovers the original signal by performing a component-wise transposed-convolution, followed by a summation. Haar wavelet, being one of the simplest wavelet transformations, splits the original signal into channels that capture different components.
3.2 Loss Functions
Following the approach of [25], the total loss function \(L_{total}\) is computed as a pre-defined weighted sum of enhancement loss, content loss and structured similarity (SSIM) loss functions, respectively:
where \(L_{cont}\) and \(L_{SSIM}\) are computed between the input low-light content image and the enhanced output image. \(L_{enh}\) is the enhancement loss between the input normal-light image and the enhanced output image. \(L_{cont}\) and \(L_{enh}\) are based on the perceptual loss [15]. The parameters \(\alpha , \beta , \gamma \) represents the weights of the above three losses. For the content loss, the \(relu_{2 \_ 2}\) is chosen as the feature layer, different from the perceptual loss and the Gram matrices of the features are used for the normal-light image features. The enhancement loss \(L_{enh}\) is the sum of all outputs from the four ReLU layers of the VGG-16 network and the SSIM loss is calculated as:
where SSIM(C, E) represents the output of structural similarity (SSIM) [35] measure between the input low-light content image C and enhanced output image E. SSIM is a perception-based model that incorporates important perceptual information, including luminance and contrast terms.
4 Experimental Results
The following section provides insights on the considered datasets, the configurations adopted for the conducted experiments as well as the qualitative and quantitative validation of the corresponding results in comparison with other relevant works.

Qualitative comparison of the proposed framework with state-of-the-art.
4.1 Datasets
Two benchmark datasets namely LOL [36] and SYN [36] respectively were utilised to accomplish an effective performance comparison on the low-light and enhanced images. LOL dataset has 500 image pairs, where 485 pairs of them are randomly selected for training and 15 pairs for testing. SYN dataset has 1,000 image pairs, and where 950 pairs of them are randomly selected for training and 50 pairs for testing.
4.2 Training Process
The training process was initiated by feeding the model with the normal-light and low-light images. For both datasets, the weights for total loss was set as \(\alpha = 0.5 \), \(\beta = \gamma = (1-\alpha )*0.5 \) following the default values of [25]. Similarly, the number of epochs is set to 150 for the LOL dataset and 100 for the SYN dataset. The batch size is set 4 for both datasets. All input images are 256\(\times \)256 pixels. Adam optimizer is used for training and the optimal learning rate is 0.0001.

Qualitative comparison of the proposed framework with state-of-the-art on SYN dataset.
4.3 Results
The baseline methods of the presented comparison are the histogram equalization methods of [1, 17], the Retinex theory based methods of [6, 10, 16, 21, 27, 36], the neural network approaches of [20, 26, 30, 33] and the GANs based approaches of [7, 9, 14] due to their relevance to low-light image enhancement problem and the fact that they cover all different approaches based on histogram equalization, Retinex-based methods, neural networks and GANs. The proposed approach denoted in Table 1 and Fig. 2 as “Ours”.

Qualitative comparison of the proposed framework with state-of-the-art on LOL dataset.
The visual quality of the proposed framework is compared with other methods and the results are shown in Fig. 2. It is observed that the GLADNet [33], Retinex-Net [36], EnlightenGAN [14] and Zero-DCE [9] are not able to fully reconstruct the hidden information of the low-light input image on the left. These methods increase the brightness of the image, but the color saturation of the results is lower compared to the proposed approach. Moreover, they suffer from noise and color bias. In Figs. 3 and 4 we present more qualitative results on SYN and LOL dataset respectively. It is observed that there are some bright regions of the results generated by the compared methods, especially on LOL dataset, which are over- exposed in the enhanced outputs. In contrast, the proposed approach performs well in all datasets with nearly no artifacts and generates quite realistic normal-light images. In addition to the two given datasets, the proposed framework is also tested in a qualitative manner in the no-paired ExDARK [31] dataset. For this purpose as normal-light image is used for the inference mode a random selected cat image from the web and as it is illustrated in Fig. 2 the outputs is realistic and enhanced.
Moreover, a quantitative evaluation is provided in Table 1, where the proposed approach is compared with the aforementioned methods for LOL and SYN datasets, as they were reported in [7, 30]. The Peak Signal-to-Noise Ratio (PSNR) scores correspond to the average value of the complete test set of enhanced images in LOL and SYN datasets. We observe that the highest PSNR values for each image test correspond to the output of the proposed framework and the method of Le-GAN [7]. PSNR values show that the generated images from the proposed approach and Le-GAN method, obtain higher proximity to the input normal-light images than the imaged generated by all other methods. Compared to Le-GAN, the proposed approach is significantly more efficient, without the need of the additional computational resources that are reported in [7] and this is depicted in training and testing times (Table 1). More specifically, the training time of Le-GAN method is 25.6 h, 2.5 times higher the training time of the proposed approach and they use 3 NVIDIA 3090ti GPUs. The training time of our method is 10.7 h on the NVIDIA GeForce RTX 2060 SUPER. Moreover, Le-GANs execution time on a 600 \(\times \) 400 image is about 8.43 ms, 1.5 times up to the execution time of the proposed approach. In Le-GAN, the method requires 3*24 GB (standard Memory of 3 NVIDIA 3090ti) contrary to 8 GB of ours As far as SSIM value is concerned, the outputs of the presented framework on LOL dataset is on top-2 higher scores and on SYN dataset the outputs have comparable results with other state-of-the-art methods.
5 Conclusions
In this work, a photorealistic style transfer approach is adapted and modified to low-light image enhancement. The proposed method is based on a U-net architecture using dense blocks and three main modules, namely encoder, enhancer, and decoder. The encoder and enhancer include a Haar wavelet based pooling layer for downsampling that has shown superiority compared to max pooling in transferring brightness, contrast and color-like information from one input image to a generated. Experiments in two benchmark datasets compared the proposed method with recent works in image enhancement, showing that the proposed approach on two benchmark low-light datasets achieves state-of-the-art with at less computational resources, both in training and testing processes. Future modifications will focus on evaluating further the impact of the wavelet incorporation and their deployment in other levels of the architecture.
References
Abdullah-Al-Wadud, M., Kabir, M.H., Dewan, M.A.A., Chae, O.: A dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53(2), 593–600 (2007)
Chen, S.D., Ramli, A.R.: Minimum mean brightness error bi-histogram equalization in contrast enhancement. IEEE Trans. Consum. Electron. 49(4), 1310–1319 (2003)
Chen, Y.S., Wang, Y.C., Kao, M.H., Chuang, Y.Y.: Deep photo enhancer: unpaired learning for image enhancement from photographs with GANs. In: Proceedings of the IEEE Conference on CVPR, pp. 6306–6314 (2018)
Coltuc, D., Bolon, P., Chassery, J.M.: Exact histogram specification. IEEE Trans. Image Process. 15(5), 1143–1152 (2006)
Deng, Y., Loy, C.C., Tang, X.: Aesthetic-driven image enhancement by adversarial learning. In: Proceedings of the 26th ACM international conference on Multimedia, pp. 870–878 (2018)
Fu, X., Zeng, D., Huang, Y., Zhang, X.P., Ding, X.: A weighted variational model for simultaneous reflectance and illumination estimation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2782–2790 (2016)
Fu, Y., Hong, Y., Chen, L., You, S.: LE-GAN: unsupervised low-light image enhancement network using attention module and identity invariant loss. Knowl.-Based Syst. 240, 108010 (2022)
Gharbi, M., Chen, J., Barron, J.T., Hasinoff, S.W., Durand, F.: Deep bilateral learning for real-time image enhancement. ACM Trans. Graphics (TOG) 36(4), 1–12 (2017)
Guo, C., et al.: Zero-reference deep curve estimation for low-light image enhancement. In: Proceedings of the IEEE/CVF Conference on CVPR, pp. 1780–1789 (2020)
Guo, X., Li, Y., Ling, H.: Lime: low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 26(2), 982–993 (2016)
Huang, X., Belongie, S.: Arbitrary style transfer in real-time with adaptive instance normalization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1501–1510 (2017)
Ibrahim, H., Kong, N.S.P.: Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 53(4), 1752–1758 (2007)
Ignatov, A., Kobyshev, N., Timofte, R., Vanhoey, K., Van Gool, L.: DSLR-quality photos on mobile devices with deep convolutional networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3277–3285 (2017)
Jiang, Y., et al.: EnlightenGAN: deep light enhancement without paired supervision. IEEE Trans. Image Process. 30, 2340–2349 (2021)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 694–711. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_43
Lee, C.H., Shih, J.L., Lien, C.C., Han, C.C.: Adaptive multiscale retinex for image contrast enhancement. In: 2013 International Conference on Signal-Image Technology & Internet-Based Systems, pp. 43–50. IEEE (2013)
Lee, C., Lee, C., Kim, C.S.: Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 22(12), 5372–5384 (2013)
Lee, H., Sohn, K., Min, D.: Unsupervised low-light image enhancement using bright channel prior. IEEE Signal Process. Lett. 27, 251–255 (2020)
Lee, J., Son, H., Lee, G., Lee, J., Cho, S., Lee, S.: Deep color transfer using histogram analogy. Visual Comput. 36(10), 2129–2143 (2020)
Li, C., Guo, J., Porikli, F., Pang, Y.: LightenNet: a convolutional neural network for weakly illuminated image enhancement. Pattern Recogn. Lett. 104, 15–22 (2018)
Li, M., Liu, J., Yang, W., Sun, X., Guo, Z.: Structure-revealing low-light image enhancement via robust retinex model. IEEE Trans. Image Process. 27(6), 2828–2841 (2018)
Li, Y., Fang, C., Yang, J., Wang, Z., Lu, X., Yang, M.H.: Universal style transfer via feature transforms. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Li, Y., Liu, M.-Y., Li, X., Yang, M.-H., Kautz, J.: A closed-form solution to photorealistic image stylization. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11207, pp. 468–483. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01219-9_28
Lore, K.G., Akintayo, A., Sarkar, S.: LLNET: a deep autoencoder approach to natural low-light image enhancement. Pattern Recogn. 61, 650–662 (2017)
Rao, D., Wu, X.J., Li, H., Kittler, J., Xu, T.: UMFA: a photorealistic style transfer method based on U-Net and multi-layer feature aggregation. J. Electron. Imaging 30(5), 053013 (2021)
Ren, W., et al.: Low-light image enhancement via a deep hybrid network. IEEE Trans. Image Process. 28(9), 4364–4375 (2019)
Ren, Y., Ying, Z., Li, T.H., Li, G.: LECARM: low-light image enhancement using the camera response model. IEEE Trans. Circuits Syst. Video Technol. 29(4), 968–981 (2018)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Shen, L., Yue, Z., Feng, F., Chen, Q., Liu, S., Ma, J.: MSR-Net: low-light image enhancement using deep convolutional network. Preprint arXiv:1711.02488 (2017)
Song, X., Huang, J., Cao, J., Song, D.: Feature spatial pyramid network for low-light image enhancement. Visual Comput. 39, 489–499 (2022)
Tao, L., Zhu, C., Xiang, G., Li, Y., Jia, H., Xie, X.: LLCNN: a convolutional neural network for low-light image enhancement. In: 2017 IEEE Visual Communications and Image Processing (VCIP), pp. 1–4. IEEE (2017)
Wang, R., Zhang, Q., Fu, C.W., Shen, X., Zheng, W.S., Jia, J.: Underexposed photo enhancement using deep illumination estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6849–6857 (2019)
Wang, W., Wei, C., Yang, W., Liu, J.: GladNet: low-light enhancement network with global awareness. In: 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), pp. 751–755. IEEE (2018)
Wang, Y., Wan, R., Yang, W., Li, H., Chau, L.P., Kot, A.: Low-light image enhancement with normalizing flow. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, pp. 2604–2612 (2022)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560 (2018)
Yoo, J., Uh, Y., Chun, S., Kang, B., Ha, J.W.: Photorealistic style transfer via wavelet transforms. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9036–9045 (2019)
Acknowledgment
This work was partially supported by the European Commission under contracts H2020-952133 xR4DRAMA and H2020-958161 ASHVIN.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Batziou, E., Ioannidis, K., Patras, I., Vrochidis, S., Kompatsiaris, I. (2023). Low-Light Image Enhancement Based on U-Net and Haar Wavelet Pooling. In: Dang-Nguyen, DT., et al. MultiMedia Modeling. MMM 2023. Lecture Notes in Computer Science, vol 13834. Springer, Cham. https://doi.org/10.1007/978-3-031-27818-1_42
Download citation
DOI: https://doi.org/10.1007/978-3-031-27818-1_42
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-27817-4
Online ISBN: 978-3-031-27818-1
eBook Packages: Computer ScienceComputer Science (R0)