
Abstract
Tokenization or segmentation is a wide concept that covers simple processes such as separating punctuation from words, or more sophisticated processes such as applying morphological knowledge. Neural Machine Translation (NMT) requires a limited-size vocabulary for computational cost and enough examples to estimate word embeddings. Separating punctuation and splitting tokens into words or subwords has proven to be helpful to reduce vocabulary and increase the number of examples of each word, improving the translation quality. Tokenization is more challenging when dealing with languages with no separator between words. In order to assess the impact of the tokenization in the quality of the final translation on NMT, we experimented on five tokenizers over ten language pairs. We reached the conclusion that the tokenization significantly affects the final translation quality and that the best tokenizer differs for different language pairs.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Segmentation is an essential process that has been extensively studied in literature [3, 4, 13, 14]. It covers simple processes such as separating punctuation from words (tokenization), splitting words in subparts based on their frequency or more sophisticated processes such as applying morphological knowledge. In this work, we use tokenization referring to separating punctuation and splitting tokens into words or subwords.
Tokenizing words has proven to be helpful to reduce vocabulary and increase the number of examples of each word. It is extremely important for languages in which there is no separation between words and, therefore, a single token corresponds to more than one word. The way in which tokens are split can greatly change the meaning of the sentence. For example, the Japanese word  means admonish, and
means admonish, and  means observe. However, together they form the word police
means observe. However, together they form the word police  . Therefore, a correct tokenization can help to improve translation quality.
. Therefore, a correct tokenization can help to improve translation quality.
In this study, we aim to find the impact of tokenization on the quality of the final translation. To do so, we experimented with five tokenizers over ten language pairs. To the best of our knowledge, this is the first work in which an exhaustive comparison between tokenizers has been run for NMT. We include tokenizers based on morphology that could guide the splitting of the words [17].
Some previous works include studying the effect of word-level preprocessing for Arabic on Statistical Machine Translation (SMT). A comparison of several segmenters for Chinese on SMT was done by Zhao et al. [24]. Huck et al. [6] compared morphological segmenters for German in NMT. Finally, Kudo [11] compared their statistical word segmenter with other well-known Japanese morphological segmenters, reaching the conclusions that statistical segmenters worked better than morphological ones.
Our main contributions are as follows:
-
First study of tokenizers for neural machine translation.
-
Experimentation with five different tokenizers over ten language pairs.
The rest of this document is structured as follows: Sect. 2 introduces the neural machine translation system used in this work. After that, in Sect. 3, we present the tokenizers applied for comparison purposes. Then, in Sect. 4, we describe the experimental framework, whose results are presented and discussed in Sect. 5. Section 6 shows some translation examples of the results. Finally, in Sect. 7, conclusions are drawn.
2 Neural Machine Translation
Given a source sentence \(x_1^J=x_1,\dots ,x_J\) of length J, NMT aims to find the best translated sentence \(\hat{y}_1^{\hat{I}}=\hat{y}_1,\dots ,\hat{y}_{\hat{I}}\) of length \(\hat{I}\):
where the conditional translation probability is modelled as:
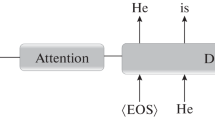
NMT frequently relies on a Recurrent Neural Network (RNN) encoder-decoder framework. The source sentence is projected into a distributed representation at the encoding step. Then, the decoder generates, at the decoding step, its translation word by word [21].
The input of the system is a word sequence in the source language. Each word is projected linearly to a fixed-size real-valued vector through an embedding matrix. Then, these word embeddings are fed into a bidirectional [18] Long Short-Term Memory (LSTM) [5] network. As a result, a sequence of annotations is produced by concatenating the hidden states from the forward and backward layers.
An attention mechanism [1] allows the decoder to focus on parts of the input sequence, computing a weighted mean of annotated sequences. A soft alignment model computes these weights, weighting each annotation with the previous decoding state.
Another LSTM network is used for the decoder. This network is conditioned by the representation computed by the attention model and the last generated word. Finally, a distribution over the target language vocabulary is computed by the deep output layer [16].
The model is trained by applying stochastic gradient descent jointly to maximize the log-likelihood over a bilingual parallel corpus. At decoding time, the model approximates the most likely target sentence with beam-search [21].
3 Tokenizers
In this section, we present the tokenizers we employed in order to assess their impact on the quality of the final translation.
-
SentencePieceFootnote 1: an unsupervised text tokenizer and detokenizer mainly for Neural Network-based text generation systems where the vocabulary size is predetermined prior to the neural model training. It can be used for any language, but its models need to be trained for each of them. To do so, we used the unigram [12] mode and a vocabulary size of 32000 over each corpora’s training partition. Figure 1a shows an example of tokenizing a sentence using SentencePiece.
-
MecabFootnote 2: an open source morphological analysis engine for Japanese, based on conditional random fields. It extracts morphological and syntactical information from sentences and splits tokens into words. Figure 1b shows an example of tokenizing a sentence using Mecab.
-
Stanford Word Segmenter [22]: a Chinese word segmenter based on conditional random fields. Using a set of morphological and character reduplication features, it is able to split Chinese tokens into words. In this work, we use the toolkit’s CTB scheme. Figure 1c shows an example of tokenizing a sentence using Stanford Word Segmenter.
-
OpenNMT tokenizer [8]: the tokenizer included with the OpenNMT toolkit. It normalizes characters (e.g., quotes Unicode variants) and separates punctuation from words. It can be used with any language. Figure 1d shows an example of tokenizing a sentence using OpenNMT tokenizer.
-
Moses tokenizer [10]: the tokenizer included with the Moses toolkit. It separates punctuation from word—preserving special tokens such as URL or dates—and normalizes characters (e.g., quotes Unicode variants). It can be used with any language. Figure 1e shows an example of tokenizing a sentence using Moses tokenizer.

Examples of segmenting sentences with each word segmenter.
4 Experimental Framework
In this section, we describe the corpora, systems and metrics used in order to asses our proposal.
4.1 Corpora
The corpora selected for our experimental session was extracted from translation memories from the translation industry. The files are the result of professional translation tasks demanded by real clients. The general domain is technical (see Table 1 for the specific content of each language pair), which is harder for NMT than other general domains such as news. Unlike in other domains, in technical domains certain words correspond to specific terms and have a different translation to their most frequent one: e.g., rear arm translates into German as hinterer Arm. However, in this domain, it should be translated as hinterer Querlenker. In order to increase language diversity, we selected the following language-pairs: Japanese–English, Russian–English, Chinese–English, German–English, and Arabic–English. Table 2 shows the corpora statistics.
The training dataset is composed of around three million sentences in the German–English language pair and around half a million sentences in the rest of the language pairs. Development and test datasets are composed of two thousand sentences for all the language pairs.
4.2 Systems
NMT systems were trained with OpenNMT [8]. We used LSTM units taking into account the findings in [2]. The size of the LSTM units and word embeddings were set to 1024. We used Adam [7] with a learning rate of 0.0002 [23], a beam size of 6 and a batch size of 20. We reduced the vocabulary using Byte Pair Encoding (BPE) [19], training the models with a joint vocabulary of 32000 BPE units. Finally, the corpora were lowercased and, later, recased using OpenNMT’s tools.
4.3 Evaluation Metrics
We made use of the following well-known metrics to assess our proposal:
-
BiLingual Evaluation Understudy (BLEU) [15]: corresponds to the geometric average of the modified n-gram precision. It is multiplied by a brevity factor to penalize short sentences.
-
Translation Error Rate (TER) [20]: number of word edit operations (insertion, substitution, deletion, and swapping), normalized by the number of words in the final translation.
Confidence intervals (\(p=0.05\)) are computed for all metrics by means of bootstrap resampling [9].
5 Results
In this section, we present the results of the experiments conducted in order to assess the impact of the tokenizer on the translation quality. Table 3 shows the experimental results.
For the Ja–En experiment, the best results were yielded by Moses tokenizer and Mecab. It must be taken into account that in both experiments, the English side of the corpus was segmented with Moses tokenizer, this means that the segmentation of the target side has a greater impact on the translation quality. Overall, there is a quality improvement of around 4 points in terms of BLEU and 3 points in terms of TER with respect to the tokenizer which yielded the second best results.
For En–Ja, the best results were yielded by Mecab, representing a significant improvement (around 12 points in terms of BLEU and 15 points in terms of TER) with respect to the tokenizer which yielded the second best results. Most likely, this is due to Mecab being developed specifically to segment Japanese.
For Ru–En and En–Ru, Moses tokenizer yielded the best results (with improvements of around 2 to 4 points in terms of BLEU and 5 points in terms of TER). It is worth noting that, in both cases, SentencePiece and OpenNMT tokenizer yielded similar results.
The Chinese experiments behaved similarly to the Japanese experiments: Moses tokenizer and Stanford Word Segmenter (the specific Chinese word tokenizer, which included using Moses tokenizer for segmenting the English part of the corpus) achieved the best results when translating to English (yielding an improvement of around 7 points in terms of BLEU and 5 points in terms of TER), and Stanford Word Segmenter achieved the best results when translating to Chinese (yielding an improvement of around 8 points in terms of BLEU and 20 points in terms of TER).
For the German experiments, the best results were yielded by both OpenNMT tokenizer and Moses tokenizer, representing an improvement of around 7 to 9 points in terms of BLEU and 14 to 17 points in terms of TER. It is worth noting how, despite being the largest corpora, SentencePiece—which learns how to segment from the corpora’s training data—yielded the worst results. As a future study, we should evaluate the relation between the size of the corpora and the quality yielded by SentencePiece.
Finally, Arabic behaved similarly to Russian, with Moses tokenizer yielding the best results for both Ar–En and En–Ar (representing improvements of around 2 to 4 points in terms of BLEU and 4 to 6 points in terms of TER). However, SentencePiece performed similar to Moses tokenizer when translating to English. When translating to Arabic, both SentencePiece and OpenNMT tokenizer yielded similar results.
Overall, Moses tokenizer yielded the best results for German, Russian and Arabic experiments. When using specialized morphologically oriented tokenizers, the system using Mecab obtained the best results for Japanese experiments; and Stanford Word Segmenter for Chinese experiments. Additionally, OpenNMT tokenizer and SentencePiece yielded the worst translation quality in all experiments. An explanation for these poor results is that OpenNMT tokenizer is fairly simple: it only separates punctuation symbols from words. However, this is not the case for SentencePiece. We think that using SentencePiece in a bigger training dataset in order to better learn the segmentation could help to improve their results. Nonetheless, as mentioned before, we have to corroborate this in a future work.
6 Qualitative Analysis
We obtained a better performance using Moses tokenizer than OpenNMT tokenizer and SentencePiece. In order to qualitatively analyze this performance, Table 4 shows a couple of examples of translation outputs generated using SentencePiece, OpenNMT tokenizer and Moses tokenizer for segmenting the corpora.
The first example clearly shows a better performance when using Moses tokenizer rather than SentencePiece. The translation output from the system trained using Moses tokenizer for segmenting matches the reference. However, the output translations of the systems using OpenNMT tokenizer and SentencePiece are wrong. Translation segmented with OpenNMT tokenizer contains many repetitions and lacks sense. Additionally, translation segmented by SentencePiece has problems repeating some words in the translation (e.g., motor) and missing some translation words (e.g., the translation of pilot).
The system’s behavior using Moses tokenizer in the second example is similar: its translation matches the reference. By contrast, the systems using SentencePiece and OpenNMT tokenizer translated wrongly. The system using SentencePiece translated all the words from the source but its translation is not grammatically correct. A correct translation could be kalte Zeichnung des Drahtes. Lastly, OpenNMT tokenizer’s performance is the worst in this case: the translation of its system ignored the word wire.
Therefore, we observed that, despite sharing the same data and model architecture, the behavior of the systems’ translation changed as a result of using a different tokenizer.
7 Conclusions
In this study, we tested different tokenizers to evaluate their impact on the quality of the final translation. We experimented using 10 language pairs and arrived to the conclusion that tokenization has a great impact on the translation quality, achieving gains of up to 12 points of BLEU and 15 points of TER.
Additionally, we observed that there was not a single best tokenizer. Each one produced the best results for certain language pairs. Although, in some cases, those best results overlapped with the ones yielded by other tokenizers. Moreover, we have seen different behaviors depending on the language pair direction. The system using SentencePiece obtained the best results for Ar–En, but not for En–Ar translation.
As a future work, we would like to evaluate the relation between the size of the corpora and the quality yielded by SentencePiece—which uses each language’s training corpora to learn how to segment. It would also be interesting to compare more segmentation strategies such as separating by characters or fixed n-grams. Finally, we would like to confirm that repeating these experiments on some of the general domain training data used for these languages achieves similar effects.
References
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2015)
Britz, D., Goldie, A., Luong, T., Le, Q.: Massive exploration of neural machine translation architectures. arXiv preprint arXiv:1703.03906 (2017)
Dyer, C.: Using a maximum entropy model to build segmentation lattices for MT. In: Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics, pp. 406–414 (2009)
Goldwater, S., McClosky, D.: Improving statistical MT through morphological analysis. In: Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, pp. 676–683 (2005)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Huck, M., Riess, S., Fraser, A.: Target-side word segmentation strategies for neural machine translation. In: Proceedings of the Conference on Machine Translation, pp. 56–67 (2017)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Klein, G., Kim, Y., Deng, Y., Senellart, J., Rush, A.M.: OpenNMT: open-source toolkit for neural machine translation. arXiv preprint arXiv:1701.02810 (2017)
Koehn, P.: Statistical significance tests for machine translation evaluation. In: Proceedings of the Conference on Empirical Methods in Natural Language Processing, pp. 388–395 (2004)
Koehn, P., et al.: Moses: open source toolkit for statistical machine translation. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, pp. 177–180 (2007)
Kudo, T.: Sentencepiece experiments (2018). https://github.com/google/sentencepiece/blob/master/doc/experiments.md
Kudo, T.: Subword regularization: improving neural network translation models with multiple subword candidates. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, pp. 66–75 (2018)
Nguyen, T., Vogel, S., Smith, N.A.: Nonparametric word segmentation for machine translation. In: Proceedings of the International Conference on Computational Linguistics, pp. 815–823 (2010)
Nießen, S., Ney, H.: Statistical machine translation with scarce resources using morpho-syntactic information. Comput. Linguist. 30(2), 181–204 (2004)
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: BLEU: a method for automatic evaluation of machine translation. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, pp. 311–318 (2002)
Pascanu, R., Gulcehre, C., Cho, K., Bengio, Y.: How to construct deep recurrent neural networks. arXiv preprint arXiv:1312.6026 (2013)
Pinnis, M., Krišlauks, R., Deksne, D., Miks, T.: Neural machine translation for morphologically rich languages with improved sub-word units and synthetic data. In: Proceedings of the International Conference on Text, Speech, and Dialogue, pp. 237–245 (2017)
Schuster, M., Paliwal, K.K.: Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 45(11), 2673–2681 (1997)
Sennrich, R., Haddow, B., Birch, A.: Neural machine translation of rare words with subword units. In: Proceedings of the Annual Meeting of the Association for Computational Linguistics, pp. 1715–1725 (2016)
Snover, M., Dorr, B., Schwartz, R., Micciulla, L., Makhoul, J.: A study of translation edit rate with targeted human annotation. In: Proceedings of the Association for Machine Translation in the Americas, pp. 223–231 (2006)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Proceedings of the Advances in Neural Information Processing Systems, pp. 3104–3112 (2014)
Tseng, H., Chang, P., Andrew, G., Jurafsky, D., Manning, C.: A conditional random field word segmenter. In: Proceedings of the Special Interest Group of the Association for Computational Linguistics Workshop on Chinese Language Processing, pp. 168–171 (2005)
Wu, Y., et al.: Google’s neural machine translation system: bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144 (2016)
Zhao, H., Utiyama, M., Sumita, E., Lu, B.L.: An empirical study on word segmentation for Chinese machine translation. In: Proceedings of the Computational Linguistics and Intelligent Text Processing, pp. 248–263 (2013)
Acknowledgments
The research leading to these results has received funding from the Centro para el Desarrollo Tecnológico Industrial (CDTI) and the European Union through Programa Operativo de Crecimiento Inteligente (EXPEDIENT: IDI-20170964). We gratefully acknowledge the support of NVIDIA Corporation with the donation of a GPU used for part of this research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 Springer Nature Switzerland AG
About this paper

Cite this paper
Domingo, M., García-Martínez, M., Helle, A., Casacuberta, F., Herranz, M. (2023). How Much Does Tokenization Affect Neural Machine Translation?. In: Gelbukh, A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2019. Lecture Notes in Computer Science, vol 13451. Springer, Cham. https://doi.org/10.1007/978-3-031-24337-0_38
Download citation
DOI: https://doi.org/10.1007/978-3-031-24337-0_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-24336-3
Online ISBN: 978-3-031-24337-0
eBook Packages: Computer ScienceComputer Science (R0)