
Abstract
Competitive-collaborative representation based classification (CCRC) has been widely used in pattern recognition and machine learning due to its simplicity, effectiveness, and low complexity. However, its performance is highly dependent on the data distribution. When addressing imbalanced classification issue, its classification results usually tend towards the majority classes. To solve this deficiency, a class weight learning algorithm is introduced into the framework of CCRC for imbalanced classification. The weight of each class is adaptively generated according to the representation ability of each class of training samples, in which the minority classes can be given larger weights. Our proposed model is solved with a closed-form solution and inherits the efficiency property of CCRC. Extensive experimental results show that our model outperforms the commonly used imbalanced classification methods.
Supported by the National Natural Science Foundation of China under Grant 62106233 and 62106068, by the Science and Technology Research Project of Henan Province under Grant 222102210058, 222102210027, and 222102210219, and by the Grant KFJJ2020104, 2019BS032, 2020BSJJ027, and 202210463023, 202210463024.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


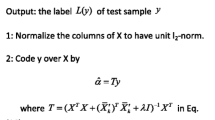
Keywords
1 Introduction
Imbalanced classification has become an important research direction in pattern recognition due to the prevalence of imbalanced datasets in the real world. Traditional classifiers generally achieve good classification results on balanced datasets but cannot work well on imbalanced datasets [14, 15, 18, 19]. Imbalanced class distribution makes traditional classifiers more inclined to the majority classes, which results in poor overall classification accuracy [8]. In practice, the minority classes usually contain more important and valuable information than the majority classes. Once they are misjudged, there may be serious consequences. For example, judging an intrusion as a normal behavior may cause a major network security incident; misdiagnosing a cancer patient as a normal person will delay the best treatment time and threaten the patient’s life. Therefore, it is necessary and urgent to improve the classification accuracy of the minority classes.
At present, there are two main aspects to improve the imbalanced classification methods [4, 12]. One is from the data-level, and the other is from the algorithm-level. The former is mainly to improve the classification performance by balancing the class distribution [1, 11, 13]. Random under-sampling (RUS) and random oversampling (ROS) [3, 9] are two commonly used sampling techniques. RUS randomly reduces the majority samples to the same number size as the minority samples, but it may lose potential information. To overcome this defect, EasyEnsemble [20, 24] introduced data cleaning scheme to improve RUS. It randomly selects several subsets from the samples of the majority classes and combines them with the data of the minority classes to train and generate multiple base classifiers, which improves the learning performance. ROS is to copy the randomly selected minority class samples and add the generated selection set to the minority classes to obtain new minority class instances. Nevertheless, it may lead to overfitting. To address the overfitting problem, the authors in [6] proposed a synthetic minority over-sampling technique (SMOTE) by using interpolation theory. Afterwards, many variants of SMOTE such as adaptive synthetic sampling (ADASYN) [10], majority weighted minority oversampling technique (MWMOTE) [1], SMOTEENN [2] were provided to obtain more effective minority class instances. However, both oversampling and undersampling would destroy the relationship between the original data so that the final recognition accuracy cannot be significantly improved.
The algorithm-level is to improve the classification accuracy by enhancing the traditional classification approaches [5, 23, 25]. The core idea of this type is to give different weights to samples of different classes to improve the classification performance of the minority classes. Among them, the spare supervised representation-based classifier (SSRC) [21] shows excellent advantages. It introduces label information and class weights into SRC to improve the classification accuracy. But the extremely high computational complexity limits its further development and application. Inspired by this, in this paper we choose the efficient and effective CCRC [26] as the base model for imbalanced classification. We incorporate a class weight learning algorithm into CCRC according to the representation ability of each class of training samples. The algorithm adaptively obtains the weight of each class and can assign greater weights to the minority classes, so that the final classification results are more fair to the minority classes. The proposed model can be solved efficiently with a closed-form solution. Experimental results on authoritative public imbalanced datasets show that our method outperforms other commonly used imbalanced classification algorithms.
The remainder of this paper is organized as follows. Section 2 briefly introduces the related work. The proposed imbalanced classification method is described in Sect. 3. Experimental results are shown in Sect. 4. Finally, Sect. 5 draws the conclusion.
2 Related Work
This section introduces the nearest subspace classification (NSC) [19], collaborative representation based classification (CRC) [22], and CCRC [26] algorithms that are closely related to our method. First, the symbols used in the paper are given. \(\text {D}=[D_{1},...D_{n},...D_{N}]\) represents the entire training sample set, where \(D_{n}\in \mathbb {R}^{d\times { M_{n}}}\) represents the training sample set of class n. \(M_{n}\) is the number of samples in \(D_{n}\), and d is the feature dimension of each sample. \(M=M_{1}+M_{2}+...M_{N}\) represents the number of all training samples. \(x\in \mathbb {R}^{d}\) represents a test sample. \(c=[c_{1};...c_{n};...c_{N}]\) is the coefficient vector of x over D, \(c^{*}=[c_{1}^*;...c_{n}^*;...c_{N}^*]\) is the optimal coefficient vector of x over D. \(c_{n}\) is the coefficient vector of x over \(D_{n}\), \(c_{n}^*\) is the optimal vector of x over \(D_{n}\). I is the identity matrix. \(\gamma \) and \(\alpha \) represent the regularization parameters. \(\beta _{n}\) represents the weight of class n.
2.1 NSC
NSC calculates the distance between the test sample x and each class of the training set and classifies x into the class of its nearest subspace. The specific model is as follows
It has a closed-form solution
According to the minimum reconstruction error criterion, the label of x is predicted as
2.2 CRC
NSC uses each class of training samples to represent the test samples individually. However, CRC takes all the training samples as a whole to collaboratively represent the test samples. Given a test sample x, CRC solves the minimum problem by introducing \(\ell _2\)-norm regularization
The above equation also has a closed-form solution
With the optimal coefficient vector, the classification result of x is obtained
2.3 CCRC
CCRC introduces a competition mechanism into the CRC model, and its model is expressed as follows
where \(\sum _{n=1}^{N}\Vert x-D_{n}c_{n}\Vert _2^2\) reflects the competitiveness of each class. \(\alpha \) is the regularization parameter that balances competitiveness and collaborativeness. The model can also be solved analytically
where G is defined as
After obtaining the optimal coefficient vector \(c^*\), CCRC classifies the test samples x according to the same classification criterion as CRC. Here, we will not repeat it.
3 Proposed Method
This section describes the weighted competitive-collaborative representation based classifier (WCCRC) model in detail. First, a class weight learning method is introduced into the CCRC model to give different weights to different classes. Next, the proposed model is solved with a closed-form solution. Finally, the classification criterion is given.
3.1 WCCRC Model
CCRC introduces a competition mechanism between each class of samples. Assuming that the true label of a given test sample x is k, CCRC desires the intra-class loss \(\Vert x-D_nc_n\Vert _2^2\) to be as small as possible and the inter-class loss \(\{\Vert x-D_nc_n\Vert _2^2\}_{n=1,n\ne k}^{N}\) to be as large as possible. Since the actual label is unknown, the model minimizes the sum of all losses \(\sum _{n=1}^{N}\Vert x-D_nc_n\Vert _2^2\). However, it does not consider class distribution information. When handling imbalanced classification tasks, CCRC generally makes the representation ability of the majority classes far more than the minority classes, resulting in the final classification results leaning towards the majority classes. Especially for severely imbalanced datasets, the minority classes usually have an extremely low representation for test samples. This will make their reconstruction error larger than the majority classes, which is not conducive to the final classification. In this section, we assign different weights to different classes in CCRC based on NSC. Our objective function is expressed as
It is called weighted competitive-collaborative representation based classifier (WCCRC) model.
3.2 Class Weight Learning Based on NSC
We use the reconstruction error of each class in the NSC model to learn each class weight. According to Sect. 2.1, the optimal coefficient vector of x over \(D_{n}\) is
The reconstruction error of this class to x is
We define the maximum reconstruction error as
Obviously, the larger the \(r_n\), the weaker the representation ability of \(D_n\) to x. The less likely it is that x belongs to the nth class. On the basis of this fact, the weight of the nth class is defined as
where the scaling parameter \(\delta >0\) is to control the class weight. Taking binary-classification as an example, we can show this method can indeed give greater weights to the minority classes. Assuming that the first class is the minority class, it has a weak representation of the test sample. The reconstruction error \(r_1>r_2\), then \(r_{max}=r_1\). Thus, \(\beta _1=\exp (\frac{r_{1}-r_{1}}{\delta })=1\) and \(\beta _2=\exp (\frac{r_{2}-r_{1}}{\delta })<1\). We get that the NSC-based class weight learning algorithm can give the minority classes greater weights for binary-classification. For multi-classification, its weighting analysis is more complicated than binary-classification. We will use experimental results in Sect. 4 to show the effectiveness of this class weight update mechanism. Algorithm 1 describes the specific steps of class weight learning.
3.3 Optimization Solution and Classification Criterion
To solve the minimization problem (10) in the WCCRC model, we first give a new matrix \(\tilde{D}_n=\left[ 0,\ldots ,0,{D}_n,0,\ldots ,0\right] \) which keeps the columns of the nth class in D and sets the other columns to zero. The theorem below can guarantee WCCRC has a closed-form solution.
Theorem 1
Given each class weight \(\beta _n\), the WCCRC model is solved as
Proof
For ease of computation, the objective function in problem (10) can be written as
Then take the derivation of \(\vartheta \) with respect to c to be zero
So the closed-form solution \(c^*\) can be easily obtained as
Thus, the proof is completed.
After obtaining the optimal coefficient vector \(c^*\), we calculate the reconstruction error of each class
The minimum reconstruction error criterion determines the label of x as
The WCCRC classification method is described in Algorithm 2


4 Experimental Results
In this section, several imbalanced datasets from UCI repository [16] are used to verify the effectiveness of the proposed method.
4.1 Datasets and Experimental Setup
During the experiments, we use two binary-class and five multi-class imbalanced datasets to test the performance of our method. The detailed feature information for these datasets is described in Table 1. The class distribution shows the number of samples of each class, and the imbalance rate (IR) indicates the ratio of the number of samples of the most majority classes to the number of samples of the least minority class. As seen from Table 1, the imbalance rates of the used datasets have a large range from 1.10 to 71.51. The higher the imbalance rate, the greater the difficulty of accurate classification.
Since the commonly used metrics in balanced classification cannot effectively evaluate imbalanced classification algorithms, we use \(F-measure\) and \(G-mean\) to measure imbalanced classification performance [7]. Whether binary-classification or multi-classification, the larger the \(F-measure\) and \(G-mean\), the better the classification performance. In the experiments, we use the five-fold cross-validation method [17]. Each dataset is randomly divided into five subsets. One subset is selected as the test set, and the remaining four are used as the training set. This method is randomly performed ten times on each dataset, and the average is taken as the final experimental result. In specific experiments, the parameters involved in each comparison model are carefully adjusted to achieve optimal experimental results. For the proposed WCCRC, there are three parameters \(\alpha \), \(\gamma \), \(\delta \) that are important for the performance evaluation of the model. We set the candidate sets of \(\alpha \), \(\gamma \) as \(\{10^{-5},10^{-4},10^{-3},10^{-2},10^{-1}\}\) and the candidate set of \(\delta \) as \(\{1,2,...,10^{1},10^{2},10^{3},10^{4},10^{5}\}\). These three parameters are tuned by a grid search algorithm to obtain the optimal experimental results.
4.2 Comparison with Imbalanced Classification Methods
In this section, we compare WCCRC with the commonly used imbalanced classification methods including RUS [20], ADASYN [10], SMOTE [6], MWMOTE [1], WELM [27], SMOTEENN [2], and EasyEnsemble [20]. Tables 2 and 3 show the comparison results of WCCRC and the competing algorithms in terms of \(F-measure\) and \(G-mean\), respectively. The best experimental results are shown in bold. It can be seen that WCCRC shows the best recognition performance on five out of seven datasets. For the severely imbalanced dataset Ecoli, although WCCRC’s \(F-measure\) is slightly lower than other methods, its \(G-mean\) far exceeds the second best. Particularly, the accuracy of WCCRC on Wine and Newthyroid1 can reach 100\(\%\).
To comprehensively evaluate the classification performance of our method, we calculate the average classification rate of each method on all imbalanced datasets. The comparison results are reported in Table 4. We can find that two undersampling methods RUS and EasyEnsemble are relatively low. Four oversampling algorithms including SMOTE, WMMOTE, ADASYN, and SMOTEENN have a little improvement and obtain comparable classification performance. WELM performs better than the above sampling approaches. Obviously, WCCRC outperforms all compared methods with a high average recognition rate of \(91.12\%\). In summary, our method has great advantages in handling imbalanced classification issue.
5 Conclusion
This paper proposes a weighted competitive-collaborative representation based classifier for imbalanced classification. It solves the problem that CCRC cannot work well on imbalanced datasets. The key idea is to introduce an adaptive class weight learning scheme into the framework of CCRC. It gives greater weights to the minority classes so that the classification results are more fair to the minority classes. The proposed model is efficiently solved with a closed-form solution. Extensive experimental results on several imbalanced datasets verify the effectiveness of the proposed method. In the future, we will consider more efficient and effective weight learning approaches.
References
Barua, S., Islam, M.M., Yao, X., Murase, K.: MWMOTE-majority weighted minority oversampling technique for imbalanced data set learning. IEEE Trans. Knowl. Data Eng. 26(2), 405–425 (2013)
Batista, G.E., Prati, R.C., Monard, M.C.: A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 6(1), 20–29 (2004)
Cao, P., Liu, X., Zhang, J., Zhao, D., Huang, M., Zaiane, O.: l(2,1) norm regularized multi-kernel based joint nonlinear feature selection and over-sampling for imbalanced data classification. Neurocomputing 234, 38–57 (2017)
Cao, P., Zhao, D., Zaiane, O.: An optimized cost-sensitive svm for imbalanced data learning. In: Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G. (eds.) PAKDD 2013. LNCS (LNAI), vol. 7819, pp. 280–292. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-37456-2_24
Castro, C.L., Braga, A.P.: Novel cost-sensitive approach to improve the multilayer perceptron performance on imbalanced data. IEEE Trans. Neural Netw. Learn. Syst. 24(6), 888–899 (2013)
Chawla, N.V., Bowyer, K.W., Hall, L.O., Kegelmeyer, W.P.: SMOTE: synthetic minority over-sampling technique (2011)
Guo, H., Liu, H., Wu, C., Zhi, W., Xiao, Y., She, W.: Logistic discrimination based on G-mean and F-measure for imbalanced problem. J. Intell. Fuzzy Syst. 31, 1155–1166 (2016)
He, H., Garcia, E.A.: Learning from imbalanced data (2008)
He, H., Garcia, E.A.: Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 21(9), 1263–1284 (2009)
He, H., Yang, B., Garcia, E.A., Li, S.: ADASYN: adaptive synthetic sampling approach for imbalanced learning. In: IEEE International Joint Conference on IEEE World Congress on Computational Intelligence Neural Networks, IJCNN 2008 (2008)
Hernandez, J., Carrasco-Ochoa, J.A., Trinidad, J.F.M.: An empirical study of oversampling and undersampling for instance selection methods on imbalance datasets. In: CIARP (1) (2013)
Huang, C., Li, Y., Loy, C.C., Tang, X.: Learning deep representation for imbalanced classification. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016, pp. 5375–5384. IEEE Computer Society (2016). https://doi.org/10.1109/CVPR.2016.580
Han, H., Wang, W.-Y., Mao, B.-H.: Borderline-SMOTE: a new over-sampling method in imbalanced data sets learning. In: Huang, D.-S., Zhang, X.-P., Huang, G.-B. (eds.) ICIC 2005. LNCS, vol. 3644, pp. 878–887. Springer, Heidelberg (2005). https://doi.org/10.1007/11538059_91
Jin, J., Li, Y., Chen, C.: Pattern classification with corrupted labeling via robust broad learning system. IEEE Trans. Knowl. Data Eng. 34(10), 4959–4971 (2021)
Jin, J., Li, Y., Yang, T., Zhao, L., Duan, J., Chen, C.P.: Discriminative group-sparsity constrained broad learning system for visual recognition. Inf. Sci. 576, 800–818 (2021)
Khan, M., Arif, R.B., Siddique, M., Oishe, M.R.: Study and observation of the variation of accuracies of KNN, SVM, LMNN, ENN algorithms on eleven different datasets from UCI machine learning repository (2018)
Kohavi, R.: A study of cross-validation and bootstrap for accuracy estimation and model selection. In: International Joint Conference on Artificial Intelligence (1995)
Li, Y., Zhang, L., Qian, T.: 2D partial unwinding-a novel non-linear phase decomposition of images. IEEE Trans. Image Process. 28(10), 4762–4773 (2019)
Li, Y., Jin, J., Zhao, L., Wu, H., Sun, L., Chen, C.L.P.: A neighborhood prior constrained collaborative representation for classification. Int. J. Wavel. Multiresolut. Inf. Process. 19, 2050073 (2020)
Liu, X., Wu, J., Zhou, Z., Member, S.: Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B 39, 539–550 (2008)
Shu, T., Zhang, B., Tang, Y.Y.: Sparse supervised representation-based classifier for uncontrolled and imbalanced classification. IEEE Trans. Neural Netw. Learn. Syst. 31, 2847–2856 (2018)
Wang, H., Wang, X., Chen, C., Cheng, Y.: Hyperspectral image classification based on domain adaptation broad learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 13(99), 3006–3018 (2020)
Cheng, F., Zhang, J., Wen, C., Liu, Z., Li, Z.: Large cost-sensitive margin distribution machine for imbalanced data classification. Neurocomputing 224, 45–57 (2017)
Yang, P., Yoo, P.D., Fernando, J., Zhou, B.B., Zhang, Z., Zomaya, A.Y.: Sample subset optimization techniques for imbalanced and ensemble learning problems in bioinformatics applications. IEEE Trans. Cybern. 44(3), 445–455 (2013)
Yang, X., Kuang, Q., Zhang, W., Zhang, G.: AMDO: an over-sampling technique for multi-class imbalanced problems. IEEE Trans. Knowl. Data Eng. 30(9), 1672–1685 (2017)
Yuan, H., Li, X., Xu, F., Wang, Y., Lai, L.L., Tang, Y.Y.: A collaborative-competitive representation based classifier model. Neurocomputing 275, 627–635 (2018)
Zong, W., Huang, G.B., Chen, Y.: Weighted extreme learning machine for imbalance learning 101, 229–242 (2013). https://doi.org/10.1016/j.neucom.2012.08.010
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Li, Y., Wang, S., Jin, J., Philip Chen, C.L. (2022). Weighted Competitive-Collaborative Representation Based Classifier for Imbalanced Data Classification. In: Fang, L., Povey, D., Zhai, G., Mei, T., Wang, R. (eds) Artificial Intelligence. CICAI 2022. Lecture Notes in Computer Science(), vol 13605. Springer, Cham. https://doi.org/10.1007/978-3-031-20500-2_38
Download citation
DOI: https://doi.org/10.1007/978-3-031-20500-2_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-20499-9
Online ISBN: 978-3-031-20500-2
eBook Packages: Computer ScienceComputer Science (R0)