
Abstract
For computer vision systems based on artificial neural networks, increasing the resolution of images typically improves the performance of the network. However, ImageNet pre-trained Vision Transformer (ViT) models are typically only openly available for 2242 and 3842 image resolutions. To determine the impact of using higher resolution images with ViT systems the performance differences between ViT-B/16 models (designed for 3842 and 5442 image resolutions) were evaluated. The multi-label classification RANZCR CLiP challenge dataset, which contains over 30,000 high resolution labelled chest X-ray images, was used throughout this investigation. The performance of the ViT 3842 and ViT 5442 models with no ImageNet pre-training (i.e. models were only trained using RANZCR data) was firstly compared to see if using higher resolution images increases performance. After this, a multi-resolution fine-tuning approach was investigated for transfer learning. This approach was achieved by transferring learned parameters from ImageNet pre-trained ViT 3842 models, which had undergone further training on the 3842 RANZCR data, to ViT 5442 models which were then trained on the 5442 RANZCR data. Learned parameters were transferred via a tensor slice copying technique. The results obtained provide evidence that using larger image resolutions positively impacts ViT network performance and that multi-resolution fine-tuning can lead to performance gains. The multi-resolution fine-tuning approach used in this investigation could potentially improve the performance of other computer vision systems which use ViT based networks. The results of this investigation may also warrant the development of new ViT variants optimized to work with high resolution image datasets.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
When developing artificial neural networks for computer vision tasks, increasing the resolution of images used for training and inference often improves the performance of the network. Intuitively, this is because higher resolution images contain more information that can be used by the network. However, once a certain image size is reached the performance gained from increasing image resolution will plateau. For EfficientNet [1] and EfficientNetV2 [2], models pre-trained on ImageNet are available that can use 2242 image resolutions (B0 model variants) to 6002 image resolutions (B7 model variants). These Convolutional Neural Networks (CNNs) provide good examples of increased classification accuracy on the ImageNet benchmark [3] when using higher image resolutions and also how accuracy begins to plateau once a given image resolution (6002) is reached. It should be noted that the image resolution at which performance begins to plateaus will likely be different depending on the dataset.
Image resolution has also been shown to have an important effect on CNNs when evaluating their performance on test datasets and for transfer learning applications. Touvron et al. [4] used a light-weight parameter adaptation of a CNN to allow larger image resolutions to be used while testing the network (the main aim was to fix the resolution discrepancy seen by CNNs between training and testing). Touvron et al. showed that test performance increased when using higher resolution images (up to a plateau value) than those the CNN was trained on. Kolesnikov et al. [5] investigated methods to improve the generalization of CNNs for transfer learning tasks by altering network architecture (e.g. replacing Batch Normalization with Group Normalization). They also showed that fine-tuning CNNs to the test dataset resolution can improve transfer learning performance.
In the original Vision Transformer (ViT) paper [6] the authors fine-tuned the ViT network at higher resolution (3842) than that used in pre-training (2242) and attained higher accuracies on popular image classification benchmarks (including ImageNet) when using 3842 ViT models when compared to 2242 ViT models. This was achieved by keeping the image patch size the same, which results in the ViT network having a larger sequence of patches. However, ViT networks for image resolutions larger than 3842 were not created and trained/fine-tuned in the original paper.
More recently, the rules determining how ViT models scale have been investigated by scaling ViT models and characterizing the relationships between error rate, data requirements and computing power [7]. This resulted in the creation of the ViT-G/14 model variant [7] which was trained on extremely large proprietary datasets (e.g. JFT-300M) using 2242 image resolutions before being fine-tuned using the same extremely large proprietary datasets with 5182 image resolutions. The ViT-G/14 model, which contains approximately two billion parameters, attained previous state-of-the-art on ImageNet with 90.45% top-1 accuracy (top-1 accuracy relates to where the highest class prediction probability is the same as the target label). However, for many users the current hardware requirements needed to train the ViT-G/14 network or use it for transfer learning tasks would be prohibitively expensive. It would be even more challenging to use ViT-G/14 as an encoder for dense prediction (e.g. segmentation or monocular depth estimation) tasks due to even more parameters being needed within the models.
The work presented in this paper details the results of an investigation to take a multi-resolution fine-tuning approach (whereby networks are trained through transfer learning, initially on low resolution images before being fine-tuned on higher resolutions versions of these images) and apply this directly to transfer learning applications relating to medical image analysis using ViT systems. To the best of the authors knowledge, this is the first time that multi-resolution fine-tuning has been applied directly to medical imaging for ViT systems. The medical image dataset used in this investigation consists of over 30,000 chest X-rays (taken to evaluate the positioning of multiple catheters) and allows the multi-label classification performance of ViT models to be evaluated. Firstly, a performance comparison between ViT 3842 and ViT 5442 networks with no prior training (i.e. models were only trained using RANZCR CLiP data) was conducted. After the initial performance comparison showed that using larger image sizes is beneficial, a multi-resolution fine-tuning approach was applied directly to the RANZCR CLiP transfer learning task. This was achieved by transferring learned network parameters (via a tensor slice copying technique) from ImageNet pre-trained ViT 3842 models, which had undergone further training on the 3842 RANZCR CLiP data, to newly initialized ViT 5442 models which were further trained on the 5442 RANZCR CLiP data. Results provide strong evidence that this approach increases multi-label classification accuracy and that using higher image resolution can improve network performance.
2 Method
2.1 Image Dataset Selection
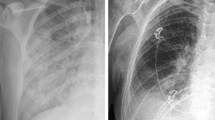
The Royal Australian and New Zealand College of Radiologists (RANZCR) Catheter and Line Position (CLiP) challenge dataset consists of over 30,000 high resolution (typically greater than 20002) labelled chest X-ray images [8]. The aim of the original dataset challenge [9] was to detect the presence and position of different catheters and lines within chest X-ray images. The positions of the inserted catheters/lines are important since if they are poorly placed, they can worsen the patient’s condition. There are four types of catheters/lines: Endotracheal Tube (ETT), NasoGastric Tube (NGT), Central Venous Catheter (CVC) and Swan-Ganz Catheter (SGC). The ETT, NGT and CVC can be categorized as ‘Normal’, ‘Borderline’ or ‘Abnormal’ and the SGC is either ‘Present’ or ‘Not Present’ hence making this a multi-label classification problem with 11 classes. The metric used to evaluate the multi-label classification performance in the original challenge was the ‘One vs Rest Area Under Curve Receiver Operator Characteristic’ (AUC-ROC) and this metric is used to evaluate performance of models within this investigation. The RANZCR CLiP dataset was selected for this transfer learning investigation due to the high resolution of the images and because classifying the placement of catheters/lines likely requires analysis of fine detail within the images (Fig. 1).

Example of a cropped X-ray image region (from the RANZCR CLiP database) [8] generated using two different original image resolutions. This demonstrates potential information loss as the image size decreases.
2.2 Multi-resolution Fine-Tuning for Transfer Learning
When using the PyTorch deep learning framework for transfer learning, it is necessary to load weights from pre-trained models into your current model. This commonly requires that the tensors containing the parameters of the models match in name, shape, and size. Therefore, using larger image sizes as input into a ViT model which has been trained on smaller sized images would not be immediately possible. To overcome this limitation, it is possible to copy parameters (in the form of tensor slices) from pre-trained ViT models and insert these into the tensors (which are either the same size or are larger) of a new ViT model capable of processing higher resolution images. This tensor slice copying technique also allows other network design features of the new ViT model to be changed whilst still making use of the original pre-trained ViT model parameters. Examples of such network design features include: fully connected layer ratio, image embedding size, network depth and number of attention heads.
As an example, comparing a standard (i.e. ViT-B/16) ViT 5442 model to a standard pre-trained ViT 3842 model shows that only the size and shape of the Layer 2 tensor changes, while for all other layers the size and shape of tensors is identical. Therefore, the learned ViT 3842 model parameters can be transferred via tensor slice copying to every layer of the 5442 ViT model. Specifically, for Layer 2 it is possible to either: (1) ignore the ViT 3842 Layer 2 tensor learned parameters and leave the Layer 2 tensor of the ViT 5442 with its original initialization state; or (2) transfer the ViT 3842 Layer 2 tensor learned parameters to the Layer 2 tensor of the ViT 5442 which only partially fills the tensor.
In this investigation parameters from ImageNet pre-trained ViT-B/16 3842 models [6, 10] were inserted via the tensor slice copying technique into a newly created ViT 5442 ViT-B/16 models which had an increased fully connected layer ratio (4.25 compared to 4 in the original ViT 3842 model). All possible parameters were transferred meaning that some ViT 5442 layer tensors would have been only partially filled (i.e. option (2) from the previous paragraph) (Table 1).
2.3 Fold Selection and PyTorch Model Training
The RANZCR CLiP data was split into twenty folds (using a typical K-Fold random stratified sampling approach) with care also being taken to ensure that no data leakage occurred (e.g. data from a given patient was always contained in the same fold). Due to hardware limitations (all training and validation was run on a single Nvidia 3090 GPU) and the need for repeat runs using different random number seeds, it was not possible to use all twenty folds for cross validation in the transfer learning investigation. Instead six folds consisting of the three highest scoring and three lowest scoring AUC ROC validation scores were selected after the twenty-fold cross validation study was conducted using an ImageNet pre-trained ViT 3842 network [6, 10] which underwent additional training on the RANZCR CLiP data. This found that the highest scoring validation folds were 14, 8 and 10, with the lowest scoring validation folds being 2, 20 and 12. After six epochs of training overfitting began to occur. The results of the twenty-fold cross validation study are displayed in Fig. 2. No data augmentation or image pre-processing was conducted (Fig. 2).

Comparison of the three highest scoring and three lowest scoring AUC ROC validation scores from the twenty-fold cross validation scoping study conducted using a pre-trained ViT 3842 network which underwent additional training on the RANZCR CLiP data. Overfitting begins to occur after approximately six epochs.
Before conducting the transfer learning investigation, a performance comparison between ViT 3842 and ViT 5442 models with no prior ImageNet training was conducted (i.e. only RANZCR CLiP data was used for training and validation) for each of the six folds selected.
For the investigation into the multi-resolution fine-tuning approach which can be directly applied to transfer learning, the model states of ImageNet pre-trained ViT 3842 models which underwent additional training on the RANZCR CLiP data were saved for each of the six folds investigated. The saved ViT 3842 model states after epoch three of training were then transferred to the corresponding ViT 5442 networks using the tensor slice copying technique. ViT 5442 networks were then trained on the RANZCR CLiP data, hence allowing for a multi-resolution fine-tuning approach. For each fold, six ViT 5442 model runs were then conducted using different random number generation seeds. An additional six ViT 3842 model runs were conducted using different random number generation seeds. These repeat runs were conducted to give confidence that improvements in performance are not down to the small random variability of network predictions. The different random number generation seeds impact the order of how image batches are loaded. In order to focus on the effects of image resolution, the PyTorch training settings and hyperparameters were kept the same between runs. However, it is likely that the training process followed in the original ViT paper [6] is heavily optimized compared to that used this investigation (Table 2).
3 Results
3.1 ViT 3842 vs ViT 5442 Model Comparison with no Prior Training
The results of the performance comparison between the ViT 3842 and ViT 5442 networks which had no pre-training for the six folds investigated (i.e. only trained using RANZCR CLiP data) are presented in Fig. 3. It can be seen that the average, maximum and minimum (shown with error bar range) AUC ROC validation scores of the six folds investigated are higher for the ViT 5442 network (after eight training epochs) when compared to the 3842 ViT network. Numerical values of the maximum achieved AUC ROC validation scores for each fold investigated are presented in Table 3.
These results provide further evidence of how increasing image resolution can increase the performance of deep learning image classification systems and that this relationship is valid for ViT systems. However, the maximum achieved AUC ROC validation scores for each fold are significantly lower for the ViT 5442 network with no pre-training compared to those of the ImageNet pre-trained ViT 3842 network shown in Fig. 2. This necessitates the need for multi-resolution fine-tuning which can be directly applied to transfer learning tasks (Fig. 3 and Table 3).

Comparison of the average, maximum and minimum AUC ROC validation scores of the six folds investigated for the ViT 3842 and ViT 5442 networks.
3.2 Multi-resolution Fine Tuning
The results of the multi-resolution fine-tuning approach directly applied to the transfer learning task of medical image multi-label classification are visualized for each fold using box plots (showing the minimum, maximum, quartiles and median validation AUC ROC scores) in Fig. 4. Apart from for fold 14, the maximum and median AUC ROC scores achieved using the ViT 5442 network are higher than those obtained using the ViT 3842 network. However, even though the maximum achieved accuracies are significantly higher when pre-training is used, the magnitude of the performance increase between ViT 5442 networks and ViT 3842 networks is smaller compared to when no pre-training was used.
These results provide further evidence that multi-resolution fine-tuning can improve network performance and that, importantly, this approach can be directly applied to transfer learning tasks using ViT systems (Fig. 4 and Table 4).

Box plots showing the minimum, maximum, quartiles and median validation AUC ROC scores of the repeat runs of the six folds investigated for the ViT 3842 (red) and ViT 5442 (blue) networks. (Color figure online)
4 Discussion
The performance comparison between the ViT 3842 and ViT 5442 networks which had no pre-training strongly demonstrate how using larger image resolutions positively impacts ViT network performance. This is further supported by the results of the multi-resolution fine-tuning approach which found that the ViT 5442 network slightly outperformed the ViT 3842 network for five out of the six folds tested.
The multi-resolution fine-tuning approach could potentially impact the performance of other computer vision systems designed for dense prediction tasks (e.g. monocular depth estimation) which use pre-trained ViT models as encoders. An example of such a system would be the Dense Prediction Transformer (DPT) [11] which previously held state-of-art performance on certain monocular depth challenges (such as NYU-Depth V2 [12]). The DPT used the original ViT 3842 ImageNet pretrained network as the encoder starting point. In addition, the multi-resolution fine-tuning approach for direct transfer learning may also be applicable to new ViT systems (such as the Vision Longformer [13]) being developed.
It is likely that further improvements could be made to the multi-resolution fine-tuning approach used in this study. The training method used is likely to not be as optimized as that used in the original ViT paper [6] and any improvements made to the training process could further increase the performance of the ViT 5442 networks. The tensor slice copying technique could also be improved as the approach used in this study directly copied Layer 2 learned parameters from the ViT 3842 network to Layer 2 of the ViT 5442 network. Layer 2 represents learned image embeddings with positional encodings and using a more complex approach to transfer these particular learned parameters to the ViT 5442 network could help during fine-tuning. For example, in the original ViT paper [6] the authors performed 2D interpolation of the pre-trained position embeddings, according to their location in the original image, for resolution adjustment. This would also ensure that all parameters in Layer 2 are updated rather than some parameters keeping their randomly initialized value which could potentially be adversely impacting gradient calculations. However, preliminary investigations which left all Layer 2 parameters in their randomly initialized state had only marginally worse performance compared to partially filling the Layer 2 tensor, suggesting that adverse effects on the gradient calculations are minimal. Examining all twenty folds rather than the six selected folds would also reduce possible bias and conducting more runs for each fold would give even higher confidence in the results obtained. Applying the developed transfer learning approach to other imaging problems and investigating performance would allow external validation of the methods used.
Since the performance gains of the ViT 5442 networks were essentially attained by changing the number of patches used, this might also justify the development of new ViT network variants designed specifically to work with larger image sizes but with network design parameters which are not as extreme as the ViT-G/14 variant (i.e. significantly reduced network depth and total parameter number). Pre-training and fine-tuning of these ViT networks with higher image resolutions (e.g. >5002) than those used in the original ViT paper (2242 and 3842) using large image databases (e.g. ImageNet dataset variants) could lead to significant performance increases. Such models would likely have hardware requirements that would make them accessible to a large number of users/developers and also make them suitable for use in encoder-decoder style systems for dense prediction tasks.
5 Conclusion
The impact of using ViT networks with higher resolution images (compared to those typically used for training on ImageNet dataset variants) on a multi-label classification problem has been evaluated. The dataset used in this investigation was the RANZCR CLiP challenge dataset which consists of over 30,000 high resolution labelled chest X-ray images [8].
A performance comparison between two ViT-B/16 networks [6, 10], which had no pre-training, designed to work with 3842 and 5442 image resolutions has been conducted on the RANZCR CLiP medical image multi-label classification task. The ViT 5442 network outperforms the ViT 3842 network for all six of the data folds that were tested.
A multi-resolution fine-tuning approach was applied to ViT 5442 networks directly for the RANZCR CLiP medical image multi-label classification task. To achieve this, ImageNet pre-trained ViT 3842 model states, after three epochs of additional training on the RANZCR CLiP dataset, were saved. The ViT 3842 model states were then transferred to ViT 5442 models using a tensor slice copying technique and the 5442 models were then trained on the RANZCR CLiP dataset. The results of this approach show that the ViT 5442 network outperformed the ViT 3842 network for five out of the six data folds that were tested.
The results obtained provide strong evidence that using larger image resolutions positively impacts ViT network performance. This may justify the development of new ViT network variants (with significantly less computational requirements than the current state-of-the-art ViT-G/14 variant) designed to work with higher image resolutions (i.e. greater than 3842). Such variants would likely be more accessible to a larger number of users and may also be suitable for use in encoder-decoder systems for dense prediction tasks. The performance of existing encoder-decoder systems for dense prediction tasks, which use ViT based systems as encoders, may also receive transfer learning performance increases by using multi-resolution fine-tuning approaches similar to that used in this investigation.
References
Tan, M., Le, Q.: EfficientNet: rethinking model scaling for convolutional neural networks. In: International Conference on Machine Learning (ICML), Long Beach (2019)
Tan, M., Le, Q.: EfficientNetV2: smaller models and faster training. In: International Conference on Machine Learning (ICML), Virtual (2021)
Deng, J., Dong, W., Socher, R., Li, L., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: IEEE Conference on Computer Vision and Pattern Recognition, Miami (2009)
Touvron, H., Vedaldi, A., Douze, M., Jegou, H.: Fixing the train-test resolution discrepancy. In: Advances in Neural Information Processing Systems (2019)
Kolesnikov, A., et al.: Big transfer (BiT): general visual representation learning. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12350, pp. 491–507. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58558-7_29
Dosovitskiy, A., et al.: An image is worth 16x16 words: transformers for image recognition at scale. In: International Conference on Learning Representations (ICLR), Virtual (2021)
Zhai, X., Kolesnikov, A., Houlsby, N., Beyer, L.: Scaling vision transformers. arXiv (2021)
Tang, J., et al.: CLiP, catheter and line position dataset. Sci. Data 8, 1–7 (2021)
Law, M., et al.: RANZCR CLiP - catheter and line position challenge. Kaggle, 8 March 2021. https://www.kaggle.com/competitions/ranzcr-clip-catheter-line-classification/overview. Accessed June 2021
Wightman, R.: PyTorch image models. GitHub Repository (2019)
Ranftl, R., Bochkovskiy, A., Koltun, V.: Vision transformers for dense prediction. In: International Conference on Computer Vision (ICCV), Montreal (2021)
Silberman, N., Hoiem, D., Kohli, P., Fergus, R.: Indoor segmentation and support inference from RGBD images. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012. LNCS, vol. 7576, pp. 746–760. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33715-4_54
Zhang, P., et al.: Multi-scale vision longformer: a new vision transformer for high-resolution image encoding. In: International Conference on Computer Vision (ICCV), Virtual (2021)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Fitzgerald, K., Law, M., Seah, J., Tang, J., Matuszewski, B. (2022). Multi-resolution Fine-Tuning of Vision Transformers. In: Yang, G., Aviles-Rivero, A., Roberts, M., Schönlieb, CB. (eds) Medical Image Understanding and Analysis. MIUA 2022. Lecture Notes in Computer Science, vol 13413. Springer, Cham. https://doi.org/10.1007/978-3-031-12053-4_40
Download citation
DOI: https://doi.org/10.1007/978-3-031-12053-4_40
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-12052-7
Online ISBN: 978-3-031-12053-4
eBook Packages: Computer ScienceComputer Science (R0)