
Abstract
In multi-turn dialogue generation, the generated response should consider the content before the current turn of dialogue. Due to multiple turns, it is difficult to maintain the context consistency by using only a few previous turns of the dialogue indiscriminately. Except for the context information, we can retrieve additional candidates from historical contexts, according to semantic similarity. Therefore, in this paper, we integrate the historical information into the generative model called HRG. The HRG model can generate a response by using both context information and retrieved historical candidates, which contain richer information such as theme and latent information. We encode contexts, current turn and historical information separately to find the most important turns and give the current turn a higher level of attention. Then we propose a hierarchical fusion encoder to integrate the retrieval information through a KL divergence gate dynamically. Finally, we conduct experiments on the Ubuntu large-scale English multi-turn dialogue community dataset and Daily dialogue dataset. The results show that our hybrid model performs well on both automatic evaluation and human evaluation compared with the existing baseline models.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Dialogue systems intend to use big data to provide users with fast and concise answers. They can be divided into single-turn dialogue systems and multi-turn dialogue systems. Because multi-turn dialogue is more popular and widely used in actual situations, it has been widely used in real-world applications, including customer service systems, personal assistants, and chatbots.
In order to make a dialogue system behave more like humans, two methods are mainly used: one is based on retrieval and the other is based on generation. The retrieval method is widely used in single-turn dialogues to quickly respond to user requests and get answers. As a multi-turn dialogue is much more complicated than a single-turn dialogue, it needs to handle more contextual information and extract effective information from context for generating a better response for the multi-turn dialogue. So how to effectively use complex context to generate a more appropriate response is an important problem in the multi-turn dialogue generation task.
In multi-turn conversation model, it is very difficult to distinguish which turn is important in the context dialogue. Hierarchical Recurrent Encoder-Decoder (HRED) [14, 17] is widely used in multi-turn dialogue generation. This method captures context information through a hierarchical encoder and decoder structure. HRED adds an additional encoder to the traditional encoder-decoder model. Compared with ordinary recurrent neural network (RNN) language model, it can capture the context, reduce the calculation steps between adjacent sentences, and realize multiple turns of dialogue generation. However, the performance of the model will be damaged if the context is handled indiscriminately, and the model often fails to grasp the specific sentence information. Then in order to solve this problem, the recent relevant context with self-attention (ReCoSa) [25] model uses long-distance self-attention mechanism to model the context and response separately, so as to find out which word is important. It uses the self-attention to encode and decode the information, the parameters of both encoder and decoder are learned by maximizing the averaged likelihood of the training data. However, due to the introduction of long attention to calculate the weight of the context only, the model tends to lose the valid information of the current turn and often replies to repeated information.
Consider more specific information is proved very effective on multi-turn conversation model in previous research. Short-text Topic-level Attention Relevance with Biterm Topic Model (STAR-BTM) [24] integrates the topic information in the dialogue generation. However, the topic information is an implicit representation in a conversation, few valid information can be learned. Conditional Historical Generation (CHG) [26] focuses more on the integration of historical information. But CHG can’t learn additional information and repeated useless historical dialogue information of a session can’t improve the performance of the model.
On the other hand, it is also a big challenge to use valid information in context to retrieve relevant historical information and integrate it with the model. There are many attempts in the integration of both the retrieval methods and generative methods in single-turn dialogue generation. Zhu et al. [28] use adversarial training methods to integrate retrieval information in single-turn dialogue. They propose a Retrieval-Enhanced Adversarial Training approach to make better use of N-best response candidates. However, using adversarial training in text generation tasks will greatly increase the difficulty of the model training. So far, no one has done the combination of the retrieval methods and generative methods in multi-turn dialogues, possibly the complexity caused by multiple turns.
Table 1 is an example in the Daily dialogue dataset. People say more than one sentence in a turn. This makes the multi-turn dialogue models more difficult to capture the most effective information. Utterance 1, utterance 2 and utterance 3 are former turns, the current turn is the asking question, retrieval 1 and retrieval 2 are the answers obtained by the retrieval method according to the contextual information. The words in red color represent the response by integrating important words of different turns and historical information in word level. We argue that the current turn is the most important and applying an attention mechanism on the current turn can get different weights of previous turns in sentence level. From Table 1, we can see the response is related to the current turn information, the context information and historical information can be used as a supplement. Utterance 1 and utterance 2 are talking about the price of the product. Utterance 3 is talking about the reasons for the rise in commodity prices. In current turn the customer wants a better price. Retrieval 1 and retrieval 2 serve as supplements to context, finding more background knowledge and hoping to reach a deal with customers in terms of quantity. The response can give the right answer according to context and historical topic, like ‘scale’ and ‘profit’ information. Due to the employment of retrieving historical information, the response is more diverse. The historical information can give response a correct direction. Without introducing historical information, it is difficult to guarantee the diversity of the generated dialogue and the consistency of the context.
In this paper, we propose the hybrid retrieval and generation Model (HRG) model, which is a multi-turn dialogue generation model that combines generated information and retrieved historical information. The model can obtain the information of the same scene according to the semantic similarity. We separate the contexts into two parts, one is current turn information and the other is previous turn information. We argue the current turn information is the most important context. The motivation of this paper is that the combination of generative and retrieval methods will make the response generated by the model more in line with the actual context, and the model can capture more information and find the latent features to maintain context semantic consistency. Compared with the existing multi-turn dialogue methods, we use the retrieved historical information and propose a novel fusion method to integrate historical information hierarchically. Compared with the existed single-turn dialogue method, our model can fit multi-turn tasks. In our proposed HRG model, we use KL divergence to measure the difference between the retrieval information and the context information and give different weights to different contexts, and finally use hierarchical fusion encoder to dynamically integrate the retrieved information. KL divergence is widely used to generate image and increase generalization ability in computer vision.
In the retrieval stage, we first use the semantic similarity method to encode different sentences and then find the most relevant answer based on the given sentence. At the same time, due to the very large amount of data, our retrieval method uses the distilled robustly optimized BERT pretraining approach (RoBERTa) [10]. In the generative stage, we use the Transformer encoder block to capture context information, current turn information, and retrieved historical information separately and then use the hierarchical fusion encoder to integrate the retrieval information, finally, we send the fusion vectors into the decoder to get the response. In our experiment, we use two public datasets, the Daily dialogue dataset, and the English Ubuntu community dataset to evaluate our model. The results show that our model can produce more flexible answers and more appropriate responses than existing baseline models. The contextual consistency of the dialogue is maintained after incorporating retrieval information, which shows that our method is effective and reasonable.
The contributions of this paper are summarized as follows:
-
We propose the HRG model, which integrates the retrieved historical information on the basis of the generative model. Due to the employment of historical information, our model can find latent information and maintain the consistency of the dialogue context.
-
We propose a novel hierarchical fusion encoder to integrate the retrieved historical information through a KL divergence gate dynamically. Using hierarchical fusion encoder can effectively utilize historical information.
-
We conduct experiments on the Ubuntu large-scale English multi-turn dialogue community dataset and Daily dialogue dataset. The experimental results show that our hybrid model performs well on both automatic evaluation and human evaluation compared with the existing baseline models.
2 Related Work
Most of the existing dialogue systems are based on the retrieval method. They use this method to find rich information and respond smoothly. They choose the information and discourse in the previous turn as input and choose the context-sensitive natural response. However, in the generative stage, the answers generated by the generative-based method are more flexible and can cope with complex contexts.
2.1 Single-Turn Response Matching
Retrieval-based methods choose a response from candidate responses. Retrieval-based methods focus more on message-response matching. Matching algorithms have to overcome semantic gaps between messages and responses [3]. Early studies of retrieval-based chatbots focus on response selection [20, 21], where only the single-turn message is used to select a proper response. They calculate the similarity between the context and the answer vector which is encoded by long short-term memory (LSTM). Recent semantic method calculate the similarity of sentences in pre-train model, such as [2, 10]. Azzalini et al. [1] try to use entity linkage to improve semantic quliaty.
2.2 Multi-turn Response Matching
In multi-turn retrieval matching, the existing work is to splice the utterances in context and match the final response. In multi-turn response selection, current message and previous utterances are taken as input. The model selects a response from the repositories which is the most relevant to the whole context. Identifying important information in the previous contexts is very important. Lowe et al. [11] encoded the context and candidate response into a context vector and a response vector through RNN and then computed the similarity between the two vectors. Selecting the previous utterances in different strategies and combining them with current messages is proved effective [23]. The next improvement is to establish a strategy to select context information. Yan et al. [23] select the previous utterances in different strategies and combined them with current message to get the answer.
2.3 Single-Turn Response Generation
Early end-to-end open domain dialogue generation work was inspired by neural machine translation [13, 16]. A good generator often can cope with complex contexts and produce a fluent, grammatical answer. The widely used method is sequence to sequence (Seq2Seq) model [18], it uses RNN or LSTM as encoder and decoder. Li et al. [6] try to use meta-learning to train a better encoder. Given a context sequence, a recurrent neural network-based encoder is first utilized to encode each message, and then in the decoding stage, another RNN decoder is used to generate the response. The parameters of both encoder and decoder are learned by maximizing the averaged likelihood of the training data. Due to the introduction of the attention mechanism, the performance of seq2seq model is better, and the decoder can use attention mechanism to utilize sentence information differently, which improves the accuracy of generation.
2.4 Multi-turn Response Generation
Despite many existing research works on single-turn dialogue generation, multi-turn dialogue generation has gained increasing attention [9, 12, 27]. One reason is that it is more accordant with the real application scenario, such as customer services chatbot. Because more information is considered, customers usually change topics in multi-turn dialogue, which has brought huge challenges to researchers in this field. In the multi-turn dialogue generation task, hierarchical recurrent encoder-decoder architectures (HRED) [14] are proposed to capture context information. Later, Serben propose HRED model with hidden variables, called VHRED [15]. This method introduces hidden variables into the intermediate state in the previous HRED to improve the diversity of the generated dialogue. ReCoSa [25] model can find the most important information of word-level in multi-turn dialogue. ReCoSa use long self-attention mechanism [19] to model multi-turn dialogues. Hierarchical self-attention network (HSAN) [5] can find the most important words and utterances in the context simultaneously.
However, although these methods fully model the context information, they have not considered the diversity of the generated sentences and the consistency of the context information. Now, the data-driven single-turn dialogue system can be roughly divided into two categories, one is generative tasks, and the other is retrieval tasks. In generative tasks, the same as the multi-turn dialogue generation method, it has improved on the basic Seq2Seq model. Recently, using the decoder in transformer block [19] is widely used because of its speed advantage, but this method often generates repetitive and meaningless responses.
There are some works that integrate retrieval and generative methods. Zhu et al. [28] used adversarial training methods to combine generative sentences with sentences obtained from retrieval to get good results, but this method is based on a single-turn of dialogue. And using generative adversarial networks (GAN) is hardly training. Similar to the fusion retrieval information, STAR-BTM [24] integrates the topic information in the dialogue generation. CHG [26] proposes a merchant history conversation selection module which can copy words directly from the relevant history conversations. However, it is difficult to retrieve valid information and fuse them into the context, no one has merged the retrieved information in multi-turn of dialogue according to our current research.
3 HRG Model

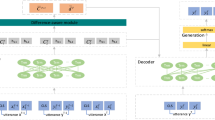
The architecture of Hybrid Generation and Retrieval model. Each turn passes the Bi-GRU to get the sentence representation and add the turn level position encoding.
In this section, we illustrate our model in detail, whose architecture is depicted in Fig. 1. The red bar represents the distribution of retrieved historical information. The knowledge base contains all candidate context information.
3.1 Current Turn and Context Attention
To find the most important turns in contexts, we get the weights of the contexts through the attention mechanism. Given contexts:
each \(utterance{_i}\) in contexts can be represented as \( utterance{_i} = \left\{ {{w_1},{w_2},...,{w_n}} \right\} \), where \({w_i}\) represents a word in an utterance. All sentences in one session are encoded by Bi-GRU to get the representation of the sentence separately, then get the word level importance coefficient and obtain every sentence representation through current turn and context attention. In addition, we integrate the positional embedding to the contexts so as to find the importance of different contexts at the sentence level. The final contexts representation is shown as follow:

where \(TOS_i\) is the turn of sentence embedding, which represents positional embedding to indicate the order of turns,
 and
and
 express Bi-directional sentence vector respectively. The current turn representation is:
express Bi-directional sentence vector respectively. The current turn representation is:

The context attention layer and attention formula are calculated as follows,
where \(h^{CurCon}\) is the current turn and contexts attention representation.
3.2 Retrieval
In order to obtain the supplement information of related contexts, we use distilled RoBERTa [10] language model. First, we set up message-response pairs, and use RoBERTa to encode each message into a 768-dimension vector. Then we use each message as a query to calculate the semantic similarity in the vector library, to search the most matching message in the range k. Finally, during the training process, according to the matching score, the semantic algorithm returns the most matching message called candidate context. In addition, our retrieval model is also trained with the model, which can not only improve the quality of model generation but also improve the retrieval performance of similar sentences. So our model can enrich the context and response fields.
Since the training set used in the retrieval is the same as the training set used in the model training, in order to avoid the retrieval method from seeing the ground truth, we exclude the retrieved sentences from the ranking. The retrieval function between retrieval and attention vectors similarity is calculated by cosine similarity.
Algorithm 1 presents how to find semantic retrieval vectors, \(h^{Con}\), \(h^{Cur}\) represent context vector and current turn vector. And input the retrieval knowledge, through our algorithm, we can finally get the most relevant retrieval vectors. The similarity formula mentioned in the algorithm is pre-encoded as shown in the above formula.

3.3 Hierarchical Fusion Encoder
In order to solve the semantic consistency of context and response, it is very important to integrate the information obtained from semantic retrieval into context. Based on this principle, we propose a hierarchical divergence fusion encoder and use KL divergence to measure the word distribution between context and retrieval context. KL divergence can measure the difference between two distributions. Then we use a hierarchical encoder to fuse retrieval and context information differences.
Through the retrieval part, we get the context candidate and response candidate. Taking context level fusion as an example, in order to detect the difference between the retrieved candidate context information and context information, we let the candidate context pass KL gate, and the formula is as follows:
where i represents the \(i^{th}\) utterance in the context. From formula 2 we get the context’s attention weights, we use it to control the amount of information in each context. Our hierarchical fusion encoder can dynamically fuse context in each time step in order to get the final contexts vector. The representation of fusion \(context_i\) is calculated as follows:
where \(W_{Con}\) represent the attention weights in context attention, \(h^{Fus}\) represents the final fusion retrieval vector.
Each fusion context vector should pass the GRU to get the final contexts representation. Figure 2 shows fusion information is auto-regressive and gets the final time step representation. Then we concatenate contexts representation and current turn representation. The response representation is similar to context, each word can be seen as the context in contexts, and get the fusion representation as to the decoder input.

Context hierarchical fusion encoder.
3.4 Decoder
Finally, the values in the encoder and the decoder are jointly trained. At this time, we combine the fused contexts vectors and current turn vectors together and sent them into the decoder. The context response attention can be expressed by the following equation:
where \(h_{Con}^{Fus}\) represents the hierarchical fusion of contexts and current turn, \(h_{Res}\) represents response vector. Given an input response: \(Response=\{y_1,y_2,\dots ,y_m\}\), the likelihood of the corresponding response sequence is:
After passing the context and response attention, we can generate words of response through softmax:
4 Experiment
4.1 Datasets
We use the Ubuntu community multi-turn dialogue dataset [11] and Daily dialogue dataset [8] to evaluate the performance of our proposed model. We use the official script to mark positive sample training.
4.2 Baselines
Seq2Seq: Sequence to sequence model with attention mechanism [18]. HRED: Hierarchical Recurrent Encoder-Decoder [14]. Using this method, multiple dialogue turns are modeled separately. VHRED: VHRED is a variant of HRED. In order to increase robustness, implicit variable information is added [15]. ReCoSa: Relevant context with self-attention [25]. Use long distance attention method can capture important word information. STAR-BTM: Multi-turn dialogue generation integrate the topic information [24]. CHG: Utilizing historical dialogue representation learning and historical dialogue selection mechanism [26]. HSAN: A hierarchicalself-attention network, which attends to find the important words and utterances in context simultaneously [5].
4.3 Experiment Settings
In order to make a fair comparison between all baseline methods, the hidden layer size is set to 512, the batch size is set to 32 and8 heads attention is used. We use Pytorch to run all models on three Tesla T4 GPUs.
4.4 Human Evaluation
We randomly sampled 200 messages from the Ubuntu test set to conduct the human evaluation as it is extremely time-consuming. We recruit 5 evaluators to judge the response from three aspects [4].
-
Appropriateness: a response is logical and appropriate to its message.
-
Informativeness: a response has meaningful information relevant to its message.
-
Grammaticality: a response is fluent and grammatical.
4.5 Automatic Evaluation
We use perplexity [14], BLEU [22] and Dist-1, Dist-2 [7] to evaluate the diversity of our responses, where Dist-k is the number of different k-grams after normalization of the total number of words in the response.
We have done a lot of experiments on both datasets to verify the effectiveness of our retrieval model. In order to ensure the fairness and consistency of the baseline model, we conducted several groups of experiments, which are: comparison between our complete model (with retrieval information) and other baseline models without retrieval information (as shown in Table 3), in order to prove the importance of introducing semantic retrieval information; Comparison between our complete model (with retrieval information) and other baseline models with simple fusion retrieval information (as shown in Table 4), in order to ensure the fairness between our model and baseline model and prove the effectiveness of using hierarchical fusion encoder; A simple way to introduce retrieval information is to use the same semantic retrieval mechanism to find the most relevant retrieval sentence of the current turn and context attention features and directly spliced together. What’s more, we also conduct an ablation experiment on the Daily dialogue dataset (as shown in Table 5) to prove our hierarchical encoder is efficient. The KL gate is replaced by a simple attention.
5 Analysis
The different test results are shown in the table. We use two evaluation criteria, one is human evaluation, and the other is mainstream evaluation algorithms based on machine translation. Under the same dataset, the hierarchical fusion mechanism through KL gate improves the fusion degree of other information, which also shows that the performance of the model can be improved by fusing more information, and the semantic-based information retrieval can recall the most relevant candidates. This shows that the model can help improve the quality of the generated dialogue when more information is considered. The following is a detailed analysis.
The human evaluation focuses more on areas that are not covered by the automatic assessment. In the human evaluation in Table 2, our method has the highest average score in terms of appropriateness, informativeness, and grammaticality. This shows that after integrating the retrieved information, the model can capture more background context and generate richer responses. Due to the use of contextual turn level attention, the model has also achieved good results in maintaining the consistency of the context of the generated response. From Table 2, we find that the improvement of appropriateness is not large. When the model is generated, it has the limitation of retrieval candidate background context direction, which leads to the lack of syntax flexibility. It can be seen from the human evaluation table that our model performs very well at +2 on the index of informativeness, which shows that it is very effective to consider richer information. Compared with the CHG and STAR-BTM model, which merge additional information, we can find that using hierarchical fusion to retrieve information is more effective than historical information and topic information. Overall, there has been an improvement in all indicators.
In automatic evaluation, in order to prevent the influence of retrieval information on the performance of the model, we also add retrieval information to the other baseline. As shown in Table 3, our model has achieved good results on the PPL index and Dist of both datasets, we think this has a great relationship with the basis encoder and decoder architecture and the integration of the retrieved information. Besides, the quality of the sentences retrieved by semantic similarity is much better. Thanks to the powerful RoBERTa model, these sentences are more in line with the context, which is also helpful to the later experimental results. We conduct several experiments with ReCoSa method, but we can’t get the performance of the BLEU score like the ReCoSa paper, but other indicators we follow the paper. Dist index can measure the richness of response. On the richness index of response model, our model performs well, due to the fusion of more information, which makes the sentences generated by the model very rich. In Table 3, our HRG model performs well in all indicators. Compared with the HSAN, which uses hierarchical self-attention, our method uses turns attention is much better. In terms of the degree of additional information fusion, our hierarchical fusion model can dynamically measure the information difference according to the data distribution by KL divergence, and fuse according to the importance of different turns on two datasets.
As shown in Table 4, we also add semantic retrieval information to the baseline model, but only simply integrate the retrieval information. A simple way to introduce retrieval information is to use the same semantic retrieval mechanism to find the most relevant retrieval sentence of the current turn of information, and directly splice the vector obtained with the vector of the current turn. The results show that after the simple introduction of the retrieval module, all baseline models improve the performance of BLEU, which also proves that considering more information can improve the richness of the model. The performance of STAR-BTM+R model is improved after integrating the retrieval distribution, this shows that the semantic retrieval features roughly contain the implicit information of the latitude of the topic, and the retrieved sentence information is richer. What’s more, in the baseline models, using our separate method to split context makes the baseline models’ performance improve, this also shows that our split method is very effective. Maybe because we simply fuse the retrieval information, the PPL index has increased a little compared with other baseline models. Overall, all response’s quality of baseline model has a certain improvement, which proves the effectiveness of integrating retrieval background information. Besides, using our hierarchical fusion encoder is more effective than simply integrating method. Both automatic evaluation and human evaluation show that the context consistency of the conversation and the richness of the answers are improved after the retrieval information is added.
In our ablation experiment on daily dialogue dataset as shown in Table 5, we remove retrieval information and hierarchical encoder simultaneously, the results of different indicators are similar to ReCoSa method, but due to we use the turn of sentence embedding (TOS), our HRG model performs a little better, which shows the necessity of TOS embedding. After removing the KL gate and replacing it with a simple attention, we can see the experiment results improve a lot compared with the former ablation experiment, which shows that using KL gate can measure the difference between two distributions effectively.
6 Conclusion and Future Work
In this paper, we propose a novel hierarchical fusion encoder that combines the retrieved information in multi-turn of dialogue generation. We encode current turn and context information respectively and add turn of sentence embedding (TOS) to enhance the sentence level attention. Using hierarchical fusion encoder can effectively utilize retrieved historical information according to the different weights of context sentences. Experiments show the effectiveness of this method. In future research, we will explore how to introduce knowledge graph information or other external forms of knowledge into multi-turn dialogue generation.
References
Azzalini, F., Jin, S., Renzi, M., Tanca, L.: Blocking techniques for entity linkage: a semantics-based approach. Data Sci. Eng. 6(1), 20–38 (2021)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, vol. 1 (Long and Short Papers), pp. 4171–4186 (2019)
Hu, B., Lu, Z., Li, H., Chen, Q.: Convolutional neural network architectures for matching natural language sentences. In: Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, 8–13 December 13 2014, Montreal, Quebec, Canada, pp. 2042–2050 (2014)
Ke, P., Guan, J., Huang, M., Zhu, X.: Generating informative responses with controlled sentence function. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, pp. 1499–1508 (2018)
Kong, Y., Zhang, L., Ma, C., Cao, C.: Hsan: A hierarchical self-attention network for multi-turn dialogue generation. In: ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 7433–7437. IEEE (2021)
Li, C., Yang, C., Liu, B., Yuan, Y., Wang, G.: LRSC: learning representations for subspace clustering. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 8340–8348 (2021)
Li, J., Galley, M., Brockett, C., Gao, J., Dolan, B.: A diversity-promoting objective function for neural conversation models. In: NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics, pp. 110–119 (2016)
Li, Y., Su, H., Shen, X., Li, W., Cao, Z., Niu, S.: DailyDialog: a manually labelled multi-turn dialogue dataset. In: Proceedings of the Eighth International Joint Conference on Natural Language Processing, IJCNLP 2017, Taipei, Taiwan, November 27– December 1, 2017 - Volume 1: Long Papers, pp. 986–995 (2017)
Liang, Y., Meng, F., Zhang, Y., Chen, Y., Xu, J., Zhou, J.: Infusing multi-source knowledge with heterogeneous graph neural network for emotional conversation generation. In: Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, pp. 13343–13352 (2021)
Liu, Y., et al.: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019)
Lowe, R., Pow, N., Serban, I., Pineau, J.: The ubuntu dialogue corpus: a large dataset for research in unstructured multi-turn dialogue systems. In: Proceedings of the SIGDIAL 2015 Conference, The 16th Annual Meeting of the Special Interest Group on Discourse and Dialogue, pp. 285–294 (2015)
Oluwatobi, O., Mueller, E.: DLGNet,: a transformer-based model for dialogue response generation. In: Proceedings of the 2nd Workshop on Natural Language Processing for Conversational AI (2020)
Ritter, A., Cherry, C., Dolan, W.B.: Data-driven response generation in social media. In: Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, EMNLP 2011, pp. 583–593 (2011)
Serban, I., Sordoni, A., Bengio, Y., Courville, A., Pineau, J.: Building end-to-end dialogue systems using generative hierarchical neural network models. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 30 (2016)
Serban, I., et al.: A hierarchical latent variable encoder-decoder model for generating dialogues. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31 (2017)
Shang, L., Lu, Z., Li, H.: Neural responding machine for short-text conversation. In: Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics, ACL 2015, pp. 1577–1586 (2015)
Sordoni, A., Bengio, Y., Vahabi, H., Lioma, C., Grue Simonsen, J., Nie, J.Y.: A hierarchical recurrent encoder-decoder for generative context-aware query suggestion. In: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, pp. 553–562 (2015)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Advances in Neural Information Processing Systems, pp. 3104–3112. The MIT Press, London (2014)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems NIPS 2017, pp. 5998–6008 (2017)
Wang, H., Lu, Z., Li, H., Chen, E.: A dataset for research on short-text conversations. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pp. 935–945 (2013)
Wang, S., Jiang, J.: Learning natural language inference with LSTM. In: NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, June 12–17, 2016, pp. 1442–1451 (2016)
Xing, C., et al.: Topic aware neural response generation. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31 (2017)
Yan, R., Song, Y., Wu, H.: Learning to respond with deep neural networks for retrieval-based human-computer conversation system. In: Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, pp. 55–64 (2016)
Zhang, H., Lan, Y., Pang, L., Chen, H., Ding, Z., Yin, D.: Modeling topical relevance for multi-turn dialogue generation. In: Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI (2020)
Zhang, H., Lan, Y., Pang, L., Guo, J., Cheng, X.: ReCoSa: detecting the relevant contexts with self-attention for multi-turn dialogue generation. In: Proceedings of ACL 2019, vol. 1: Long Papers, pp. 3721–3730 (2019)
Zhang, W., et al.: Multi-turn dialogue generation in e-commerce platform with the context of historical dialogue. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pp. 1981–1990 (2020)
Zhao, X., Wu, W., Xu, C., Tao, C., Zhao, D., Yan, R.: Knowledge-grounded dialogue generation with pre-trained language models. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, 16–20 November 2020, pp. 3377–3390 (2020)
Zhu, Q., Cui, L., Zhang, W., Wei, F., Liu, T.: Retrieval-enhanced adversarial training for neural response generation. In: Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL, pp. 3763–3773 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Zhao, D., Liu, X., Ning, B., Liu, C. (2022). HRG: A Hybrid Retrieval and Generation Model in Multi-turn Dialogue. In: Bhattacharya, A., et al. Database Systems for Advanced Applications. DASFAA 2022. Lecture Notes in Computer Science, vol 13247. Springer, Cham. https://doi.org/10.1007/978-3-031-00129-1_12
Download citation
DOI: https://doi.org/10.1007/978-3-031-00129-1_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-00128-4
Online ISBN: 978-3-031-00129-1
eBook Packages: Computer ScienceComputer Science (R0)