
Abstract
We revisit the problem of large-scale bundle adjustment and propose a technique called Multidirectional Conjugate Gradients that accelerates the solution of the normal equation by up to 61%. The key idea is that we enlarge the search space of classical preconditioned conjugate gradients to include multiple search directions. As a consequence, the resulting algorithm requires fewer iterations, leading to a significant speedup of large-scale reconstruction, in particular for denser problems where traditional approaches notoriously struggle. We provide a number of experimental ablation studies revealing the robustness to variations in the hyper-parameters and the speedup as a function of problem density.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others
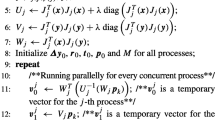


Keywords
1 Introduction
The classical challenge of image-based large scale reconstruction is witnessing renewed interest with the emergence of large-scale internet photo collections [2]. The computational bottleneck of 3D reconstruction and structure from motion methods is the problem of large-scale bundle adjustment (BA): Given a set of measured image feature locations and correspondences, BA aims to jointly estimate the 3D landmark positions and camera parameters by minimizing a non-linear least squares reprojection error. More specifically, the most time-consuming step is the solution of the normal equation in the popular Levenberg-Marquardt (LM) algorithm that is typically solved by Preconditioned Conjugate Gradients (PCG).
In this paper, we propose a new iterative solver for the normal equation that relies on the decomposable structure of the competitive block Jacobi preconditioner. Inspired by respective approaches in the domain-decomposition literature, we exploit the specificities of the Schur complement matrix to enlarge the search-space of the traditional PCG approach leading to what we call Multidirectional Conjugate Gradients (MCG). In particular our contributions are as follows:

(a) Optimized 3D reconstruction of a final BAL dataset with 1936 poses and more than five million observations. For this problem MCG is 39% faster than PCG and the overall BA resolution is 16% faster. (b) Optimized 3D reconstruction of Alamo dataset from 1dSfM with 571 poses and 900000 observations. For this problem MCG is 56% faster than PCG and the overall BA resolution is 22% faster.
-
We design an extension of the popular PCG by using local contributions of the poses to augment the space in which a solution is sought for.
-
We experimentally demonstrate the robustness of MCG with respect to the relevant hyper-parameters.
-
We evaluate MCG on a multitude of BA problems from BAL [1] and 1dSfM [20] datasets with different sizes and show that it is a promising alternative to PCG.
-
We experimentally confirm that the performance gain of our method increases with the density of the Schur complement matrix leading to a speedup for solving the normal equation of up to 61% (Fig. 1).
2 Related Work
Since we propose a way to solve medium to large-scale BA using a new iterative solver that enlarges the search-space of the traditional PCG, in the following we will review both scalable BA and recent CG literature.
Scalable Bundle Adjustment
A detailed survey of the theory and methods in BA literature can be found in [17]. Sparsity of the BA problem is commonly exploited with the Schur complement matrix [5]. As the performance of BA methods is closely linked to the resolution of the normal equations, speed up the solve step is a challenging task. Traditional direct solvers such as sparse or dense Cholesky factorization [11] have been outperformed by inexact solvers as the problem size increases and are therefore frequently replaced by Conjugate Gradients (CG) based methods [1, 6, 18]. As its convergence rate depends on the condition number of the linear system a preconditioner is used to correct ill-conditioned BA problems [14]. Several works tackle the design of performant preconditioners for BA: [9] proposed the band block diagonals of the Schur complement matrix, [10] exploited the strength of the coupling between two poses to construct cluster-Jacobi and block-tridiagonal preconditioners, [7] built on the combinatorial structure of BA. However, despite these advances in the design of preconditioners, the iterative solver itself has rarely been challenged.
(Multi-preconditioned) Conjugate Gradients
Although CG has been a popular iterative solver for decades [8] there exist some interesting recent innovations, e.g. flexible methods with a preconditioner that changes throughout the iteration [13]. The case of a preconditioner that can be decomposed into a sum of preconditioners has been exploited by using Multi-Preconditioned Conjugate Gradients (MPCG) [4]. Unfortunately, with increasing system size MPCG rapidly becomes inefficient. As a remedy, Adaptive Multi-Preconditioned Conjugate Gradients have recently been proposed [3, 15]. This approach is particularly well adapted for domain-decomposable problems [12]. While decomposition of the reduced camera system in BA has already been tackled e.g. with stochastic clusters in [19], to our knowledge the decomposition inside the iterative solver has never been explored. As we will show in the following, this modification gives rise to a significant boost in performance.
3 Bundle Adjustment and Multidirectional Conjugate Gradients
We consider the general form of bundle adjustment with \(n_{p}\) poses and \(n_{l}\) landmarks. Let x be the state vector containing all the optimization variables. It is divided into a pose part \(x_{p}\) of length \(d_{p}n_{p}\) containing extrinsic and eventually intrinsic camera parameters for all poses (generally \(d_{p}=6\) if only extrinsic parameters are unknown and \(d_{p}=9\) if intrinsic parameters also need to be estimated) and a landmark part \(x_{l}\) of length \(3n_{l}\) containing the 3D coordinates of all landmarks. Let \(r\left( x\right) =[r_{1}\left( x\right) ,...,r_{k}\left( x\right) ]\) be the vector of residuals for a 3D reconstruction. The objective is to minimize the sum of squared residuals
3.1 Least Squares Problem and Schur Complement
This minimization problem is usually solved with the Levenberg Marquardt algorithm, which is based on the first-order Taylor approximation of \(r\left( x\right) \) around the current state estimate \(x^{0}=\left( x_{p}^{0},x_{l}^{0}\right) \):
where
and J is the Jacobian of r that is decomposed into a pose part \(J_{p}\) and a landmark part \(J_{l}\). An added regularization term that improves convergence gives the damped linear least squares problem
with \(\lambda \) a damping coefficient and \(D_{p}\) and \(D_{c}\) diagonal damping matrices for pose and landmark variables. This damped problem leads to the corresponding normal equation
where
As the system matrix H is of size \(\left( d_{p}n_{p}+3n_{l}\right) ^{2}\) and tends to be excessively costly for large-scale problems [1], it is common to reduce it by using the Schur complement trick and forming the reduced camera system
with
and then solving (13) for \(\varDelta x_{p}\) and backsubstituting \(\varDelta x_{p}\) in
3.2 Multidirectional Conjugate Gradients
Direct methods such as Cholesky decomposition [17] have been studied for solving (13) for small-size problems, but this approach implies a high computational cost whenever problems become too large.
A very popular iterative solver for large symmetric positive-definite system is the CG algorithm [16]. Since its convergence rate depends on the distribution of eigenvalues of S it is common to replace (13) by a preconditioned system. Given a preconditioner M the preconditioned linear system associated to
is
and the resulting algorithm is called Preconditioned Conjugate Gradients (PCG) (see Algorithm 1). For block structured matrices as S a competitive preconditioner is the block diagonal matrix \(D\left( S\right) \), also called block Jacobi preconditioner [1]. It is composed of the block diagonal elements of S. Since the block \(S_{mj}\) of S is nonzero if and only if cameras m and j share at least one common point, each diagonal block depends on a unique pose and is applied to the part of conjugate gradients residual \(r_{i}^{j}\) that is associated to this pose. The motivation of this section is to enlarge the conjugate gradients search space by using several local contributions instead of a unique global contribution.

Adaptive Multidirections

(a) Block-Jacobi preconditioner \(D\left( S\right) \) is divided into N submatrices \(D_{p}\left( S\right) \) and each of them is directly applied to the associated block-row \(r^{p}\) in the CG residual. (b) Up to a \(\tau \)-test the search-space is enlarged. Each iteration provides N times more search-directions than PCG.
Local Preconditioners. We propose to decompose the set of poses into N subsets of sizes \(l_{1},\ldots , l_{N}\) and to take into consideration the block-diagonal matrix \(D_{p}\left( S\right) \) of the block-jacobi preconditioner and the associated residual \(r^{p}\) that correspond to the \(l_{p}\) poses of subset p (see Fig. 2(a)). All direct solves are performed inside these subsets and not in the global set. Each local solve is treated as a separate preconditioned equation and provides a unique search-direction. Consequently the conjugate vectors \(Z_{i+1}\in \mathbb {R}^{d_{p}n_{p}}\) in the preconditioned conjugate gradients (line 10 in Algorithm 1) are now replaced by conjugate matrices \(Z_{i+1}\in \mathbb {R}^{d_{p}n_{p}\times N}\) whose each column corresponds to a local preconditioned solve. The search-space is then significantly enlarged: N search directions are generated at each inner iteration instead of only one. An important drawback is that matrix-vector products are replaced by matrix-matrix products which can lead to a significant additional cost. A trade-off between convergence improvement and computational cost needs to be designed.

Adaptive \(\tau \)-Test. Following a similar approach as in [15] we propose to use an adaptive multidirectional conjugate gradients algorithm (MCG, see Algorithm 2) that adapts automatically if the convergence is too slow. Given a threshold \(\tau \in \mathbb {R}^{+}\) chosen by the user, a \(\tau \)-test determines whether the algorithm sufficiently reduces the error (case \(t_{i}>\tau \)) or not (case \(t_{i}<\tau \)). In the first case a global block Jacobi preconditioner is used and the algorithm performs a step of PCG; in the second case local block Jacobi preconditioners are used and the search-space is enlarged (see Fig. 2(b)).
Optimized Implementation. Besides matrix-matrix products two other changes appear. Firstly an \(N\times N\) matrix \(\varDelta _{i}\) must be inverted (or pseudo-inverted if \(\varDelta _{i}\) is not full-rank) each time \(t_{i}<\tau \) (line 4 in Algorithm 2). Secondly a full reorthogonalization is now necessary (line 16 in Algorithm 2) because of numerical errors while \(\beta _{i,j}=0\) as soon as \(i\ne j\) in PCG.
To improve the efficiency of MCG we do not directly apply S to \(P_{i}\) (line 3 in Algorithm 2) when the search-space is enlarged. By construction the block \(S_{kj}\) is nonzero if and only if cameras k and j observe at least one common point. The trick is to use the construction of \(Z_{i}\) and to directly apply the non-zero blocks \(S_{jk}\), i.e. consider only poses j observing a common point with k, to the column in \(Z_{i}\) associated to the subset containing pose k and then to compute
To get \(t_{i}\) we need to use a global solve (line 10 in Algorithm 2). As the local block Jacobi preconditioners \(\{D_{p}(S)\}_{p=1,...,N}\) and the global block Jacobi preconditioner \(D\left( S\right) \) share the same blocks it is not necessary to derive all local solves to construct the conjugates matrix (line 12 in Algorithm 2); instead it is more efficient to fill this matrix with block-row elements of the preconditioned residual \(D\left( S\right) ^{-1}r_{i+1}\).
As the behaviour of CG residuals is a priori unknown the best decomposition is not obvious. We decompose the set of poses into \(N-1\) subsets of same size and the last subset is filled by the few remaining poses. This structure presents the practical advantage to be very easily fashionable and the parallelizable block operations are balanced.
4 Experimental Evaluations
4.1 Algorithm and Datasets
Levenberg-Marquardt (LM) Loop. Starting with damped parameter \(10^{-4}\) we update \(\lambda \) according to the success or failure of the LM loop. Our implementation runs for at most 25 iterations, terminating early if a relative function tolerance of \(10^{-6}\) is reached. Our evaluation is built on the LM loop implemented in [19] and we also estimate intrinsics parameters for each pose.
Iterative Solver Step. For a direct performance comparison we implement our own MCG and PCG solvers in C++ by using Eigen 3.3 library. All row-major-sparse matrix-vector and matrix-matrix products are multi-threaded by using 4 cores. The tolerance \(\epsilon \) and the maximum number of iterations are set to \(10^{-6}\) and 1000 respectively. Pseudo-inversion is derived with the pseudo-inverse function from Eigen.
Datasets. For our evaluation we use 9 datasets with different sizes and heterogeneous Schur complement matrix densities d from BAL [1] and 1dSfM [20] datasets (see Table 1). The values of N and \(\tau \) are arbitrarily chosen and the robustness of our algorithm to these parameters is discussed in the next subsection.
We run experiments on MacOS 11.2 with Intel Core i5 and 4 cores at 2 GHz.
4.2 Sensitivity with \(\tau \) and N
In this subsection we are interested in the solver runtime ratio that is defined as \(\frac{t_{MCG}}{t_{PCG}}\) where \(t_{MCG}\) (resp. \(t_{PCG}\)) is the total runtime to solve all the linear systems (12) with MCG (resp. PCG) until a given BA problem converges. We investigate the influence of \(\tau \) and N on this ratio.
Sensitivity with \(\tau \). We solve BA problem for different values of \(\tau \) and for a fixed number of subsets N given in Table 1. For each problem a wide range of values supplies a good trade-off between the augmented search-space and the additional computational cost (see Fig. 3). Although the choice of \(\tau \) is crucial it does not require a high accuracy. That confirms the tractability of our solver with \(\tau \).

Robustness to \(\tau \). The plots show the performance ratio as a function of \(\tau \) for a number of subsets given in Table 1. The wide range of values that give similar performance confirms the tractability of MCG with \(\tau \).
Sensitivity with N. Similarly we solve BA problem for different values of N and for a fixed \(\tau \) given in Table 1. For each problem a wide range of values supplies a good trade-off between the augmented search-space and the additional computational cost (see Fig. 4). That confirms the tractability of our solver with N.

Robustness to the number of subsets N. The plots show the performance ratio as a function of N for \(\tau \) given in Table 1. The wide range of values that give similar performance confirms the tractability of MCG with N.

Density effect on the relative performance. Each point represents a BA problem from Table 1 and d is the density of the Schur complement matrix. Our solver competes PCG for sparse Schur matrix and leads to a significant speed-up for dense Schur matrix.
4.3 Density Effect
As the performance of PCG and MCG depends on matrix-vector product and matrix-matrix product respectively we expect a correlation with the density of the Schur matrix. Figure 5 investigates this intuition: MCG greatly outperforms PCG for dense Schur matrix and is competitive for sparse Schur matrix.
4.4 Global Performance
Figures 6 and 7 present the total runtime with respect to the number of BA iterations for each problem and the convergence plots of total BA cost for F-1936 and Alamo datasets, respectively. MCG and PCG give the same error at each BA iteration but the first one is more efficient in terms of runtime. Table 2 summarizes our results and highlights the great performance of MCG for dense Schur matrices. In the best case BA resolution is more than \(20\%\) faster than using PCG. Even for sparser matrices MCG competes PCG: in the worst case MCG presents similar results as PCG. If we restrict our comparison to the linear system solve steps our relative results are even better: MCG is up to \(60\%\) faster than PCG and presents similar results as PCG in the worst case.

Global runtime to solve BA problem. The plots represent the total time with respect to the number of BA iterations. For almost all problems the BA resolution with MCG (orange) is significantly faster than PCG (blue). (Color figure online)

Convergence plots of (a) Final-1936 from BAL dataset and (b) Alamo from 1dSfm dataset. The y-axes show the total BA cost.
5 Conclusion
We propose a novel iterative solver that accelerates the solution of the normal equation for large-scale BA problems. The proposed approach generalizes the traditional preconditioned conjugate gradients algorithm by enlarging its search-space leading to a convergence in much fewer iterations. Experimental validation on a multitude of large scale BA problems confirms a significant speedup in solving the normal equation of up to 61%, especially for dense Schur matrices where baseline techniques notoriously struggle. Moreover, detailed ablation studies demonstrate the robustness to variations in the hyper-parameters and increasing speedup as a function of the problem density.
References
Agarwal, S., Snavely, N., Seitz, S.M., Szeliski, R.: Bundle adjustment in the large. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010. LNCS, vol. 6312, pp. 29–42. Springer, Heidelberg (2010). https://doi.org/10.1007/978-3-642-15552-9_3
Agarwal, S., Snavely, N., Simon, I., Seitz, S.M., Szeliski, R.: Building Rome in a day. In: International Conference on Computer Vision (ICCV) (2009)
Bovet, C., Parret-Fréaud, A., Spillane, N., Gosselet, P.: Adaptive multipreconditioned FETI: scalability results and robustness assessment. Comput. Struct. 193, 1–20 (2017)
Bridson, R., Greif, C.: A multipreconditioned conjugate gradient algorithm. SIAM J. Matrix Anal. Appl. 27(4), 1056–1068 (2006). (electronic)
Brown, D.C.: A solution to the general problem of multiple station analytical stereo triangulation. RCA-MTP data reduction technical report no. 43 (or AFMTC TR 58–8), Patrick Airforce Base, Florida (1958)
Byrod, M., Aström, K., Lund, S.: Bundle adjustment using conjugate gradients with multiscale preconditioning. In: BMVC (2009)
Dellaert, F., Carlson, J., Ila, V., Ni, K., Thorpe, C.E.: Subgraph-preconditioned conjugate gradients for large scale slam. In: IROS, pp. 2566–2571 (2010)
Hestenes, M.R., Stiefel, E.: Methods of conjugate gradients for solving linear systems. J. Res. Nat. Bur. Standards 49(409–436), 1952 (1953)
Jeong, Y., Nister, D., Steedly, D., Szeliski, R., Kweon, I.-S.: Pushing the envelope of modern methods for bundle adjustment. In: CVPR, pp. 1474–1481 (2010)
Kushal, A., Agarwal, S.: Visibility based preconditioning for bundle adjustment. In: CVPR (2012)
Lourakis, M., Argyros, A.: Is Levenberg-Marquardt the most efficient optimization algorithm for implementing bundle adjustment. In: International Conference on Computer Vision (ICCV), pp. 1526–1531 (2005)
Mandel, J.: Balancing domain decomposition. Comm. Numer. Methods Eng. 9(3), 233–241 (1993)
Notay, Y.: Flexible conjugate gradients. SIAM J. Sci. Comput. 22(4), 1444–1460 (2000)
Saad, Y.: Iterative Methods for Sparse Linear Systems. SIAM, PHiladelphia (2003)
Spillane, N.: An adaptive multipreconditioned conjugate gradient algorithm. SIAM J. Sci. Comput. 38(3), A1896–A1918 (2016)
Trefethen, L., Bau, D.: Numerical Linear Algebra. SIAM, Philadelphia (1997)
Triggs, B., McLauchlan, P.F., Hartley, R.I., Fitzgibbon, A.W.: Bundle adjustment — a modern synthesis. In: Triggs, B., Zisserman, A., Szeliski, R. (eds.) IWVA 1999. LNCS, vol. 1883, pp. 298–372. Springer, Heidelberg (2000). https://doi.org/10.1007/3-540-44480-7_21
Wu, C., Agarwal, S., Curless, B., Seitz, S.: Multicore bundle adjustment. In: CVPR, pp. 3057–3064 (2011)
Zhou, L., et al.: Stochastic bundle adjustment for efficient and scalable 3D reconstruction. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12360, pp. 364–379. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58555-6_22
Wilson, K., Snavely, N.: Robust global translations with 1DSfM. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8691, pp. 61–75. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10578-9_5
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Weber, S., Demmel, N., Cremers, D. (2021). Multidirectional Conjugate Gradients for Scalable Bundle Adjustment. In: Bauckhage, C., Gall, J., Schwing, A. (eds) Pattern Recognition. DAGM GCPR 2021. Lecture Notes in Computer Science(), vol 13024. Springer, Cham. https://doi.org/10.1007/978-3-030-92659-5_46
Download citation
DOI: https://doi.org/10.1007/978-3-030-92659-5_46
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-92658-8
Online ISBN: 978-3-030-92659-5
eBook Packages: Computer ScienceComputer Science (R0)