
Abstract
Multi-focus image fusion plays an important role in the field of image processing for its ability in solving the depth-of-focus limitation problem in optical lens imaging by fusing a series of partially focused images of the same scene. The improvements on various fusion methods focus on the image decomposition methods and the fusion strategies. However, most decompositions are separately conducted on each image, which fails to sufficiently consider the nature of multiple images in fusion tasks, and insufficiently explores the consistent and inconsistent features of two source images simultaneously. This paper proposes a new cooperative image multiscale decomposition (CIMD) based on the mutually guided filter (MGF). With CIMD, two source multi-focus images are simultaneously decomposed into base layers and detailed layers through the iterative operation of MGF cooperatively. A saliency detection based on a mean-guide combination filter is adopted to guide the fusion of detailed layers and a spatial frequency-based fusion strategy is used to fuse the luminance and contour features in the base layers. The experiments are carried on 28 pairs of publicly available multi-focus images. The fusion results are compared with 7 state-of-the-art multi-focus image fusion methods. Experimental results show that the proposed method has the better visual quality and objective assessment.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Multi-focus image fusion
- Depth-of-focus
- Mutually-guided filter
- Cooperative image multiscale decomposition
- Focus region detection
1 Introduction
Optical imaging has the limitation of the depth-of-focus, which makes it difficult to obtain an all-in-focus image with conventional digital cameras. The multi-focus image fusion technology which obtains an all-in-focus image by merging multiple optical images has an important practical significance. The fused images are widely used in the fields of human vision, computer vision, artificial intelligence, and so on.
According to the feature domains where the source images are fused, image fusion methods are roughly divided into two main categories, namely, spatial domain methods and transform domain methods. Spatial domain methods usually investigate the saliency information of pixels or regions to establish the fusion. Some of them are based on total variation, gradient optimization [4]. This type of methods is efficient. However, there may be artifacts and distortions in the fused image. Transform domain approaches are consist of three steps, namely, decomposition, coefficient fusion, and reconstruction [1]. Pyramid transform [5][6], wavelet transform, and contourlet transform are commonly used to decompose the source images into different feature coefficients. These transform methods offer not only higher efficiencies but also offer greater flexibility to the fusion strategy design. The sparse representation [7] also attracts numerous researchers in image fusion applications due to its effective capability in underlying information extraction from an image. In recent years, deep learning has also been introduced to achieve multi-focus image fusion because of its potential in deep feature extraction [9].
Existing multiscale transforms have made various improvements in image fusion rules and image multiscale decomposition for resolving the problem of saliency detection and improving the fusion effect. Whereas the traditional multiscale decompositions do not sufficiently separate the consistent structure and inconsistent structure in the two images to be fused that have gradient amplitude differences. In this paper, we present a new fusion method based on the proposed cooperative image multiscale decomposition (CIMD). The CIMD is used to separate the consistent structure and the inconsistent structure in two images by the CIMD. With CIMD, two source images are decomposed into detailed layers and base layers cooperatively. The detailed layers which contain the inconsistent gradient structure of two source images are very helpful in adjusting the local clarity of two source images. Therefore, a saliency detection-based fusion rules are used to fusion the detailed layers that contain the inconsistent structure, and spatial frequency-based fusion rules are used to integrate the base layers. Finally, the fused base layers and detailed layers are merged together to obtain the final fused image. 28 pairs of publicly available multi-focus images are used to test the performances of the proposed method. The experimental results demonstrate that the proposed image fusion method demonstrates versatility across multiple types of multi-focus images.
The rest of this paper is organized as follows. we construct the CIMD-based MGF in Sect. 2. Sect. 3 describes the proposed image fusion algorithm in detail. The experiment results and discussions are presented in Sect. 4, and conclusions are given in Sect. 5.
2 Cooperative Image Multiscale Decomposition Based MGF
2.1 Mutually Guided Filter
Shen et al. [3] divided the mutual-structures of two input images into three types, including mutual structure, flat structure, and inconsistent structure. The mutual structure describes the part with both strong gradient structures, while the flat structure references the part of the consistent weak gradient structure. The two structures are collectively referred to as the consistent structure in this paper. The inconsistent structure represents the structure with divergence gradient amplitudes in two images at the same pixel position. The inconsistent structure would be vital for multi-focus image fusion applications. However traditional guide filter ignores the structural inconsistency when we need to filter two content correlative images simultaneously. To solve these problems, a mutually guided filter is proposed for the purpose to preserve the mutual structure, prevent misleading from inconsistent structure, and smooth flat regions between two input images [2]. Let \({\mathrm{T}}_{0}\) and \({\mathrm{R}}_{0}\) denote two input images that should be filtered simultaneously. The filtered outputs \(\mathrm{T}\) and \(\mathrm{R}\) from the MGF are obtained by:
where
represents the mutual structure discrimination indicated by the gradient ratio between two images. The symbol \(\Omega\) represents the pixel sets of the source images. \({\mathrm{\rm T}}_{i}\) and \({\mathrm{R}}_{\mathrm{i}}\) indicate the pixel values at \(i\) position. The symbol \(\upvarepsilon \) is a small positive constant to avoid division by zero. \({\nabla }_{\mathrm{h}}\) and \({\nabla }_{\mathrm{r}}\) are the horizontal and vertical derivative operators respectively. The first term in Eq. (1) is the regularization term which is the consistent structure restraint aiming to reduce the gradient discrepancy between two images to be filtered. The second and third terms are the fidelity term. The parameter \(\alpha \) is regularization parameter given by the users.
From Eq. (1), we can easily deduce that the mutual structure and flat structure from two filter outputs toward identical. Figure 1 (a) shows two images obtained with different focus settings. The upper image shows rich texture in the left area while the bottom one focuses on the right area. Figure 1 (b), (c), and (d) illustrate filters employed by the mean filter, the guide filter [12], and MGF, respectively. All filter results are blurred in different various degrees. However, only the two outputs of MGF still maintain the consistent gradient structure. It demonstrates that MGF can preserve the contour information of multi-focus images.
2.2 Cooperative Image Multiscale Decomposition
It is known that a good decomposition method should separate the useful information, such as contour, texture, and structure information into the different sub-band images. MGF is a novel edge-preserving filter that offered an effective way of preserving the mutual structure and flat structure. The inconsistent structure that exhibits divergence gradient amplitudes between two source images is filtered out. For multi-focus image fusion, the inconsistent gradient structure is very helpful in adjusting the clarity of two source images. In this paper, the CIMD based on MGF is proposed for multi-focus image fusion. The CIMD can separate the inconsistent structure represented by texture information.
The CIMD is achieved by

source multi-focus images; (b) Output from mean filter; (c) Output from guide filter; (d) Output from MGF.
Two multi-focus images and the output results with different filters. (a) The
where \({I}_{t}\) and \({I}_{r}\) represent two source multi-focus images; \({B}_{t}\) and \({B}_{r}\) are the base layers of the multi-focus images; \({D}_{t}\) and \({D}_{r}\) represent the detailed layers. The base layers are simultaneously obtained by the mutually guided filter with two source images being employed collaborative references. The base layers contain the consistent structure such as contour, brightness, and part of details of the source images. While the detailed layers obtained by subtracting base layers from the source images show the gradient discrepancy components of the source images.
Figure 2 shows an example of the CIMD on multi-focus images. In Fig. 2, the consistent structure such as the contour features of the source images is extracted separately into the base layers, while the inconsistent structure which shows local clarity of the source images is preserved in the detailed layers. Thus, the different amplitudes of inconsistent information can accurately discriminate the focus area of the source images. In addition, the separation property of consistent structure and inconsistent structure can effectively reduce the artifacts in the fused results.

Cooperative image multiscale decomposition on multi-focus images.
3 Image Fusion with CIMD
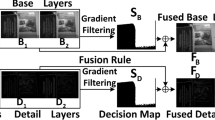
The schematic diagram of the proposed fusion strategy is illustrated in Fig. 3. Firstly, two multi-focus images are divided into the base layers and the detailed layers based on CIMD simultaneously. Then, the fused base layers and detailed layers are obtained by weight average fusion rules. Finally, the final fused image is a superimposition of the fused base and detailed layers.
3.1 Base Layers Fusion
Base layers images filtered by CMID preserve the consistent gradient structure of the source images. However, the consistent structure does not guarantee identical local intensity or other image features in different source images. In particular, the difference between the two base layer images manifests as weak amplitude differences, and the weak amplitude differences can be measured by the local spatial frequency (LSF). Therefore, the difference in the LSF value can be implemented to discriminate the regions of interest. This paper adopts the LSF-based fusion rule to measure the blurred features of base layers images.
The LSF of a certain sub-band image \(B\) obtained by
where
where \(B(i,j)\) is the pixel value at position \((i,j)\).
With Eq. (6), \({LSF}_{t}\) and \({LSF}_{r}\) of the base layers \({B}_{t}\) and \({B}_{r}\) are obtained respectively. Then the fusion weighted map \(\overline{m }\) for \({B}_{t}\) and \({B}_{r}\) is constructed as
where \(TH\) is a predetermined threshold. To reduce the artifacts in the fused image, a threshold parameter is defined to restrict that the arithmetic mean fusion rule is used when the value of LSF difference between two images less than \(TH\). In this paper, we set \(TH=0.001\) empirically. Furthermore, the guide filter defined in [12] is used to refined the weighted map as.

Schematic diagram of the proposed algorithm.
The base image \({B}_{t}\) is served as the guided image.
Finally, the fused image \({B}_{F}\) is obtained by
3.2 Detailed Layers Fusion
The inconsistent structure such as texture information of multi-focused images determines the clarity of the fused image. A good fused result should contain all the inconsistent structure in images obtained by different focus sets. The detailed image filtered by CIMD preserves most of the inconsistent structure such as texture features in multi-focused images. Therefore, a weighted fusion rule based on saliency detection is proposed for distinguishing the saliency of inconsistent structure in detailed layers.
The saliency information map \(\overline{D }\) of a certain sub-band image \(D\) is obtained by the mean-guide filter as
where \({f}_{m}\) is a 7 × 7 mean filter operator and \(\left|\right|\ {\rm represents}\) the absolute operator. The \(*\) denotes the convolution operation. Furthermore, in order to enhance regional consistency of the map, the features saliency \(\overline{D }\) are obtained by the guide filter.
With Eq. (12) and Eq. (13), the features saliency information maps \({\overline{D} }_{t}\) and \({\overline{D} }_{r}\) of the sub-band images \({D}_{t}\) and \({D}_{r}\) are obtained. The initial weight map \(\overline{m }\) is determined by
Furthermore, to reduce artifacts or halos caused by unaligned source images or detection of edge misalignment problems, the optimized weight map \(m\) is obtained by
The fused detailed layers \({D}_{F}\) is obtained by
3.3 Reconstruction
Finally, the fused image is constructed by
4 Experiment
4.1 Experiment Setup
28 pairs of publicly available multi-focus images are selected to test the proposed method. 22 pairs of images are collected from the Lytro multi-focus image dataset created by Nejati et al. in [13]. The remaining 6 pairs are collected from the website [14]. All of the source images are gray images. Figure 4 shows ten pairs of multi-focus images in the experiment dataset. All the experiments are implemented on a laptop equipped with an Intel(R) Core(TM) i5–10400 CPU (2.90GHz) and NVIDIA GeForce RTX 2070 GPU with 16GB RAM. And the software environment is MATLAB R2018b installed on Win 10 64-bit operating system.
To demonstrate the fusion effectiveness of the proposed algorithm, we quantitative compare the proposed method with 7 state-of-the-art image fusion algorithms, including guided filtering fusion (GFF) [5], sparse representation (SR) [7], gradient transfer fusion (GTF) [4], guided filter-based image detection fusion (GFDF) [6], multi-scale structural image decomposition (MSID) [10], Laplacian re-decomposition (LRD) [11], and residual neural network analysis image fusion (ResNet) [9]. For SR, we use the MST-SR-Fusion-Toolbox provided by Liu et al. [8]. The remaining algorithms are implemented based on publicly available codes provided by authors. For all methods, we use the optimal default parameters reported in the related publications.
To qualitatively analyze the effectiveness of different algorithms in terms of the perspective of visual effects, we select six evaluation metrics, including the gradient-based fusion performance QAB/F [15], the structural similarity-based metric QS [19], QC [17], QY [16], the human perception inspired metric QCB [20], the phase congruency-based metric QP [18].

Ten pairs of multi-focus images were selected from the experiment dataset.
4.2 Comparison to Classical Fusion Method
To evaluate the sensitivities of the key parameters in the proposed method, we experimentally studied the influence of parameters α, ε in Eq. (1) and Eq. (2). Figure 5 shows the fusion quality measures with different parameter settings. The fusion performances are evaluated by the average value of QAB/F, QS, QC, QY, QCB, and QP on 28 pairs source images. From Fig. 5(a)–(f), we can conclude that the performance of the proposed method is comprehensively optimal when the parameter α is in the range of [0.05 0.1] and the parameter ε is in the range of [0.01 0.02]. Moreover, we can see from Fig. 5(a) when the parameter ε is larger than 0.01, the fused results are all of the good quality. Figure 5(f) shows that the fused results are all of the lower quality when the parameter ε = 0.01 and the parameter α = 0.1. In the following experiments, the parameters are set as α = 0.05 and ε = 0.01.

Influence of parameters α and ε. (a)–(f) are the results of QAB/F, QY, QC, QP, QS, and QCB.
Figure 6 shows an example of the fused images of different methods on the face image. The label regions by the blue rectangle are magnified and shown in the lower-left corner of each image. As shown in Fig. 6(a) and (h), the hair and skin texture of the edge area are completely preserved. SR and ResNet in Fig. 6(b) and (e) preserve partial texture
(f)GFDF (g)ResNet (h)MSID (i)LRD (j)Ours.

source images. (c)–(j) are the fusion results of GFF, SR, GTF, GFDF, ResNet, MSID, LRD, and the proposed method.
Fusion results of the proposed and compared methods on the face image: (a) and (b) are the
information of the source image, but the texture of the skin disappear. Figure 6(c) generated by GTF suffers from edge clutter and texture loss. Moreover, there is a global blurring in Fig. 6(c). The edge information of hair is lost in Fig. 6(d), but the skin texture is preserved well. The person is shown in Fig. 6(f) is blurred. Figure 6(g) from LRD fails to handle white balance around the edge of the eyeglass border. The characters on the temple are overexposed caused distortions and contrast decreased surrounding pixels. As seen in Fig. 6(h), the fused image of the proposed algorithm preserves all texture details of surface skin and no blur in the fused image.
Figure 7 shows another example of fusion results of the proposed and compared methods on the game machine image. There are apparent distortions and regional blurring in the gamepads areas of the GFF in Fig. 7(a). Artifacts are visible around the wires in the green rectangle area and the buttons in the blue rectangle area in the final result generated by SR in Fig. 7(b). The GTF in Fig. 7(c) has some blurring of the whole picture due to the lack of accurate focused regions detection, especially the gamepads where there is also brightness distortion. The corresponding shadow area of the gamepads in Fig. 7(d) and (f) is not completely preserved. The whole image generated by ResNet in Fig. 7(e) has over-exposure and blurring. The corresponding red rectangle area in Fig. 7(g) generated by the LRD is blurred, and the whole picture is noisy especially around the wires and the buttons. In contrast, our proposed method can obtain a better visibility effect.
The objective evaluation metrics of Fig. 6 and Fig. 7 are shown in Table 1. For each metric, the best performance result is labeled in bold. The underlined values indicate the second-largest values. Our method provides the highest QAB/F and QY for two experimental images. In addition, the QP and QS values of the proposed method are the best in Fig. 6. The QC and QCB values of the proposed method are the best in Fig. 7. The significant information in terms of gradient retention QAB/F, structural similarity QY, and image phase consistency QP are achieved maximum preservation in our algorithm. This is mainly attributable to the fact that the complete decomposition of the consistent structure and the inconsistent structure by CIMD and the appropriate fusion rules. In our experiment, the proposed method can effectively improve the evaluation of subjective effects and the advantage of objective metrics.

source images. (c)–(j) are the fusion results of GFF, SR, GTF, GFDF, ResNet, MSID, LRD, and the proposed method.
Fusion results of the proposed and compared methods game machine image: (a) and (b) are the
The average metric values and standard deviations on results of 28 pairs of source images with different methods are shown in Table 2. For each metric, the best performance result is labeled in bold, and the underlined values indicate the second-largest values. The smallest standard deviation is bolded and the second smallest is underlined. It can be seen that the proposed method is always the largest in the metrics of QAB/F, QY, QC, QP, and QS for all images, which means that the proposed can well preserve the original information of different sources images. QY and QCB have the smallest standard deviation. This means the proposed method is very stable in all experimental images.
5 Conclusions
In this paper, we have presented a novel multi-focus fusion method based on MGF. To my knowledge, the proposed method is the first to introduce CIMD into the field of image fusion to obtain the two-scale representation. Exploiting the separation feature of CIMD on the inconsistent structure, and purposely proposing a detailed layers fusion method based on the mean-guide filter and a base layers’ fusion method based on the spatial frequency. Finally, the fusion result was obtained by overlaying the fused detailed layers and the base layers. The experimental part compares 28 pairs of multifocal images of three different types and validates the experimental results in terms of both subjective visual evaluation and six sets of objective metrics. The proposed method can preserve more effective information and improving the effectiveness of multi-focus image fusion compared with seven state-of-the-art methods. New advancement of introducing dual channels on the image fusion framework is achieved.
References
Li, S., Kang, X., Fang, L., Hu, J.: Pixel-level image fusion: a survey of the state of the art. Inf. Fusion 33, 100–112 (2017)
Guo, X., Li, Y., Ma, J., Ling, H.: Mutually guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 42(3), 694–707 (2018)
Shen, X., Zhou, C., Xu, L., Jia, J.: Mutual-structure for joint filtering. In: ICCV, pp. 3406–3414. IEEE, Santiago (2015)
Ma, J., Chen, C., Li, C., Huang, J.: Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 31, 100–109 (2016)
Li, S., Kang, X., Hu, J.: Image fusion with guided filtering. IEEE Trans. Image Process. 22(7), 2864–2875 (2013)
Qiu, X., Li, M., Zhang, L., Yuan, X.: Guided filter-based multi-focus image fusion through focus region detection. Signal Process. Image Commun. 72, 35–46 (2016)
Yang, B., Li, S.: Multifocus image fusion and restoration with sparse representation. IEEE Trans. Instrument Measur. 59(4), 884–892 (2010)
Liu, Y., Liu, S., Wang, Z.: A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 24, 147–164 (2015)
Li, H., Wu, X.J., Durrani, T.S.: Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 102,103039 (2019)
Li, H., Qi, X., Xie, W.: Fast infrared and visible image fusion with structural decomposition. Knowl. Based Syst. 204, 106182 (2020).
Li, X., Guo, X., Han, P., Wang, X., Luo, T.: Laplacian re-decomposition for multimodal medical image fusion. Trans. Instrument Measur. 69(9), 6880–6890 (2020)
He, K., Sun, J., Tang, X.: Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 35(6), 1397–1409 (2013)
Nejati M, Lytro Multi-focus Dataset (2019). https://mansournejati.ece.iut.ac.ir/content/lytro-multi-focus-dataset. Accessed 6 Jan 2019
Pxleyes: Multi Focus Photography. http://www.pxleyes.com/photography-contest/19726. Accessed 20 Jan 2021
Xydeas, C.S., Petrovic, V.: Objective image fusion performance measure. Electron. Lett. 36(4), 308–309 (2000)
Yang, C., Zhang, J., Wang, X., Liu, X.: A novel similarity based quality metric for image fusion. Inf. Fusion 9, 156–160 (2008)
Cvejic, N., Loza, A., Bul, D., Canagarajah, N.: A similarity metric for assessment of image fusion algorithms. Int. J. Signal Process. 2(3), 178–182 (2005)
Zhao, J., Laganiere, R., Liu, Z.: Performance assessment of combinative pixel-level image fusion based on an absolute feature measurement. Int. J. Innov. Comput. Inf. Control 3(6), 1433–1447 (2007)
Piella, G., Heijmans, G.: A new quality metric for image fusion. In: Proceedings International Conference Image Processing, pp. 3–173. IEEE, Barcelona (2010)
Chen, Y., Blum, R.S.: A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 27(10), 1421–1432 (2009)
Acknowledgments
This paper is supported by the National Natural Science Foundation of China (No.61871210) and Chuanshan Talent Project of the University of South China.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Tan, Y., Yang, B. (2021). Multi-focus Image Fusion with Cooperative Image Multiscale Decomposition. In: Ma, H., et al. Pattern Recognition and Computer Vision. PRCV 2021. Lecture Notes in Computer Science(), vol 13021. Springer, Cham. https://doi.org/10.1007/978-3-030-88010-1_15
Download citation
DOI: https://doi.org/10.1007/978-3-030-88010-1_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-88009-5
Online ISBN: 978-3-030-88010-1
eBook Packages: Computer ScienceComputer Science (R0)