
Abstract
Choosing the best interaction modalities and protocols in Human-Robot Interaction (HRI) is far from being straightforward, as it strictly depends on the application domain, the tasks to be executed, the types of robots and sensors involved. In the last years, a growing number of HRI researchers exploited Virtual Reality (VR) as a mean to evaluate proposed solutions, focusing in particular on safety and correctness of collaborative tasks. This allows to prove the effectiveness and robustness of a certain approach in a simulated environment, thus permitting to converge more easily to the best solution, also avoiding to experiment potentially harmful actions in a real scenario. In this paper, we aim at reviewing existing VR based approaches targeting or embodying HRI.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Both technical and societal drivers are pushing a vision of robotics where machines work together with people [14], thus making the study of Human-Robot Interaction (HRI) fundamental. One of the prevalent forms this interaction happens if by having robots and humans collaborating together in executing a specific task, which is one of the key elements in recently developed systems. In particular, in such solutions, researches have proved that a joint effort of people and androids in a shared workspace, would significantly reduce the time of executing certain tasks, by improving the efficiency of the overall architecture [13]. In particular, robots can support and relieve human operators, enable versatile automation steps and increase productivity by combining human capabilities with the efficiency and precision of machines [20].
HRI can rely on single sensory channels such as hearing, sight, speech and gestures [38] or through the combination of two or more of them in order to obtain a more robust system [5]. Signals that are exchanged along these channels must be coherent, since a clear understanding of their meanings is resuired to enable communication [25] and to establish a more solid relationship between people and machines. Additionally, human safety is an aspect to be taken into account in robotics systems, in which human workers and androids need to share the same workspace with different degrees of proximity avoiding risks [39].
Development and validation of HRI solutions still lacks to a large extent fast and effective approaches, typically undergoing a long trial-and-error expensive cycle. Recently, Virtual Reality (VR) has been employed in variety of ways to replace preliminary validation of HRI approaches, which often requires hard to implement experimental settings where the interaction between humans and robots takes place [8]. Indeed, a VR environment may allow users to perform multiple evaluations in sequence by observing and manipulating virtual objects in a simulated immersive scenario. Hence, VR has the advantage to support the validation of costly solutions in a safe and cheap artificially replicated world [21]. Since the interaction between people and androids requires an in depth analysis of the communication modalities, type and position of sensors on the robot, human-machine distance and the application domain where the relationship will take place, a virtual world seems to be very suitable to conduct such tests.
Our goal is to adopt a VR environment to carry out the experimental activity planned in the CANOPIES project (see https://canopies.inf.uniroma3.it/), where the collaboration between humans and robots takes place in an agriculture scenario, for grape harvesting and branch pruning operations, with the aim of combining people and machines skills. In order to design and implement our collaborative framework, we look at the interaction from an agent communication perspective, which identifies different message types (speech acts) and characterizes their meaning to allow for a proper understanding of each other. Hence, we have investigated the literature in order to distinguish the VR solutions that have been proposed to support in manifold ways the exchange of information between humans and robots. While we are still trying to identify the basic principles to develop the aforementioned system, our analysis shows interesting findings in terms of the design space to be explored.
In this paper we aim at reviewing existing VR solutions targeting or embodying HRI. The remainder of this study is structured as follows: Sect. 2 provides a general view of the topic, while Sect. 3 presents a scheme for the examination of the literature that is centered on the notion of communication act and Sect. 4 elaborates on the interaction modalities that are associated with different types of speech acts. We conclude the paper with a discussion of the findings for exploring the design space of our application.
2 Related Works
In order to define a first taxonomy, we analyzed recent surveys in the area of HRI, focusing on works where VR is used for the evaluation purposes. In particular, we identified three studies targeting this topic from different points of view.
Authors in [8] classify papers according to the goal of the interaction. In particular, four main categories have been identified, namely operator support, simulation, instruction and manipulation.
Papers belonging to the operator support category focuses on interaction modalities helping operators in controlling predicting and monitoring robots’ actions through, for example, acoustic and visual feedback methods [4]. Moniri et al. [28] introduce an additional dimension to existing HRI scenarios, involving two participants in different physical locations: one shares the robot’s workspace to perform a collaborative task, while the other monitors the process of the area through a VR system. The necessity of increasing human safety awareness [33] and providing more information of the surrounding environment through the use of Augmented Reality (AR) are other relevant aspects that are emerging in some studies belonging to this category.
The simulation category explores solutions using simulation software to enhance the users’ understandability of the working ambient. In particular, the virtual space allows the human to interact either with a robot or with objects.
Papers in the instruction category focus on providing the human user with a hierarchy of tasks that are proposed in the virtual environment. Here, the distinction of the workspace in safe and dangerous zones is essential where the presence of both, humans and robots is a prerequisite. Virtual buttons, to confirm or change the next robot task, allow the user to exploit a gesture-based interaction by pointing with the finger to the desired instruction.
Finally, papers in the manipulation category focus on teleoperating and supervising robots remotely.
Authors of the survey [39] stress instead the importance of human safety as a critical factor when HRI is applied in collaborative environments, and provide an in depth analysis of safety aspects in systems involving a close collaboration with people. In particular, based on the existing articles on safety features that minimize the risk of HRI, provide a classification of the works into five main categories, i.e., robot perception for safe HRI, cognition enabled robot control in HRI, action planning for safe navigation close to humans, hardware safety features and societal and psychological factors.
Robot perception has a profound impact on safety aspects in Human-Robot Collaboration tasks. Human-in-the-loop systems are developed, for example, for human assistance provision through teleoperation. In this case, VR is used to test several abilities of the robots (e.g., the effectiveness of grasping strategies), or to teach the robot new skills for collaborative work. Vision-enabled methods play a key role in the perception-based safety approaches, in which real-time modeling of the operating workspace through accurate RGB-D and lidar sensors [11] allow fast robot planning, obstacle avoidance [27] and increase human presence understanding [19], leading to more predictable and safe robot behaviors [29].
Human aware robot navigation, actions prediction and recognition, together with the understanding of a shared workspace, are essential in the development of novel systems where collaboration between people and machines is required, thus allowing a safe human-robot coexistence. Human behavior understanding should be also integrated into robots’ navigation mechanisms [18] allowing, for example, to adapt action execution to velocity, speed and proximity distances [35].
Safe system degradation also plays an important role in HRI, since it can avoid uncomfortable situations in HRI tasks by informing the person about robots current abilities, while at the same time retaining fail-safe mechanisms.
Finally, in a recent survey [6], authors focus on AR instead of VR solutions. Despite this important difference, authors provide a list of application domains that are relevant to our case including manufacturing and assembly, pick and place, search and rescue, medical, space, and restaurants. Noticeably, agriculture is not covered by any of the analyzed papers.
Despite the availability of these recent surveys, at the best of our knowledge, there is no work that classifies studies of HRI performed in VR based on the information exchanged between humans and robots. For this reason, we propose an innovative way of analyzing the topic based on the speech act theory [15].

The identified taxonomy
3 Taxonomy of Content Information
A clear and exhaustive definition of the term speech act is provided by the philosopher Kent Bach, that explained this concept by saying that “almost any speech act is really the performance of several acts at once, distinguished by different aspects of the speaker’s intention: there is the act of saying something, what one does in saying it, such as requesting or promising, and how one is trying to affect one’s audience” [3]. Generally, such term identifies a set of classes differing according to the information exchanged in a Human-Human, Robot-Robot or, as in our case of study, HRI. Another relevant aspect is the selected interaction channel (e.g. voice, gesture, text, visual feedbacks, audio signals).
Our aim in this paper is to present a preliminary study in which two fundamental concepts are highlighted: what is the informative content exchanged and how the communication takes place in a virtual world. The first aspect is discussed in this section, whereas the second one is presented in Sect. 5.
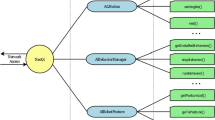
By reviewing papers concerning VR evaluation for HRI, we identified the following speech act categories: information, command, alert, request, instruction and greeting. In addition, a further subdivision, based on the specific message type, is performed as shown in Fig. 1.
Information is the most frequently adopted speech act, allowing to notify a teammate about: an intention [1, 23], the current activity, the measured distance from the target [23] or from the human [36], object properties [37] or trajectory [2]. Human presence (awareness of the person in the environment) is another relevant element considered in different studies [31], together with information about position with respect to an object [10, 22] or a teammate [32], current status [36] and achieved performance [26, 36].
An unidirectional speech act category, expressing the commands given by the human to the robot, is represented by the command speech act class, in which two sub-classes have been identified: motion, in which the android must reach a new position [22, 23], change its velocity, or stop its operation [7, 23], and action, that consists of performing specific activities, such as following a person [16, 32], picking up [7] or positioning an object [17].
A notification of a dangerous situation is a fundamental aspect that emerges from different works and for this reason, the alert speech act category is provided. Collision risk (higher probability of human-robot collision [31]), touch (the collision is verified, hence the person and the android are in contact [12]), error (about task execution), velocity (reduction or increase of robot’s speed [24]) and motion (change in machine’s motion trajectory [24]) belong to this classification.
Another relevant class, which has not to be confused with the already introduced command category, is request. The difference is straightforward: in the last case, the human is asking the teammate to perform a specific action [37], select an object [30] or provide information [22, 26], but the robot can refuse while, when a command is issued, the android must follow the person’s requirements.
A further unidirectional speech act class is represented by instructions, by which the machine provides instructions [9] or hand motion suggestions [24, 31] to be performed by the human worker to complete the assignment.
Finally, a category that emerges when interacting with social robots is greeting. In particular, the robot can welcome the user to increase human’s trust, which is fundamental in collaborative tasks [34].
4 Taxonomy of Delivery Modality
Starting from the aforementioned speech act categories and their classification based on the informative content, we devote this section to examine the modalities adopted in the analyzed articles for performing information exchange between humans and robots in virtual environments. The following discussion mainly concerns robot-human communication, but some categories can be employed also to allow the exchange of information from human to robot. In any case, we present the most relevant interaction channels for each speech act, together with an explanation of their use in the analyzed studies.
Voice and visual feedbacks are the preferred interaction channels for the information category. The first modality is exploited, for example, by a social robot tour guide in the virtual museum, with the aim of showing and talking about existing artworks of the Metropolitan Museum of Art of New York [37]. Moreover, vocal communication allows the exchange of mission details between humans and robots in marine [32] and military [7] scenarios; to update the teammate about processes, so to increase awareness of system’s features and to improve performances, by clarifying ambiguous situations, giving suggestions to correctly complete a task [34] and communicating the final outcome [26].
Light signals, as visual feedbacks, are employed on industrial robots to notify the human about their proximity to the goal or intention, as presented in [23], in which a filled circle with higher intensity indicates that the robot is far from its target position, while the empty shape identifies the zero distance. Such interaction channel is described by [2] as an immediate and efficient way of communicating the android’s future trajectory in a shared environment, where multiple robots collaborate with humans and each of the autonomous driving workers is able to re-plan its motion based on the teammates intentions. Human presence detection is introduced in [31] through the usage of different colors, exploited to categorize three zones: green, yellow and red. The green one is a completely safety area, a medium risk is associated to the yellow region, while a higher hazard is assigned to the red sector, in which the human and the industrial robot perform the collaborative task very close to each other. Visual feedbacks are exploited to increase awareness of robot’s workspace, represented as a toroidal red semitransparent surface and its projection on the floor through a red line circle, as developed in [24]. In addition, the authors of this work, introduce a yellow semitransparent wedge to specify the robot movement volume in an industrial scenario. Interesting is the combination of visual and audio signals to exchange information from robots to humans, as shown in [36] and [17]. In the first study, the authors associate a particular beeping frequency to one of the eight colored rings (one for each zone), distinguished based on human-robot distance in a collaborative nut screwing task, that allows the user to understand the android’s state by considering the sound wave together with different shapes and colors of the signs on the machine. In the second article instead, researchers focus on the advantages related to the simultaneous reproduction of a yellow warning light (positioned in the bottom part of each of the two robotic arms) and a sound. In this case, a reduction of mental workload of industrial operators and increment of the final performance and awareness have been observed.
Gestures are the preferred communication modality for the command speech act category. In [23] and [7], such interaction channel is exploited by the human to stop robot’s activity in an immediate way by showing his/her opened hand to the mobile vehicle, but also indication of the next position to reach by the android is covered in the first aforementioned study. This is not the only work that uses gestures as a way of communicating a new location to a mobile teammate; in effect this concept is also emphasized in [26], in which the authors highlight the power of their system for the presence of a robot able to translate a non-verbal behavior into an understandable action. Pointing is not only employed to provide a specific position to reach, but also to indicate an object, as presented in [16]. The authors of this article stress the importance of such interaction channel in commanding a robot to follow someone, by only pointing the person [32].
From the analyzed studies, one can see that visual feedbacks are more suitable for the alert category. Generally, such communication modality is combined with audio signals in order to provide an imminent warning of a dangerous situation to the person, as in [24] where a sound is used to notify the contact between the human and the robot’s motion volume. Furthermore, in this work, a visual and audio information are provided when a reduction/increment of robot’s speed is verified or a change in motion is performed to avoid a risky condition. Therefore, when a human and a robot touch each other, a red and blurred vision is displayed, together with a simultaneous haptic vibration, as described in [12].
Voice is obviously the modality adopted in all studies that belong to request category. For example, the description and properties of a certain object, are asked by a teammate to the other one, as in [26] and [30]. In this last work, other important concepts emerge, such as the request of performing an action [16, 37], select a certain object or ask information to other teammates about their tasks [32]. Such interaction channel is also used to provide notifications coming from an industrial robotic platform to the human [22].
Visual feedbacks are displayed to the user to perform a specific action by following a semitransparent palm that appears in the immersive industrial VR scenario [24] or to follow assembly instructions slides, illustrating how to complete the collaborative task [9].
The sole work belonging to the greeting category [34] employs voice as interaction modality to welcome the person in the virtual environment.
5 Discussion
In this paper, a preliminary study about the deployment of VR as an evaluation mean for HRI solutions has been presented. This aspect is fundamental for us to define the most suitable delivery channels to be adopted for developing the interaction in the CANOPIES project, with the aim of discovering the most frequently employed communication modalities for exchanging the different informative contents between humans and robots.
Noticeably, none of the considered studies targeted the agriculture scenario, with most of the proposed solutions focusing on industrial application domains. As a consequence, our future work will address the evaluation of identified techniques in a smart agriculture environment modeled using VR.
To summarize the outcome of our first investigation, some general conclusions can be drawn about modalities to be employed to exchange a specific informative content, and to emphasize the importance of considering each of the presented speech act categories in creating a complex robotic system. From our analysis emerges that (i) rarely, all speech act categories are examined in designing an elaborated interaction; so to develop a more robust and efficient robotic architecture, they should all be taken in consideration, (ii) the most used communication channels adopted for messages belonging to information speech act category are voice and visual feedbacks, (iii) commands are mainly based on gestures, e.g., by pointing an object to pick up, (iv) alert and instruction notifications employ visual feedbacks as the way of interaction, because such modality generates information easily understandable by the human, (v) voice is preferred for the request and greeting categories to ask a robot/person to perform specific tasks, but also to make the human feel comfortable and safe in executing the collaborative assignment with the android in a VR scenario.
In order to avoid issues associated to the employment of a single communication channel, it could be interesting to combine more modalities to increase awareness and facilitate the interaction. For example, considering that in an outdoor scenario, as in our case in an agriculture environment, noise or sounds in the background are frequent, the preferred choice would be to exploit voice together with other modalities such as (i) visual feedbacks, to notify the human about particular events or situations, and (ii) gestures, to provide commands or request information to the robot, but also to greet a person in a more natural way. Investigating multimodality to alert the human about dangerous situations by using visual and audio feedbacks, would surely improve both human safety and the performances of a collaborative task. Hence, an efficient and clear way to show instructions about a specific assignment to the user, would be the combination of visual feedbacks and voice/gesture.
As anticipated at the beginning of this article, our goal relies on developing a robust system, in which humans and robots can collaborate on a shared task by overcoming issues associated to a single communication channel to interact with each other. Therefore, in a future work, we plan to better investigate and discuss this topic by also considering AR solutions in HRI.
References
Arntz, A., Eimler, S.C.: Experiencing AI in VR: a qualitative study on designing a human-machine collaboration scenario. In: Stephanidis, C., Antona, M., Ntoa, S. (eds.) HCI International 2020 - Late Breaking Posters, pp. 299–307 (2020)
Aschenbrenner, D., Tol, D.v., Rusak, Z., Werker, C.: Using virtual reality for scenario-based responsible research and innovation approach for human robot co-production. In: 2020 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), pp. 146–150 (2020)
Bach, K., Harnish, R.M.: Linguistic Communication and Speech Acts. MIT Press, Cambridge (1979)
Bolano, G., Juelg, C., Roennau, A., Dillmann, R.: Transparent robot behavior using augmented reality in close human-robot interaction. In: 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), pp. 1–7 (2019)
Bonarini, A.: Communication in human-robot interaction. In: Current Robotics Reports, pp. 1–7 (2020)
Chang, C.T., Hayes, B.: A survey of augmented reality for human-robot collaboration (2020)
Cockburn, J., Solomon, Y.: Multi-modal human robot interaction in a simulation environment (2013)
Dianatfar, M., Latokartano, J., Lanz, M.: Review on existing vr/ar solutions in human-robot collaboration. Procedia CIRP 97, 407–411 (2021)
Dimitrokalli, A., Vosniakos, G.C., Nathanael, D., Matsas, E.: On the assessment of human-robot collaboration in mechanical product assembly by use of virtual reality. Procedia Manuf. 51, 627–634 (2020)
Etzi, R., et al.: Using virtual reality to test human-robot interaction during a collaborative task. In: International Design Engineering Technical Conference and Computers and Information in Engineering Conference. ASME Digital Collection (2019)
Flacco, F., Kröger, T., Luca, A.D., Khatib, O.: A depth space approach for evaluating distance to objects. J. Intell. Rob. Syst. 80, 7–22 (2015)
Fratczak, P., Goh, Y.M., Kinnell, P., Soltoggio, A., Justham, L.: Understanding human behaviour in industrial human-robot interaction by means of virtual reality. In: Proceedings of the Halfway to the Future Symposium 2019, pp. 1–7 (2019)
Galin, R., Meshcheryakov, R.: Review on human-robot interaction during collaboration in a shared workspace. In: Ronzhin, A., Rigoll, G., Meshcheryakov, R. (eds.) Interactive Collaborative Robotics, pp. 63–74 (2019)
Goodrich, M., Schultz, A.: Human-robot interaction: a survey. Found. Trends Human-Comput. Interact. 1, 203–275 (2007)
Hidayat, A.: Speech acts: force behind words (2016)
Inamura, T., Mizuchi, Y.: Sigverse: a cloud-based vr platform for research on multimodal human-robot interaction. Front. Rob. AI 8, 158 (2021)
Kaufeld, M., Nickel, P.: Level of robot autonomy and information aids in human-robot interaction affect human mental workload - an investigation in virtual reality, pp. 278–291 (06 2019)
Khambhaita, H., Alami, R.: Assessing the social criteria for human-robot collaborative navigation: A comparison of human-aware navigation planners. In: 2017 26th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), pp. 1140–1145 (2017)
Kostavelis, I., Gasteratos, A.: Semantic maps from multiple visual cues. Expert Syst. Appl. 68(C), 45–57 (2017)
Kurth, J., Marcel Wagner, A.: New planning methods for systems with human-robot collaboration. Carl Hanser Verlag Munich 115, 698–702 (12 2020)
Liu, D., Bhagat, K.K., Gao, Y., Chang, T.W., Huang, R.: The potentials and trends of virtual reality in education (2017)
Malik, A.A., Masood, T., Bilberg, A.: Virtual reality in manufacturing: immersive and collaborative artificial-reality in design of human-robot workspace. Int. J. Comput. Integr. Manuf. 33(1), 22–37 (2020)
Mara, M., et al.: Cobot studio vr: A virtual reality game environment for transdisciplinary research on interpretability and trust in human-robot collaboration (2021)
Matsas, E., Vosniakos, G.C., Batras, D.: Prototyping proactive and adaptive techniques for human-robot collaboration in manufacturing using virtual reality. Rob. Comput.-Integr. Manuf. 50 (2017)
Mavridis, N.: A review of verbal and non-verbal human-robot interactive communication. Rob. Auton. Syst. 63, 22–35 (2015)
Milliez, G., Ferreira, E., Fiore, M., Alami, R., Lefèvre, F.: Simulating human-robot interactions for dialogue strategy learning. In: Brugali, D., Broenink, J.F., Kroeger, T., MacDonald, B.A. (eds.) SIMPAR 2014. LNCS (LNAI), vol. 8810, pp. 62–73. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-11900-7_6
Mohammed, A., Schmidt, B., Wang, L.: Active collision avoidance for human-robot collaboration driven by vision sensors. Int. J. Comput. Integr. Manuf. 30(9), 970–980 (2017)
Moniri, M.M., Valcarcel, F.A.E., Merkel, D., Sonntag, D.: Human gaze and focus-of-attention in dual reality human-robot collaboration. In: 2016 12th International Conference on Intelligent Environments (IE), pp. 238–241 (2016)
Morato, C., Kaipa, K.N., Zhao, B., Gupta, S.: Toward safe human robot collaboration by using multiple kinects based real-time human tracking. J. Comput. Inf. Sci. Eng. 14, 011006 (2014)
Murnane, M., Higgins, P., Saraf, M., Ferraro, F., Matuszek, C., Engel, D.: A simulator for human-robot interaction in virtual reality. In: 2021 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops, pp. 470–471 (2021)
Nikolakis, N., Maratos, V., Makris, S.: A cyber physical system (cps) approach for safe human-robot collaboration in a shared workplace. Rob. Comput.-Integr. Manuf. 56, 233–243 (2019)
Novitzky, M., Semmens, R., Franck, N.H., Chewar, C.M., Korpela, C.: Virtual reality for immersive human machine teaming with vehicles. In: Chen, J.Y.C., Fragomeni, G. (eds.) HCII 2020. LNCS, vol. 12190, pp. 575–590. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-49695-1_39
Palmarini, R., del Amo, I.F., Bertolino, G., Dini, G., Erkoyuncu, J.A., Roy, R., Farnsworth, M.: Designing an ar interface to improve trust in human-robots collaboration. Procedia CIRP 70, 350–355 (2018)
Schmitz, N., Hirth, J., Berns, K.: A simulation framework for human-robot interaction. In: 2010 Third International Conference on Advances in Computer-Human Interactions, pp. 79–84. IEEE (2010)
Shi, D., Collins Jr, E.G., Goldiez, B., Donate, A., Liu, X., Dunlap, D.: Human-aware robot motion planning with velocity constraints. In: 2008 International Symposium on Collaborative Technologies and Systems, pp. 490–497 (2008)
Shu, B., Sziebig, G., Pieters, R.: Architecture for safe human-robot collaboration: multi-modal communication in virtual reality for efficient task execution, pp. 2297–2302 (2019)
Wijnen, L., Bremner, P., Lemaignan, S., Giuliani, M.: Performing human-robot interaction user studies in virtual reality*. In: 29th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), pp. 794–794 (2020)
Yan, H., Ang, M.A., Poo, A.: A survey on perception methods for human-robot interaction in social robots. Int. J. Soc. Rob. 6, 85–119 (2014)
Zacharaki, A., Kostavelis, I., Gasteratos, A., Dokas, I.: Safety bounds in human robot interaction: A survey. Saf. Sci. 127, 104667 (2020)
Acknowledgements
The work of S. Kaszuba, F. Leotta and D. Nardi has been partly supported by the H2020 EU project CANOPIES - A Collaborative Paradigm for Human Workers and Multi-Robot Teams in Precision Agriculture Systems, Grant Agreement 101016906.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Kaszuba, S., Leotta, F., Nardi, D. (2021). A Preliminary Study on Virtual Reality Tools in Human-Robot Interaction. In: De Paolis, L.T., Arpaia, P., Bourdot, P. (eds) Augmented Reality, Virtual Reality, and Computer Graphics. AVR 2021. Lecture Notes in Computer Science(), vol 12980. Springer, Cham. https://doi.org/10.1007/978-3-030-87595-4_7
Download citation
DOI: https://doi.org/10.1007/978-3-030-87595-4_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-87594-7
Online ISBN: 978-3-030-87595-4
eBook Packages: Computer ScienceComputer Science (R0)