
Abstract
Augmented Reality is increasingly used for visualizing underground networks. However, standard visual cues for depth perception have never been thoroughly evaluated via user experiments in a context involving physical occlusions (e.g., ground) of virtual objects (e.g., elements of a buried network). We therefore evaluate the benefits and drawbacks of two techniques based on combinations of two well-known depth cues: grid and shadow anchors. More specifically, we explore how each combination contributes to positioning and depth perception. We demonstrate that when using shadow anchors alone or shadow anchors combined with a grid, users generate 2.7 times fewer errors and have a 2.5 times lower perceived workload than when only a grid or no visual cues are used. Our investigation shows that these two techniques are effective for visualizing underground objects. We also recommend the use of one technique or another depending on the situation.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

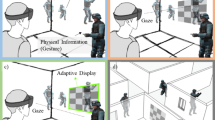

Keywords
1 Introduction
In this article, our goal is to help the understanding of underground objects by visualizing them using an Augmented Reality Head-Mounted Display. According to Milgram et al. [21], Augmented Reality (AR) is part of a continuum between real and virtual environments and consists of augmenting reality by superimposing virtual content on it. On the one hand, AR is a promising way of representing many kinds of information, such as 2D data, 3D data, texts, images, or holograms, directly in situ and with better immersion. On the other hand, a bad perception of the distances between or of the positions of the augmentations can considerably alter the experience of AR, especially with direct perception systems like a Head-Mounted Display (HMD).
Several studies [8, 19, 28] focus on the problems of perception in AR. They show that virtual content cannot be naively added to reality: visual cues are necessary. Indeed, human perception is influenced by our experience of our environment, and virtual objects do not follow the same physical rules as real objects. This work focuses on removing the ambiguities of interpreting a complex underground scene in AR. This open issue has been recently highlighted in a course taught by Ventura et al. [34].
In this work, we focus on a specific optical see-through HMD: the first generation of the HoloLens. The design of this device allows parallax movement and stereoscopic disparity, both of which are natural features for enhancing perception as mentioned in the work of Cutting [6]. In this paper, we focus on cues for improving the visualization of underground objects. One cue is a synthetic projection on the floor of the virtual object’s silhouette, linked to the object by an axis, i.e., Projection Display (PD). We combine this projection with a grid that represents the virtual floor and overlays the real floor, i.e., Projection Grid Display (PGD). We conducted two experiments to determine whether these visualization techniques improved spatial perception. More specifically, we evaluated the benefits and drawbacks of three visualization techniques in comparison to the naive technique used to display buried objects in AR.
The contributions in this paper are the following:
-
Two hybridizations of visualization techniques for displaying underground objects in AR.
-
A comparison of how four visualization techniques affect the user’s perception of the absolute positioning of underground virtual objects in AR.
-
A comparison of how four visualization techniques affect the user’s perception of the relative positioning and altitude of underground virtual objects in AR.

Comparison of two classical methods, Naive Display and Grid Display (ND-GD), with hybridized visual cues, Projection Grid Display and Projection Display (PGD-PD), for depth perception methods, including both relative and absolute methods: Projection Display (PD), Projection Grid Display (PGD), Naive Display (ND), and Grid Display (GD).
2 Motivation
In recent years, underground facilities (e.g., for electricity, water, or natural gas networks) have been precisely referenced to prevent accidents during future works. They are typically reported on 2D maps with depth information, but sometimes are reported directly in 3D. Ventura et al. [34] observed that these maps can be used for many tasks: information querying, planning, surveying, and construction site monitoring.
We focus on the marking picketing task, which consists of reporting map points of interest directly in situ in the field. While carrying out these tasks, workers have many constraints. We conducted interviews beforehand to collect needs and constraints during these tasks and, more generally, during the use of these 2D/3D maps on 2D displays (paper or screen).
According to workers, these plans are very difficult to interpret in the field. As Wang et al. [35] mentioned, reading 3D GIS data from a 2D display affects the user cognition and understanding of 3D information. For example, at a construction site during an excavation, the underground elements are indicated by a color code. They are classified according to what they consist of. Workers are in a dangerous environment (construction site) and want to keep their hands free. In addition, they need to quickly visualize and understand the information being displayed.
We choose AR to facilitate the visualization of 2.5/3D data in the field. In our case, we need to display underground virtual objects. We opted for a non-realistic rendering to allow workers to quickly target important information. Rolim et al. [24] classified some perception issues into three main categories: visual attention, visual photometric consistency, and visual geometric consistency. Due to our industrial background, we choose to focus on the last category, visual geometric consistency. This choice is appropriate because our focus is the display of underground pipes using the data from 2D plans. Following the example of Zollmann et al., [43, 45] who displayed underground pipes, our major challenges are to maintain the coherence between the real environment and the virtual data (management of occlusions by the ground) and to provide a correct perception of distances and spatial relationships between objects.
3 Related Work
The display of 3D underground virtual objects involves two main problems: occlusion management and depth perception.
3.1 Occlusion Management
The link between real and virtual worlds can be made by managing the occlusion of virtual objects by the ground. According to Zollmann et al. [41], if occlusions are not considered, it always leads to poor depth perception. Our goal is to account for occlusions without losing the precision or the resolution of underground object information (as can be the case for solutions that use transparencies or patterns that partially mask underground objects).
There are several methods for managing occlusion. One method consists of revealing the interior of an object by maintaining and/or accentuating its edges [7, 17, 20]. This type of solution works well for small objects that are included in larger objects (for example, organs in a body). The user can see the whole object and therefore better understand the spatial relationships between the larger object and the smaller, virtual objects inside it. However, such a method must be adapted when the occlusion occurs in a large plane without visible bounds (such as occlusion by the floor or walls).
Another method is to apply occlusion masks as demonstrated in many works [22, 23, 26, 27, 37, 40]. The different areas of interest are separated layer by layer, and the virtual objects are displayed at the appropriate level of depth in the image by managing their occlusions with other layers. Since our goal is to display underground objects, such a method is not directly possible.
Transparency is a solution that takes advantage of the benefits of the previous two solutions. Ghosting techniques render occluding surfaces onto semitransparent textures to reveal what is behind them. For example, some works [2, 4, 10, 27, 42, 45] used important image elements for occlusion, sometimes with different levels of transparency, to give a feeling of depth. We do not want to lose any information about underground objects or compromise their accuracy; However, this is likely to occur when using ghosting techniques alone since they add semitransparent layers in front of the hidden objects. These solutions have therefore been discarded. Some transparency methods have been combined with other techniques [15, 16]. With the visualization proposed by Kalkofen et al. [16], all nearest edges overlap the information and all objects appear to be on the same plane despite their different depths. In Kalkofen et al.’s other work [15], occluders are displaced to better understand relationships, but perception of their real position is lost. It seems that transparency techniques allow ordering objects but do not quantify the distance between them.
Another very useful technique is the excavation box [9, 14, 46]. This is a synthetic trench identical to the excavation during construction. Virtual excavation offers valuable visual cues; however, if it is not combined with transparency techniques, the contained objects will only be visible when the user’s point of view allows it. Virtual excavation alone does not offer a complete visualization of virtual objects from all points of view.
3.2 Depth Perception
There are some solutions to understand occlusion by a plane, but it is still difficult to perceive virtual objects position and negative altitude. Rosales et al. [25] studied the difference in perception between objects on or above the ground. Their work demonstrates that objects above the ground were seen on it, but further from the observer than their actual distance. Distance and altitude are intrinsically related. We can hypothesize that there would be a similar perception disparity with our underground objects: they would be perceived as being underground and stuck to the ground but they would appear closer to the observer than they actually are.
Many factors influence the perception of an object’s position. These factors include the conditions of the experiment: display [1], being indoors or outdoors [18]. Other factors also include the elements of realism [33] in the scene: the coherence of shadows [5, 31] and illuminations [11] improve the user’s perception of positions. However, perception can also be influenced by the focal distance, the age of the user (physiological characteristics of the user), or luminosity (characteristics of the scene) [29] as well as interpupillary distance or parallax [39].
The anatomical characteristics of the users are not something that can be changed. In addition, our system must work outdoors on an optical see-through HMD device. Another factor that has a great impact on the perception of an object’s position is the visualization technique used [9, 13], which can include many factors, such as shadows or realism. Several visualization techniques have been proposed. In our context, some visual cues, such as those described by Luboschik et al. [19] would be unusable. Indeed, their use of perspective lines is interesting, but these lines must be adapted to our context, as they could easily be confused with pipes when visualizing many networks. The system must work despite the influence of all the factors incurred by our technical and technological choices.
The visualizations that we compare are inspired by those of Ware et al. [36], Skinner et al. [30] or even Heinrich et al. [13]. Ware et al. and Skinner et al. worked on virtual object projection on a surface (grid for the first, ground for the second). Heinrich et al. worked with a projective AR display and compared many methods for displaying 3D holograms that improve the user’s understanding of their position (both vertical position and object distance to the user). They asked their users to sort objects according to these two dimensions and found that their supporting lines approach is the best approach for removing ambiguity from scene perception. The same kinds of projections have been named dropping lines by Ware et al. [36] or shadow anchors by Ventura et al. [34], but these methods always involve objects that are above the ground.
Our study is closely related to some aspects of the work done by Zollmann et al. [44]. However, nothing during their study suggested that their visual cues would provide the same results for underground objects within a small range of distances (up to 1.50 m deep in our case). Additionally, our problem is slightly different: the relative (spatial relationship between objects) and absolute (absolute distance) perception of the positions of underground objects needs to be improved, even for objects which are below the ground and not above, and we want to provide an evaluation of absolute positioning perception.
4 Concepts
We describe the design of two visualizations for underground objects that are based on different visual cues.
-
Projection: In various works [13, 36, 38], projection facilitates better estimates of the relative distances between objects. Because underground objects need to be displayed, we choose a hybridization of this approach. The silhouettes of underground objects are projected onto the ground in an unrealistic way. These silhouettes are also connected to the corresponding objects with a vertical axis. All the projections are on the same plane and could be compared side by side. Additionally, the heights of the projection axes could be compared to allow a better perception of the negative altitude.
-
Grid: Projection alone allows all objects to be referenced on a single plane, however, sometimes it is difficult to discern nearby objects and identify that they are underground. As a result, we choose to add a visual cue to reference the floor. Zollmann et al. [45] help to materialize this real surface in the virtual world using a ghosting technique with a semitransparent chessboard. In AR, however, transparent layers cannot be numerous due to the brightness of the screens, which would make it difficult to see all the layers and objects behind them. Therefore, we choose to use a grid. This allows us to implement a visual cue for the ground without obscuring underground objects. The grid is regular and orthogonal, so we hypothesize that it can improve distance perception. In addition, the grid allows users to integrate their perception of their own body into the virtual world. Thus, they can have a better understanding of the spatial relationships between the ground, objects (relative altitude), and themselves.
5 Implementation
We calibrate the position of the ground using an ARToolKit markerFootnote 1 (Hiro pattern) that is printed and placed on the real scene. The size of this marker is 8 by 8 cm. The user must look at the marker continuously for 5 consecutive seconds. The system then evaluates the position of the marker using the HoloLens camera. We previously informed the system of the camera’s intrinsic parameters. Then, we obtain the ground’s height and save it.
We choose this solution instead of the traditional spatial mapping of the HoloLens because we do not find this spatial mapping to be precise enough [4]. Indeed, the ground is estimated at 10 cm above its real position. We implement the two cues as follows:
-
Projection: We project the silhouettes of underground objects directly onto the ground. We also connect them with a vertical axis. The axis and silhouette are rendered in a semitransparent shader to distinguish the object from visual cues, making it more perceptible.
-
Grid: The grid is made up of 3D lines. The grid is green because the user needs to distinguish it from other cues such as projections, and additionally, green is a color well perceived by the human eye [12]. The grid is rendered with a semitransparent shader. The grid is displayed at the same height as the ground horizontally, and its rotation is not modified (HoloLens has a stabilization method).
We therefore implement four visualization techniques, one using projection, one using a grid, one using a combination of the two and one without any visual cues.
6 Experiments
The goal of the experiments is to compare the designed visualization techniques in the case of buried networks. We consider only points of interest (specific components of an installation or parts of a pipe that are not straight) on buried network maps. Indeed, the links between these points can provide additional visual cues due to their appearance and their geometry. We choose to display points of interest as cubes. Later, we will expand our exploration of our techniques by considering the entire network topology and test our techniques using more complex scenes.
Rosales et al. [25] revealed that there is an ambiguity for cubes of 0.20 m per side that are 0.20 m above the ground. We therefore choose to evaluate the perception at 6 underground depth levels, from 0.20 m to 1.5 m (most of the objects in the industrial context are in this interval).
Rosales et al. also carried out a preliminary study to determine the range of distances in which their method worked. They found the HoloLens to be reliable up to an 8 m distance. Additionally, it is difficult to test a higher distance under laboratory conditions. Even for the high range of the average interpupillary spacing interval, the parallax reconstruction is only viable to just under 5 m. We, therefore, choose to evaluate objects from a distance of 5 m (to minimize this natural cue) to 8 m. We define the distances d\(_{A}\) and d\(_{E}\), visible in Fig. 2 as being the altitude (negative in our case) and the egocentric distance, respectively. For the experiments, we define an orthogonal coordinate system O (X, Y, Z) (see Fig. 2). We conducted two experiments: one to evaluate the absolute spatial position and another to evaluate the relative spatial relationships.
6.1 Procedure, Apparatus, Tasks
Our experiments used Microsoft 1\(^{st}\) generation HoloLens. The applications were built using Unity3D 2018.3.f1. The tests took place as follows: one participant entered the empty test room, with no marks or indicators on the ground. Participants had an open space in front of them measuring 5 by 10 m. They calibrated the HoloLens using the native application so that the display was adapted to their vision. Then, they launched the test application (Absolute or Relative), and in both cases, they stared at a Hiro marker to calibrate the height of the ground. After that, the test started, and participants used a large gray cube to their right to switch scenes. Participants stared at the cube for 5 s, and the gray cube then became greener until it disappeared to make way for a new scene. We used the same behavior for both applications.
For the “Absolute” experiment, participants only had one task:
-
Task 1 (T1): Participants observed a scene composed of one small gray cube that could be at 6 different distances ([5; 5.6; 6.2; 6.8; 7.4; 8] m, named d\(_{E}\) on Fig. 2) and 6 different depths ([0.20; 0.46; 0.72; 0.98; 1.24; 1.50] m, named d\(_{A}\) on Fig. 2). The cube was randomly rotated and scaled (0.20–0.30 m per side) to avoid a comparison bias with the floor or the previous scenes. The cube The cube was randomly rotated and scaled (0.20–0.30 m per side) to avoid a comparison bias with the floor or the previous scenes. The cube appeared for 10 s using a random visualization technique and then disappeared. During this phase, participants had to observe the cube and its position. Then, they had to walk to the position they had estimated the cube to be and place a black cross on the ground. If the cube was perceived to be above or below the ground, participants placed the black cross below or above the real position of the cube, respectively, directly on the ground. They mentally projected the cube on the ground. Participants had begun walking to this position by the time the cube disappeared.
For the “Relative” experiment, participants had to complete two tasks in the same scene:
-
Task 2 (T2): The scene was composed of six simple gray cubes. All cubes are at 6 different distances (defined in Task 1) and 6 different depths (defined in Task 1). They were randomly rotated and scaled (defined in Task 1) to avoid a comparison bias between the cubes themselves and with the ground. The cubes were separated by 0.5 m along the X-axis (see Fig. 2). During this phase, participants had to classify the cubes by altitude (d\(_{A}\)), from highest to lowest.
-
Task 3 (T3): During the same scene, participants had to order the cubes by egocentric distance (d\(_{E}\)), from nearest to farthest.

Apparatus schema
After the practical part of the test, each participant was invited to sit down to answer some questions and to complete some surveys (see Sect. 6.3). First, images rendered using the four visualization techniques were presented, and then, participants were asked to fill out a NASA-TLX survey for each visualization technique.
Then, for each experiment (relative and absolute), we asked the participant to answer a few questions: which visualization technique did you prefer and why? Rank them in order of preference. Do you have any thoughts on which cue helped you more or less? We then conducted a small interview to better understand their choices and feelings. Participants used each visualization technique twice. We randomly chose the visualization methods’ order of appearance.
6.2 Participants
We recruited 40 participants, 20 for each experiment. For the “Absolute” experiment, their ages ranged from 21 to 54. Ages ranged from 22 to 53 for the “Relative” experiment (see Table 1 for ages and gender distribution). All participants had perfect color perception, 4 wore glasses for the absolute experiment and 6 wore glasses for the “Relative” experiment. For each experiment, we conducted a preliminary survey of their familiarity with AR, which indicates self-rated familiarity on a scale from one (not familiar—never) to five (familiar—every day). For each experiment, participants were not familiar with AR.
6.3 Measures and Surveys
Understanding the effects of the grid, the projection, and the combination of both was important. These methods’ comparison to a naive visualization is also important. Therefore, our experiments involved both independent and dependent variables. We also present our hypothesis for this work.
Independent Variables:Our independent variables were the four visualization techniques (visible on Fig. 1). Cues from the Sect. 4 were used to construct them:
-
Projection Display (PD) = projection
-
Projection Grid Display (PGD) = projection + grid
-
Grid Display (GD) = grid
-
Naive Display (ND) = no hint
Dependent Variables: For both experiments, we examined the NASA-TLX scores for each visualization technique: Mental Demand (MD), Physical Demand (PD), Temporal Demand (TD), Performance (P), Effort (E), Frustration Level (FL), and Total score (Total). These scores were the main factors we focused on improving.
-
“Absolute” Experiment: We evaluated the distance differences (Diff-D) between the perceived distance and the real distance during T1, in meters.
-
“Relative” Experiment: For T2, the participant sorted the cubes according to d\(_{A}\). We computed the inversion score (Error d\(_{A}\)) according to the real positions of the cubes. The sorting error score was calculated using the number of inversions that existed between the combination given by the participant and the perfect combination (the real positions of the cubes). For example, if the perfect combination was A-B-C and the participant chose B-A-C, there was only one inversion (A and B, Error = 1). However, if the participant chose C-A-B, there were two inversions (B and C but also A and C, Error = 2). We also recorded the sorting time (Time d\(_{A}\)), in seconds. Similarly, for T3, we evaluated the sorting error score according to d\(_{E}\) (Error d\(_{E}\)). We also recorded the sorting time (Time d\(_{E}\)), in seconds.
Hypothesis: For the “Absolute” experiment we hypothesize the following:
-
The perceived workload is less when using PGD and PD than when using ND and GD – Total NASA-TLX score (H1): PGD-ND (H1a); PGD-GD (H1b); PD-ND (H1c); PD-GD (H1d).
-
PGD has a lower perceived workload than PD – Total NASA-TLX score (H1bis).
-
PGD and PD are more accurate in terms of egocentric distance estimation when compared to ND and GD – Diff-D (H2): PGD-ND (H2a); PGD-GD (H2b); PD-ND (H2c); PD-GD (H2d).
-
PGD is more accurate in terms of egocentric distance estimation when compared to PD – Diff-D (H2bis).
For the “Relative” experiment we hypothesize that:
-
PGD and PD reduce the perceived workload for sorting tasks when compared to ND and GD – Total NASA-TLX score (H3): PGD-ND (H3a); PGD-GD (H3b); PD-ND (H3c); PD-GD (H3d).
-
PGD reduces the perceived workload for sorting tasks when compared to PD – Total NASA-TLX score (H3bis).
-
PGD and PD are more efficient at ordering virtual objects by their altitude than ND and GD over similar periods of time – Error d\(_{A}\)/Time d\(_{A}\) (H4): (PGD-ND (H4a); PGD-GD (H4b); PD-ND (H4c); PD-GD (H4d)).
-
PGD is more efficient at ordering the virtual objects by their altitude than PD over similar period of time – Error d\(_{A}\)/Time d\(_{A}\) (H4bis).
-
same supposition as in H4 but for egocentric distance rather than altitude – Error d\(_{E}\)/Time d\(_{E}\) (H5): PGD-ND (H5a); PGD-GD (H5b); PD-ND (H5c); PD-GD (H5d).
-
The same supposition as in H4 is proposed here, but for egocentric distance rather than altitude – Error d\(_{E}\)/Time d\(_{E}\) (H5bis).
7 Results
All results were obtained using R [32] scripts and R StudioFootnote 2. We set the risk parameter, \(\alpha \), at 5%. The p-values must therefore be less than 0.05 to make the test meaningful.
We analyzed the results of each experiment separately. Since participants tested the four visualization techniques, experiments were within-subject, so all data were paired. We used a Friedman test with a post-hoc Conover test. The Friedman test is the equivalent of a nonparametric repeated measures ANOVA, which can be applied to ordinal qualitative variables or when the conditions of the ANOVA are not met (normality of the residuals and homogeneity of variances). During the Conover post-hoc, we chose the Bonferroni method to adjust the p-values.
7.1 “Absolute” Experiment
Table 3 shows the p-values, while Table 2 shows the means, standard deviation and Conover’s t-values. Figure 3 presents boxplots of the NASA-TLX scores, arranged by theme, as well as total scores for the absolute experiment. Figure 4 shows boxplots of differences in absolute distance estimation.

NASA-TLX scores of the absolute experiment

Boxplots of differences of absolute distances estimation
Based on Table 3, the differences in terms of perceived mental workload between PGD-ND and PD-ND were not due to chance. PGD and PD both appear to lower the perceived mental load in comparison with the baseline ND technique.
Concerning the perceived distance, there is a very high probability that the observed differences between PGD and PD and the other two visualization techniques are not due to chance. We can thus say that PGD allows for better precision in the evaluation of these distances than ND and GD. We find the same result when comparing PD to ND and GD.
7.2 “Relative” Experiment
All of the p-value results are displayed in Table 4, and Table 2 displays the means, standard deviation and t-values from Conover’s post-hoc test. Additionally, see Fig. 5 for NASA-TLX scores by theme and total NASA-TLX score for the relative experiment. See Fig. 6 for the boxplots of Errors d\(_{E}\) and Error d\(_{A}\), made during sorting.
It is very likely that the observed differences between the averages of the total NASA-TLX scores between PGD and ND and between PGD and GD are not due to chance. We deduce that using PGD induces a lower mental load than using GD or ND (H3a and H3b validated). Similarly, PD seems more effective for reducing mental load than ND.
It is likely that PGD is more efficient than ND for sorting objects according to d\(_{A}\). To compare PGD and GD according to this same factor, it is very likely that PGD is more efficient than GD. When comparing PD and GD on this criterion, PD seems more efficient than GD. Although statistically significant, this comparison would require further testing.
With sorting by d\(_{E}\), PGD is most likely more efficient than ND and GD. For comparisons between PD and other visualization techniques, we can only say that it is very likely that this visualization technique is more efficient than GD. Regarding hypotheses H1bis, H2bis, H3bis, H4bis and H5bis, none of them can be validated by the experiments carried out in this paper. But some NASA-TLX themes in the “Relative” experiment show significant differences between PD and PGD. In both cases, the statistical tests indicate that there seems to be an advantage when using the PGD visualization technique, which has a lower score on average on these two themes. We conclude that PGD implies a lower mental load than GD or ND.

NASA-TLX scores of relative experiment

Boxplot of the number of sorting errors
8 Discussion
The statistical results show that Projection Display (PD) and Projection Grid Display (PGD) supplant the other two techniques (ND and GD). However, some of the results can also be better understood through the interviews with participants. Moreover, the results obtained can be moderated due to the conditions of the experiments and many other factors.
8.1 “Absolute” Experiment
Regarding the projection, some participants were very confident about their performance using ND or GD, more than with PD or PGD. We did not explain to them what the cues looked like or how to use them, so some participants preferred to trust their perception and chose to ignore these visual cues. However, given the overall results, we see that the projection greatly improves performance, whether using PD or PGD. These few users, therefore, were incorrect in their assertion that they could be more efficient without cues.
Four participants said that the grid helped but overloaded the visualization compared to ND or PD. Two participants said the grid might be too thick. We can hypothesize that having the ability to change the visualization mode or change the thickness or transparency of the grid will probably lead to better results. In addition, the position of the grid was determined using the position of the marker. Although the accuracy was higher than that with HoloLens spatial mapping, the grid was still a few centimeters above the ground. The combination of these inaccuracies with an overloaded visualization can induce an incorrect interpretation of the position of the projection, which is supposed to stick to the grid. In addition, H2 and partially H1 have been validated, but H1bis and H2bis have not.
Regarding hypotheses H1bis, H2bis, H3bis, H4bis and H5bis, none of them are validated by the two experiments carried out in this paper. On the other hand, some NASA-TLX themes in the relative experiment show significant differences between PD and PGD (Mental Demand: p-value = 0.0246120 t-value = −2.991; Performance p-value = 0.03020057 t-value = −1.999). In both cases, the statistical tests indicate that there seems to be an advantage when using the PGD visualization technique, which has a lower score on average on these two themes. Regarding the perceived workload, the observed difference between PGD and GD was not statistically significant. Nevertheless, it is close to the alpha risk. Further experiments with new samples would need to be carried out to study whether there is a significant difference between PGD and GD. The nonsignificance of the results when comparing PGD and PD can be explained by the appearance chosen for the grid (e.g., thickness or color). Indeed, an evaluation of the influence of these parameters might be helpful. Additionally, consideration should be given to whether the appearance of the grid may cause participants to change their minds about feeling visually overloaded.
8.2 “Relative” Experiment
If we consider the PGD-GD and PGD-ND comparisons, all hypotheses are validated (H3a, H4a, H5a, H3b, H4b, H5b). However, in regard to PD comparisons, the hypotheses are not all verified because of the nonsignificance of some of the p-values (H3c, H4d, H5d validated). This confirms the results of the “Absolute” experiment.
In this experiment, although the tests between PGD and PD are not decisive, PGD outperforms ND and GD for these tasks, while PD does not. We also see that PGD is better than PD in terms of Mental Demand, while it is not in the absolute experiment. This difference can be explained by the nature of the task: it is useful to have a grid while comparing two objects that are far from each other but at similar distances from the user (d\(_{E}\)). Indeed, according to the participants, the grid is useful for comparing distances since it is regular and therefore allows measurement. Participants also added that the grid allowed them to map the room. More experiments must be conducted to further study the differences between PGD and PD, such as evaluating different thicknesses and/or colors of the grid.
9 Conclusion and Perspectives
In this article, we evaluate four visualization techniques in regard to the perception of vertical and horizontal distances in the case of buried objects. Based on the experimental results, the hybridization techniques are promising. However, some users think that the grid overloads the visualization, although it improves the understanding of the scene. We can thus envision implementing several options to let users decide how much information they need as they go. For example, projection is precise enough to visualize the absolute position of virtual objects under the ground. However, in regard to comparing the positions of objects relative to each other, the grid is useful for nearby objects and to better understand that objects are underground.
Additionally, absolute depth perception was evaluated in only one direction, d\(_{E}\), and not d\(_{A}\). It would be interesting to find a way to assess this issue to see if the results would be different. Another question to address would be to assess if the same conclusions can be drawn with objects that are above the ground. We plan to test projection alone and its combination with the grid with more objects and assess the impact of the density of displayed objects. We also want to test these methods with a more complex geometry, for example, cubes linked by pipes, and improve visualization by changing the appearance of the data. The final step will be to integrate real data from 3D underground network maps and study how they are perceived by the user.
10 Health Crisis
The tests were carried out outside of a lockdown at a time when national laws and laboratory rules allowed it. We ensured that our protocol was validated by our hierarchy. We, therefore, followed a very strict sanitary protocol, with individual protective equipment (e.g., masks, disposable caps), disinfection of all surfaces, all equipment, and the HMD to perform the tests.
Note
This article is a translation of a French article from the IHM20.21 conference with permission [3].
Notes
- 1.
- 2.
https://rstudio.com/, Version 1.2.1335 on Windows.
References
Ahn, J., Ahn, E., Min, S., Choi, H., Kim, H., Kim, G.J.: Size perception of augmented objects by different AR displays. In: Stephanidis, C. (ed.) HCII 2019. CCIS, vol. 1033, pp. 337–344. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-23528-4_46
Avery, B., Sandor, C., Thomas, B.H.: In: Improving spatial perception for augmented reality X-ray vision, pp. 79–82. IEEE (2009). https://doi.org/10.1109/VR.2009.4811002
Becher, C., Bottecchia, S., Desbarats, P.: Projection Grid Cues: une manière efficace de percevoir les profondeurs des objets souterrains en Réalité Augmentée. In: IHM 2020–2021 (To appear) (2021). https://doi.org/10.1145/3450522.3451247
Chen, J., Granier, X., Lin, N., Peng, Q.: In: On-line visualization of underground structures using context features, pp. 167–170. ACM, New York (2010). https://doi.org/10.1145/1889863.1889898
Cöster, J.: The effects of shadows on depth perception in augmented reality on a mobile device. Technical report (2019)
Cutting, J.E.: How the eye measures reality and virtual reality. Behav. Res. Methods Instrum. Comput. 29(1), 27–36 (1997). https://doi.org/10.3758/BF03200563
De Paolis, L.T., Luca, V.D.: Augmented visualization with depth perception cues to improve the surgeon’s performance in minimally invasive surgery. Med. Biol. Eng. Comput. 57(5), 995–1013 (2018). https://doi.org/10.1007/s11517-018-1929-6
Dey, A., Cunningham, A., Sandor, C.: In: Evaluating depth perception of photorealistic mixed reality visualizations for occluded objects in outdoor environments, vol. VRST 10, p. 211. ACM Press, New York (2010). https://doi.org/10.1145/1889863.1889911
Eren, M.T., Balcisoy, S.: Evaluation of X-ray visualization techniques for vertical depth judgments in underground exploration. Vis. Comput. 34(3), 405–416 (2017). https://doi.org/10.1007/s00371-016-1346-5
Fukiage, T., Oishi, T., Ikeuchi, K.: In: Reduction of contradictory partial occlusion in mixed reality by using characteristics of transparency perception, pp. 129–139. IEEE (2012). https://doi.org/10.1109/ISMAR.2012.6402549
Gao, Y., Peillard, E., Normand, J.M., Moreau, G., Liu, Y., Wang, Y.: Influence of virtual objects shadows and lighting coherence on distance perception in optical see-through augmented reality. J. Soc. Inf. Disp. 28(2), 117–135 (2019). https://doi.org/10.1002/jsid.832
Gross, H.: Handbook of Optical Systems, vol. 1. Wiley-VCH (September 2005). https://doi.org/10.1002/9783527699223
Heinrich, F., Bornemann, K., Lawonn, K., Hansen, C.: In: Depth perception in projective augmented reality: an evaluation of advanced visualization techniques, pp. 1–11. ACM, New York (2019). https://doi.org/10.1145/3359996.3364245
Junghanns, S., Schall, G., Schmalstieg, D.: In: VIDENTE-What lies beneath?, A new approach of locating and identifying buried utility assets on site, vol. 08), p. showcase. p. 28, Salzburg, Austria (2008)
Kalkofen, D., Tatzgern, M., Schmalstieg, D.: Explosion diagrams in augmented reality. In: 2009 IEEE Virtual Reality Conference, pp. 71–78. IEEE (March 2009). https://doi.org/10.1109/VR.2009.4811001
Kalkofen, D., Mendez, E., Schmalstieg, D.: Interactive focus and context visualization for augmented reality. In: 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, pp. 1–10. IEEE (November 2007). https://doi.org/10.1109/ISMAR.2007.4538846
Kalkofen, D., Veas, E., Zollmann, S., Steinberger, M., Schmalstieg, D.: In: Adaptive ghosted views for augmented reality, pp. 1–9. IEEE (2013). https://doi.org/10.1109/ISMAR.2013.6671758
Livingston, M., Ai, Zhuming, Swan, J., Smallman, H.: In: Indoor vs. Outdoor depth perception for mobile augmented reality, pp. 55–62. IEEE (2009). https://doi.org/10.1109/VR.2009.4810999
Luboschik, M., Berger, P., Staadt, O.: In: On spatial perception issues in augmented reality based immersive analytics, vol. 16, pp. 47–53. ACM Press, New York (2016). https://doi.org/10.1145/3009939.3009947
Mendez, E., Schmalstieg, D.: In: Importance masks for revealing occluded objects in augmented reality, vol. VRST 2009, p. 247. ACM Press, New York (2009). https://doi.org/10.1145/1643928.1643988
Milgram, P., Takemura, H., Utsumi, A., Kishino, F.: Augmented reality: a class of displays on the reality-virtuality continuum. In: Das, H. (ed.) Telemanipulator and Telepresence Technologies. SPIE (1995). https://doi.org/10.1117/12.197321
Montero, A., Zarraonandia, T., Diaz, P., Aedo, I.: Designing and implementing interactive and realistic augmented reality experiences. Univ. Access Inf. Soc. 18(1), 49–61 (2017)
Otsuki, M., Kamioka, Y., Kitai, Y., Kanzaki, M., Kuzuoka, H., Uchiyama, H.: Please show me inside. In: SIGGRAPH Asia 2015 Emerging Technologies on - SA 2015, pp. 1–3. ACM Press, New York (2015). https://doi.org/10.1145/2818466.2818469
Rolim, C., Schmalstieg, D., Kalkofen, D., Teichrieb, V.: Design guidelines for generating augmented reality instructions. In: IEEE International Symposium on Mixed and Augmented Reality, pp. 120–123. IEEE (September 2015). https://doi.org/10.1109/ISMAR.2015.36
Rosales, C.S., et al.: In: Distance judgments to on- and off-ground objects in augmented reality, pp. 237–243. IEEE (2019). https://doi.org/10.1109/VR.2019.8798095
Roxas, M., Hori, T., Fukiage, T., Okamoto, Y., Oishi, T.: In: Occlusion handling using semantic segmentation and visibility-based rendering for mixed reality, vol. VRST 2018, pp. 1–8. ACM Press, New York (2018). https://doi.org/10.1145/3281505.3281546
Sandor, C., Cunningham, A., Dey, A., Mattila, V.V.: In: An Augmented Reality X-Ray system based on visual saliency, pp. 27–36. IEEE (2010). https://doi.org/10.1109/ISMAR.2010.5643547
Schall, G., et al.: Handheld augmented reality for underground infrastructure visualization. Pers. Ubiquit. Comput. 13(4), 281–291 (2008). https://doi.org/10.1007/s00779-008-0204-5
Singh, G., Ellis, S.R., Swan, J.E.: The effect of focal distance, age, and brightness on near-field augmented reality depth matching. IEEE Trans. Vis. Comput. Graph. 26(2), 1385–1398 (2020). https://doi.org/10.1109/tvcg.2018.2869729
Skinner, P., Ventura, J., Zollmann, S.: Indirect augmented reality browser for GIS Data. In: Adjunct Proceedings - 2018 IEEE International Symposium on Mixed and Augmented Reality, ISMAR-Adjunct 2018, pp. 145–150. Institute of Electrical and Electronics Engineers Inc. (July 2018). https://doi.org/10.1109/ISMAR-Adjunct.2018.00054
Sugano, N., Kato, H., Tachibana, K.: The effects of shadow representation of virtual objects in augmented reality. Presented at the (2003)
Team, R.C.: R Core Team. R: A language and environment for statistical computing. Foundation for Statistical Computing (2013)
Vaziri, K., Liu, P., Aseeri, S., Interrante, V.: In: Impact of visual and experiential realism on distance perception in VR using a custom video see-through system, vol. 17, pp. 1–8. ACM Press, New York (2017). https://doi.org/10.1145/3119881.3119892
Ventura, J., Zollmann, S., Stannus, S., Billinghurst, M., Driancourt, R.: In: Understanding AR inside and out – Part Two, pp. 1–243. ACM, New York (2020). https://doi.org/10.1145/3388769.3407543
Wang, W., et al.: Holo3DGIS: leveraging Microsoft Hololens in 3D geographic information. ISPRS Int. J. Geo-Inf. 7(2), 60 (2018). https://doi.org/10.3390/ijgi7020060
Ware, C.: Information Visualization: Perception for Design: Second Edition. Elsevier (2004). https://doi.org/10.1016/B978-1-55860-819-1.X5000-6
Wilson, A., Hua, H.: Design and prototype of an augmented reality display with per-pixel mutual occlusion capability. Opt. Express 25(24), 30539 (2017). https://doi.org/10.1364/OE.25.030539
Wither, J., Hollerer, T.: In: pictorial depth cues for outdoor augmented reality, vol. ISWC 2005, pp. 92–99. IEEE (2005). https://doi.org/10.1109/ISWC.2005.41
Woldegiorgis, B.H., Lin, C.J., Liang, W.Z.: Impact of parallax and interpupillary distance on size judgment performances of virtual objects in stereoscopic displays. Ergonomics 62(1), 76–87 (2018). https://doi.org/10.1080/00140139.2018.1526328
Zhu, J., Pan, Z., Sun, C., Chen, W.: Handling occlusions in video-based augmented reality using depth information. Comput. Animation Virtual Worlds 21(5), 509–521 (2009). https://doi.org/10.1002/cav.326
Zollmann, S., Grasset, R., Langlotz, T., Lo, W.H., Mori, S., Regenbrecht, H.: Visualization techniques in augmented reality: a taxonomy, methods and patterns. IEEE Trans. Vis. Comput. Graph. (2020). https://doi.org/10.1109/TVCG.2020.2986247
Zollmann, S., Grasset, R., Reitmayr, G., Langlotz, T.: In: Image-based X-ray visualization techniques for spatial understanding in outdoor augmented reality, vol. 14, pp. 194–203. ACM Press, New York (2014). https://doi.org/10.1145/2686612.2686642
Zollmann, S., Hoppe, C., Kluckner, S., Poglitsch, C., Bischof, H., Reitmayr, G.: Augmented reality for construction site monitoring and documentation. Proc. IEEE 102(2), 137–154 (2014). https://doi.org/10.1109/JPROC.2013.2294314
Zollmann, S., Hoppe, C., Langlotz, T., Reitmayr, G.: FlyAR: augmented reality supported micro aerial vehicle navigation. IEEE Trans. Vis. Comput. Graph. 20(4), 560–568 (2014). https://doi.org/10.1109/TVCG.2014.24
Zollmann, S., Kalkofen, D., Mendez, E., Reitmayr, G.: In: Image-based ghostings for single layer occlusions in augmented reality, pp. 19–26. IEEE (2010). https://doi.org/10.1109/ISMAR.2010.5643546
Zollmann, S., Schall, G., Junghanns, S., Reitmayr, G.: Comprehensible and interactive visualizations of GIS Data in augmented reality. In: Bebis, G., et al. (eds.) ISVC 2012. LNCS, vol. 7431, pp. 675–685. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-33179-4_64
Acknowledgements
We gratefully acknowledge the support of ANRT (French National Association for Research and Technology). We also warmly thank Professor Laurence Nigay for her help during the shepherding process.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 IFIP International Federation for Information Processing
About this paper

Cite this paper
Becher, C., Bottecchia, S., Desbarats, P. (2021). Projection Grid Cues: An Efficient Way to Perceive the Depths of Underground Objects in Augmented Reality. In: Ardito, C., et al. Human-Computer Interaction – INTERACT 2021. INTERACT 2021. Lecture Notes in Computer Science(), vol 12932. Springer, Cham. https://doi.org/10.1007/978-3-030-85623-6_35
Download citation
DOI: https://doi.org/10.1007/978-3-030-85623-6_35
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-85622-9
Online ISBN: 978-3-030-85623-6
eBook Packages: Computer ScienceComputer Science (R0)