
Abstract
This paper deals with the deep learning revolution in Music Information Research (MIR), i.e. the switch from knowledge-driven hand-crafted systems to data-driven deep-learning systems. To discuss the pro and cons of this revolution, we first review the basic elements of deep learning and explain how those can be used for audio feature learning or for solving difficult MIR tasks. We then discuss the case of hand-crafted features and demonstrate that, while those where indeed shallow and explainable at the start, they tended to be deep, data-driven and unexplainable over time, already before the reign of deep-learning. The development of these data-driven approaches was allowed by the increasing access to large annotated datasets. We therefore argue that these annotated datasets are today the central and most sustainable element of any MIR research. We propose new ways to obtain those at scale. Finally we highlight a set of challenges to be faced by the deep learning revolution in MIR, especially concerning the consideration of music specificities, the explainability of the models (X-AI) and their environmental cost (Green-AI).
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Using Deep Neural Network (DNN) algorithms to represent the audio signal has been proposed as early as 1990 when Waibel et al. [121] proposed to use Time Delay Neural Network (TDNN) to allow the representation of the time-varying natures of phonemes in speech. Later, Bourlard et al. [14] convincingly demonstrated in their “connectionist speech recognition” the use of the discriminative projection capabilities of DNN to extract audio features. This has led, among others, to the development of the “tandem features” [48] which uses the posterior probabilities of a trained Multi-Layer-Perceptron (MLP) as audio features or the “bottleneck features” [45] extracted from the bottleneck part of a MLP. This has led today to the end-to-end speech recognition systems which inputs are directly the raw audio waveforms and the output the transcribed text [101, 102]. As 2012 is considered a landmark year for Computer Vision (with the AlexNet [66] network wining the ImageNet Large Scale Visual Recognition Challenge), it is also one for speech recognition with the publication of the seminal paper [52], jointly written by the research groups of the University of Toronto, Microsoft-Research, Google, and IBM-Research demonstrating the benefits of DNN architectures for speech processing.
1.1 The Deep Learning Revolution in MIR
The same year, 2012, Humphrey et al. [57] published a manifesto promoting the use of DNN for music audio processing. In this manifesto, the authors demonstrated that any hand-crafted feature (such as Mel-Frequency-Cepstral- Coefficients (MFCC) or Chroma) or algorithms (such as pitch, chord or tempo estimation) used so far are just layers of non-linear projections and pooling operations and can therefore be profitably replaced by the trainable non-linear projections of DNN.
With regard to this “deep learning revolution” announced in 2012, it is striking that the “Roadmap for Music Information Research” [108]Footnote 1 published in 2013, which was supposed to guide the MIR research for the next decade, has largely missed the warning signs. In this, only one sentence refers to deep learning and in an almost negative wayFootnote 2.
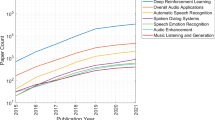
Since 2012, Deep Learning has progressively become the dominant paradigm in MIR. The large majority of MIR works, whether related to recognition or generation tasks, and whether based on audio, symbolic or optical-score data, rely on deep learning architectures.
1.2 What Is This Paper About?
Deep Learning (DL) is not (only) about a new Machine Learning (ML) algorithm to perform better classification or regression. It is mainly about finding homeomorphisms (performed by a cascade of non-linear projections) which allows representing the data in the manifold in which they live. This manifold hypothesis states that real-world high-dimensional data lie on low-dimensional manifolds embedded within this high-dimensional space (such as we perceive the earth as flat while it is a sphere; it is a 2D manifold embedded in a 3D space). Finding this manifold produces a space that makes classification and regression problems easier. It also allows new processes such as interpolation in it or generation from it. In this sense, deep learning does not only provide better representation of the data, better solutions to existing problem but also provides new paradigms for data processing. In part Sect. 2, we first review what deep learning is and how it can be used for audio feature learning and for solving difficult MIR tasks.
While Deep Neural Network (DNN) systems are indeed often “deep” learning systems, the authors of those often refer to the non-DNN systems (those based on handcrafted audio features) as “shallow” systems. They admit however that those are more easily explainable. We would like to show here that, while hand-crafted systems were indeed shallow and explainable at the start of MIR, they tended to be deep, data-driven and unexplainable over time. We discuss this in part Sect. 3.
One assumption made by one of the god-father of MIR [50] is that MIR had 4 successive ages: - the age of audio features, - the age of semantic descriptors, - the age of context-awareness systems and - the age of creative systems. It is somehow supposed that technology developments are driven by the desired applications. We argue here that most of these applications (semantic, creative) already existed from a long time. However, they were hardly achievable due to the limitation of the technology at that time. It is therefore rather the opposite: the (possible) applications are driven by the technology developments. While the idea of “music composition by a computer” dates back to half a century [51], making this a reality, as with the OpenAI “Jukebox generative model for music” [24], was only possible thanks to the latest advances in DL (VQ-VAE and Transformer). We also argue - that the technology developments were mainly possible in MIR thanks to the accessibility of large annotated datasets, - that hand-crafted audio features were “hand-crafted” because of the lack of annotated datasets that prevented using feature learning. When those became available in the 2000s, the first feature-learning systems were proposed (such as the EDS system [88]). Today, thanks to the large accessibility of those, DNN approaches are possible. We therefore support the idea that dataset accessibility defines the possible technology developments which define the (possible) applications. In part Sect. 4, we argue that annotated datasets have then become the essential elements in data-driven approaches such as deep learning and we propose new way to obtain those at scale.
Application of DL methods for the processing of audio and music signals, such as done in MIR, has for long ignored the specificities of this audio and music signal and at best adapted Computer Vision networks to time and frequency audio representations. Recently, a couple of DL methods started including such specificities, such as the harmonic structure of audio signals or their sound-production model. Those pave the way to the development of audio-specific DL methods. We discuss this challenge in part Sect. 5 as well as challenges related to the explainability of the DL models (X-AI) and to the development of models with low computational costs (Green-AI).
2 Deep Learning: What Is It?
We define Deep Learning here as a deep stack of non-linear projections, obtained by non-linearly connecting layers of neurons. This process, vaguely inspired by biological neural networks, was denoted by Artificial Neural Network (ANN) in the past and by Deep Neural Network (DNN) since [53]. Deep Learning encompasses a large set of possible algorithms (often considered as a “zoo”) which can be roughly organized according to - their architecture, i.e. the way neurons are connected to each other, - the way these architectures are combined into meta-architectures (defined by the task at hand) - the training paradigm which defines the criteria to be optimized.
2.1 DNN Architectures
A DNN architecture defines a function f with parameters \(\theta \) applied to an input x. Its output \(\hat{y}=f_{\theta }(x)\) approximates a ground-truth value y according to some measurements (a “Loss”). The parameters \(\theta \) are (usually) trained in a supervised way using a set of input/output pairs \((x^{(i)}, y^{(i)})\). The parameters \(\theta \) are (usually) estimated using one variant of the Steepest Gradient Descent: moving \(\theta \) in the opposite direction of the gradients of the Loss function w.r.t. to the \(\theta \). These gradients are obtained using the back-propagation algorithm [99]. The function f is defined by the architecture of the network. The three main architectures are:
Multi-Layer-Perceptron (MLP). In this, neurons of adjacent layers are organized in a Fully-Connected (FC) way, i.e. each neuron \(a_j^{[l]}\) of a layer [l] is connected to all neurons \(a_i^{[l-1]}\) of the previous layer \([l-1]\). The connections are done through multiplication by weights \(w_{ij}^{[l]}\), addition of a bias \(b_j^{[l]}\) and passing through a non-linear function (activation function) g (the common sigmoid, tanh or ReLu functions). Each \(w_{:j}^{[l]}\) therefore defines a specific projection j of the neurons i of the previous layer (as seen in Fig. 1).
Convolutional Neural Network (CNN). While the FC architecture does not assume any specific organization between the neurons of a given layer, in the CNN architecture we assume a local connectivity of those. This is done to allow representing the specificities of vision were nearby pixels are usually more correlatedFootnote 3 than far-away ones. To do so, each “spatial region” (x, y) of \(\vec {A}_i^{[l-1]}\) (which is now an image) is projected individually. The resulting projections of the (x, y) are also considered as an image, and is denoted by feature-map and noted \(\vec {A}_{i \rightarrow j}^{[l]}\) for the \(j^{th}\) projection. CNN also add a parameter sharing property: for a given j, the same projection \(\vec {W}_{ij}^{[l]}\) (which is now a matrix) is used to project the different regions (x, y), i.e. the weights are shared. Doing so allows to apply the same projectionFootnote 4 to the various regions (x, y) of \(\vec {A}_i^{[l-1]}\). Combining these two properties lead to the convolutional operator [39, 68], i.e. the projections are expressed as convolutions. In practice there are several input feature-maps \(\vec {A}_{1 \ldots i \ldots I}^{[l-1]}\), the convolution is performed over x and y with a tensor \(\vec {W}_{:j}^{[l]}\) that extends over I (as seen in Fig. 1). The result of this convolution is an output feature-map \(\vec {A}_j^{[l]}\). As MLP can have J different projections \(w_{:j}^{[l]}\), CNN can have J different convolutions \(\vec {W}_{:j}^{[l]}\); resulting in J output feature maps. As in MLP the output feature maps are the inputs of the next layer. CNN is the most popular architecture in Computer Vision.

Fully-Connected (as used in MLP), Convolutional (as used in CNN) and Recurrent (as used in RNN) architectures.
Temporal Convolutional Network (TCN). While attempts have been made to apply CNN to a 2D representation of the audio signal (such as its spectrogram), recent approaches [26] use 1D-Convolution directly applied on the raw audio waveform. The motivation of using such convolution is to learn better filters than the ones of usual spectral transforms (for example the sines and cosines of the Fourier transform). However, compared to images, audio waveforms are of much higher dimensionsFootnote 5. To solve this issue, [86] have proposed in their WaveNet model the use of 1D-Dilated-Convolutions (also named convolution-with-holes or atrous-convolution). The 1D-Dilated-Convolutions is at the heart of the Temporal Convolutional Network (TCN) [7] which is very popular in audio today.
Recurrent Neural Network (RNN). While CNN allows representing the spatial correlations of the data, they do not allow to represent the sequential aspect of the data (such as the succession of words in a text, or of images in a video). RNN [99] is a type of architecture with a memory that keeps track of the previously processed events of the sequence. For this, the internal/hidden representation of the data at time t, \(\vec {a}^{<t>}\), does not only depend on the input data \(\vec {x}^{<t>}\) but also on the internal/hidden representation at the previous time \(\vec {a}^{<t-1>}\) (as seen in Fig. 1). Because of this, RNN architectures have become the standard for processing sequences of words in Natural Language Processing (NLP) tasks. Because RNN can only store in memory the recent past, more sophisticated cells such as Long Short Term Memory (LSTM)[54] or Gated Re- current Units (GRU)[19] have been proposed for long-term memory storage.
2.2 DNN Meta-Architectures
The above architectures can then be combined in the following “meta-architectures”.
Auto-Encoder (AE). An AE is made of two sub-networks: - an encoding network \(\phi _e\) which projects the input data \(\vec {x} \in \mathbb {R}^M\) in a latent space of smaller dimensionality: \(\vec {z}=\phi _e(\vec {x}) \in \mathbb {R}^d\) (\(d<<M\)); - a decoding network \(\phi _d\) which attempts to reconstruct the input \(\vec {x}\) from \(\vec {z}\): \(\hat{\vec {y}}=\phi _d(\vec {z})\). \(\phi _e\) and \(\phi _d\) can be any of the architectures described above (MLP, CNN, RNN). AEs are often used for feature learning (\(\vec {z}\) is considered as a feature; \(\phi _e\) as a feature extractor). Many variations of this vanilla AE have been proposed to improve the properties of the latent space (Denoising AE, Sparse AE or Contractive AE).
Variational Auto-Encoder (VAE). In an AE, the latent space \(\vec {z}\) is not smooth. Because of this, it is not possible to sample a point from it to generate new data \(\hat{y}\). To allow this generation, VAEs [64] have been proposed. In a VAE, the encoder and decoder are considered as posterior probability \(p_{\theta }(\vec {z}|\vec {x})\) and likelihood \(p_{\theta }(\vec {x}|\vec {z})\). The encoder actually estimates the parameters of a distribution (here Gaussian for convenience); \(\vec {z}\) is then sampled from this estimated distribution and given to the decoder for maximizing the likelihood of \(\vec {x}\). Given the smoothness of the latent space \(\vec {z}\), it is possible to sample a point from it to generate new data \(\hat{y}\).
Generative Adversarial Network (GAN). Another popular type of network for generation is the GAN [41]. GAN only contains the decoder part of an AE here named “Generator” G. Contrary to the VAE, \(\vec {z}\) is here explicitly sampled from a chosen distribution \(p(\vec {z})\). Since \(\vec {z}\) does not arise from any existing real data, the Generator \(G(\vec {z})\) must learn to generate data that look real. This is achieved by defining a second network, the “Discriminator” D, which goal is to discriminate between real and fake (the generated ones) data. D and G are trained in turn using a minmax optimization.
Encoder/Decoder (ED). ED [19] or Sequence-to-Sequence [115] architectures can be considered as an extension of the AE for sequences: an input sequence \(\{\vec {x}^{<1>} \ldots \vec {x}^{<t>} \ldots \vec {x}^{<T_x>}\}\) of length \(T_x\) is encoded into \(\vec {z}\) which then serves as initialization for decoding a sequence \(\{\vec {y}^{<1>} \ldots \vec {y}^{<\tau>} \ldots \vec {y}^{<T_y>}\}\) of length \(T_y\) in another domain. Both sequences can have different lengths. This architecture is very popular in machine translation where an input English sentence is translated into an output French sentence (encoder and decoder are then RNNs). It is also used for generating text caption from input images [120] (the encoder is then a deep CNN and the decoder a RNN). Extensions of the ED or Sequence-to-Sequence architecture have been proposed to allows a better encoding of the input sequences information, as in the Attention Mechanism [6] or in the Transformer [119].
Neural Autoregressive Models. Autoregressive model aims at predicting a value \(x_n\) as a linear combination of its P preceding values: \(x_n=\sum _{p=1}^{P} a_p x_{n-p}\). In Neural Auto-regressive models, this linear combination is replaced by a DNN. For audio, the most popular model is probably Wavenet [86]. In this, the conditional probability distribution \(p(x_n|x_1,\ldots ,x_{n-1})\) is modeled by a stack of TCNs. The model is trained to predict \(x_n\) which is here discretized into classes.
2.3 DNN Training Paradigms and Losses
Once the architecture and meta-architecture are defined, one still has to define the criterion to be optimized during the training. This criterion corresponds to the task to be solved and is defined by a “loss” to be minimized by optimizing the parameters \(\theta \). Deep learning actually provides a large set of possible training paradigms. The most popular are the following.
Classification. In the simplest case of binary classification, the network has a single output neuron (with sigmoid activation) and is trained to estimate the probability of the positive class: \(\hat{y}=p(y=1|x)\). This is done by minimizing a Binary-Cross-Entropy (BCE) loss between y and \(\hat{y}\). In the most common case of multi-class classification (predicting a given class c among C mutually exclusive classes), the network has C output neurons (with softmax activations) which are trained to estimate the probability \(\hat{y_c}=p(y=c|x)\). This is done by minimizing a cross-entropy loss between the \(y_c\) and the \(\hat{y}_c\). The case of multi-label classification (C non-mutually exclusive classes) is processes as a set of C parallel binary classifications.
Reconstruction. When the goal of the network is to reconstruct the input data (such as with AE), the simple Mean Square Error (MSE) between the output and input data is used: \(MSE = \sum _{i=1}^N ||\vec {x}^{(i)} - \hat{\vec {y}}^{(i)}||^2\).
Metric Learning. Metric learning aims at automatically constructing (using ML) distance metrics from data. DNN provides a nice framework for this. In this, the parameters \(\theta \) of a network are learnt such that a distance function \(g(f_{\theta }(x), f_{\theta }(y))\) is minimized for similar training samples x and y and maximized for dissimilar samples. A common choice for g is the Euclidean distance. A popular method for this is the minimization of a “triplet loss” [105]). In this, three data samples are simultaneously considered: an anchor a, a positive p (similar to a) and a negative n (dissimilar to a). The goal is to iteratively train the network on such triplets to ensure that the distance between \(f_{\theta }(p)\) and \(f_{\theta }(a)\) is smaller than between \(f_{\theta }(n)\) and \(f_{\theta }(a)\).
2.4 Deep Learning for Audio Feature Learning
We first highlight here why it make sense to use deep learning for learning audio and music representations. To phrase Humphrey et al. [57] in their manifesto, a DNN is “a cascade of multiple layers, composed of a few simple operations: affine transforms, point-wise non-linearities and pooling operators. Cascaded non-linearities allow for complex systems composed of simple, linear parts. Music is composed by hierarchies of pitch and loudness forming chords and melodies, phrases and sections, eventually building entirely pieces. Deep structures are well suited to encode these relationships.” At the lowest level, a large part of the most-commonly used audio signal processing algorithms can be formulated as a cascade of affine transformations, non-linear transforms and pooling operations. This is for example the case of the Discrete-Fourier-Transform (DFT). In this the signal is projected on a set of basis (affine transform) from which the absolute value can be taken (point-wise non-linearity). This is also the case of the MFCC or of the Chroma as illustrated in Fig. 2. Principal Component Analysis (PCA) or Non Negative Matrix Factorization (NMF) are also linear affine transformations but are learnt. The only difference between these transformations lies in their parameterization. DL hence provides a convenient framework to learn such parametrization from the data.
Following this idea, the training of “deep-chroma” (a “chroma” representation obtained as the output of a trained DNN) have for example been proposed in [65] (using chord recognition as a pretext task) or [125] (using weakly aligned score-audio pairs as pretext task). In both of these, DL is not used to achieve the final task (chord or alignment) but only to get a better chroma representations.
NMF can also be reformulated using DL as proposed in Smaragdis et al. [113] using a deep AE. In NMF, an observed matrix \(X \in \mathbb {R}^+\) is reconstructed as the product of a basis-matrix \(W \in \mathbb {R}^+\) with an activation-matrix \(H \in \mathbb {R}^+\): \(\hat{X}=W \cdot H\). By comparison, in an AE, X is reconstructed by passing z (which plays the same role as H) in the decoder \(\phi _d\) (which plays the same role as W): \(\hat{X}=\phi _d(z)\). A positivity can be imposed by using ReLu activations. NMF can then be considered a linear version of the more expressive AE.

Figure adapted from [56].
Deep Neural Network for feature learning. [Top] A neural network as a cascade of matrix multiplication, non-linearity and pooling operations. [Bottom left] MFCC computation flowchart as cascade of affine transforms and non-linearities, [Bottom right] same from Chroma computation.
2.5 Deep Learning for Solving Difficult MIR Tasks
Apart from audio feature learning, DL can be used to solve difficult MIR tasks. We consider here three of those.
Blind Audio Source Separation (BASS) deals with the development of algorithms to recover one or several source signals \(s_j(t)\) from a given mixture signal \(x(t)=\sum _j s_j(t)\) without any additional information. For a long time, BASS algorithms relied on the application of Computational Auditory Scene Analysis (CASA) principles [16] or matrix decomposition methods (mostly ICA or NMF). In recent years DNN methods have allowed to largely improve the separation quality by formulating it as a supervised task: a model is trained to transform an input mixed signal x(t) to an output separated source \(s_j(t)\) or to an output separation mask \(m_j(t)\) to be applied to the input \(s_j(t)=x(t) \odot m_j(t)\). Such a DNN model often takes the form of a Convolutional Denoising Auto- Encoder (CDAE) (as in Computer Vision) where CNN encoder and decoder are trained to reconstruct the clean signal from its noisy version. However, such a CDAE tends to blur the fine details of the spectrogram. In Jansson et al. [59], a U-Net architecture [98] is then proposed: it is an AE with skip-connections between the encoder and the decoder (see Fig. 3). It has been applied to a spectrogram representation to isolate the singing voice from realFootnote 6 polyphonic music. The network is trained to output a Time/Frequency mask \(M_j(t,f)\) which is applied to the amplitude Short-Time Fourier Transform (STFT) of the mixture |X(t, f)| to separate the amplitude STFT of the isolated source \(|S_j(t,f)|=|X(t,f)| \odot M_j(t,f)\). This simple network has provided a large increase in source separation performances.

Figure adapted from [58].
Source separation using a U-Net architecture.
Cover Detection. “Covers” denote the various recorded interpretations of a same musical composition (for example “Let It Be” performed by The Beatles or performed by Aretha Franklin). For a long time, two tracks were considered covers of each other if they shared similar harmonic content over time. This content was represented by the sequence of Chroma vectorsFootnote 7 of the track. Tracks were then compared pair-by-pair by computing the cost necessary to align their respective sequences. This cost was generally obtained using Dynamic Time WarpingFootnote 8 as in [107]. This led to a computationally expensive algorithm. Also only one facet of the problem was considered: the harmonic content. While it is hard to define exactly why two tracks are “covers” of each otherFootnote 9, it is easy to provide examples and counter-examples of those. This is the approach proposed by Doras et al. in [27,28,29]. In this, the content of a track is represented using jointly a Constant-Q-Transform (CQT), the sequence of its estimated dominant melody and multi-pitches. Those are fed to deep CNN networks which architecture projects them to a time-less vector. The weights of the deep CNN are then trained using a triplet loss paradigm [105], i.e. given simultaneously an anchor track, a positive example (a cover of the anchor) and a negative example (a non-cover of the anchor) a triplet loss is minimized. This simple formulation has provided a large increase in cover-detection performances.

Figure adapted from [83].
Music translation using Auto-Encoder with reconstruction and adversarial losses.
Music Translation aims at translating an input music track \(\vec {x}\) with {musical instruments, genres, and style} i to an output y with {musical instruments, genres, and style} j while preserving the musical score. In Mor et al. [83], this ambitious goal is achieved without explicitly extracting the musical score and with a single but smart network illustrated in Fig. 4. We detail this system here since it is quite representative of current audio DL systems. The network has the form of an AE. An encoder E (a single WaveNet [86] for all i) is used to project \(\vec {x}\) in the latent space \(\vec {z}\). \(\vec {z}\) is then used to reconstruct an output music track with {musical instruments, genres, and style} j. This is achieved by specific decoders \(D^j\) for each j (which are all WaveNet decoders). The encoder and decoder are trained to minimize a reconstruction loss between \(\vec {x}\) and \(\vec {y}\). However, for the translation to work, it is important that \(\vec {z}\) does not contain information related to the {musical instruments, genres, and style} i, and only contains information related to the musical score. To achieve the disentanglement of \(\vec {z}\), a classifier C is first trained to recognize i from \(\vec {z}\). With C fixed (the parameters are not changed anymore), we then add an adversarial loss, i.e. we train the encoder E to maximize a classification loss (to guarantee that it is not possible to recognize i from \(\vec {z}\)). The final system is then trained to minimize the reconstruction loss and maximize the adversarial loss. While difficult to quantity, convincing music translation results are obtained with this systemFootnote 10.
3 Deep Learning: Was the Learning so Shallow and Explainable Before?
Deep learning systems are often denoted as “deep” in comparison to the hand-crafted systems previously used in MIR which are considered “shallow”. We argue here that while hand-crafted systems were indeed shallow and explainable at the start of ISMIR, they tended to be deep, data-driven and unexplainable over time. To demonstrate this, we consider four main trends (almost chronological) in audio feature design.
3.1 Audio Feature Design: The Timbre Period
Around 2004, the design of audio features was mostly driven by the description of the timbre aspect of the sound or its acoustic characteristics. On one side, timbre scalar features (such as spectral centroid/ spread/ flux, fundamental frequency, loudness, harmonic to noise ratio, log-attack time) [90] were developed with the purpose of allowing their direct semantic interpretation (“brightness”, “sharpness”, “noisiness”). These features were audio signal algorithms constructured to be by-design invariant to unwanted variations (such as designing the spectral centroid to be invariant to the recording level of the signal, or the harmonic spectral centroid to the pitch). Interestingly by comparison, in DL systems, these invariances need to be learned from the data or by explicitly imposing “adversarial losses” (as we have seen above for the music translation network of [83]). These timbre features have for example been used - to provide a semantic understanding of the underlying dimensions of the “timbre spaces”Footnote 11 or - in the first instrument recognition systems, as the one of Jensen et al. [60] illustrated in Fig. 5. Given the interpretability of the features and the ML model used at that time (here a binary decision tree), it leads to associate hand-crafted systems with explainable systems.

Figure from [60].
Instrument classification using timbre features and binary decision tree.
On the other side, features were developped to provide a representation of the whole timbre characteristics as a single vector. In speech processing, the well-known MFCC [15] were proposed. Those use the underlying model of speech production (the source/filter model) combined with a simplified model of perception (critical bands are modeled by a Mel scale). Without much justification, those were then considered also as the timbre representation of polyphonic multi-source music [72]. To describe the harmonic content of a signal, a Chroma (also named Pitch-Class-Profile) [38, 122] vector representation was proposed.
For complex recognition task (such as drum recognition [49] or large-scale instrument recognition [91]), Automatic Feature Selection algorithms were then developped to allow automatically selecting, from the pool of hand-crafted features, the most relevant for a task at hand. It is interesting to consider that, already at that time, a debate existed related to whether it was better to automatically select the most relevant hand-crafted features or to automatically generate those (using genetic algorithms in [88]).
3.2 Audio Feature Design: The Dynamic Features
All the above representations allowed the description of the sound content around a given time without much consideration of the temporal aspects of the sound (with the exception of the log-attack-time or spectral flux). The temporal evolution of the sound properties was usually simply represented using delta, delta-delta or the first two statistical moments of the features (mean and standard deviation). While this simplification may hold for a stationary process, it surely does not for non-stationary signals as music. Because of this, more sophisticated temporal models were developed around 2010 as the “block-level” features [110]. In those, elaborated summary of the temporal behavior of the audio features are proposed based on the computation of specific percentiles of histogram of the features, temporal correlation pattern or fluctuation pattern (amplitude modulation coefficients weighted by psychoacoustic models).
3.3 Audio Feature Design: Taking Inspiration from Auditory Physiology and Neuro-Science
A completely different path on feature design arose from auditory physiology and neuro-science. As demonstrated in the work of [104]“the mammalian auditory system has a specialized sensitivity to amplitude modulation of narrowband acoustic signals”. This has opened the path to the development of audio features specialized in representing these modulations, such as the modulation spectrogram [4, 44] the first and second order modulation spectrogram with inter-band correlation [33, 79], the Spectro Temporal Receptive Fields [18] or the well-mathematically-formulated Joint Time/Frequency scattering transform based on a cascade of wavelet transforms [1]. As demonstrated by Mallat [74] this scattering representation actually shares many of the properties of the Deep Learning CNN architecture while providing an explanation to its success.
3.4 Audio Feature Design in Speech: Toward Deep Trained Models
Audio feature design owes speech processing a lot. Between the MFCCs and the Deep Learning eraFootnote 12, a large set of deep features have been proposed for speech processing. For example, the so-called supervector features [96] were proposed for speaker identification. Those represent the necessary adaptationFootnote 13 of a Uni- versal Background Model (UBM) to represent a target speaker. This UBM is a Gaussian Mixture Model used to pave the space of possible MFCCs values for speech. Joint Factor Analysis [61] or i-Vector [23] further extended this idea by decomposing the supervector into speaker independent, speaker dependent, transmission-channel and residual components. Those deep features have been used very successfully to describe non-speech sounds (audio scene classification [32] or music [17, 31]). In these representations, ML is used as a way to find the projection space. Matching pursuit (decomposition of a sound as a set of atoms or molecules), Non Negative Matrix Factorization or Probabilistic Latent Component Analysis have also been used to train projections of the data which facilitate recognition task (for example pitch and instrument in Leveau et al. [70], pitch only in Smaragdis et al. [112] or vocal-imitations in Marchetto et al. [75]).
With the above in mind, we can say that considering hand-crafted systems as shallow and explainable is an over-simplification of the reality. While this was true at the beginning, the last hand-crafted systems (such as the one based on i-Vectors illustrated in Fig. 6) were for sure deep and hardly explainable.

Figure from [71].
Advanced system for speaker recognition based on i-Vector representation, Gaussianized Cosine Distance Scoring (GCDS), Regularized Logistic Regression (L2LR), Universal Background Support SVM (UBSSVM) and Probabilistic Linear Discriminant Analysis (PLDA).
However, a major difference between hand-crafted systems and deep learning system lies in their construction. Hand-crafted systems are designed by optimizing separately the successive stages of the system (such as improving the audio features, their automatic selection/ transformation, the classification algorithm). In the opposite, in deep learning those are just parts of a single DNN which parameters are all jointly optimized (as we have seen above for the music translation network of [83]).
4 Deep Learning: Datasets
We Argue Here that Annotated Datasets are Probably the Most Sustainable Part of Any MIR Research Today. This statement seems obvious if we consider that DL approaches are data-driven approaches and that therefore the knowledge is in the annotated data. Another way to demonstrate this is to consider that the outputs of a research program are: (1) scientific reasoning or experimental results (as published in scientific papers), (2) program code (as published on github.com), (3) annotated dataset (as published on zenodo.org). In audio-content-analysis, (1) is usually achieved by applying the most recent ML algorithms (Gaussian Mixture Model, Hidden Markov Model, Support Vector Machine in the past, DL today). (1) is therefore likely to change as quickly as the advances of ML. (2) is associated to programming environment. While Matlab has been the leading environment for numerical computing for long (hence the development of the Timbre toolbox [90] or the MIR toolbox [67] in Matlab), it has been replaced by the fastest C/C++ (hence the development Marsyas [117], Yaafe [76] or Essentia [13] library in C++); which has been replaced by the much-more-easy-to-use data-science programming language python (hence the development of the librosa [80] package). Only (3) seems sustainable.
However, for long, annotated datasets have only been considered as side tools necessary to validate the scientific reasoning. Regarding this, it is interesting to consider that the GTZAN dataset (one of the most used dataset) was actually not published but only used internally by the authors to validate their experiment in [118]. The first published datasets, AIST-RWC [42, 43] and QMUL-Isophonic [77], were only presented as posters or “late-breaking-news/demo” during conferences. Despite that, they all had an enormous influence on MIR research. Today, in the new data-driven area (where knowledge arise directly from the data), things have however changed: a significant part of the papers presented at the ISMIR conference concern such datasets, and the TISMIR journal has a dedicated track for those.
As a proof of the importance and sustainability of this datasets, it is interesting to consider the most cited works of well-known researchers: - Georges Tzanetakis most cited contribution relates to the GTZAN dataset [118]: 3446 citationsFootnote 14, - Thierry Bertin-Mahieux to Million-Song-Dataset [10]: 1161 citations, - Masataka Goto second and third most cited contributions to AIST-RWC [42, 43]: 744 and 586 citations, - Rachel Bittner to Medley-DB [12]: 264 citations.
4.1 New Practices for the Development of MIR Annotated Datasets
The development of such MIR annotated datasets follows several paths: - the recording of new audio material (McGill Sound Library [87], Ircam Studio-On-Line [8], AIST-RWC [42], ENST MAPS [34], Medley-DB [12]), - the use of copyright-free material (Jamendo [94], FMA [22]), - the use of copyrighted material (GTZAN [118], Harmonix [84]). The annotation process also follows different paths: - careful-manual-annotations (AIST-RWC [42]), - crowd-sourced annotations (Million-Song-Dataset [10]), - web-grabbed annotations (Ircam DALI [82]). The size of those also seems to increase over time; according to [58]: from one hour of audio in 2000 to one year of audio in 2020.
It is interesting to consider how trends in DL as used in multimedia, Computer Vision or Natural Language Processing also progressively influence MIR practices for the development of MIR annotated datasets.
Data-Augmentation. Among those, data-augmentation aims at extending the set of training data in order to better cover the distribution p(x, y). Indeed, training a ML system is equivalent to try to approximate the unknown distribution p(x, y) between its inputs x and outputs y. While unknown, the distribution p(x, y) is observed through a set of pairs \((x^{(i)},y^{(i)})\) (the training data) sampled from this distribution. The goal of training is to minimize a risk on these data (Empirical Risk Minimization). Data augmentation aims at increasing the coverage performed by these samples. This is done by extending the set of \(x^{(i)}\) (using processing) while preserving \(y^{(i)}\). In audio, such processing are - the addition of noise, - equalization, - distortion, - quantification, - time-stretc.hing, - pitch-shifting. While the data can be augmented automatically, the set of possible augmentations should be decided manually based on a prior knowledge of the relationship between x and y. For example, pitch-shifting (time-stretching) cannot be applied blindly to \(x^{(i)}\) if the labels \(y^{(i)}\) depend on pitch information (on tempo information). This may seem counter-intuitive since the goal of ML is precisely to acquire the knowledge of the relationship between x and y. Data-augmentation has for example been used in Cohen-Hadria et al. [21] to increase the training data for a singing-voice separation task.
Semi-Supervised Learning. Semi-Supervised Learning (Semi-SL) combines training with a small amount of labeled data and training with a large amount of unlabeled data. One popular form of Semi-SL used the so-called teacher-student paradigm. It is a supervised learning technique in which the knowledge of a teacher (a model trained on clean labeled data) is used to label a large set of unlabeled data which is used in turn to train student models. It has for example been used in audio - by Aytar et al. [5] in SoundNet to transfer knowledge from Computer Vision models to audio models (using the synchronization of images and audio channels in Audio-Video clips), - by Wu et al. [124] to train deep learning models for drum transcription (using the output of Partially-Fixed-NMF model for the same task), or - by Meseguer-Brocal et al. [81] to train deep learning models for singing-voice detection (by iterating the training using the output of a deep CNN initialized with clean data).
Self-Supervised Learning. Self-Supervised Learning (Self-SL) is a supervised learning technique in which the training data are automatically labeled. To automatically create labels, one can use the natural temporal synchronization between the various modalities of multi-media data as used in the “Look, Listen and Learn” [2], “Object that Sounds” [3] or “Sound of the Pixels” [126] networks. It is also possible to train the network to predict a modification of the input: such as cropping, distorting or rotating an image, or shuffling a video sequence. In audio, such an approach has been proposed by Gfeller et al. [40] in SPICE (Self-supervised Pitch Estimation) to predict the pitch transposition factor applied to the input. As for data augmentation, the set of processes applied to the input is directly governed by the nature of the data to be described by the network. Therefore, as for data augmentation, one should have a prior knowledge of the relationship between x and y to decide on the set of processes to be applied.
The aim of these three approaches is to allow the automatic annotation of audio data and hence to allow the development of very large annotated datasets.
5 Deep Learning: What Are the Challenges for Deep MIR?
We highlight here a set of challenges for deep-MIR.
5.1 Toward Taking into Account Audio and Music Specificities in Models
The first challenge relates to the necessity to develop Deep Learning models that take into account the specificities of audio and music. While it seems obvious to do so, it has not been the case at the start. To understand this, we need to sum up the short history of DNN for audio. We do so by distinguishing four successive periods. Those correspond to increasing consideration/integration of audio/music specificities/knowledge in the models.
First Period: Time-Frequency Representation. The first attempts to use DNN for audio signals date back to 1990 where Waibel et al. [121] proposed a so-called Time-Delay Neural Network (TDNN), an architecture similar to a 1-D convolution over time. As most models proposed in the first periodFootnote 15, the audio is represented by a time-frequency representation: a Mel-spectrogram in [121]. In MIR, time-frequency representation inputs have also been used at the start of DL. For example, Dieleman [25] used this representation as input to a CNN but only performed convolution over time. In the opposite, Choi et al. [20] considered time/frequency representations as natural images and applied a Computer Vision CNN to it, hence performing convolution both over time and frequency.
However, time/frequency representations cannot be considered as natural images. In natural images - the two axis x and y represent the same concept (spatial position), - the elements of an image have the same meaning independently of their positions over x and y, - the neighboring pixels are usually highly correlated (they often belong to the same object). In time-frequency representations - the two axis x and y represent profoundly different concepts (time and frequency), - the elements of a spectrogram have the same meaning independently of their positions over time but not over frequency, - the neighboring pixels of a spectrogram are not necessarily correlated (the harmonics of a given sound source can be distributed over the whole frequency in a sparse way and interleaved with the ones of another source). Because of this, when using CNN architectures, one should carefully choose the shape of the filters and the axis along which the convolution is performed. Therefore, as opposed to Choi et al. [20], Pons et al. [92] specifically addresses these differences by designing musically-motivated filters. The shapes of the CNN filters are carefully chosen to allow representing the timbre (vertical filters extending over the frequency axis) or the rhythm (horizontal filters extending over the time axis) content of a music track.
Second Period: End-To-End Systems. While musically-motivated CNN filter shape is a promising path, one still has to manually design this shape for a given application. Also, one has to decide what is the most appropriate 2D representation (STFT, Log-Mel-Spectrogram (LMS), CQT) and its parameters (window size, hop size, number of bands) for a given application. For these reasons, the so-called “end-to-end” approaches, which consider directly the raw audio waveform as input, have been developed. In those, a 1D-convolution (a convolution over time with 1D-filters) on the waveform is used for the first layer of the network. This is the case of [26] with large temporal filters or of [63, 69] in Sample-CNN with a cascade of small temporal filters. While these filters can theoretically re-learn the sines and cosines basis of the Fourier transform (or Gamma-tone filters in [100]), in practice their training often lead to noisy and hardly interpretable temporal basis. One reason for this is the lack of Time Translation Invariance (TTI). TTI is a property of a transform that makes it insensitive to the time translation (or phase shift) of the input. The modulus/amplitude of the DFT (as used in the spectrogram) is TTI.
Third Period: Introducing Audio Signal Knowledge. With this in mind, Ravanelli et al. [95] proposed SincNet, a deep learning model which defines the 1D-filters as a parametric function g (the difference between two sinc functions) which theoretical frequency responses are parameterizable band pass filters. The training therefore consists in estimating the parameters of g. To deal with the TTI property, Noe et al. [85] extended SincNet to the complex domain in the Complex Gabor CNN. It is also possible to use knowledge of the underlying sound-production-model to construct DNN models. Such models can be the source/filter modelFootnote 16 or the harmonic modelFootnote 17. For example, in Basaran et al. [9] the source/filter model is assumed. A NMF source/filter model [30] is first used. A DNN is then fed with the source activation matrix to predict the dominant melody. The Deep Salience network of Bittner et al. [11] assumes an harmonic model. This model leads to the development of an Harmonic CQT which is fed to a DNN to predict the dominant melody. The aims of the Harmonic CQT is to bring back the vicinity of the harmonics of a sound (spread over the whole spectrum) by projecting each frequency f into a third dimension (the depth of the input) which represents the values of the spectrum at the harmonics hf. Combining the idea of SincNet with the Harmonic CQT leads to the Harmonic-CNN of Won et al. [123]. In this the 1D-convolution is performed with filters constrained as for SincNet but extended to the harmonic dimensions (stacking band-pass filters at harmonic frequencies \(h f_c\)).
Fourth Period: Implementing a Sound-Production-Model as a Network. Just as SincNet defines the 1D-filters as parametric functions g and trains the parameters of g, Engel et al. propose in their Differentiable Digital Signal Processing (DDSP) [35] to represent a sound-production-model (here the Spectral Modeling Synthesis (SMS) model [109]) as a network. The network combines harmonic additive synthesis (adding together many harmonic sinusoidal components) with subtractive synthesis (filtering white noise) and extra room acoustics (another convolution by room impulse response). Since the network is differentiable, it can be trained to estimate the SMS parameters and the room impulse response to reproduce a given sound.
It is striking that the most recent fourth period actually brings back the old signal-based SMS model [109] in a deep learning version: the network is trained to predict the parameters of the harmonic-plus-noise model (as were the peak-picking and partial-tracking algorithms in the 90s).
Pursuing this integration of the audio and music specificities in DNN is a challenge. This will allow to prevent audio network simply being Computer Vision networks applied to audio and would facilitate their understanding (X-AI) and reducing their cost (Green-AI) as we see now.
5.2 Explainable AI (X-AI)
Despite their impressive performances, deep neural networks remains largely intriguing. According to Szegedy et al. [116] “Deep neural networks are highly expressive models that have recently achieved state of the art performance on speech and visual recognition tasks. While their expressiveness is the reason they succeed, it also causes them to learn uninterpretable solutions that could have counter-intuitive properties.”
(a) One such intriguing property is the case of adversarial examples as discussed in Szegedy et al. [116]. Those are small, hardly perceptible, perturbations of the input data that lead the network to drastically change its output decision (such as adding a small perturbation to an input image of a “panda” that makes it recognized as a “gibbon”). Kereliuk et al. [62] demonstrated that deep learning systems for music content analysis are also sensitive to these adversarial attacks.
(b) Another intriguing property is the case of non-trained deep neural networks (a neural network with random weights) which can achieve significant performances. Saxe et al. [103] show that the classification performance of Support Vector Machines (SVMs) fed with features extracted from a non-trained CNN show significant performances for image classification. This seems to demonstrate that the performances can be attributed to the architecture of the network itself, not to its weights (which are randomly chosen here). As proposed by Pons et al. [93], a possible explanation is the similarity between [103] experiment (which somehow uses CNN as a tool to perform a random projection) and Extreme Machine Learning [55] (which uses a single-layer MLP with random weights to feed a trainable layer). Pons et al. [93] demonstrate the same effect for MIR applications: genre, rhythm class or acoustic event recognition with random projections.
(c) Lastly, the “lottery ticket hypothesis” [37] argue that “a large neural network contains a smaller subnetwork that, if trained from the start, will achieve a similar accuracy than the larger structure”; or in another word, that the architecture can be changed but the initialization of the weights for training the amputed-network should be the same. (b) and (c) therefore seems in contradiction: while (b) says that only the architecture matter and not the weight, (c) says that the architecture can be amputed but the initialization weights should be the same. In MIR, Esling et al. [36] demonstrated that this lottery ticket hypothesis can also be used in typical networks performing instrument, pitch, chord or drum recognition with only 10% of the initial network.
Because of these intriguing properties, Explainable AI (X-AI) has been a growing field over the past years. “X-AI refers to methods and techniques in the application of artificial intelligence technology (AI) such that the results of the solution can be understood by humans. It contrasts with the concept of the “black box” in machine learning where even their designers cannot explain why the AI arrived at a specific decision.” In X-AI, two main approaches have been developed so far. In the post-hoc approaches, the network is interpreted afterward. Example of this are the local linear proxy of LIME [97], saliency maps of [111], or the tree explainer of [73]. In the explainability by design approach, the architecture of a network is modified to make it interpretable. Example of this are the generation of visual explanations in [47] or the FLINT framework of [89].
In MIR, XAI still need to be developed.
5.3 Green-AI
As stated in the position paper of Schwarz et al. [106], “The computations required for deep learning research have been doubling every few months, resulting in an estimated 300,000x increase from 2012 to 2018. These computations have a surprisingly large carbon footprint. Ironically, deep learning was inspired by the human brain, which is remarkably energy efficient.” As examples of this carbon footprint, Strubell et al. [114] compare the estimated CO2 emissions of - a round-trip flight (1 passenger, NY \(\leftrightarrow \) SF): 1984 lbs, - Human life (avg, 1 year): 11 023 lbs, - a US car including fluel (avg 1 lifetime): 126 000 lbs and - the training of a recent Natural Language Processing DNN (Transformer): 626 155 lbs.
This observation led [106] to promote a “Green-AI”, an AI research that yields novel results without increasing computational cost, and ideally reducing it. This “Green-AI” is opposed to the traditional AI, here renamed “Red AI”, which is an AI research that seeks to obtain state-of-the-art results in accuracy (or related measures) through the use of massive computational power—essentially, “buying” stronger results. To move toward Green-AI, Henderson et al. [46] propose to report in research papers, along the accuracy results obtained with a given system, the energy and carbon footprints implied in the research of this system (training and hyper-parameters optimization).
While it does not seem at first that MIR is so much concerned by “Green-AI”, the recent Jukebox’ model for music generation published by OpenAI [24]—which opens a new era of large-size MIR models—surely is. According to the authors of [24]: “The upsamplers have one billion parameters and are trained on 128 V100s for 2 weeks, and the top-level prior has 5 billion parameters and is trained on 512 V100s for 4 weeks”.
Notes
- 1.
- 2.
“More recently, deep learning techniques have been used for automatic feature learning in MIR tasks, where they have been reported to be superior to the use of hand-crafted feature sets for classification tasks, although these results have not yet been replicated in MIREX evaluations. It should be noted however that automatically generated features might not be musically meaningful, which limits their usefulness.”.
- 3.
such as the adjacent pixels that form a “cat’s ear”.
- 4.
such as \(\vec {W}_{ij}^{[l]}\) represeting a “cat’s ears” detectors.
- 5.
1 s of an audio signal with a sampling rate of 100 Hz is a vector of dimension 44 100.
- 6.
non-synthetic.
- 7.
or more elaborated versions of it.
- 8.
or more elaborated algorithms.
- 9.
Consider the case of “Blurred Lines” by Pharrell Williams and Robin Thicke and “Got to Give It Up” by Marvin Gaye.
- 10.
- 11.
The “timbre spaces” are the results of a Multi-Dimensional-Scaling (MDS) analysis of similarity/dissimilarity user ratings between pairs of sounds as obtained through perceptual experiments [78].
- 12.
The idea of using DL for representation learning in audio was initially proposed in the case of speech as described in [52].
- 13.
using an Expectation-Maximization algorithm.
- 14.
The citation figures are derived from Google Scholar as of December 15th, 2020.
- 15.
- 16.
where a sound x(t) is considered as the results of the convolution of a periodic source signal s(t) with a filter h(t): \(x(t) = (s * e) (t)\).
- 17.
where a sound with a pitch \(f_0\) is represented in the spectral domain as a set of harmonically related components at frequencies \(h f_0, h \in \mathbb {N}^+\) with amplitudes \(a_h\).
References
Andén, J., Lostanlen, V., Mallat, S.: Joint time-frequency scattering for audio classification. In: Proceedings of IEEE MLSP (International Workshop on Machine Learning for Signal Processing) (2015)
Arandjelovic, R., Zisserman, A.: Look, listen and learn. In: Proceedings of IEEE ICCV (International Conference on Computer Vision) (2017)
Arandjelović, R., Zisserman, A.: Objects that sound. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11205, pp. 451–466. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01246-5_27
Atlas, L., Shamma, S.A.: Joint acoustic and modulation frequency. EURASIP J. Adv. Signal Process. 2003(7), 1–8 (2003)
Aytar, Y., Vondrick, C., Torralba, A.: Soundnet: learning sound representations from unlabeled video. In: Proceedings of NIPS (Conference on Neural Information Processing Systems) (2016)
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. In: Proceedings of ICLR (International Conference on Learning Representations) (2015)
Bai, S., Kolter, J.Z., Koltun, V.: An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271 (2018)
Ballet, G., Borghesi, R., Hoffman, P., Lévy, F.: Studio online 3.0: an internet ’killer application’ for remote access to ircam sounds and processing tools. In: Proceeding of JIM (Journées d’Informatique Musicale). Issy-Les-Moulineaux, France (1999)
Basaran, D., Essid, S., Peeters, G.: Main melody extraction with source-filter NMF and C-RNN. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Paris, France, 23–27 September 2018
Bertin-Mahieux, T., Ellis, D.P., Whitman, B., Lamere, P.: The million song dataset. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Miami, Florida, USA (2011)
Bittner, R., McFee, B., Salamon, J., Li, P., Bello, J.P.: Deep salience representations for f0 estimation in polyphonic music. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Suzhou, China, 23–27 October 2017
Bittner, R.M., Salamon, J., Tierney, M., Mauch, M., Cannam, C., Bello, J.P.: Medleydb: a multitrack dataset for annotation-intensive MIR research. ISMIR 14, 155–160 (2014)
Bogdanov, D., et al.: Essentia: an audio analysis library for music information retrieval. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Curitiba, PR, Brazil (2013)
Bourlard, H.A., Morgan, N.: Connectionist Speech Recognition A Hybrid Approach, vol. 247. Springer, US (1994)
Bridle, J.S., Brown, M.D.: An experimental automatic word recognition system. JSRU report 1003(5), 33 (1974)
Brown, G.J., Cooke, M.: Computational auditory scene analysis. Comput. Speech Lang. 8(4), 297–336 (1994)
Charbuillet, C., Tardieu, D., Peeters, G.: GMM supervector for content based music similarity. In: Proceeding of DAFx (International Conference on Digital Audio Effects), Paris, France, pp. 425–428, September 2011
Chi, T., Ru, P., Shamma, S.A.: Multiresolution spectrotemporal analysis of complex sounds. J. Acoust. Soc. Am. 118(2), 887–906 (2005)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: Proceedings of EMNLP (Conference on Empirical Methods in Natural Language Processing) (2014)
Choi, K., Fazekas, G., Sandler, M.: Automatic tagging using deep convolutional neural networks. In: Proceedings of ISMIR (International Society for Music Information Retrieval), New York, USA (2016)
Cohen-Hadria, A., Roebel, A., Peeters, G.: Improving singing voice separation using deep u-net and wave-u-net with data augmentation. In: Proceeding of EUSIPCO (European Signal Processing Conference), Coruña, Spain, 2–6 September 2019
Defferrard, M., Benzi, K., Vandergheynst, P., Bresson, X.: FMA: a dataset for music analysis. In: Proceeding of ISMIR (International Society for Music Information Retrieval), Suzhou, China, 23–27 October
Dehak, N., Kenny, P., Dehak, R., Dumouchel, P., Ouellet, P.: Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 19(4), 788–798 (2011)
Dhariwal, P., Jun, H., Payne, C., Kim, J.W., Radford, A., Sutskever, I.: Jukebox: a generative model for music. arXiv preprint arXiv:2005.00341 (2020)
Dieleman, S.: Recommending music on spotify with deep learning. Technical report (2014). http://benanne.github.io/2014/08/05/spotify-cnns.html
Dieleman, S., Schrauwen, B.: End-to-end learning for music audio. In: 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 6964–6968. IEEE (2014)
Doras, G., Peeters, G.: Cover detection using dominant melody embeddings. In: Proceeding of ISMIR (International Society for Music Information Retrieval), Delft, The Netherlands, 4–8 November 2019
Doras, G., Peeters, G.: A prototypical triplet loss for cover detection. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), Barcelona, Spain, 4–8 May 2020
Doras, G., Yesiler, F., Serra, J., Gomez, E., Peeters, G.: Combining musical features for cover detection. In: Proceeding of ISMIR (International Society for Music Information Retrieval), Montreal, Canada, 11–15 October 2020
Durrieu, J.L., Richard, G., David, B., Févotte, C.: Source/filter model for unsupervised main melody extraction from polyphonic audio signals. IEEE Trans. Audio Speech Lang. Process. 18(3), 564–575 (2010)
Eghbal-zadeh, H., Lehner, B., Schedl, M., Gerhard, W.: I-vectors for timbre-based music similarity and music artist classification. In: Proceeding of ISMIR (International Society for Music Information Retrieval), Malaga, Spain (2015)
Elizalde, B., Lei, H., Friedland, G.: An i-vector representation of acoustic environments for audio-based video event detection on user generated content. In: 2013 IEEE International Symposium on Multimedia, pp. 114–117. IEEE (2013)
Ellis, D.P.W., Zeng, X., McDermott, J.: Classifying soundtracks with audio texture features. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), pp. 5880–5883. IEEE (2011)
Emiya, V., Badeau, R., David, B.: Multipitch estimation of piano sounds using a new probabilistic spectral smoothness principle. IEEE Trans. Audio Speech Lang. Process. 18(6), 1643–1654 (2010)
Engel, J., Hantrakul, L., Gu, C., Roberts, A.: DDSP: differentiable digital signal processing. In: Proceeding of ICLR (International Conference on Learning Representations) (2020)
Esling, P., Bazin, T., Bitton, A., Carsault, T., Devis, N.: Ultra-light deep LIR by trimming lottery tickets. In: Proceeding of ISMIR (International Society for Music Information Retrieval), Montreal, Canada, 11–15 October 2020
Frankle, J., Carbin, M.: The lottery ticket hypothesis: finding sparse, trainable neural networks. In: Proceeding of ICLR (International Conference on Learning Representations) (2019)
Fujishima, T.: Realtime chord recognition of musical sound: a system using common lisp music. In: Proceedings of ICMC (International Computer Music Conference), pp. 464–467. Beijing, China (1999)
Fukushima, K., Miyake, S.: Neocognitron: a self-organizing neural network model for a mechanism of visual pattern recognition. In: Amari, S., Arbib, M.A. (eds.) Competition and Cooperation in Neural Nets, pp. 267–285. Springer, Heidelberg (1982)
Gfeller, B., Frank, C., Roblek, D., Sharifi, M., Tagliasacchi, M., Velimirović, M.: Spice: self-supervised pitch estimation. IEEE/ACM Trans. Audio Speech Lang. Process. 28, 1118–1128 (2020)
Goodfellow, I., et al.: Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680 (2014)
Goto, M.: Aist annotation for the RWC music database. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Victoria, BC, Canada, pp. 359–360 (2006)
Goto, M., Hashiguchi, H., Nishimura, T., Oka, R.: RWC music database: popular, classical, and jazz music databases. In: Proceeding of ISMIR (International Society for Music Information Retrieval), Paris, France, pp. 287–288 (2002)
Greenberg, S., Kingsbury, B.E.: The modulation spectrogram: In pursuit of an invariant representation of speech. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), vol. 3, pp. 1647–1650. IEEE (1997)
Grézl, F., Karafiát, M., Kontár, S., Cernocky, J.: Probabilistic and bottle-neck features for lvcsr of meetings. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), vol. 4, pp. IV-757. IEEE (2007)
Henderson, P., Hu, J., Romoff, J., Brunskill, E., Jurafsky, D., Pineau, J.: Towards the systematic reporting of the energy and carbon footprints of machine learning. arXiv preprint arXiv:2002.05651 (2020)
Hendricks, L.A., Akata, Z., Rohrbach, M., Donahue, J., Schiele, B., Darrell, T.: Generating visual explanations. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 3–19. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_1
Hermansky, H., Ellis, D.P., Sharma, S.: Tandem connectionist feature extraction for conventional hmm systems. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), vol. 3, pp. 1635–1638. IEEE (2000)
Herrera, P., Yeterian, A., Gouyon, F.: Automatic classification of drum sounds: a comparison of feature selection methods and classification techniques. In: Proceedings of ICMAI (International Conference on Music and Artificial Intelligence), Edinburgh, Scotland (2002)
Herrera, P.: MIRages: an account of music audio extractors, semantic description and context-awareness, in the three ages of MIR. Ph.D. thesis, Music Technology Group (MTG), Universitat Pompeu Fabra, Barcelona (2018)
Hiller Jr, L.A., Isaacson, L.M.: Musical composition with a high speed digital computer. In: Audio Engineering Society Convention 9. Audio Engineering Society (1957)
Hinton, G., et al.: Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups. IEEE Signal Process. Mag. 29(6), 82–97 (2012)
Hinton, G.E., Osindero, S., Teh, Y.W.: A fast learning algorithm for deep belief nets. Neural Comput. 18(7), 1527–1554 (2006)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Huang, G.B., Zhu, Q.Y., Siew, C.K.: Extreme learning machine: theory and applications. Neurocomputing 70(1–3), 489–501 (2006)
Humphrey, E.J.: Tutorial: Deep learning in music informatics, demystifying the dark art, Part III - practicum. In: Proceeding of ISMIR (International Society for Music Information Retrieval), Curitiba, PR, Brazil (2013)
Humphrey, E.J., Bello, J.P., LeCun, Y.: Moving beyond feature design: deep architectures and automatic feature learning in music informatics. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Porto, Portugal (2012)
Jansson, A.: Musical Source Separation with Deep Learning and Large-Scale Datasets. Ph.D. thesis, City University of Mondon (2020)
Jansson, A., Humphrey, E.J., Montecchio, N., Bittner, R., Kumar, A., Weyde, T.: Singing voice separation with deep u-net convolutional networks. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Suzhou, China, 23–27 October 2017
Jensen, K., Arnspang, K.: Binary decision tree classification of musical sounds. In: Proceedings of ICMC (International Computer Music Conference), Bejing, China (1999)
Kenny, P., Boulianne, G., Ouellet, P., Dumouchel, P.: Speaker and session variability in GMM-based speaker verification. IEEE Trans. Audio Speech Lang. Process. 15(4), 1448–1460 (2007)
Kereliuk, C., Sturm, B.L., Larsen, J.: Deep learning and music adversaries. IEEE Trans. Multimedia 17(11), 2059–2071 (2015)
Kim, T., Lee, J., Nam, J.: Sample-level CNN architectures for music auto-tagging using raw waveforms. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing) (2018)
Kingma, D.P., Welling, M.: Auto-encoding variational Bayes. In: Proceedings of ICLR (International Conference on Learning Representations) (2013)
Korzeniowski, F., Widmer, G.: Feature learning for chord recognition: The deep chroma extractor. In: Proceedings of ISMIR (International Society for Music Information Retrieval), New York, USA, 7–11 August 2016
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks. In: Proceedings of NIPS (Conference on Neural Information Processing Systems), pp. 1097–1105 (2012)
Lartillot, O., Toiviainen, P.: A matlab toolbox for musical feature extraction from audio. In: Proceeding of DAFx (International Conference on Digital Audio Effects), pp. 237–244. Bordeaux (2007)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Lee, J., Park, J., Kim, K.L., Nam, J.: Sample-level deep convolutional neural networks for music auto-tagging using raw waveforms. arXiv preprint arXiv:1703.01789 (2017)
Leveau, P., Vincent, E., Richard, G., Daudet, L.: Instrument-specific harmonic atoms for mid-level music representation. IEEE Trans. Audio Speech Lang. Process. 16(1), 116–128 (2007)
Liu, G., Hansen, J.H.: An investigation into back-end advancements for speaker recognition in multi-session and noisy enrollment scenarios. IEEE Trans. Audio Speech Lang. Process. 22(12), 1978–1992 (2014)
Logan, B.: Mel frequency cepstral coefficients for music modeling. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Plymouth, Massachusetts, USA (2000)
Lundberg, S.M., et al.: Explainable AI for trees: from local explanations to global understanding. arXiv preprint arXiv:1905.04610 (2019)
Mallat, S.: Understanding deep convolutional networks. PhilosophicalTransactions (2016)
Marchetto, E., Peeters, G.: Automatic recognition of sound categories from their vocal imitation using audio primitives automatically found by SI-PLCA and HMM. In: Aramaki, M., Davies, M.E.P., Kronland-Martinet, R., Ystad, S. (eds.) CMMR 2017. LNCS, vol. 11265, pp. 3–22. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01692-0_1
Mathieu, B., Essid, S., Fillon, T., Prado, J., Richard, G.: Yaafe, an easy to use and efficient audio feature extraction software. In: Proceedings of ISMIR (International Society for Music Information Retrieval), pp. 441–446. Utrecht, The Netherlands (2010)
Mauch, M., et al.: Omras2 metadata project 2009. In: Late-Breaking/Demo Session of ISMIR (International Society for Music Information Retrieval), Kobe, Japan (2009)
McAdams, S., Windsberg, S., Donnadieu, S., DeSoete, G., Krimphoff, J.: Perceptual scaling of synthesized musical timbres: common dimensions specificities and latent subject classes. Psychol. Res. 58, 177–192 (1995)
McDermott, J., Simoncelli, E.: Sound texture perception via statistics of the auditory periphery: evidence from sound synthesis. Neuron 71(5), 926–940 (2011)
McFee, B., et al.: librosa: audio and music signal analysis in python. In: Proceedings of the 14th Python in Science Conference, vol. 8, pp. 18–25 (2015)
Meseguer Brocal, G., Cohen-Hadria, A., Peeters, G.: Dali: a large dataset of synchronized audio, lyrics and pitch, automatically created using teacher-student. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Paris, France, 23–27 September 2018
Meseguer Brocal, G., Peeters, G.: Creation of a large dataset of synchronised audio, lyrics and notes, automatically created using a teacher-student paradigm. Trans. Int. Soc. Music Inf. Retrieval 3(1), 55–67. https://doiorg/105334/tismir30 2020
Mor, N., Wolf, L., Polyak, A., Taigman, Y.: A universal music translation network. In: Proceedings of ICLR (International Conference on Learning Representations) (2019)
Nieto, O., McCallum, M., Davies, M., Robertson, A., Stark, A., Egozy, E.: The harmonix set: Beats, downbeats, and functional segment annotations of western popular music. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Delft, The Netherlands, 4–8 November
Noé, P.G., Parcollet, T., Morchid, M.: Cgcnn: Complex gabor convolutional neural network on raw speech. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), Barcelona, Spain, 4–8 May 2020
van den Oord, A., et al.: WaveNet: a generative model for raw audio. arXiv preprint arXiv:1609.03499 (2016)
Opolko, F., Wapnick, J.: Mcgill university master samples cd-rom for samplecellvolume 1 (1991)
Pachet, F., Zils, A.: Automatic extraction of music descriptors from acoustic signals. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Barcelona (Spain) (2004)
Parekh, J., Mozharovskyi, P., d’Alche Buc, F.: A framework to learn with interpretation. arXiv preprint arXiv:2010.09345 (2020)
Peeters, G.: A large set of audio features for sound description (similarity and classification) in the cuidado project. Cuidado project report, Ircam (2004)
Peeters, G., Rodet, X.: Hierachical gaussian tree with inertia ratio maximization for the classification of large musical instrument database. In: Proceedingg of DAFx (International Conference on Digital Audio Effects), pp. 318–323. London, UK (2003). peeters03c
Pons, J., Lidy, T., Serra, X.: Experimenting with musically motivated convolutional neural networks. In: Proceedings of IEEE CBMI (International Workshop on Content-Based Multimedia Indexing) (2016)
Pons, J., Serra, X.: Randomly weighted cnns for (music) audio classification. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing) (2019)
Ramona, M., Richard, G., David, B.: Vocal detection in music with support vector machines. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), Las Vegas, Nevada, USA, pp. 1885–1888 (2008)
Ravanelli, M., Bengio, Y.: Speaker recognition from raw waveform with sincnet. In: 2018 IEEE Spoken Language Technology Workshop (SLT). pp. 1021–1028. IEEE (2018)
Reynolds, D., Quatieri, T., Dunn, R.: Speaker verification using adapted gaussian mixture models. Digit. Signal Proc. 10(1–3), 19–41 (2000)
Ribeiro, M.T., Singh, S., Guestrin, C.: “why should i trust you?” explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 1135–1144 (2016)
Ronneberger, O., Fischer, P., Brox, T.: U-Net: convolutional networks for biomedical image segmentation. In: Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F. (eds.) MICCAI 2015. LNCS, vol. 9351, pp. 234–241. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back-propagating errors. Nature 323(6088), 533–536 (1986)
Sainath, T.N.: Towards end-to-end speech recognition using deep neural networks. In: Proceedings of ICML (International Conference on Machine Learning) (2015)
Sainath, T.N., Vinyals, O., Senior, A., Sak, H.: Convolutional, long short-term memory, fully connected deep neural networks. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), pp. 4580–4584. IEEE (2015)
Sainath, T.N., Weiss, R.J., Senior, A., Wilson, K.W., Vinyals, O.: Learning the speech front-end with raw waveform CLDNNS. In: Sixteenth Annual Conference of the International Speech Communication Association (2015)
Saxe, A.M., Koh, P.W., Chen, Z., Bhand, M., Suresh, B., Ng, A.Y.: On random weights and unsupervised feature learning. In: Proceeding of ICML (International Conference on Machine Learning), vol. 2, p. 6 (2011)
Schreiner, C.E., Urbas, J.V.: Representation of amplitude modulation in the auditory cortex of the cat. i. the anterior auditory field (aaf). Hearing Res. 21(3), 227–241 (1986)
Schroff, F., Kalenichenko, D., Philbin, J.: Facenet: A unified embedding for face recognition and clustering. In: Proceedings of IEEE CVPR (Conference on Computer Vision and Pattern Recognition), pp. 815–823 (2015)
Schwartz, R., Dodge, J., Smith, N.A., Etzioni, O.: Green AI. CACM, Assoc. Comput. Mach. 63, 54–63 (2020)
Serrà, J., Gomez, E., Herrera, P., Serra, X.: Chroma binary similarity and local alignment applied to cover song identification. IEEE Trans. Audio Speech Lang. Process. (2008)
Serra, X., et al.: Roadmap for Music Information Research. Creative Commons BY-NC-ND 3.0 license (2013). ISBN: 978-2-9540351-1-6
Serra, X., Smith, J.: Spectral modeling synthesis: a sound analysis/synthesis system based on a deterministic plus stochastic decomposition. Comput. Music J. 14(4), 12–24 (1990)
Seyerlehner, K.: Content-based music recommender systems: beyond simple frame-level audio similarity. Ph.D. thesis, Johannes Kepler Universität, Linz, Austria, December 2010
Simonyan, K., Vedaldi, A., Zisserman, A.: Deep inside convolutional networks: Visualising image classification models and saliency maps. In: Proceedings of ICLR (International Conference on Learning Representations) (2014)
Smaragdis, P., Brown, J.C.: Non-negative matrix factorization for polyphonic music transcription. In: Proceedings of IEEE WASPAA (Workshop on Applications of Signal Processing to Audio and Acoustics), New Paltz, NY, USA, pp. 177–180. IEEE (2003)
Smaragdis, P., Venkataramani, S.: A neural network alternative to non-negative audio models. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing). pp. 86–90. IEEE (2017)
Strubell, E., Ganesh, A., McCallum, A.: Energy and policy considerations for deep learning in NLP. Proceedings of ACL (Conference of the Association for Computational Linguistics) (2019)
Sutskever, I., Vinyals, O., Le, Q.V.: Sequence to sequence learning with neural networks. In: Proceedings of NIPS (Conference on Neural Information Processing Systems), pp. 3104–3112 (2014)
Szegedy, C., et al.: Intriguing properties of neural networks. In: Proceedings of ICLR (International Conference on Learning Representations) (2013)
Tzanetakis, G., Cook, P.: Marsyas: a framework for audio analysis. OrganisedSound 4(3) (1999)
Tzanetakis, G., Cook, P.: Musical genre classification of audio signals. IEEE Trans. Speech Audio Process. 10(5), 293–302 (2002)
Vaswani, A., et al.: Attention is all you need. In: Proceedings of NIPS (Conference on Neural Information Processing Systems), pp. 5998–6008 (2017)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: Proceedings of IEEE CVPR (Conference on Computer Vision and Pattern Recognition), pp. 3156–3164 (2015)
Waibel, A., Hanazawa, T., Hinton, G., Shikano, K., Lang, K.J.: Phoneme recognition using time-delay neural networks. In: Readings in Speech Recognition, pp. 393–404. Elsevier (1990)
Wakefield, G.H.: Mathematical representation of joint time-chroma distributions. In: Proceedings of SPIE conference on Advanced Signal Processing Algorithms, Architecture and Implementations, Denver, Colorado, USA, pp. 637–645 (1999)
Won, M., Chun, S., Nieto, O., Serra, X.: Data-driven harmonic filters for audio representation learning. In: Proceedings of IEEE ICASSP (International Conference on Acoustics, Speech, and Signal Processing), Barcelona, Spain, 4–8 May 2020
Wu, C.W., Lerch, A.: Automatic drum transcription using the student-teacher learning paradigm with unlabeled music data. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Suzhou, China, 23–27 October 2017
Zalkow, F., Müller, M.: Using weakly aligned score-audio pairs to train deep chroma models for cross-modal music retrieval. In: Proceedings of ISMIR (International Society for Music Information Retrieval), Montreal, Canada, 11–15 October 2020, pp. 184–191
Zhao, H., Gan, C., Rouditchenko, A., Vondrick, C., McDermott, J., Torralba, A.: The Sound of Pixels. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11205, pp. 587–604. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01246-5_35
Acknowledgments
The content of this paper is partly based on a set of keynotes given at the “Berlin Interdisciplinary Workshop on Timbre” (2017/01), at the “Digital Music Research Network Workshop” in London (2018/12), at the “International Symposium on Computer Music Multidisciplinary Research” in Marseille (2019/10) and at the “Collège de France” in Paris (2020/02). The author is grateful to the respective organizers for their invitations. The author is also grateful to Giorgia Cantisani and Florence d’Alché-Buc for sharing materials and Laure Pretet for proof-reading.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Peeters, G. (2021). The Deep Learning Revolution in MIR: The Pros and Cons, the Needs and the Challenges. In: Kronland-Martinet, R., Ystad, S., Aramaki, M. (eds) Perception, Representations, Image, Sound, Music. CMMR 2019. Lecture Notes in Computer Science(), vol 12631. Springer, Cham. https://doi.org/10.1007/978-3-030-70210-6_1
Download citation
DOI: https://doi.org/10.1007/978-3-030-70210-6_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-70209-0
Online ISBN: 978-3-030-70210-6
eBook Packages: Computer ScienceComputer Science (R0)