
Abstract
Recommendation system has been seen to be very concentrated on individual recommendations but few of the new techniques are now concentrated on groups. The aim of this paper is to provide an overview of the existing state of the art techniques for collecting ratings, strategies used in aggregating these strategies and the practical application for group recommendations. This study explored five databases which include IEEE, Science Direct, Springer, ACM and Google Scholar, from which 300 publications were screened. Irrelevant, duplicate and ambiguous papers were removed. At the end, 26 papers were used for depth analysis. This study provides a systematic review of the available evidence based literature concerning recommender systems for groups.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

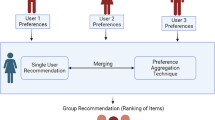
Keywords
1 Introduction
There exists much research done in the individual recommendation system but there are many other situations in which group recommendation comes in handy. Instances, where a restaurant needs to be chosen for a group to dine, is one of the typical examples of a recommendation system. People have also come up with different kinds of strategies for group recommendations [10]. Some of which are commonly used and easy to understand but the best strategy for all systems is still not known, not all strategies are optimal in all cases. Different ways of explicitly or implicitly collecting information about the user is another area where a lot of work has been done [5, 9]. Many issues and challenges have been seen in this area. Few of which have been taken into consideration but others are yet to be solved [11].
In Table 1, the sub-tasks and differences are given briefly. The steps that a recommendation system follows is divided into sub-tasks in the table above and difference between individual and group recommendations for every step is highlighted. During these steps, certain issues are encountered. In this paper, only the first sub-task that deal with acquiring information about the members’ preferences are considered. This sub-task differs in the sense that if the recommendation system collects the information explicitly then the users may find seeing each other’s preference advantageous. Users can get an idea of what to expect in the recommendations if they see other people’s recommendations. It can also give them the idea of the item to be rated if the user finds a person with similar taste in the group. The issues could be how beneficial this is to the user and how the system will use this technique. Other tasks include how the system will generate recommendations and how it should be applied to the group recommendation, how the system will give out the information and how the users will come about a final decision. The goal of the paper is to give an overview on the group recommendation categories, preference of elicitation and some experiments done by previous researchers. The rest of the paper is structured as follows: Sect. 2 discusses the related works of recommendation systems. Section 3 addresses the preference of elicitation. Techniques of elicitation of preferences are presented in Sect. 4. In Sect. 5, the strategies are categorized and explained. Section 6 sheds a light on the applications of these strategies and finally, Sect. 7 concludes this work.
2 Related Works
In this section, some of the works previously done in the literature are presented. Many recommendation system exists in the vacation area. Examples of which include Travel Decision Forum and Collaborative Advisory Travel System (CATS). The former is primarily used by a group of people who are planning a vacation together. This system lets the group decide on the desired attributes for choosing a vacation package. All the individual preferences are aggregated and only explicit elicitation is likely to be possible since the user needs to give ratings about all the attributes taken into consideration [1]. The latter is another system that helps in choosing a joint holiday. According to the preference of the user regarding features and packages the system recommends holidays. Users can provide suggestions for other group members and the suggestions are checked against the preferences of group members. The more the preferences are matched the likely the item will be recommended [12].
The entertainment area also has some known systems which are PolyLens, Adaptive Radio, MusicFX, TV recommender, FIT and FlyTrap. PolyLens is an extension of MovieLens which is primarily used by a group of people who want to go to a movie together. Movies are recommended based on social filtering and individual tastes are inferred from previous ratings. People can form a group together and recommendations for that group is given by the system. The members of the group rate individual movies and not describe the movie preferences [1]. Adaptive Radio can be used by colleagues working together in an office to play songs on the radio. This system plays songs autonomously based on preferences and the members of the group. It only gets feedback when the user is dissatisfied with the performance of the radio [5]. MusicFX recommends a radio station for a group of people in a fitness center [13]. TV recommender and FIT suggests a television program to watch for a group of people [14, 15]. The recommendations of TV recommender are based on the preference of users according to certain features whereas FIT assumes that the choices of people will change when they are in a group. FIT implicitly collects information regarding the watching times of the individual person and updates the member preferences accordingly. FlyTrap is also used in the music field to play tracks for the people in a public area of a building [16].
Let’s Browse on the other hand was used mainly by people browsing the web together. The system takes into consideration the members of the group by suggesting new recommendation which might be of interest to the members. Let’s Browse automatically detects the presence of the users, dynamically displays the user profiles and provides explanations of the recommendations [2]. IM-TAG, a web 2.0 tool offers recommendations of mentoring contents built upon personal competencies of the mentee, combined with content and opinion tagging [27]. Pocket RestaurantFinder is used mostly when colleagues plan to go together to dine in a restaurant. It helps in selecting the restaurant for the group, but for all the types of the cuisines, restaurant amenities, price categories and travel time the user needs to give a rating on a 5-point scale [3]. Group Adaptive Information and News System (GAIN) adapts the news and advertisements according to the people viewing a wall display or information kiosk. It also takes into account uncertainty about which users will be viewing the display at any given time [4]. INTRIGUE is widely used by people who are visiting a tourist place in a group or sightseeing group. The system divides the group into homogeneous subgroups with the same characteristics. Each subgroup may fit into stereotypes. The problem might be that group may visit more than one place and a balanced sequence selection has not been addressed in the research work [6]. Another recommendation system in the field of tourism was proposed by authors in [26]. The proposed recommendation system collects data from the initial visit by the means of pervasive approaches and offers relevant recommendations based on positioning and bio-inspired recommender systems.
3 Elicitation of Preference
Preference acquisition is the method of collecting information from the user. This method can be explicit or implicit. There still exist many recommender systems that use methods for acquiring information from an individual and generalize it for a group [7]. In this section, methods specifically developed for group recommendation as well as methods for individual recommendation will be discussed.
3.1 Acquisition of Preferences Without Explicit Specification
Some recommendations do not require the user to explicitly enter the information but rather collect information from other means in other words, implicit collection of information [8, 9]. An instance of a system that uses this method is Let’s Browse. This system is primarily used in web pages recommendation for a group. Initial candidates who might interest the user are chosen by analyzing the words available on the web page of the user. After all, the words are collected and groups are formed, then the system recommends the common words of all members that existed during the group visit.
3.2 Acquisition of Preferences with Explicit Specification
This method explicitly requires users to enter the information typically about all the features. Instances of systems include Pocket RestaurantFinder which lets the user choose the cuisine types, location, and price, Travel Decision Forum which lets the user choose destinations, facilities, and sightseeing. Users have a lot of information to fill out to get a precise recommendation. This process is usually tedious for the user and tends to provide only confined results.
3.3 Adapting Preference Specification to the Requirements of Group Recommendation
Focus on Negative Preferences. In this method, the user expresses a dislike towards a feature and the system tries to eliminate that feature for future recommendations. For instance, the system might not recommend action movies if any of the users in a group dislikes it. An instance is the Adaptive Radio [5] which recommends music to a group of people. The system avoids playing the disliked music tracks. The major difference between this system is that it elicits negative preference about music tracks than eliciting a more detailed type of ratings.
Sharing Information About Specified Preferences. People in a group may have some interest in knowing the preference of other group members so that it gives idea or suggestions to the user about him/herself. If the user knows someone that has similar preferences then he/she can use those preferences for better future recommendations. Sometimes, user can get new information from other users. These other users can be friends, family members and colleagues who have had experience in different areas or have tried something new which the user might like to try. Other users can also influence user and this usually happens because of peer group influence, relationships, etc. So, the user has a lot of options for making recommendations better by using other resources rather than relying on himself. An instance of this system is the Travel Decision Forum. This lets you see the preference of other members of the group. An additional feature suggested by [7] is to add brief verbal explanations for the ratings so the user knows whether the rating applies to him or not.
Some additional features can be added to the interfaces of the recommendation systems for improved predictions. Considering other people’s preference is one of the mechanisms for group recommendations. If a user is shown other members’ preference she/he might adapt accordingly to the group. For instance, if there is a person of 65 years or a kid of 5 years, the other members can adapt to their preferences thereby giving respect or importance to the kid or old-aged. A way to tackle this situation is showing the preference of the individual members to the whole group. This may give an idea about ratings to other users or adjust the ratings.
The problem also arises when the predictions are not what the group expected. In this case, it makes sense to test against the predicted preferences. Users can use yes/no mechanism to select whether the prediction is suitable for them or not. The system can then adapt to the recommendations accordingly. Explanations can also be quite helpful for recommendations. The reason why a certain item was not chosen by the user gives a sense of understanding to other users. The other users can then decide whether the option should be still considered for the group. The group may decide to have an open discussion with the members to resolve conflicts or come to a consensus.
Better recommendations can be made by better interfaces. Interfaces that contain preference of all users side by side on the screen can help the current user in many different ways. An addition of a feature regarding negotiability is also a feasible method of handling recommendations. For instance, while selecting features for a holiday vacation, the user may choose not to negotiate on certain features such as parking facilities but for other features, he/she might be open for other recommendations. The group may want to choose only certain features and may not care about others. So adding/removing a feature accordingly can come in handy. An option of choosing 2 or 3 similar users provided by the system or can be chosen by the user to generate a recommendation for one user may prove to be very useful when the user is new to the system with no preferences. It will save time and effort for the user rather when the user would enter everything manually.
4 Techniques for Elicitation of Preference
4.1 Techniques Based on Machine Learning Approaches
Author in [19] uses Regression Tree Learning (RTL) where target variable is utility of each item and the description of items are the samples. The regression tree defines a partitioning of the original outcome space by use of axis-parallel linear constraints, with each partition corresponding to a leaf node in the tree. Two problems in this approach can occur. One of which is that addition of a new item can change the predictions dramatically. This may cause cold start problems. The other is the problem of collecting information for new users. Accurate predictions can’t occur until sufficient information about users is gotten. They solve this by running the RTL algorithm over all the texts and discarding any information on the user giving each rating. In this paper however, we are focusing more on the user interactions so this won’t be discussed in detail.
4.2 Techniques Based on Interaction Mode
Pairs of items are drawn out from user interactions which are then used for training the ranking model.
Sub-list Ranking. In this mode, subsets of items are sorted which then forms a completely ordered list of preferences. The higher the item in the list the more that item is preferred over other items. At least two items are required in the list so that a pair is formed. This is the most common mode for recommendation systems. Sub-list ranking is depicted in Fig. 1(a).
Categorical Binning. A subset of items are grouped into high, medium and low by the user. Items within each group are not compared but items in the higher group are preferred more than ones in medium and low category. A user can put an item in two or three groups. Any number of items can be put into the groups and at least two items are required to be put into different groups for a ranking to be displayed. Categorical binning is depicted in Fig. 1(b).
Pairwise comparison In this mode, users have to group pair of items into a binary category such as high and low. Items in the high category are preferred over the ones in the low. A user has the freedom to put one item many times if that item is preferred over many other items. Pairwise comparison is depicted in Fig. 1(c).
Since this techniques is applicable for a single user, further work can be done in generalizing this to group recommendations. The interface could also be developed in a way that the user sees what the other users chose. Multiple users can be then combined using different aggregation strategies discussed in Sect. 5.

Preference elicitation interfaces.
4.3 Techniques Based on Algorithm
Authors in [14] proposes an algorithm for user profile merging based on total distance minimization. Three strategies namely group agent, merging recommendations and merging user profiles are presented and analysed in brief. In group agent strategy, the members of the group login with one account and put the preferences using that account to generate a common profile. Merging recommendations lets the individual to enter the preferences and then those individual preferences are merged into one profile. Aggregation techniques mentioned in the next section will be quite helpful in this regard. Any of the strategies can be adopted to merge user profiles. The merged profile now has a list of common preference for the group. In merging user profiles, all user profiles are first merged into a common profile and then recommendations are generated for the common user profile.
First strategy is the simplest but non-adaptive and inflexible. It doesn’t work if any of the group members are missing. A new group has to be created every time excluding the missing member. The other two strategies are considered in this work. In a user profile, many features and weights indicating the significance of these features are considered. A lexicon is defined by all the features of the user profiles alphabetically. The feature list can be reduced by using a thesaurus. Each user profile is denoted as a vector V. The algorithm measures the inconsistency between two preferences and defines the merging result. The merging of the results takes into account feature selection and weight assignment. Feature selection is the process of choosing features that will be considered in providing recommendations for the common profile. This is based on distance minimization. On the other hand, weights are consistent for user profiles but in explicit ratings the users may perceive different criteria for ratings. To solve this problem, weight normalization is used for each feature and then the weight of the feature of merged profile is calculated by adding all the normalized weight of a feature for each user profile divided by the number of members in the group. The authors also did an experiment in which they asked the group of 5 members to rank a list of programs and assign similarity scores. The similarity scores had a range of 0.1 to 0.9 with steps of 0.1, these scores were then compared with the algorithm’s similarity values. Authors in this paper claim that merging user profiles strategy is superior to merging recommendations after performing certain experiments.
4.4 Techniques Based on Reviews
Instead of explicitly asking user preferences, more information can be extracted from the reviews and feedback of users. Authors in [21] present some techniques on how to incorporate feedback with preferences.
-
Frequent terms: An easy way to analyse reviews is to count the frequency of each term. Each term could be assigned a weight measure which would represent the significance of each term. The terms can then be used to classify the user on term based user profile.
-
Overall opinion: This opinion takes into account the general opinion of the item. It can be concluded from the review that the user had a positive review about the hotel. These opinions can also be inferred from the numerical scale rating of the item. Whereas overall opinion from text based can be gotten from applying machine learning techniques such as naive Bayesian classifier or Support Vector Machine (SVM) which will categorize the items properly.
-
Feature opinion: Collecting information about the features instead of the whole item can come in handy when classifying many items. In Fig. 2, feature opinion is underlined in blue. The underlined features such as ‘The gym facility was excellent’ and ‘Service was attentive and gracious, appointments were luxurious, location was convenient’ tells us more about the features of the hotel such as location, gym facility or service. The opinion can be identified by looking at the adjectives of the sentences. For instance, luxurious, excellent, attentive are some of the words describing the reviews. These reviews can be classified under positive or negative to classify the recommendations. Many techniques have been used in the past for feature opinion such as associative rule mining, SVM based method, lexicalized Hidden Markov Model (L-HMMs) and many others.
-
Comparative opinions: As the name implies, this opinion can only be considered when there is a comparison between two or more items [22]. The comparison is done to highlight the similarities or differences of features. The differences might qualify one of the items to be better or worse than the other items. In Fig. 2, it is underlined in red. The underlined sentence compares this hotel with two other hotels, St. Regis’ is considered better while Westins heavenly stateside is worse than this hotel according to the user.
-
Contextual opinions: In this method, a set of contexts can be defined such as location, component and frequency and the words in the sentence can then be categorized under the identified contexts accordingly. For instance, in Fig. 2, a sentence is underlined in yellow. The sentence has a location context of company, component context of Hong Kong office and the frequency context of first visit.

A hotel review example
5 Categorization of Strategies
After the necessary information such as rating or feature selection is gained through elicitation of preferences, this information can now be used in producing recommendations. The ratings could be gained implicitly or explicitly from the defined process in Sect. 3. The ratings used in strategies are aggregated for group thereby giving appropriate recommendations. This section deals with the different strategies for aggregating the individual to group recommendations. 5 different categories have been proposed in this section. In Table 2, this sample table is going to be used as a reference throughout this section.
-
Voting Strategies: This category consists of Plurality voting and Approval voting.
-
Plurality voting: Each group member votes with the highest individual preference for a particular alternative. In other words, when a sequence of items is needed to be chosen, the item with the most votes are chosen repetitively [11]. For instance, For instance, from the table given above, given only one alternative, Mary has a tendency to choose item 1, 5 or 9 respectively, user James tends to chooses item 2, 4, 6 or 8 whereas user John chooses item 1. Item 1 has the most tendency to get selected for this group in this case (Table 3).
-
Approval Voting: This strategy takes a threshold value into account and only values above the threshold are considered for votes [10]. The values above the threshold are depicted as “1” whereas values below are denoted by “0”. For instance, choosing the threshold value as 6, the new values of the table are given in Table 4. The new ranking of the items are (5, 6),(1, 4, 8, 9, 10),(2, 3),7. This strategy can be used in sub-list ranking mode discussed in Sect. 4.2 where rankings above a certain threshold would be considered.
-
-
Extremities Strategy: This category of strategies include most pleasure, least misery. This particular set of strategies can be used in pairwise comparison mode where most pleasure can be used for the high category and least misery for the lower categories. It can also be used for comparative opinions in which qualification of good or worse can be made if the opinion is above or below the threshold. For instance, if the threshold is 5, values above 5 may qualify the item to be better the other item and vice versa.
-
Most pleasure: The rankings of the items is based on the maximum ratings by the user [11]. Majority vote is considered important in this case.
-
Least misery: The rankings of the items is based on the minimum ratings by the respective users. The minority gets a say in this strategy [10]. This strategy is the opposite of the Most pleasure.
-
-
Frequency-based strategies: Copeland rule and Borda count are some of the strategies in this category. Frequency based strategies can be adapted based on interaction mode such as categorical binning mode to classify them based on the frequency into categories. For instance, higher frequency can go into high category followed by the others. Or techniques based on reviews such as use of frequent terms can form the list of recommendations.
-
Copeland rule: This strategy sorts items according to their Copeland index. The items with better ratings take positive sign whereas the lower ones take negative signs. In other words, counts how often an item beats other item and how often it loses [18]. For instance, for the items 1 and 5 user John has the same preference, Adam prefers item 5 and Mary prefers item 1. Thus, there is no clear winner between the items, which results in a “0”. According to the calculations from the Table 5, the rankings of items are item 5, 1, 6, 9, 4, 8, 10, (2, 7), 3.
-
Borda count: Ranking is done on user profile. Lowest rated item get 0, the next best item gets 1 and so on. Items with same ratings use averaged sum of hypothetical score [17]. For example, items 2 and 7 received the same rating from Mary and correspond to the items with the second lowest score. Thus, they share the scores 1 and 2, leading to (1+2)/2 = 1.5. These individual scores are summed up to get the total. The final ranked list of the group is 6, 5, 1, (4, 8), 9, 10, 2, 7, 3 (Table 6).
-
-
Simple mathematical strategies: Simple arithmetic operations such as average, additive and multiplicative are in this category. All the items are added, multiplied or taken average of by their respective users. The higher the sum/product, the more appealing the option is to the users.
-
Consensus-based strategies: Average without misery, fairness are instances in this category.
-
Average without misery: determines the group rating for a particular item by calculating the average of the individual ratings but this technique also considers values above a certain threshold [10]. For instance, item 1 is not considered for the group recommendations because James rated it with 1 which is below the threshold. Techniques based on overall opinion mentioned in Sect. 4.4 should use this strategy because it makes sense to consider all the features and then compare it with a baseline. Consider a threshold of value 4 in Table 7. The rankings of the items are as follows: (5,6), 8, (4, 10), 2, 7 when using a threshold of 4.
-
Fairness strategy: This combines most pleasure and least misery causing strategies. Firstly, a user is selected is chosen at random then item that causes least misery is chosen, this process is done repetitively until all the items are finished. Items are chosen as if individual user are choosing the items in turn [11]. One person chooses first then second person until everyone made a choice. Everyone then chooses the second item starting with the person who finished last. In this way everyone gets a chance. If John starts first, James second and Mary last then the ranked item list from Table 8 will be 5, 6, 4, 8, 10, 7, 1, 2, 9, 3.
-
6 Strategies in Applications
-
INTRIGUE: This system uses the average weight strategy. It takes average and gives weights depending on the number of members in the group and the significance of subgroups. INTRIGUE gives more importance to certain subgroups such as children and disabled and therefore heavier weights are given to these subgroups.
-
GAIN: This uses a form of Average strategy which also uses weights. These weights are dependent on the members who are near and those who should be statistically in the group.
-
MusicFX: MusicFX uses a variant of Average Without Misery Strategy. The ratings are in range of −2 to 2, the higher the values are, the more positive the member is about that track. Individual ratings above a certain threshold are considered and then only those items’ average are taken. A weighted random selection is used to prevent choosing same station every time.
-
CATS: Without misery strategy is used because members either need to consider some of the features or may need to fill quantities of the items available. The recommendation which represents the most requirements of the whole group is chosen.
-
PolyLens: This recommendation system uses Least Misery strategy. PolyLens has an assumption of small group size and the group tends to be as happy as its least happy member.
-
Flickr Tag Recommendation: This helps in suggesting tag for users which people usually do manually. Two strategies are used here namely, plurality voting and summing. The former doesn’t take account of co-occurrence values while the latter does but on the other hand, both strategies are applied to top m co-occurring tags in the list [23].
-
Next Item Recommendation: This system gets item-item relationship from users’ past interactions. Afterwards, weights are estimated and assigned for every item in user trajectories which aids in effectively choosing the relevant items for short-term intentions. Average (mean), Most pleasure(max), Least misery(min) and sum are used as aggregation methods and then compared with each other [24].
-
Food Recommendation: Authors in [25] gives an overview of the systems available with different strategies used. In a group of 4 people who have to rate recipes on a scale of 1 to 5, least misery strategy is recommended by the authors in order to minimize misery.
7 Conclusion
This paper gives an overview on the previous research work, methods of collecting information, techniques by which this information can be categorized, categorization and practical application of strategies. Some ways of providing better recommendations was proposed. The paper also proposed what to do to make interfaces attractive and appealing for the group members. There are differences between individual and group recommendations in specifying preferences, presenting, explaining and making final decisions and this paper takes into account these differences. A lot of strategies exist some of which are grouped into categories to easily identify the similar ones for predictions, one section of this paper concentrates on that. The strategies which are practically used in recommendation systems present awareness about the most popular strategies. Ways to collect information is highly dependent on the makers of the recommendation system and all these different ways are discussed in details in this work. Techniques which affect the elicitation of preferences are also highlighted to shed a light on the practical use of recommendation systems. Recommendation systems can be made much more convenient and appealing if a bit more research and work is done in this field. I want to investigate more on certain elicitation techniques based on interaction mode, including user interfaces to find which techniques are preferred more by the users in future work. In specific, how to adapt the individual interaction to group recommendations. Using aggregation techniques to combine the individual preferences and some extra features such as showing the preferences of other members in the group or making the interfaces more appealing for the group.
References
Jameson, A. More than the sum of its members: challenges for group recommender systems
Lieberman, H., Vandyke, N. & Vivacqua, A. Let’s browse: a collaborative Web browsing agent
Mccarthy, J. Pocket restaurantfinder: A situated recommender system for groups
Pizzutilo, S., Decarolis, B., Cozzolongo, G. & Ambruoso, F. Group modeling in a public space: methods, techniques, experiences
Chao, D., Balthrop, J. & Forrest, S. Adaptive radio: achieving consensus using negative preferences
Ardissono, L., Goy, A., Petrone, G., Segnan, M., Torasso, P.: Intrigue: personalized recommendation of tourist attractions for desktop and hand held devices. Applied Artificial Intelligence. 17, 687–714 (2003)
Jameson, A. & Smyth, B. Recommendation to groups. (Springe 2007
Pazzani, M. & Billsus, D. Content-based recommendation systems. (Springe 2007
Schafer, J., Frankowski, D., Herlocker, J. & Sen, S. Collaborative filtering recommender systems. (Springe 2007
Masthoff, J. Group modeling: Selecting a sequence of television items to suit a group of viewers. (Springe 2004
Masthoff, J. Group recommender systems: aggregation, satisfaction and group attributes. (Springe 2015
Mccarthy, K., Mcginty, L., Smyth, B. & Salamó, M. The needs of the many: a case-based group recommender system
Mccarthy, J. & Anagnost, T. MusicFX: an arbiter of group preferences for computer supported collaborative workouts
Yu, Z., Zhou, X., Hao, Y., Gu, J.: TV program recommendation for multiple viewers based on user profile merging. User Modeling And User-adapted Interaction. 16, 63–82 (2006)
Goren-bar, D., Glinansky, O.: FIT-recommend ing TV programs to family members. Computers & Graphics. 28, 149–156 (2004)
Crossen, A. & Budzik, J. Promoting social interaction in public spaces: The flytrap active environment. (Springe 2006
Borda, J. amie Royale des Sciences, Paris. Cook Wd (2006) Distance-based And Ad Hoc Consensus Models In Ordinal Preference Ranking. Eur. J. Oper. Res. 172 pp. 369–385 (178)
Copeland, A.H. A reasonable social welfare function. (University of Michigan, 1951)
Andreadis, P. Coarse preferences: representation, elicitation, and decision making. (The University of Edinburg, 2019)
Kuhlman, C., Doherty, D., Nurbekova, M., Deva, G., Phyo, Z., Schoenhagen, P., Vanvalkenburg, M., Rundensteiner, E. & Harrison, L. Evaluating Preference Collection Methods for Interactive Ranking Analytics
Chen, Li, Chen, Guanliang, Wang, Feng: Recommender systems based on user reviews: the state of the art. User Modeling and User-Adapted Interaction 25(2), 99–154 (2015). https://doi.org/10.1007/s11257-015-9155-5
Jindal, N. & Liu, B. Mining comparative sentences and relations
Sigurbjörnsson, B. & Vanzwol, R. Flickr tag recommendation based on collective knowledge
Zhang, S., Tay, Y., Yao, L., Sun, A. & An, J. Next item recommendation with self-attentive metric learning
Trang Tran, Thi Ngoc, Atas, Müslüm, Felfernig, Alexander, Stettinger, Martin: An overview of recommender systems in the healthy food domain. Journal of Intelligent Information Systems 50(3), 501–526 (2017). https://doi.org/10.1007/s10844-017-0469-0
Colomo-Palacios, R., García-Peñalvo, F.J., Stantchev, V., Misra, S.: Towards a social and context-aware mobile recommendation system for tourism. Pervasive and Mobile Computing. 38, 505–515 (2017)
Colomo-Palacios, R., Casado-Lumbreras, C., Soto-Acosta, P., Misra, S.: Providing knowledge recommendations: an approach for informal electronic mentoring. Interactive Learning Environments. 22(2), 221–240 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Misra, A. (2021). A Survey for Recommender System for Groups. In: Misra, S., Muhammad-Bello, B. (eds) Information and Communication Technology and Applications. ICTA 2020. Communications in Computer and Information Science, vol 1350. Springer, Cham. https://doi.org/10.1007/978-3-030-69143-1_3
Download citation
DOI: https://doi.org/10.1007/978-3-030-69143-1_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-69142-4
Online ISBN: 978-3-030-69143-1
eBook Packages: Computer ScienceComputer Science (R0)