
Abstract
The new perspective in visual classification aims to decode the feature representation of visual objects from human brain activities. Recording electroencephalogram (EEG) from the brain cortex has been seen as a prevalent approach to understand the cognition process of an image classification task. In this study, we proposed a deep learning framework guided by the visual evoked potentials, called the Event-Related Potential (ERP)-Long short-term memory (LSTM) framework, extracted by EEG signals for visual classification. In specific, we first extracted the ERP sequences from multiple EEG channels to response image stimuli-related information. Then, we trained an LSTM network to learn the feature representation space of visual objects for classification. In the experiment, 10 subjects were recorded by over 50,000 EEG trials from an image dataset with 6 categories, including a total of 72 exemplars. Our results showed that our proposed ERP-LSTM framework could achieve classification accuracies of cross-subject of 66.81% and 27.08% for categories (6 classes) and exemplars (72 classes), respectively. Our results outperformed that of using the existing visual classification frameworks, by improving classification accuracies in the range of 12.62%–53.99%. Our findings suggested that decoding visual evoked potentials from EEG signals is an effective strategy to learn discriminative brain representations for visual classification.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Visual classification is a computer vision task that inputs an image and outputs a prediction of the category of the object image. It has become one of the core research directions of object detection and been developed rapidly with the discovery of Convolutional Neural Networks (CNN) in the last decades. CNN has been seen as a powerful network which is loosely inspired by human’s visual architecture, however, some researchers are cognizant that there are still significant differences in the way that human and current CNN process visual information [4]. Particularly, the performance of recognition of negative images [8] and generalisation towards previously unseen distortions [4] have further shown the robustness of CNNs on object recognition are not at the human level.
For human beings, object recognition seems to be accomplished effortlessly in everyday life, because the advantage of visual exteroceptive sense is distinct. For example, someone usually directly looks at the objects they want to recognise to make full use of the foveal vision. It has always been a challenging issue in cognitive neuroscience to figure out the mechanisms that human employed for the visual object categorisation [12]. Researchers have investigated that the brain exhibits functions of feature extraction, shape description, and memory matching, when the human brain is involving visual cognitive processes [3]. Subsequent studies [6, 15] have further revealed that analysing brain activity recordings, linkage with the operating human visual system, is possible to help us understand the presentational patterns of visual objects in the cortex of the brain. Inspired from the above visual neuroscience investigations, some recent work considered to process visual classification problems by analysing neurophysiology and neuroimaging signals recorded from human visual cognitive processes [1, 7, 9, 10, 16]. However, they are still limited to analyse the brain visual activities by using the raw physiological signals without extracting a more representative input during the signal preprocessing stage.
In addition, many existing visual classification studies have been focusing on electroencephalography (EEG)-based visual object discriminations as we explored above. EEG signals, featuring by a high temporal resolution in comparison with other neuroimaging, are generally recorded by electrodes on the surface of the scalp, which has been applied in developing several areas of brain-computer interface (BCI) classification systems [5], such as pictures, music, and speech recognitions [2]. However, the raw waveforms of EEG signals are the recorded spontaneous potential of the human brain in a natural state, which is difficult to distinguish the hidden event-related information during the visual cognitive process [3, 11]. Thus, the event-related potential (ERP) was proposed to identify the real-time evoked response waveforms caused by stimuli events (e.g., specific vision and motion activities), which usually performed lower values than the spontaneous EEG amplitude [3] and extracted from the EEG fragments with averaged superposition in multiple visual trials.
2 Related Work
Decoding image object-related EEG signals for visual classification has been a long-sought objective. For example, the early-stage studies in [13, 14] attempted to classify single-trial EEG responses to photographs of faces and cars. An image classification task [9] in 2015 considered a comprehensive linear classifier to tackle EEG brain signals evoked by 6 different object categories, and achieved the classification accuracy around 40%.
Afterwards, investigating the intersection between deep learning and decoding human visual cognitive feature spaces has increased significantly. In 2017, Sampinato et al. [16] proposed an automated visual classification framework to compute EEG features with Recurrent Neural Networks (RNN) and trained a CNN-based regressor to project images onto the learned EEG features. However, the recent two studies in 2018 and 2020 [1, 10] brought force questions to Spampinato’s block design [16] employed in the EEG data acquisition, where all stimulus of a specific class are presented together without randomly intermixed. In particular, the latest study in 2020 [1] replicated the Spampinato’s experiment [16] with a rapid-event design and analysed the classification performance on the randomised EEG trials. In addition, we noted that a special structure recurrent neural network, Long Short-Term Memory (LSTM) network, is commonly used in these studies to learn the representations of brain signals, which have shown the feasibility to decode human visual activities and deep learning for visual classification.
However, most of current machine learning approaches for visual classification ignored to explore the EEG evoked potentials of spontaneous generation. Even now deep learning is still difficult to recognise distinctive patterns of evoked potentials from the raw waveforms of EEG signals with a visual stimulus, so we assume that excluding visual related evoked potentials could be a fundamental cause that leads to an uncertain feature representation space for visual classification and place a restriction on the improvement of classification accuracy.
Thus, in this study, our work was inspired from two assumptions: (1) the feature representations employed by human brains for visual classification will be more pronounced learned from the purer ERP which conveys image stimuli-related information; (2) the multi-dimensional ERPs can be decoded to obtain a one-dimensional representation using RNN and do not require pre-selection of spatial or temporal components. One special type of RNNs, the LSTM, presents the strong capability in recognising long-term and short-term feature representations from time-series EEG signals.
With the above two assumptions, in this study, we proposed the first visual evoked potential-guided deep learning framework, called ERP-LSTM framework, to learn the discriminative representations for visual classification. The ERP-LSTM framework is constituted by two stages: (1) acquiring the ERP waveforms from multiple EEG trials with averaged superposition; (2) a parallel LSTM network mapping the extracted ERPs into feature representation vectors and involving an activation layer that classifies the derived vectors into different classes.
3 Our Proposed Framework
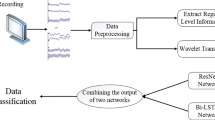
The overview of our proposed ERP-LSTM framework is shown in Fig. 1, which is separated into two stages for visual classification. In Stage 1, we employed raw EEG signals recorded from the visual experiment and then extracted ERPs from the raw EEG data to secure the visual stimuli-related signals. In Stage 2, we trained an LSTM network to learn the representation space of the ERP sequences and followed a Softmax classification trained to discriminate the different classes of the images.

The overview of the ERP-LSTM framework
3.1 Stage 1: ERPs Extractions from EEG
The representative features of EEG signals play an essential role in classifying image object categories. The first stage of our proposed framework aims to extract representative visual-related features of ERPs by increasing the signal-noise ratio (SNR) of the raw EEG signals with smooth-averaging measurement. A number of EEG segments with the same trials are averaged out to a fused waveform. In specific, during the averaging process, the consistent features of the segments (the ERPs) are retained, while features that vary across segments are attenuated (refer to the upper left corner of Fig. 1).
More formally, let \(d_{i}^{j}=\left\{ T_{1}^{j}, T_{2}^{j}, \ldots , T_{n}^{j}\right\} \), \(i \times n = N \), \(d_{i}^{j}\) is the \(i_{th}\) subset of the multi-channel temporal EEG signals, when one subject is viewing the \(j_{th}\) exemplar image. N is the number of EEG trials to be averaged, which contains n of EEG trials, where trial \(T_{n}^{j} \in \mathbb {R}^{c}\) (c is the number of channels).
The averaging process is described by the following fomula:
where \(e_{i}^{j}\) is the ERP sequence averaged from \(d_{i}^{j}\).
Let E be the sum of extracted multi-channel ERPs, \(E=\left\{ e_{1}^{j}, e_{2}^{j}, \ldots , e_{i}^{j}\right\} \), which will be the inputs of the LSTM encoder module we addressed in the next subsection to learn discriminative feature representations for visual classification.
3.2 Stage 2: Feature Representations and Classification
To further utilise the spatial and temporal information from extracted ERPs, we applied an LSTM encoder module shown in the lower part of Fig. 1, which refers to Spampinato’s “common LSTM + output layer” architecture [16]. The inputs of the encoder are the multi-channel temporal signals - ERPs, which are preprocessed in the previous subsection.
At each time step t, the first layer takes the input \(s(\Delta , t)\) (the vector of all channel values at time t), namely that all ERPs from multiple channels are initially fed into the same LSTM layer. After a stack of LSTM layers, a ReLU layer is added to make the encoded representations easy to map the feature space. The whole LSTM encoder outputs a one-dimensional representation feature of each ERP. After the representation vectors are obtained, a Softmax activation layer is finally connected to classify the LSTM representative features to different visual categories.
The LSTM encoder module is evaluated by the cross-entropy loss, which measures the differences between the classes predicted from the network and the ground-truth class labels. The total loss is propagated back into the neural network to update the whole model’s parameters through gradient descent optimisation.
In the proposed ERP-LSTM framework, the LSTM encoder module is used for generating feature representations from ERP sequences, followed by a Softmax classification layer to predict the visual classes.
4 The Experiment
4.1 The Dataset
In this study, we evaluated our model on the dataset proposed in [9]. There are 51840 trials of EEG signal that were collected from 10 subjects viewed 72 images, where each subject completed 72 trials of each of the 72 images and conducted a total of 5,184 trials per subject. The 72 images belong to 6 different categories of images, which are Human Body, Human Face, Animal Body, Animal Face, Fruit Vegetable, and Inanimate Object. In this study, each of the trials was labelled to map the description of the visual evoked-related events, namely the corresponding image category or the image exemplar number. Note that, we excluded the associated dataset proposed in [16] because of the block design problem in EEG data acquisition as mentioned in Sect. 2.
4.2 Settings
In this study, we randomly segmented the 72 EEG trials into 6 sets, and each set contains 12 EEG trials. The trials in each set are averaged to extract an ERP sequence with the same image and category label. Then, we obtained 6 ERP sequences of each image and also achieved E, the ERP space of the overall extracted 124-channel ERP sequences. Of note, the ERP space E is split into the training set and the testing set with a proportion of 5:1, indicating that 80% ERP sequences for each image keep in the training set and the remaining 20% sequences are on the testing set. To further evaluate the performance of the classification framework, we performed two types of data classification: cross-subject and within-subject basis.
5 Results
5.1 Performance of Six-Category Visual Classification
As shown in Table 1, we presented the classification performance of the basic LSTM using raw EEG (EEG-LSTM) [16] and our proposed ERP-LSTM frameworks. It also illustrated the two types (cross-subject and within-subject) of classification performance. Our findings showed that our proposed ERP-LSTM framework could reach about 66.81% accuracy for cross-subject type of visual classification and achieve the highest classification accuracy of 89.06% for a single subject (subject 1). Both outcomes were outperformed that of EEG-LSTM framework, where the classification accuracy improved 30.09% across 10 subjects, 53.99% for subject 1, and 23.46% for averaged within-subject from 1 to 10.
Our findings suggested that the representation feature space encoded from the extracted ERPs is more discriminative to classify image objects compared to that of the raw EEG. Also, we suppose that the critical information for object cognition of the brain signals did not miss during the averaging process. On the contrary, the extracted ERPs have retained the spatial and temporal feature that is related to the visual evoked potentials.
5.2 Performance of Exemplar-Level Visual Classification
Here, we further analysed the existing frameworks and our proposed ERP-LSTM framework at the exemplar image level. It removed the categories as the classification labels, and instead, it aims to identify a specific image as an exemplar. As shown in Table 2, we presented the existing two frameworks, Kaneshiro [9] and EEG-LSTM [16], to identify the exemplars with 72 classes across all 10 subjects. The findings showed that our proposed ERP-LSTM framework still could achieve the classification accuracy of 27.08% at the exemplar level, which outperformed 14.46% for Kaneshiro and 7.97% for EEG-LSTM. We also attached the results of six-category level classification to get insights into the difference between easy (category) and hard (exemplar) modes.
Thus, relative to the existing model, our work denoted that the representation feature decoded from the extracted ERPs is less confusion than raw EEG signals, which benefits to learn a more discriminative feature space for visual classification. Furthermore, our ERP-LSTM framework also achieved better performance than a recent work in 2020 [1] (in which the reported classification accuracy on 6 categories is 17.1%), even if we used the different data source. This suggested that the LSTM network is capable to encode the ERPs to obtain a representative feature space, as the advantages of LSTM network on tackling temporal dynamics of time-series EEG signals.
6 Conclusion
In this paper, we proposed an evoked potential-guided deep learning framework, called ERP-LSTM framework, for visual classification, which is separated into two stages: (1) extracting ERP sequences from multi-trial EEG segments; (2) a parallel LSTM network to encode a representation feature space for object categorisation as well as to classify EEG signal representations. Our proposed ERP-LSTM framework achieved better performance compared to existing frameworks both on the classification of 6 categories and 72 exemplar images. We believe our findings are presenting the feasibility to learn representational patterns of visual objects based on the recording of brain cortex activities, and an ERP-LSTM framework could learn characteristic features for visual classification.
References
Ahmed, H., Wilbur, R.B., Bharadwaj, H.M., Siskind, J.M.: Object classification from randomized EEG trials. arXiv preprint arXiv:2004.06046 (2020)
Bashivan, P., Rish, I., Yeasin, M., Codella, N.: Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv preprint arXiv:1511.06448 (2015)
Gazzaniga, M., Ivry, R., Mangun, G.: Cognitive Neuroscience: The Biology of the Mind, 3rd ed., Chap. 6 (2008)
Geirhos, R., Temme, C.R., Rauber, J., Schütt, H.H., Bethge, M., Wichmann, F.A.: Generalisation in humans and deep neural networks. In: Advances in Neural Information Processing Systems (NIPS), pp. 7538–7550 (2018)
Gu, X., et al.: EEG-based brain-computer interfaces (BCIs): a survey of recent studies on signal sensing technologies and computational intelligence approaches and their applications. arXiv preprint arXiv:2001.11337 (2020)
Hanson, S.J., Matsuka, T., Haxby, J.V.: Combinatorial codes in ventral temporal lobe for object recognition: haxby (2001) revisited: is there a “face” area? Neuroimage 23(1), 156–166 (2004)
Haynes, J.D., Rees, G.: Decoding mental states from brain activity in humans. Nat. Rev. Neurosci. 7(7), 523–534 (2006)
Hosseini, H., Xiao, B., Jaiswal, M., Poovendran, R.: On the limitation of convolutional neural networks in recognizing negative images. In: 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), pp. 352–358. IEEE (2017)
Kaneshiro, B., Guimaraes, M.P., Kim, H.S., Norcia, A.M., Suppes, P.: A representational similarity analysis of the dynamics of object processing using single-trial EEG classification. PLoS One 10(8), e0135697 (2015)
Li, R., et al.: Training on the test set? An analysis of Spampinato et al. [31]. arXiv preprint arXiv:1812.07697 (2018)
Pascalis, V.D.: Chapter 16 - on the psychophysiology of extraversion. In: Stelmack, R.M. (ed.) On the Psychobiology of Personality, pp. 295–327. Elsevier, Oxford (2004)
Peelen, M.V., Downing, P.E.: The neural basis of visual body perception. Nat. Rev. Neurosci. 8(8), 636–648 (2007)
Philiastides, M.G., Ratcliff, R., Sajda, P.: Neural representation of task difficulty and decision making during perceptual categorization: a timing diagram. J. Neurosci. 26(35), 8965–8975 (2006)
Philiastides, M.G., Sajda, P.: Temporal characterization of the neural correlates of perceptual decision making in the human brain. Cereb. Cortex 16(4), 509–518 (2005)
Simanova, I., Van Gerven, M., Oostenveld, R., Hagoort, P.: Identifying object categories from event-related EEG: toward decoding of conceptual representations. PLoS One 5(12), e14465 (2010)
Spampinato, C., Palazzo, S., Kavasidis, I., Giordano, D., Souly, N., Shah, M.: Deep learning human mind for automated visual classification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6809–6817 (2017)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Zheng, X., Cao, Z., Bai, Q. (2020). An Evoked Potential-Guided Deep Learning Brain Representation for Visual Classification. In: Yang, H., Pasupa, K., Leung, A.CS., Kwok, J.T., Chan, J.H., King, I. (eds) Neural Information Processing. ICONIP 2020. Communications in Computer and Information Science, vol 1333. Springer, Cham. https://doi.org/10.1007/978-3-030-63823-8_7
Download citation
DOI: https://doi.org/10.1007/978-3-030-63823-8_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-63822-1
Online ISBN: 978-3-030-63823-8
eBook Packages: Computer ScienceComputer Science (R0)