
Abstract
At present, the consistency detection of products mainly relies on manual method which has defects such as difficulty in identifying similar categories and low efficiency. Recently, the methods which are based on image classification have been widely used in it. However, image classification is based merely on simple visual features without making full use of other categrizable attributes. The approach this paper adopt to solve the problem is a joint detection algorithm which is based on deep learning. This algorithm locates product areas and implements image segmentation according to the default information code. Then it takes the segmented image as input of convolutional neural network model for classification. A reflection-assisted decision-making algorithm is used to solve the defect that the approximate class output probability is unstable. Finally, the consistency judgment is made according to the extracted default class information and product category. The experimental results obtained in this research show that the proposed algorithm can segment the products image accurately and quickly. The joint decision-making algorithm has better accuracy and stability than the single classification network.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
China has now become the world’s largest manufacturing country. Product consistency testing is an important step during the processes of production, transportation and distribution in the fields of both industrial manufacturing and logistics. For example, a reminder technology for product shelf life based on graphic recognition technology is proposed. By extracting the warranty date of the image containing the shelf life information, the inconsistent expired products are screened out [1].
The traditional product consistency test method uses manual visual inspection to observe whether there is product confusion or not through human eyes. This method is inefficient and highly dependent on personal experience. With the development of the Internet of Things technology, more automated methods of product consistency detection have been presented. L. Cui et al. proposed a new matching method in theory [2]. Matching the properties of the part to ensure consistent product assembly. C. H. Zhao et al. introduced the method of target anomaly detection by hyperspectral imaging technology [3, 4]. Hyperspectral imaging technology combines image with spectral analysis to express the external and internal features of the product. C. Xie et al. proposed a classification method to attach wireless sensors (Radio Frequency Identification, RFID) in products, then used it to carry or gather product information for classification purposes [5, 6]. K. Wamg et al. proposed a classification method that the product information is recorded by barcode, and the product information is decoded by the terminal to classify the product [7]. With the successful application of deep learning in the field of image processing and item classification, T. J. Li et al. uses a pre-trained convolutional neural network to identify the target object and obtain the location and category information of the target [8, 9].
In this paper, we mainly focus on solving the defects of similar items in the traditional product consistency detection method, such as difficulty in identifying similar items, cumbersome manual operation and slow processing speed. In this paper, a product consistency detection algorithm based on deep learning is proposed, which automatically extracts preset information and product images during the detection process, identifies product categories and makes product batch consistency judgments. Firstly, the method constructs an image classification model based on MobileNet network, and uses the transfer learning to train it. The last hidden layer is trained through fixing model parameters except the last hidden layer and the image classification model uses the collected predefined class data as input. Secondly, image segmentation is performed on the detected product image to extract a single product image. In order to reduce the operation complexity, a method of locating the product area by preset information code and implementing image segmentation is designed. At the same time, the preset standard class information extraction is completed. The classification model is used to classify the segmented product images. Aiming at the defects of the classification probability value which is too close and unstable when classifying similar material class by image, an auxiliary decision algorithm based on illumination reflection is proposed. Finally, the determination of product consistency is completed according to the preset standard class information and product classification results. The experimental results show that this algorithm can accurately segment the products image which is to be inspected and the processing time has a large-scale adaptability. Using the auxiliary decision algorithm will effectively change the distribution of the similar class output probability values and increase the variance. Meanwhile, it has a classification output function that corrects the original judgment error.
2 Related Work
2.1 CNN Introduction
Image object classification and detection are two important basic problems in computer vision research, and also the basis of other high-level visual tasks such as image segmentation, object tracking and behavior analysis [10]. In recent years, the deep learning has been successfully applied in technical areas including handwriting recognition, speech recognition, image recognition and natural language processing. Alex-Net has won an overwhelming victory in the ImageNet image classification competition in 2012. Subsequently, more powerful network structures such as VGGNet (Visual Geometry Group), Inception, ResNet (Deep Residual Network), etc. have been proposed. The classification accuracy rate can be comparable to or even exceed the human accuracy rate in the standard test set. But with the improvement of model accuracy is the huge cost of computation, storage space and energy consumption, they are difficult to accept for mobile applications. Google’s team proposed a lightweight identification network MobileNet [11], which greatly reduces convolution computation, providing a near real-time processing speed. The emergence of these technologies has made it possible to detect product consistency based on image recognition.
Convolutional neural Network (CNN) consists of a feature extraction convolutional layer and a feature sampling layer. The convolution kernel with shared weights is used to extract the spatial features of the image [12]. As a feature filter, Convolution kernels of different sizes extract the feature of each scale field of view domain, and transform the input original image into a feature map. The traditional convolution kernel is manually designed to extract the established features such as edge detection. In CNN, the parameters in the convolution kernel are trained by a large number of labelled data. The convolution kernel is obtained after the network best fit with the training data set. CNN can effectively avoid the limitations of manual design features and greatly improve the accuracy of recognition. However, in the image classification task, the approximate class image has high similarity, which causes the output probability value of the CNN classification network to be too close or classified incorrectly.
2.2 MobileNet Model and Transfer Learning
MobileNet is an efficient, lightweight neural network structure proposed by Google. The goal is for visual applications used in mobile and embedded devices. In the model miniaturization method, the MobileNet model is based on the depth-wise separable convolutions, which can decompose the standard convolution into a deep convolution and a dot convolution. This approach is firstly calculated by using a two-dimensional convolution kernel with a channel number of one. After the process of channel-by-channel convolution is finished, the three-dimensional 1 * 1 convolution kernel is used to process the previously output feature map. After using the decomposition convolution, the amount of calculation is greatly reduced, while the accuracy decreases very little. In the network structure, deep convolution and point convolution are treated as two independent modules, and a large number of point convolution operations save considerable computation time. MobileNet proposes two hyperparameters: width multiple and resolution multiple. The width multiple is mainly to reduce the number of channels proportionally, and the resolution multiple is mainly to reduce the size of the feature map proportionally. The final experimental results show that the model parameters can be reduced to a large extent while ensuring the performance.
Transfer Learning [13] is a new machine learning method that uses the prior knowledge to solve problems in different but related domains. The purpose is to transfer the prior knowledge to solve target domain problems which only have a small number of training data sets or even have no labelled data [14]. People can reuse and inherit the knowledge they have learned in the current learning. Thus, their abilities are enhanced. In the field of machine learning, the same ability is represented by multiplexing the parameters obtained from other training sets which are used for new learning tasks. The advantage of transfer learning is that it is suitable for small datasets, avoiding the over-fitting of small data on large models and maintaining the superior feature extraction capability of large neural networks. Transfer learning is mainly implemented by freezing part of the convolutional layer of the pre-training model, which trains the remaining convolutional layers and fully connection layers.
3 Consistency Detection Based on Combination of CNN and Illumination Reflection
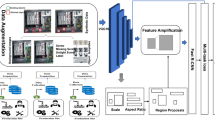
At present, the object image classification technology based on deep convolutional network is very mature and the classification accuracy is close to the human level in the ImageNet Challenge. However, the difficulties of applying it to product consistency detection include: 1. The confusion of product state makes it impossible to extract a single image effectively for further analysis. 2. The classification accuracy of products with high similarity is unacceptable if the image classification is the only one to be used. In order to solve the problems above, this paper proposes a product consistency detection algorithm which is shown in Fig. 1. The algorithm consists of data collection, preprocessing and joint decision making.

Product consistency detecting process
Data Collection: The specific data required to be collected at this stage include: a training set of the convolutional neural network and an image to be detected with a preset information code. The training data set could be collected from standard class and its historical confusion class. In the paper, they are product images which will be used for the transfer training of MobileNet. The acquired image which contains the product to be tested and the preset information code is used for image segmentation, preset information extraction and input data for consistency judgment.
Preprocessing: This stage consists of preset information code locating and information extraction, product image segmentation, training set normalization and model training. The preset information code positioning means to locate code position in the image based on the preset information code characteristics. The information extraction is parsing the standard class information contained in the code. The product image segmentation calculates the product area according to the positioning result before obtaining images of single product. The training set normalization is to sort the training set images according to categories, and then to remove the image which is blurred or has unsuitable size, even is obvious distorted. The image is transformed to meet the model input requirements. The model training uses a normalized training set to perform transfer learning training in the MobieNet. It is a method that includes three steps: 1. freezing hidden layer parameters except the last layer, 2. using the training set to train the last hidden layer, 3. changing the number of neurons in the output layer to meet the actual demand. Eventually, a custom training classification network model is obtained.
Joint Decision: This stage consists of object classification based on deep learning, auxiliary decision based on illumination reflection and consistency decision. The object classification based on deep learning obtains classification probability values by inputting the single-sample product image which is obtained from pre-processing into the classification model. If the probability distribution is consistent with the definition of similar classes, then the auxiliary system of illumination reflection is used for joint decision making. This auxiliary system converts the material reflectivity into the class probability value. The final probability is a weighted summation from probability values of network model and illumination reflection system. It is used to predict the single product class. The consistency judgment is made on the basis of each product class and the extracted standard class information, representing whether the batch products are consistent or not.
The main idea of the algorithm is to pre-define the position of the object which will be tested and segment the individual product images by the information code. Then deep neural network and auxiliary decision system is used in the step of classification. Finally, the product consistency is judged. The key points in the whole algorithm contain: 1. Product image segmentation. 2. Joint decision mechanism. 3. Consistency detection.
3.1 Product Image Segmentation
Image segmentation is an important preprocessing method in image processing and pattern recognition. The purpose of image segmentation is to divide the image into several non-overlapping sub-regions, so that the features in the same sub-region have certain similarities and the features among different sub-regions show obvious differences [15]. The macroscopic meaning is to extract semantic related regions. Since the training data for deep learning is mostly a single instance of this class, the parameters of model learned are fitting for a single object. However, there is a very low probability of occurrence in reality in the ideal single object image. The objects often cover each other. The input image of the classification network is distorted, missing or oversaturated. Thereby, the detection accuracy is reduced.
The traditional image segmentation method relies on the color, brightness and texture of the pixel to determine the similarity. It is easy to generate incorrect segmentation. Segmentation methods that is frequently used are threshold, boundary detection, regional method, etc. [16]. In recent years, the deep learning has been applied to the field of image segmentation. The idea is to transform the segmentation problem into a single pixel classification problem. Typical methods are Faster R-CNN (Regions with CNN) [17] based on the candidate region and the end-to-end method FCN (Fully Convolutional Networks) [18]. The accuracy is sufficient in these methods, but they also fail to solve the missing features caused by the mutual coverage of objects. If the product location is pre-standardized, the segmentation method of deep learning will result in significant computational waste and processing delay.
In this paper, a method to estimate the products area based on the preset product information code position and then segment the original image which a single product image will be obtained.


3.2 Joint Decision Mechanism
The CNN-based classification network has a significant effect on classification among the more differentiated categories. The output class probability has a large variance and is highly practical. However, the classification results between approximate subclasses are not sufficiently robust and stable. In the experiment, similar classes occupy the main probability distribution. The probability values between similar classes are too close. A slight change in the detected image can result in a large change in the output value of the classification network, which ultimately leads to incorrect classification results. In product detection application, the approximate subclass is the main cause of confusion.
In addition to image, classification methods based on material detection are also widely used. For example, near infrared spectroscopy (Near Infrared, NIR) chemical imaging is a new analytical tool developed rapidly in recent years [19]. Its advantage lies in the analysis of material composition. At present, attempts have been made to combine spectral analysis with machine learning methods to detect object. J. Ning et al. use the method of near infrared spectroscopy combining with neural network to determine the degree of fermentation of Pu’er tea [20]. H. Jiang et al. propose a method that uses the combination of chemical composition data obtained by infrared spectroscopy and clustering method for testing plastic beverage bottles [21].
The classification probability values obtained by the neural network classification model are extremely close and fallible when the shape and color of objects are highly similar. In this paper, the material reflectivity is used as the auxiliary decision parameter to solve the confusion of approximate subclass. This method improves accuracy and stability of the consistency detection in a low cost manner.

3.3 Consistency Detection
Product consistency refers to the logo and structure of a batch product should be consistent with the type of qualified products. The macroscopic consistency is expressed in the same category as the product, and there is no other confused class. After the key points of the algorithm are proposed in this paper: product image segmentation and joint decision mechanisms are implemented. Accordingly, the class of each product in the batch can be confirmed and a consistency determination will be worked out conclusively. The output of classification can be obtained from historical confused data. When the new class of confused product appears, the existing algorithm fails. Then, the new confused class should be added to the classification model output, and the classification network can be reset. The adaptive consistency detection model can be obtained again after that.
The detailed steps for the consistency detection based on convolutional neural network combined with illumination reflection are:
-
Step 1. Collecting images of expected products, including standard and confused classes. Clearning and organizing the data: (1) removing image such as blur, unsuitable size, obvious distortion and incomplete items. (2) Adjusting the image with excessive tilt angle to improve classification accuracy. (3) Resizing to the input image.
-
Step 2. Training a classification neural network model using the training set in step 1.
-
Step 2.1. Defining the input and output of the neural network. In the detected image, there may be cases that n detection areas are not filled. So a class named Blank must be added. It can be the background image of detection station. The final output is the probability value of k class, adding the probability value of class of Blank.
-
Step 2.2. Constructing a convolutional neural network. In order to improve the accuracy of this model, a training method based on transfer learning is adopted. The output is probability values of k + 1 classes;
-
Step 2.3. Dividing collected images into training sets, validation sets and test sets.
-
Step 2.4. Defining the loss function and the accuracy calculation method.
-
Step 2.5. Iterating training and updating parameters.
-
-
Step 3. Performing segmentation for the image of product to be tested
-
Step 4. The product image obtained in step 3 is processed through the classification model from step 2. If the classification probability values are too close, a joint decision mechanism is adopted.
-
Step 5. According to the preset information obtained in step 3 and the product class information obtained in step 4, it is determined whether the batch products are consistent or not. The standard class Classstd is parsed from the preset information Sinfo before traversing the product class list Sclass obtained in step 4. If there is only Classstd in Sclass except ClassBlank, then the true of the consistency of the batch product can be determined, otherwise it is false.
4 Experiments
4.1 Experimental Setup
The experimental environment in this paper utilizes the deep learning framework Tensorflow and computer vision library OpenCV to implement the proposed algorithm. TensorFlow is an open source software library for high performance numerical computation whose flexible architecture allows easy deployment of computation across a variety of platforms and from desktops to clusters of servers to mobile and edge devices. It originally developed by researchers and engineers from the Google Brain team within Google’s AI organization. OpenCV is free for both academic and commercial use. OpenCV was designed for computational efficiency with a strong focus on real-time applications. It can takes advantages of the hardware acceleration of the underlying heterogeneous compute platform.
The experimental data are normal commercial including plastic bottles, cans and glass bottles. Parts of plastic bottles and glass ones are similar in shapes and colors in the experimental data. The preset information code uses a QR code to record class information string: “plastic”, “can” and “glass”. The training set includes 4 types of images (adding class of Blank) and are resized to 224 * 224 pixels. The images quantity of each class are about 1000 and the capability is about 400 M.
The model used for transfer learning is MobileNet. The accuracy of the test set after training was about 93%. The chosen suitable single detection area size is 30 * 12 cm. When the number of product area n is 3, the scaling factor a is 4, b is 6.4.
The experimental items include:
-
Testing the accuracy and execution time of the image segmentation algorithm on different detection sets (including the time of saving images).
-
Testing the classification probability value of the typical sample to be tested only processed by Mobilnet classification network.
-
Testing the classification probability value of the similarity sample after being processed by the joint decision mechanism (where wm is 0.4, ws is 0.6, fstd of glass is 0.8, fstd of plastic is 0.4,).
4.2 Results and Discussion
Experiment one: To test the accuracy and execution time of the image segmentation algorithm on different detection sets. In this experiment, image segmentation was performed on the image to be tested containing different numbers of products. The execution time of this algorithm is recorded, and the accuracy is obtained according to the integrity and correctness of the single product image after the segmentation. The experimental results are shown in Table 1 and Fig. 2 below:

The results of image segmentation
It can be seen from Table 1 and Fig. 2 obviously that this algorithm can accurately segment the area where the products to be tested are located. Observing the processing time, it can be inferred that the main processing time of this segmentation algorithm spend in is for locating QR code and then calculating its area. The linear increase of the amount of test set does not lead to a linear increase of the processing time. Thereby, this algorithm is advantageous for implementing large-scale detection.
Experiment two: To test the classification probability value of the typical sample to be tested only processed by Mobilnet classification network. In this experiment, three types of products (plastic bottles, glass bottles, and cans) in the test data were classified by merely using the MobileNet classification model. In order to test the classification accuracy of convolutional neural networks on appearance similar classes, two contrastive groups have been set. One group are higher in appearance similarity: plastic bottles (transparent) and glass bottles (transparent). While another group has lower appearance similarity: plastic bottles (opaque) and glass bottles (opaque).
Classification probability values are generated by MobileNet only. The experimental results are shown in Table 2 and Fig. 3 below:

The classification results of MobileNet network
It can be concluded from Table 2 and Fig. 3 that when MobileNet is used as the classification model only, the output probability values which come from the class with large difference in shape and color account for a large distribution space. This indicates that they can be availably judged by the classification model. But when the shape and color difference of the object to be tested are small, the output probability values between similar classes share little differences, even the classification result according to the maximum probability value is erroneous.
Experiment three: To test the classification probability value of the similarity sample after being processed by the joint decision mechanism. In this experiment, the products that are confused in experiment 2 are used as test data. They are plastic bottles (transparent) and glass bottles (transparent). The classification model is changed to the joint decision mechanism which is based on MobileNet network and illumination reflection assistance. The classification probability values are obtained with updated configuration. The typical parameters wm is 0.4, ws is 0.6, fstd of glass is 0.8 and fstd of plastic is 0.4. The experimental results are shown in Table 3 and Fig. 4:

The classification results of Joint Decision
It can be concluded from Table 3 and Fig. 4 that when the material-based joint decision system is added, the distribution of the similar class output probability values will be effectively changed and the variance will be increased. The auxiliary decision-making mechanism can correct the error classification output as well. The weight parameters wm and ws depend on the validity of the material detection method.
The essence of joint decision-making is to increase the data dimension and to use more categorizable attributes. The data distribution which is difficult to classify becomes easy to distinguish by adding new attributes. Therefore, the newly added features should be distributed independently from the image features. The weight w represents the parameter of the optimal classification function f(x). The parameter w can be determined by the objective weighting method. This method means that the weight should reflect the influence degree of each feature on the final result. It can be generally obtained by normalizing the reliability of different features. Assume that the image classification accuracy is pi and the material classification accuracy is pm. The weight vector [wm, ws] can be obtained from normalizing the vector [pi, pm].
Furthermore, the neural network is a nonlinear function of pixel features. The linear weighting method used in this paper still contains a large number of artificial designed factors such as weight selection. This leads to limited generalization of the model. In the future work, you can consider the material properties as input of the neural network and choose to add them in the appropriate layer. Then, the joint decision weight can be automatically learned by the machine to get stronger generalization ability.
5 Conclusion
This paper proposes a product consistency joint detection algorithm based on convolutional neural network and illumination reflection to solve the consistency problem in batch products. Firstly, the image to be detected is segmented to obtain a single product image to be tested and standard class information. Then, through the pre-trained MobileNet network, the product class is effectively identified by joint decision which is based on the illumination reflection system. Finally, the consistency is determined according to the standard class information and classification result. This algorithm are advantageous in rapid image segmentation, accurate and stable classification results. The shortcoming of this algorithm is that in large-scale detection, each product needs to perform a large number of parameters calculation, which affects the efficiency of this algorithm. In the future work, it is considered to introduce the similarity between product images for pre-determination and reduce redundant neural network calculation. Meanwhile, it is also possible to adjust the classification sequence and adopt the idea of cascade screening.
References
Wang, B., Yunlu, W.: Research on product quality reminder technology based on graphic recognition technology. Technol. Innov. Appl. 29, 6–7 (2016)
Lirong, C., Dejing, K., Haijun, L.: Matching via majorization for consistency of product quality. Q. Technol. Quant. Manag. 13(4), 439–452 (2016)
Chunhui, Z., Xiaohui, L., et al.: Research advance on anomaly detection for hyperspectral imagery. J. Electron. Meas. Instrum. 28(8), 803–811 (2014)
Ouyang Aiguo, O., Jian, W., et al.: Application of hyperspectral imaging in nondestructive detection of agricultural products. Guangdong Agric. Sci. 23, 164–171 (2015)
Chuan, X., Ying, P.: Research of intelligent garbage collection collaboration based on RFID technology. J. Sic. Univ. 48(3), 556–560 (2011)
Yuyan, S., Hong, Y., et al.: An intelligent logistics tracking system based on WSN. J. Comput. Res. Dev. 48, 343–349 (2011)
Kun, W., Xiaoshan, L., et al.: Design of automatic sorting system for logistics package based on bar code recognition. J. Luoyang Institute Sci. Technol. 26(2), 66–70 (2016)
Xiru, W., Guoming, H., et al.: Fast Visual identification and location algorithm for industrial sorting robots based on deep learning. Robot 38(6), 711–719 (2016)
Tianjian, L., Bin, H., Jiangyu, L., et al.: Application of convolutional neural network object detection algorithm in logistics warehouse. Comput. Eng. 44(6), 176–181 (2018)
KaiQi, H., Weiqiang, R., et al.: A review on image object classification and detection. Chin. J. Comput. 37(6), 1225–1240 (2014)
Howard, A.G., Zhu, M., Chen, B., et al.: Mobilenets: efficient convolutional neural networks for mobile vision applications. arXiv:1704.04861v1 (2017)
Shun, Z., Yihong, G., et al.: The development of deep convolutional neural network and its applications on computer vision. Chin. J. Comput. 40(144), 30 (2017)
Jialin, P.S., Qiang, Y.: A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22(10), 1345–1359 (2010)
Zhuang, F.Z., Luo, P., He, Q., Shi, Z.Z.: Survey on transfer learning research. J. Softw. 26(1), 26–39 (2015)
Lili, Z., Feng, J.: Survey on image segmentation methods. Appl. Res. Comput. 34(7), 1921–1928 (2016)
Jiang, F., Gu, Q., Hao, H.Z., Li, N., Guo, Y.W., Chen, D.X.: Survey on content-based image segmentation methods. J. Softw. 28(1), 160–183 (2017)
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell., 91–99 (2016)
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: Proceedings of the 28th IEEE Conference on CVPR, pp. 1337–1342. IEEE Computer Society, Washington (2015)
Chu, X., Lu, W.: Research and application progress of near infrared spectroscopy analytical technology in China in the past five years. Spectroscopy Spectral Anal. 34(10), 2595–2605 (2014)
Jingming, N., Xiaochun, W., Zhengzhu, Z., et al.: Discriminating Fermentation Degree of Pu’er tea based on NIR spectroscopy and artificial neural network. Trans. Chin. Soc. Agric. Eng. 29(11), 255–260 (2013)
Hong, J., Chenyang, J., et al.: Spectral analysis of plastic beverage bottles based on cluster analysis. Infrared Laser Eng. 47(8), 358–363 (2018)
Acknowledgement
This work was supported by the National Natural Science Foundation of China (No. 61862068), Yunnan Provincial Smart Education Key Laboratory Project, and Program for innovative research team (in Science and Technology) in University of Yunnan Province, and Starting Foundation for Doctoral Research of Yunnan Normal University (No. 2017ZB013).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, B., Gan, J., Wang, J., Wen, B. (2020). Product Consistency Joint Detection Algorithm Based on Deep Learning. In: Chen, X., Yan, H., Yan, Q., Zhang, X. (eds) Machine Learning for Cyber Security. ML4CS 2020. Lecture Notes in Computer Science(), vol 12488. Springer, Cham. https://doi.org/10.1007/978-3-030-62463-7_28
Download citation
DOI: https://doi.org/10.1007/978-3-030-62463-7_28
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-62462-0
Online ISBN: 978-3-030-62463-7
eBook Packages: Computer ScienceComputer Science (R0)